Recognition: unknown
Copy-as-Decode: Grammar-Constrained Parallel Prefill for LLM Editing
Pith reviewed 2026-05-10 04:39 UTC · model grok-4.3
The pith
Copy-as-Decode recasts LLM editing as grammar-constrained decoding that copies input spans via single-step parallel prefill instead of full autoregressive regeneration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
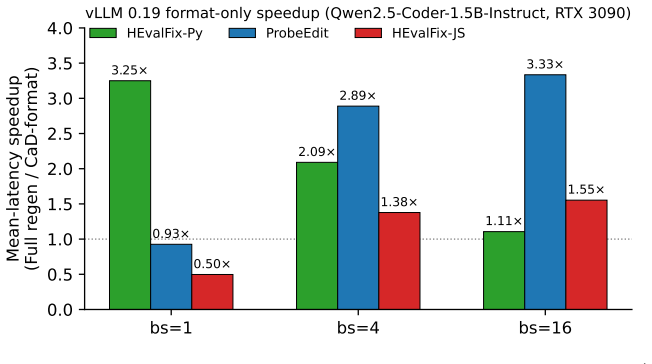
Editing generation reduces to structured decoding over the grammar with primitives <copy lines=i-j/> and <gen>...</gen>; a deterministic resolver executes copy spans by one parallel-prefill KV-cache update rather than N autoregressive steps, yielding kernel speedups of 6.8x-303x on Qwen2.5 models and closed-form wall-clock bounds of 29.0x/3.4x/4.2x (13.0x pooled) when composed with each corpus's span histogram, while guaranteeing 100 percent exact-match round-trip on 482 oracle programs.
What carries the argument
Grammar-constrained FSM decoder paired with parallel-prefill copy primitive that updates the KV cache for input spans in a single forward pass.
If this is right
- Kernel-level copying of N tokens via parallel prefill is 6.8x-303x faster than autoregressive decoding for N between 8 and 512 tokens on Qwen2.5-1.5B and 7B models.
- Line-level grammar reaches 74-98 percent of gold tokens on the evaluated code-edit corpora, composing with span histograms to the stated wall-clock bounds.
- Token-level extension of the primitive lifts coverage to 91-99 percent with speed floors of 4.5x-6.5x.
- Oracle programs achieve exact round-trip on all 482 cases, confining downstream failure exclusively to span selection.
- A fine-tuning pilot on Qwen2.5-Coder-1.5B raises exact match from 0/33 to 12-17 percent on one fix dataset, indicating span selection is learnable.
Where Pith is reading between the lines
- The single-step copy primitive could be combined with existing speculative-decoding infrastructure to allow hybrid draft-and-accept pipelines that mix copied spans with generated continuations.
- Extending the grammar to cross-file references would enable multi-file editing without separate context windows.
- Attention patterns or retrieval modules could be trained to propose the copy ranges directly, turning the lossless mechanism into a practical end-to-end system.
- The same parallel-prefill copy operator might apply to retrieval-augmented generation where long passages are inserted verbatim rather than regenerated.
Load-bearing premise
That accurate copy spans can be selected at inference time, since the mechanism is lossless only with perfect spans but exact-match performance falls from 100 percent to 15.48 percent under off-by-one noise.
What would settle it
End-to-end exact-match rate on the ProbeEdit and HumanEvalPack-Fix suites when a learned span selector replaces the oracle program, compared against the reported 100 percent oracle round-trip fidelity.
Figures







read the original abstract
LLMs edit text and code by autoregressively regenerating the full output, even when most tokens appear verbatim in the input. We study Copy-as-Decode, a decoding-layer mechanism that recasts edit generation as structured decoding over a two-primitive grammar: <copy lines="i-j"/> references an input line range, <gen>...</gen> emits new content. A token-level FSM guarantees syntactic validity, and a serving-layer primitive updates the KV cache for each copy span via a single parallel-prefill forward rather than $N$ autoregressive steps -- sharing the parallel-forward kernel of speculative decoding but with input tokens as the draft and program-enforced acceptance replacing probabilistic verification. We report an upper-bound analysis that requires no end-to-end training. (i) Kernel speedup: on Qwen2.5-{1.5B, 7B}, copying $N$ tokens via parallel prefill is $6.8\times$--$303\times$ faster than autoregressive ($N \in [8, 512]$, A100 80GB bf16). (ii) Copy ceiling: on ProbeEdit and HumanEvalPack-Fix (Py/JS), $74$--$98\%$ of gold tokens are reachable under the line-level primitive; composed with the empirical kernel over each corpus's span histogram this yields a closed-form wall-clock bound of $29.0\times / 3.4\times / 4.2\times$ ($13.0\times$ pooled). A token-level extension reaches $91$--$99\%$ coverage with $4.5\times$--$6.5\times$ floors. (iii) Pipeline losslessness: oracle programs round-trip through the deterministic resolver on all $482$ cases, localizing any downstream failure to span selection rather than the mechanism. A perturbation study shows pooled EM drops from $100\%$ to $15.48\%$ under off-by-one noise. A fine-tuning pilot on Qwen2.5-Coder-1.5B lifts HEvalFix-Py EM from $0/33$ (untrained) to $12$--$17\%$, a learnability signal, not a production selector. Batched-serving integration and multi-file coverage are scoped as follow-up.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that by recasting LLM editing as grammar-constrained decoding with copy and generate primitives, and implementing copies via parallel prefill, significant speedups are possible. It supports this with direct kernel timing measurements on hardware, coverage statistics from editing benchmarks, a closed-form upper-bound calculation yielding up to 29× speedup, exhaustive proof of losslessness on 482 cases under perfect spans, and a small fine-tuning pilot showing that span selection is learnable to some degree.
