Recognition: no theorem link
COSAC: Counterfactual Credit Assignment in Sequential Cooperative Teams
Pith reviewed 2026-05-12 01:57 UTC · model grok-4.3
The pith
COSAC assigns each agent in a sequential cooperative team its own credit signal from a shared reward by fitting an additive decomposition with ridge regression and estimating advantages from fictitious policy continuations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
COSAC is a critic-free per-agent policy gradient for sequential cooperative teams. It fits an additive per-agent decomposition of the team reward by a single ridge regression on the rollout batch and computes each agent's counterfactual advantage from fictitious continuations of the current policy. The estimator realizes the Sequential Aristocrat Utility and comes with proofs that its bias and variance bounds remain controlled as team size increases.
What carries the argument
The Sequential Aristocrat Utility (SeqAU) realized through a single ridge regression that recovers per-agent reward shares plus fictitious policy forward passes that generate counterfactual advantages without extra environment interactions or importance sampling.
If this is right
- Each agent's policy gradient becomes independent of noise from teammates' actions.
- Bias and variance of the per-agent credits stay bounded even as team size reaches 16.
- Advantage estimation error is lower than other critic-free methods on sequential bandit tasks.
- Learning regret remains consistently low across increasing team sizes in controlled studies.
- Faster convergence occurs on collaborative reasoning tasks with multiple language-model agents.
Where Pith is reading between the lines
- The approach could reduce reliance on centralized critics in other large multi-agent systems where actions are ordered.
- Checking how well the additive decomposition holds on new domains would directly test when the method remains reliable.
- The fictitious-continuation technique might combine with other decomposition methods to handle non-additive rewards approximately.
Load-bearing premise
The shared team reward admits an additive decomposition into per-agent contributions that ridge regression on finite rollout batches can recover accurately enough to avoid bias in policy learning.
What would settle it
If advantage mean squared error or learning regret in the sequential bandit study grows with team size in the same way as importance-sampling baselines, the controlled-bounds claim would be contradicted.
Figures










read the original abstract
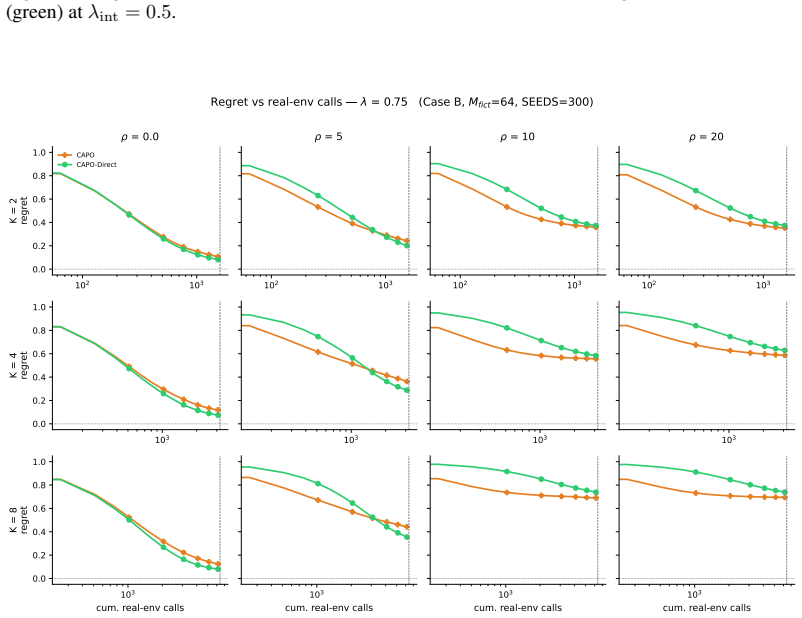
In cooperative teams where agents act in a fixed order and share a single team-level reward (multi-agent language systems, sequential robotic tasks), per-agent credit assignment is under-determined. Critic-based approaches scale poorly as the number of agents grows owing to the costly maintenance of joint/factored critic(s), whereas the existing critic-free alternatives have other issues: common credit across agents that couples every agent's signal to teammate noise, importance-sampling corrections for upstream-update staleness that incur variance exponential in team size, or per-agent counterfactual replay that isolates each agent's effect at the price of extra environment or reward calls. We propose COSAC, a critic-free per-agent policy gradient for sequential cooperative teams. COSAC fits an additive per-agent decomposition of the team reward by a single ridge regression on the rollout batch (giving each agent a learning signal decoupled from teammate noise), and computes each agent's counterfactual advantage from fictitious continuations of the current policy (policy forward passes that replace both importance-sampling reweighting and per-agent environment replay, at no extra environment or reward cost). The estimator instantiates the Sequential Aristocrat Utility (SeqAU), our extension of Wolpert and Tumer's (2001) aristocrat utility to sequential teams. We prove bias and