Recognition: unknown
Screen Before You Interpret: A Portable Validity Protocol for Benchmark-Based LLM Confidence Signals
Pith reviewed 2026-05-10 04:54 UTC · model grok-4.3
The pith
LLM confidence signals must be screened with adapted clinical validity indices before use, since only valid-profile models show positive correlation with actual accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Transferring the validity screening principle from clinical personality assessment yields a portable protocol that computes indices L, Fp, RBS, TRIN, and an item-sensitivity statistic from a single 2x2 contingency table. This classifies LLM confidence profiles into Invalid, Indeterminate, and Valid tiers. Valid-profile models exhibit a mean correlation of .18 with item correctness (15/16 significant), whereas invalid-profile models show a mean correlation of -.20 (d = 2.48). Cross-benchmark validation on 18 models using MMLU with verbalized confidence and external data confirms the classification transfers across benchmarks and probe formats.
What carries the argument
The 2x2 contingency table protocol that derives clinical-style indices L, Fp, RBS, TRIN, and item-sensitivity statistic to classify whether an LLM's confidence signal carries item-level information about correctness.
If this is right
- Only models passing the screen should be trusted for abstention, routing, or safety-critical decisions that rely on confidence.
- Invalid-profile models require their confidence signals to be discarded or heavily discounted.
- The protocol can be applied to any benchmark that supplies both correctness labels and confidence values without collecting extra data.
- The classification remains stable when switching between multiple-choice and verbalized confidence formats.
- The screen supports routine pre-deployment checks for any frontier model before confidence-based features are enabled.
Where Pith is reading between the lines
- Production systems could run this screen automatically on candidate models to decide whether to expose or suppress their confidence outputs.
- The negative correlations in invalid profiles point to systematic overconfidence patterns that may warrant targeted mitigation techniques.
- Similar contingency-table screening could be tested on other LLM outputs such as generated explanations or uncertainty estimates.
- If the screen generalizes to open-ended tasks, it could reduce over-reliance on unreliable confidence in agentic or multi-step workflows.
Load-bearing premise
The clinical validity indices and item-sensitivity statistic, when computed from LLM benchmark contingency tables, validly indicate the presence of item-level information in the confidence signals.
What would settle it
A new benchmark where models classified Valid show no positive correlation with accuracy or where models classified Invalid show positive item-level correlation in their confidence signals.
Figures





read the original abstract
LLM confidence signals are used for abstention, routing, and safety-critical decisions. No standard practice exists for checking whether a confidence signal carries item-level information before building on it. We transfer the validity screening principle from clinical personality assessment (PAI, MMPI-3) as a portable protocol for benchmark-based LLM confidence data. The protocol specifies three core indices (L, Fp, RBS), a structural indicator (TRIN), and an item-sensitivity statistic, computed from a single 2x2 contingency table. A three-tier classification system (Invalid, Indeterminate, Valid) draws on four clinical traditions. Validated on 20 frontier LLMs across 524 items, four models are classified Invalid, two Indeterminate. Valid-profile models show mean r = .18 (15/16 significant). Invalid-profile models show mean r = -.20 (d = 2.48). Cross-benchmark validation on 18 models using MMLU with verbalized confidence and on external data from Yang et al. (2024) confirms the screen transfers across benchmarks and probe formats. All data and code: https://github.com/synthiumjp/validity-scaling-llm
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a portable validity protocol for assessing whether LLM confidence signals on benchmark items carry item-level information. Adapted from clinical personality assessment (e.g., PAI, MMPI-3), the protocol computes three core indices (L, Fp, RBS), a structural indicator (TRIN), and an item-sensitivity statistic from a single 2x2 contingency table of (correct/incorrect × high/low confidence). Models are classified into Valid, Indeterminate, or Invalid profiles using a three-tier system. Empirical results on 20 frontier LLMs across 524 items show valid-profile models with mean r = 0.18 (15/16 significant) between confidence and accuracy, invalid-profile with mean r = -0.20 (d = 2.48). Cross-validation on MMLU with verbalized confidence and external data from Yang et al. (2024) supports transferability, with code and data publicly available.
Significance. If the protocol's indices indeed screen for genuine item-level informativeness in confidence signals, this would fill an important gap in LLM evaluation by providing a standardized pre-use check for applications involving abstention or safety. The clear separation in correlations, large effect size, and successful cross-benchmark and cross-probe validation indicate practical value. The provision of open code and data is a strength that facilitates community scrutiny and extension.
major comments (2)
- The transfer of clinical validity indices (L, Fp, RBS, TRIN) to LLM 2x2 contingency tables is central to the claim, but the manuscript lacks a dedicated validation (e.g., via simulation with controlled item sensitivity or comparison to direct measures of per-item information) to confirm these indices isolate item-level confidence informativeness rather than capturing overall calibration, accuracy levels, or response biases. This is load-bearing as the subsequent r differences may be tautological with the classification criteria.