Significance. If the assumption of accurate span selection holds, this technique could substantially accelerate code and text editing applications by avoiding unnecessary autoregressive steps for copied content. The use of direct measurements rather than simulations, the exhaustive oracle verification, and the parameter-free nature of the bound are notable strengths that increase confidence in the reported numbers. The work also re-purposes speculative decoding infrastructure, enhancing its practicality.
major comments (2)
- [Abstract] The wall-clock bounds of 29.0× / 3.4× / 4.2× (13.0× pooled) are presented prominently, yet they rely on the unproven ability to select accurate copy spans at inference time. The perturbation study indicates that even minor inaccuracies collapse performance to 15.48% EM, while the fine-tuning pilot only achieves 12–17% EM. This makes the bounds an idealized upper limit whose relevance depends on future progress in span selection, which should be stated more clearly to avoid overstatement.
- [Fine-tuning pilot description] The pilot experiment on Qwen2.5-Coder-1.5B is too small in scope (only 12-17% EM on one benchmark) to serve as convincing evidence that span selection is feasible at the accuracy levels required (74-98%). More details on the training procedure, data, and potential improvements would help assess whether this direction can close the gap to the oracle performance.
minor comments (2)
- The two-primitive grammar is introduced without a formal syntax definition or illustrative example early in the paper; adding this would improve accessibility.
- Ensure that all reported speedups specify the exact model variant, batch size, and precision used in the kernel measurements for full reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps clarify the scope of our upper-bound results. We address each major comment below and will revise the manuscript accordingly to avoid any potential overstatement while preserving the technical contributions.
read point-by-point responses
-
Referee: [Abstract] The wall-clock bounds of 29.0× / 3.4× / 4.2× (13.0× pooled) are presented prominently, yet they rely on the unproven ability to select accurate copy spans at inference time. The perturbation study indicates that even minor inaccuracies collapse performance to 15.48% EM, while the fine-tuning pilot only achieves 12–17% EM. This makes the bounds an idealized upper limit whose relevance depends on future progress in span selection, which should be stated more clearly to avoid overstatement.
Authors: We agree that the reported wall-clock bounds constitute an idealized upper limit under oracle span selection. The manuscript already frames the analysis as an 'upper-bound analysis that requires no end-to-end training,' reports the perturbation study showing the EM drop to 15.48%, and explicitly labels the fine-tuning result as 'a learnability signal, not a production selector.' To address the concern about prominence in the abstract, we will revise the abstract and introduction to state more explicitly that the speedups assume perfect spans and that realized gains will depend on advances in span selection. This revision will be made without altering the kernel measurements, coverage statistics, or closed-form bound derivation. revision: yes
-
Referee: [Fine-tuning pilot description] The pilot experiment on Qwen2.5-Coder-1.5B is too small in scope (only 12-17% EM on one benchmark) to serve as convincing evidence that span selection is feasible at the accuracy levels required (74-98%). More details on the training procedure, data, and potential improvements would help assess whether this direction can close the gap to the oracle performance.