variance bounds on SeqAU credits that stay controlled as the team grows. Our controlled study on sequential bandits demonstrates that COSAC attains the lowest advantage MSE and consistently low learning regret across team sizes up to $K = 16$. On the AI2 Reasoning Challenge (ARC) task, where four Qwen3-0.6B agents reason in turn about a grade-school science question, COSAC attains faster convergence than the other critic-free baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes COSAC, a critic-free per-agent policy gradient method for sequential cooperative multi-agent teams that share a team-level reward. COSAC fits an additive per-agent reward decomposition via a single ridge regression on the rollout batch and computes each agent's counterfactual advantage (instantiating the Sequential Aristocrat Utility, or SeqAU) from fictitious continuations of the current policy. It proves bias and variance bounds on the SeqAU credits that remain controlled as the number of agents grows, and reports empirical results showing lower advantage MSE and faster convergence than critic-free baselines on sequential bandits (up to K=16) and a four-agent Qwen3-0.6B setup on the ARC task.
Significance. If the bias/variance bounds hold and the ridge-regression decomposition introduces negligible error, COSAC would offer a scalable, low-overhead alternative to joint-critic methods for credit assignment in ordered cooperative settings such as multi-agent language-model reasoning or sequential robotics. The use of fictitious policy continuations avoids both importance-sampling variance and extra environment calls, and the controlled scaling with team size addresses a known limitation of existing critic-free approaches. The ARC experiment provides concrete evidence of applicability to LLM-based agents.
major comments (2)
- [Theoretical analysis (bias/variance bounds)] Proof of bias and variance bounds on SeqAU credits: the stated guarantees that bounds remain controlled as team size grows rest on the assumption that the single ridge regression on the finite on-policy rollout batch recovers an additive decomposition whose per-agent terms yield unbiased counterfactual advantages. No misspecification analysis or sensitivity result is provided for the case in which the chosen regressors fail to span the true marginal contributions under temporal action dependence; this assumption is load-bearing for the central theoretical claim.
- [Empirical study (sequential bandits)] Experimental validation on sequential bandits: the reported lowest advantage MSE and low learning regret across K up to 16 rely on the fitted decomposition being accurate, yet the manuscript does not specify the exact feature set used in the ridge regression, the batch size relative to team size, or any controls for post-hoc selection effects when evaluating the estimator on the same rollout data used for fitting.
minor comments (1)
- [Method description] Notation for the fictitious continuation operator and the exact form of the ridge-regression objective could be clarified with an explicit equation reference to avoid ambiguity when readers compare to standard counterfactual estimators.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential of COSAC as a scalable critic-free approach. We address each major comment below with clarifications and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Theoretical analysis (bias/variance bounds)] Proof of bias and variance bounds on SeqAU credits: the stated guarantees that bounds remain controlled as team size grows rest on the assumption that the single ridge regression on the finite on-policy rollout batch recovers an additive decomposition whose per-agent terms yield unbiased counterfactual advantages. No misspecification analysis or sensitivity result is provided for the case in which the chosen regressors fail to span the true marginal contributions under temporal action dependence; this assumption is load-bearing for the central theoretical claim.