- Only four models are classified as Invalid out of 20, and the mean r = -0.20 for this group drives the d = 2.48 effect; the paper should report the specific models in each category, individual r values, and a sensitivity analysis to threshold choices to ensure the separation is robust and not driven by a few outliers or post-hoc decisions.
minor comments (2)
- The total number of valid-profile models is implied as 16 but not explicitly stated; clarify the breakdown (e.g., 14 valid, 2 indeterminate, 4 invalid) for precision.
- The GitHub link is provided, but the manuscript should include a brief description of the repository contents and any requirements for reproducing the 524-item analysis.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review. The comments raise important points about validation and transparency that we address below, with proposed revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: The transfer of clinical validity indices (L, Fp, RBS, TRIN) to LLM 2x2 contingency tables is central to the claim, but the manuscript lacks a dedicated validation (e.g., via simulation with controlled item sensitivity or comparison to direct measures of per-item information) to confirm these indices isolate item-level confidence informativeness rather than capturing overall calibration, accuracy levels, or response biases. This is load-bearing as the subsequent r differences may be tautological with the classification criteria.
Authors: We agree that dedicated validation of the index transfer is valuable to confirm isolation of item-level informativeness. The indices follow clinical precedents for detecting atypical response patterns (e.g., over-reporting or inconsistency) that are designed to be distinct from substantive scales. The observed r separation is not tautological, as classification integrates multiple indices (L, Fp, RBS, TRIN) rather than the correlation itself. To directly address the concern, we will add a simulation study in the revised manuscript: synthetic 2x2 tables will be generated with controlled item sensitivity (varying association strength/direction while fixing marginals and biases), the protocol applied, and results compared against direct measures such as mutual information and phi coefficient. This will appear as a new subsection in Results. revision: yes
-
Referee: Only four models are classified as Invalid out of 20, and the mean r = -0.20 for this group drives the d = 2.48 effect; the paper should report the specific models in each category, individual r values, and a sensitivity analysis to threshold choices to ensure the separation is robust and not driven by a few outliers or post-hoc decisions.
Authors: We agree that additional granularity and robustness checks will improve transparency. In the revised manuscript we will add a table (main text or appendix) listing all 20 models with their profile classification, individual validity index values, and per-model Pearson r between confidence and accuracy. We will also include a sensitivity analysis varying index thresholds and classification cutoffs (within ranges informed by the clinical literature) to confirm that the mean r separation and effect size (d = 2.48) remain stable and are not driven by outliers or specific threshold choices. revision: yes
Circularity Check
No significant circularity: indices computed directly from empirical 2x2 tables without self-referential reduction
full rationale
The paper's protocol transfers established clinical validity indices (L, Fp, RBS, TRIN) and an item-sensitivity statistic to LLM data by direct computation from single 2x2 contingency tables of (correct/incorrect × high/low confidence) across benchmark items. Classification into Invalid/Indeterminate/Valid profiles follows from these empirical counts and thresholds drawn from four clinical traditions, with no parameter fitting, ansatz smuggling, or definitional equivalence to the reported mean r values. The separation (valid r = .18 vs invalid r = -.20) is presented as an observed outcome of applying the screen, not an input or constructed identity. Cross-benchmark checks on MMLU and Yang et al. (2024) data are external to the original tables and do not rely on self-citation chains. No load-bearing step reduces by construction to its own inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- Classification thresholds for L, Fp, RBS, TRIN
axioms (1)
- domain assumption Clinical personality assessment validity indices (L, Fp, RBS, TRIN) transfer directly to LLM confidence signals computed from 2x2 contingency tables without substantial domain-specific recalibration.
Forward citations
Cited by 1 Pith paper
-
Verbal Confidence Saturation in 3-9B Open-Weight Instruction-Tuned LLMs: A Pre-Registered Psychometric Validity Screen
Seven 3-9B instruction-tuned LLMs produce verbal confidence that saturates at high values and fails psychometric validity criteria for Type-2 discrimination under minimal elicitation.