Authors: We acknowledge that the pilot is limited in scope and does not reach the oracle coverage levels; its intent was solely to demonstrate that span selection is learnable from the untrained baseline of 0/33 EM rather than to provide a production system. In the revised manuscript we will expand the pilot section with additional details on the training procedure (including data construction, loss formulation, and hyperparameters), the exact benchmark split used, and a brief discussion of potential improvements such as scaling to larger models or incorporating the grammar constraints during fine-tuning. We agree that substantial further research is required to approach oracle accuracy. revision: partial
Circularity Check
Derivation chain is self-contained with no circular reductions
full rationale
The paper's central upper-bound analysis composes two independently obtained quantities: (1) direct wall-clock measurements of parallel-prefill kernel latency versus autoregressive decoding for varying N on A100 hardware, and (2) coverage fractions computed from span-length histograms on the ProbeEdit and HumanEvalPack-Fix corpora. These are multiplied to produce the closed-form speedups (29.0×/3.4×/4.2× pooled). No parameter is fitted to the final bound, no self-citation supplies a load-bearing uniqueness theorem or ansatz, and the oracle round-trip plus perturbation study are separate empirical checks of mechanism losslessness. The derivation therefore remains external to its own outputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- corpus span-length histogram
axioms (1)
- domain assumption A single parallel prefill forward pass can correctly update the KV cache for an arbitrary input-derived copy span
Reference graph
Works this paper leans on
-
[1]
Lee, Deming Chen, and Tri Dao
Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, Jason D. Lee, Deming Chen, and Tri Dao. Medusa: Simple LLM inference acceleration framework with multiple decoding heads. In Proceedings of the 41st International Conference on Machine Learning, 2024
2024
-
[2]
Can it edit? evaluating the ability of large language models to follow code editing instructions
Federico Cassano, Luisa Li, Akul Sethi, Noah Shinn, Abby Brennan-Jones, Anton Lozhkov, Carolyn Jane Anderson, and Arjun Guha. Can it edit? evaluating the ability of large language models to follow code editing instructions. InProceedings of the First Conference on Language Modeling (COLM), 2024
2024
-
[3]
Accelerating Large Language Model Decoding with Speculative Sampling
Charlie Chen, Sebastian Borgeaud, Geoffrey Irving, Jean-Baptiste Lespiau, Laurent Sifre, and John Jumper. Accelerating large language model decoding with speculative sampling.arXiv preprint arXiv:2302.01318, 2023
work page internal anchor Pith review arXiv 2023
-
[4]
Instant apply
Cursor. Instant apply. https://www.cursor.com/blog/instant-apply, 2024. Accessed: 2026-04
2024
-
[5]
Ruan, Yaxing Cai, Ruihang Lai, Ziyi Xu, Yilong Zhao, and Tianqi Chen
Yixin Dong, Charlie F. Ruan, Yaxing Cai, Ruihang Lai, Ziyi Xu, Yilong Zhao, and Tianqi Chen. XGrammar: Flexible and efficient structured generation engine for large language models. In Proceedings of Machine Learning and Systems (MLSys), 2025
2025
-
[6]
Aider: Ai pair programming in your terminal
Paul Gauthier. Aider: Ai pair programming in your terminal. 2024. Software. https: //aider.chat
2024
-
[7]
Grammar-constrained decoding for structured NLP tasks without finetuning
Saibo Geng, Martin Josifoski, Maxime Peyrard, and Robert West. Grammar-constrained decoding for structured NLP tasks without finetuning. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 2023
2023
-
[8]
Jiatao Gu, Zhengdong Lu, Hang Li, and Victor O.K. Li. Incorporating copying mechanism in sequence-to-sequence learning. InProceedings of the 54th Annual Meeting of the Association for Computational Linguistics, 2016
2016
-
[9]
Levenshtein transformer
Jiatao Gu, Changhan Wang, and Junbo Zhao. Levenshtein transformer. InAdvances in Neural Information Processing Systems, volume 32, 2019
2019
-
[10]
Lee, and Di He
Zhenyu He, Zexuan Zhong, Tianle Cai, Jason D. Lee, and Di He. REST: Retrieval-based speculative decoding. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL), 2024
2024
-
[11]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. SWE-bench: Can language models resolve real-world GitHub issues? In Proceedings of the 12th International Conference on Learning Representations (ICLR), 2024. 18
2024
-
[12]
In: Proceedings of the 29th Symposium on Operating Systems Principles
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th Symposium on Operating Systems Principles (SOSP), pages 611–626. ACM, 2023. doi: 10.1145/3600006.3613165
-
[13]
Fast inference from transformers via speculative decoding
Yaniv Leviathan, Matan Kalman, and Yossi Matias. Fast inference from transformers via speculative decoding. InProceedings of the 40th International Conference on Machine Learning, 2023
2023
-
[14]
EAGLE: Speculative sampling requires rethinking feature uncertainty
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. EAGLE: Speculative sampling requires rethinking feature uncertainty. InProceedings of the 41st International Conference on Machine Learning (ICML), 2024
2024
-
[15]
EAGLE-2: Faster inference of language models with dynamic draft trees
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. EAGLE-2: Faster inference of language models with dynamic draft trees. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2024
2024
-
[16]
Line numbers and context references: Serving-layer techniques for short-document LLM editing, 2026
Ziyang Liu. Line numbers and context references: Serving-layer techniques for short-document LLM editing, 2026. Prior preprint, superseded by this work
2026
-
[17]
Felix: Flexible text editing through tagging and insertion
Jonathan Mallinson, Aliaksei Severyn, Eric Malmi, and Guillermo Garrido. Felix: Flexible text editing through tagging and insertion. InFindings of the Association for Computational Linguistics: EMNLP 2020, 2020
2020
-
[18]
Encode, tag, realize: High-precision text editing
Eric Malmi, Sebastian Krause, Sascha Rothe, Daniil Mirylenka, and Aliaksei Severyn. Encode, tag, realize: High-precision text editing. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing, 2019
2019
-
[19]
SpecInfer: Accelerating large language model serving with tree-based speculative inference and verification
Xupeng Miao, Gabriele Oliaro, Zhihao Zhang, Xinhao Cheng, Zeyu Wang, Zhengxin Yang, Binghao Zhuang, Xuanye Shi, Chunan Jin, Zhihao Wu, and Zhihao Jia. SpecInfer: Accelerating large language model serving with tree-based speculative inference and verification. InPro- ceedings of the 29th ACM International Conference on Architectural Support for Programming...