Authors: The bias and variance bounds for the SeqAU credits are formally derived conditional on the ridge regression recovering an additive per-agent decomposition of the team reward. Under this condition, the proof demonstrates that the counterfactual advantages obtained from fictitious policy continuations have bias and variance that remain bounded independently of team size K. The manuscript does not include a dedicated misspecification or sensitivity analysis for the case where the chosen regressors (linear features over actions and timesteps) fail to span the true marginal contributions in the presence of strong temporal action dependence. We view this as a valid point and will add a new subsection in the theoretical analysis that explicitly states the assumption, discusses its implications, and notes that the empirical advantage MSE results provide supporting evidence for the approximation quality in the evaluated settings. A full non-asymptotic sensitivity analysis would require additional technical development beyond the current scope. revision: partial
-
Referee: [Empirical study (sequential bandits)] Experimental validation on sequential bandits: the reported lowest advantage MSE and low learning regret across K up to 16 rely on the fitted decomposition being accurate, yet the manuscript does not specify the exact feature set used in the ridge regression, the batch size relative to team size, or any controls for post-hoc selection effects when evaluating the estimator on the same rollout data used for fitting.
Authors: We agree that these implementation details are essential for reproducibility and for addressing concerns about estimator accuracy. In the sequential bandits experiments the ridge regression uses a feature matrix whose columns are one-hot encodings of each agent's action together with the current timestep index (feature dimension linear in K). Each policy update is performed on a batch of 512 on-policy trajectories, with the decomposition fitted on this batch and advantage estimates subsequently evaluated on a disjoint held-out set of 128 trajectories to avoid post-hoc selection bias. These specifications, along with pseudocode for the ridge-regression step, will be added to the experimental section and appendix of the revised manuscript. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper proposes COSAC as an algorithmic estimator: it explicitly fits an additive per-agent reward decomposition via ridge regression on the observed rollout batch, then computes counterfactual advantages using fictitious policy continuations. This fitting step is presented as part of the method to obtain per-agent signals, not as a first-principles derivation that reduces by construction to its own inputs. The bias and variance bounds are proved for the resulting SeqAU credits (under the maintained assumption that the fitted decomposition is sufficiently accurate), but no equation or step is shown to be tautological or statistically forced in a self-referential loop. No load-bearing self-citations, uniqueness theorems imported from prior author work, or ansatzes smuggled via citation appear in the abstract or described chain. The approach has independent content in its use of regression for decoupling and policy simulations to avoid extra environment calls. Concerns about regression misspecification or bias belong to correctness analysis rather than circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Difference rewards policy gradients
Jacopo Castellini, Sam Devlin, Frans A Oliehoek, and Rahul Savani. Difference rewards policy gradients. Neural Computing and Applications, 37 0 (19): 0 13163--13186, 2025
work page 2025
-
[2]
Yanjun Chen, Yirong Sun, Hanlin Wang, Xinming Zhang, Xiaoyu Shen, Wenjie Li, and Wei Zhang. Contextual counterfactual credit assignment for multi-agent reinforcement learning in LLM collaboration, 2026
work page 2026
-
[3]
DeepSeek-R1 : Incentivizing reasoning capability in LLM s via reinforcement learning, 2025
DeepSeek-AI . DeepSeek-R1 : Incentivizing reasoning capability in LLM s via reinforcement learning, 2025
work page 2025
-
[4]