Reference graph
Works this paper leans on
-
[1]
A two-stage protocol architecture (Stage A: validity screening; Stage B: substantive analysis) grounded in the MMPI-3/PAI interpretation sequence. 4
-
[2]
A minimal index set (L, Fp, RBS, plus TRIN as structural indicator and r(confidence, correct) as diagnostic statistic) computable from a single correctness-by-confidence contingency table
-
[3]
A three-tier classification system (Invalid / Indeterminate / Valid) grounded in four clinical assess- ment traditions
-
[4]
Subsampling analysis establishing stability characteristics across item counts and error frequen- cies
-
[5]
Failure-mode demonstration showing that unscreened invalid models produce misleading down- stream metrics
-
[6]
A minimal reporting table (VRS Table) for standardised validity reporting
-
[7]
arXiv preprint arXiv:2603.09309 (2026)
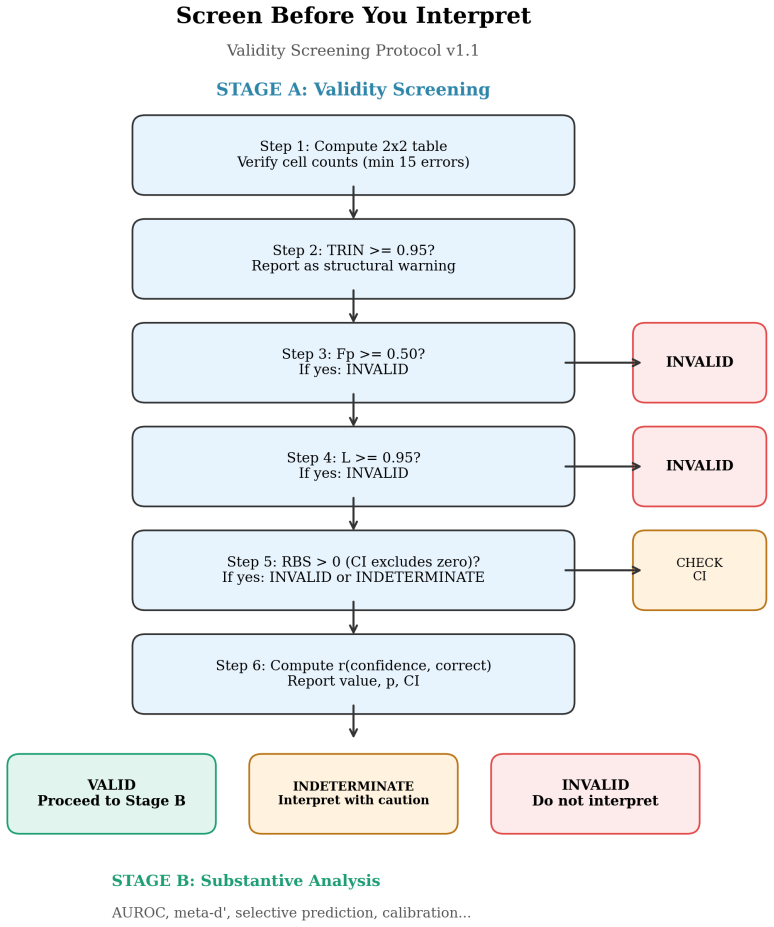
Explicit guidance on cross-family comparison and training-regime equivalence. 2 The Protocol 2.1 Two-stage architecture Stage A: Validity Screening.Is the confidence signal non-degenerate and item-informative? Compute validity indices. Apply tiered thresholds. Report the VRS Table. Stage B: Substantive Analysis.Only if Stage A classifies the signal as Val...
-
[8]
Check cell counts >= 5
Compute 2x2 table. Check cell counts >= 5
-
[9]
Note if >= 0.95 (structural warning, not a flag)
TRIN = max(n_high, n_low) / N Report value. Note if >= 0.95 (structural warning, not a flag)
-
[10]
Fp = P(low confidence | correct) Invalid if >= 0.50 (with Wilson CI lower bound > 0.40)
-
[11]
L = P(high confidence | incorrect) Invalid if >= 0.95 (with Wilson CI lower bound > 0.90)
-
[12]
RBS = Fp - (1 - L) If > 0: Invalid if CI excludes zero; Indeterminate if CI includes zero
-
[13]
THREE-TIER CLASSIFICATION - Invalid: Clear threshold violation, narrow CI
r(confidence, correct) = point-biserial Report value, p, 95\% CI. THREE-TIER CLASSIFICATION - Invalid: Clear threshold violation, narrow CI. Do not interpret Stage B. - Indeterminate: Near threshold, wide CI. Stage B with caution + flags. - Valid: No flags. Proceed to Stage B. REPORT - Complete VRS Table (Section 2.8) for every model. - Include VRS Table ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.