2024
-
[20]
OctoPack: Instruction tuning code large language models
Niklas Muennighoff, Qian Liu, Armel Zebaze, Qinkai Zheng, Binyuan Hui, Terry Yue Zhuo, Swayam Singh, Xiangru Tang, Leandro von Werra, and Shayne Longpre. OctoPack: Instruction tuning code large language models. InProceedings of the International Conference on Learning Representations, 2024
2024
-
[21]
GECToR – grammatical error correction: Tag, not rewrite
Kostiantyn Omelianchuk, Vitaliy Atrasevych, Artem Chernodub, and Oleksandr Skurzhanskyi. GECToR – grammatical error correction: Tag, not rewrite. InProceedings of the Fifteenth Workshop on Innovative Use of NLP for Building Educational Applications, 2020
2020
-
[22]
Prompt lookup decoding, 2023
Apoorv Saxena. Prompt lookup decoding, 2023. URL https://github.com/apoorvumang/ prompt-lookup-decoding. GitHub repository
2023
-
[23]
PICARD: Parsing incrementally for constrained auto-regressive decoding from language models
Torsten Scholak, Nathan Schucher, and Dzmitry Bahdanau. PICARD: Parsing incrementally for constrained auto-regressive decoding from language models. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 2021
2021
-
[24]
Liu, and Christopher D
Abigail See, Peter J. Liu, and Christopher D. Manning. Get to the point: Summarization with pointer-generator networks. InProceedings of the 55th Annual Meeting of the Association for Computational Linguistics, 2017
2017
-
[25]
Blockwise parallel decoding for deep autoregressive models
Mitchell Stern, Noam Shazeer, and Jakob Uszkoreit. Blockwise parallel decoding for deep autoregressive models. InAdvances in Neural Information Processing Systems, 2018
2018
-
[26]
Pointer networks
Oriol Vinyals, Meire Fortunato, and Navdeep Jaitly. Pointer networks. InAdvances in Neural Information Processing Systems, volume 28, 2015
2015
-
[27]
Efficient Guided Generation for Large Language Models
Brandon T. Willard and Rémi Louf. Efficient guided generation for large language models. arXiv preprint arXiv:2307.09702, 2023
work page internal anchor Pith review arXiv 2023
-
[28]
Speculative decoding: Exploiting speculative execution for accelerating seq2seq generation
Heming Xia, Tao Ge, Peiyi Wang, Si-Qing Chen, Furu Wei, and Zhifang Sui. Speculative decoding: Exploiting speculative execution for accelerating seq2seq generation. InFindings of the Association for Computational Linguistics: EMNLP 2023, 2023
2023
-
[29]
Yang, S., Huang, S., Dai, X., and Chen, J
Sen Yang, Shujian Huang, Xinyu Dai, and Jiajun Chen. Multi-candidate speculative decoding. arXiv preprint arXiv:2401.06706, 2024. 19
-
[30]
Draft & verify: Lossless large language model acceleration via self-speculative decoding
Jun Zhang, Jue Wang, Huan Li, Lidan Shou, Ke Chen, Gang Chen, and Sharad Mehrotra. Draft & verify: Lossless large language model acceleration via self-speculative decoding. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, 2024
2024
-
[31]
<" LT_SLASH = 522 #
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark Barrett, and Ying Sheng. SGLang: Efficient execution of structured language model programs. InAdvances in Neural Information Processing Systems (NeurIPS), 2024. A FSM and Tokenizer Figure 7:Grammar-enforcin...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.