Foerster, Gregory Farquhar, Triantafyllos Afouras, Nantas Nardelli, and Shimon Whiteson
Jakob N. Foerster, Gregory Farquhar, Triantafyllos Afouras, Nantas Nardelli, and Shimon Whiteson. Counterfactual multi-agent policy gradients. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 2974--2982, 2018. doi:10.1609/aaai.v32i1.11794
-
[5]
Carlos Guestrin, Michail G. Lagoudakis, and Ronald Parr. Coordinated reinforcement learning. In Proceedings of the Nineteenth International Conference on Machine Learning (ICML), pages 227--234. Morgan Kaufmann, 2002
work page 2002
-
[6]
Multi-agent deep research: Training multi-agent systems with M-GRPO , 2025
Haoyang Hong, Jiajun Yin, Yuan Wang, Jingnan Liu, Zhe Chen, Ailing Yu, Ji Li, Zhiling Ye, Hansong Xiao, Yefei Chen, Hualei Zhou, Yun Yue, Minghui Yang, Chunxiao Guo, Junwei Liu, Peng Wei, and Jinjie Gu. Multi-agent deep research: Training multi-agent systems with M-GRPO , 2025
work page 2025
-
[7]
Jelle R. Kok and Nikos Vlassis. Collaborative multiagent reinforcement learning by payoff propagation. Journal of Machine Learning Research, 7 0 (65): 0 1789--1828, 2006. URL http://jmlr.org/papers/v7/kok06a.html
work page 2006
-
[8]
Settling the variance of multi-agent policy gradients
Jakub Grudzien Kuba, Muning Wen, Linghui Meng, Shangding Gu, Haifeng Zhang, David Henry Mguni, Jun Wang, and Yaodong Yang. Settling the variance of multi-agent policy gradients. In Advances in Neural Information Processing Systems 34 (NeurIPS 2021), pages 13458--13470, 2021
work page 2021
-
[9]
Trust region policy optimisation in multi-agent reinforcement learning
Jakub Grudzien Kuba, Ruiqing Chen, Muning Wen, Ying Wen, Fanglei Sun, Jun Wang, and Yaodong Yang. Trust region policy optimisation in multi-agent reinforcement learning. In International Conference on Learning Representations (ICLR), 2022. URL https://openreview.net/forum?id=EcGGFkNTxdJ
work page 2022
-
[10]
Tor Lattimore and Csaba Szepesv \'a ri. Bandit algorithms. Cambridge University Press, 2020
work page 2020
-
[11]
Who deserves the reward? SHARP : Shapley credit-based optimization for multi-agent system, 2026 a
Yanming Li, Xuelin Zhang, WenJie Lu, Ziye Tang, Maodong Wu, Haotian Luo, Tongtong Wu, Zijie Peng, Hongze Mi, Yibo Feng, Naiqiang Tan, Chao Huang, Hong Chen, and Li Shen. Who deserves the reward? SHARP : Shapley credit-based optimization for multi-agent system, 2026 a
work page 2026
-
[12]
Difference advantage estimation for multi-agent policy gradients
Yueheng Li, Guangming Xie, and Zongqing Lu. Difference advantage estimation for multi-agent policy gradients. In Proceedings of the 39th International Conference on Machine Learning (ICML), volume 162 of Proceedings of Machine Learning Research, pages 13066--13085, 2022. URL https://proceedings.mlr.press/v162/li22w.html
work page 2022
-
[13]
Zhongyi Li, Wan Tian, Yikun Ban, Jinju Chen, Huiming Zhang, Yang Liu, and Fuzhen Zhuang. Counterfactual credit policy optimization for multi-agent collaboration. arXiv preprint arXiv:2603.21563, 2026 b
-
[14]
LLM collaboration with multi-agent reinforcement learning, 2025
Shuo Liu, Tianle Chen, Zeyu Liang, Xueguang Lyu, and Christopher Amato. LLM collaboration with multi-agent reinforcement learning, 2025
work page 2025
-
[15]
Sequential multi-agent dynamic algorithm configuration
Chen Lu, Ke Xue, Lei Yuan, Yao Wang, Yaoyuan Wang, Sheng Fu, and Chao Qian. Sequential multi-agent dynamic algorithm configuration. In Advances in Neural Information Processing Systems 38 (NeurIPS 2025), 2025
work page 2025
-
[16]
Bei Peng, Tabish Rashid, Christian Schroeder de Witt, Pierre-Alexandre Kamienny, Philip H. S. Torr, Wendelin B \"o hmer, and Shimon Whiteson. FACMAC : Factored multi-agent centralised policy gradients. In Advances in Neural Information Processing Systems 34 (NeurIPS 2021), pages 12208--12221, 2021
work page 2021
-
[17]
Tabish Rashid, Mikayel Samvelyan, Christian Schr \"o der de Witt, Gregory Farquhar, Jakob N. Foerster, and Shimon Whiteson. QMIX : Monotonic value function factorisation for deep multi-agent reinforcement learning. In Proceedings of the 35th International Conference on Machine Learning (ICML), volume 80 of Proceedings of Machine Learning Research, pages 4...
work page 2018
-
[18]
Proximal policy optimization algorithms, 2017
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms, 2017
work page 2017
-
[19]
Leibo, Karl Tuyls, and Thore Graepel
Peter Sunehag, Guy Lever, Audrunas Gruslys, Wojciech Marian Czarnecki, Vin \' cius Flores Zambaldi, Max Jaderberg, Marc Lanctot, Nicolas Sonnerat, Joel Z. Leibo, Karl Tuyls, and Thore Graepel. Value-decomposition networks for cooperative multi-agent learning based on team reward. In Proceedings of the 17th International Conference on Autonomous Agents and...
work page 2085
-
[20]
Off-policy evaluation for slate recommendation
Adith Swaminathan, Akshay Krishnamurthy, Alekh Agarwal, Miroslav Dud \' k, John Langford, Damien Jose, and Imed Zitouni. Off-policy evaluation for slate recommendation. In Advances in Neural Information Processing Systems 30 (NIPS 2017), pages 3632--3642, 2017
work page 2017
-
[21]
Hindsight credit assignment for long-horizon LLM agents, 2026
Hui-Ze Tan, Xiao-Wen Yang, Hao Chen, Jie-Jing Shao, Yi Wen, Yuteng Shen, Weihong Luo, Xiku Du, Lan-Zhe Guo, and Yu-Feng Li. Hindsight credit assignment for long-horizon LLM agents, 2026
work page 2026
-
[22]
Counterfactual effect decomposition in multi-agent sequential decision making
Stelios Triantafyllou, Aleksa Sukovic, Yasaman Zolfimoselo, and Goran Radanovic. Counterfactual effect decomposition in multi-agent sequential decision making. In Proceedings of the 42nd International Conference on Machine Learning (ICML), volume 267 of Proceedings of Machine Learning Research, pages 60072--60098, 2025
work page 2025
-
[23]
A Concise Introduction to Multiagent Systems and Distributed Artificial Intelligence
Nikos Vlassis. A Concise Introduction to Multiagent Systems and Distributed Artificial Intelligence. Morgan and Claypool Publishers, 1st edition, 2007. ISBN 1598295268
work page 2007
-
[24]
DOP : Off-policy multi-agent decomposed policy gradients
Yihan Wang, Beining Han, Tonghan Wang, Heng Dong, and Chongjie Zhang. DOP : Off-policy multi-agent decomposed policy gradients. In International Conference on Learning Representations (ICLR), 2021. URL https://openreview.net/forum?id=6FqKiVAdI3Y
work page 2021
-
[25]
David H. Wolpert and Kagan Tumer. Optimal payoff functions for members of collectives. Advances in Complex Systems, 4 0 (2--3): 0 265--279, 2002
work page 2002
-
[26]
Sequential cooperative multi-agent reinforcement learning
Yifan Zang, Jinmin He, Kai Li, Haobo Fu, Qiang Fu, and Junliang Xing. Sequential cooperative multi-agent reinforcement learning. In Proceedings of the 22nd International Conference on Autonomous Agents and Multiagent Systems (AAMAS), pages 485--493, 2023
work page 2023
-
[27]
Multi-agent reinforcement learning: A selective overview of theories and algorithms
Kaiqing Zhang, Zhuoran Yang, and Tamer Ba s ar. Multi-agent reinforcement learning: A selective overview of theories and algorithms. In Kyriakos G. Vamvoudakis, Yan Wan, Frank L. Lewis, and Derya Cansever, editors, Handbook of Reinforcement Learning and Control, volume 325 of Studies in Systems, Decision and Control, pages 321--384. Springer, 2021. doi:10...
-
[28]
Unlocking the power of multi-agent LLM for reasoning: From lazy agents to deliberation, 2025
Zhiwei Zhang, Xiaomin Li, Yudi Lin, Hui Liu, Ramraj Chandradevan, Linlin Wu, Minhua Lin, Fali Wang, Xianfeng Tang, Qi He, and Suhang Wang. Unlocking the power of multi-agent LLM for reasoning: From lazy agents to deliberation, 2025
work page 2025
-
[29]
Stronger-MAS : Multi-agent reinforcement learning for collaborative LLM s, 2025
Yujie Zhao, Lanxiang Hu, Yang Wang, Minmin Hou, Hao Zhang, Ke Ding, and Jishen Zhao. Stronger-MAS : Multi-agent reinforcement learning for collaborative LLM s, 2025
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.