Recognition: unknown
Correction and Corruption: A Two-Rate View of Error Flow in LLM Protocols
Pith reviewed 2026-05-10 04:52 UTC · model grok-4.3
The pith
LLM protocol steps can be audited and composed by tracking separate rates for fixing errors and breaking correct answers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose a paired-outcome measurement interface for auditing a single protocol step on exact-match tasks. For each instance, the interface records a baseline correctness bit E0 and a post-step correctness bit E1, separating correction from corruption through two rates: c equal to the probability that E1 equals 1 given E0 equals 0, and γ equal to the probability that E1 equals 0 given E0 equals 1. These rates predict accuracy changes and define a reusable empirical interface testable across seeds, mixtures, and pipelines. Under mixture shift the pooled estimates become biased, but conditioning on a difficulty proxy restores stability. Under state insufficiency a Markov factorization test is
What carries the argument
The paired correctness bits E0 and E1 that produce the correction rate c and corruption rate γ for auditing and composing each protocol step.
If this is right
- Net accuracy after one step equals initial accuracy plus c times the initial error fraction minus γ times the initial accuracy.
- A step is activated only when its estimated gain from c and γ is positive.
- Conditioning the rates on a difficulty proxy removes bias from changes in the proportion of hard versus easy problems.
- A Markov test on the correctness sequence identifies when additional state is needed for reliable multi-step composition.
- Steps that pass the diagnostics form auditable modules whose total accuracy in a pipeline is the product of the individual rate effects.
Where Pith is reading between the lines
- The same paired measurement could be applied to non-exact-match tasks by replacing the binary bits with graded correctness scores.
- Protocol designers could search for new steps that improve the pair (c, γ) on a validation set before deployment.
- In production the rates could be re-estimated periodically on recent traffic to decide whether to keep or drop a step.
Load-bearing premise
The binary correctness bits before and after a step carry enough history to keep the rates stable and transferable across mixtures and pipeline positions without extra state.
What would settle it
Measure actual accuracy change on a held-out mixture or multi-step pipeline and compare it to the change predicted from the estimated c and γ; any systematic mismatch shows the rates do not transfer.
Figures











read the original abstract
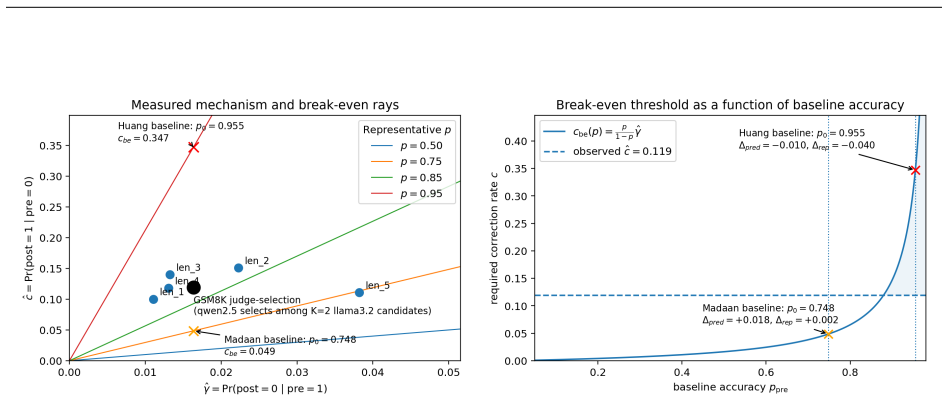
Large language models are increasingly deployed as protocols: structured multi-call procedures that spend additional computation to transform a baseline answer into a final one. These protocols are evaluated only by end-to-end accuracy, giving limited insight into when they help, when they hurt, and whether their behavior transfers under distribution shift or composition. We propose a paired-outcome measurement interface for auditing a single protocol step on exact-match tasks. For each instance, the interface records a baseline correctness bit $E_0\in\{0,1\}$ and a post-step correctness bit $E_1\in\{0,1\}$, separating correction ($E_0=0\to E_1=1$) from corruption ($E_0=1\to E_1=0$) through two rates: $c=\Pr(E_1=1\mid E_0=0)$ and $\gamma=\Pr(E_1=0\mid E_0=1)$. These rates predict accuracy changes and define a reusable empirical interface testable across seeds, mixtures, and pipelines. We identify three failure mechanisms. Under mixture shift, pooled estimates of $(c,\gamma)$ become biased when calibration and deployment mixtures differ; conditioning on a difficulty proxy restores stability without additional model calls. Under presentation contamination, selection protocols alter the interface through stable presentation artifacts when candidate content is fixed. Under state insufficiency, the correctness bit may not carry enough history for multi-step pipelines to compose predictably; a Markov factorization test identifies when composition is valid and where additional state is needed. When a protocol step passes these diagnostics, it becomes an auditable module: gated by estimated gain, conditioned on a difficulty proxy to correct mixture bias, and composed into multi-step pipelines with predictable accuracy. We demonstrate these ideas on synthetic mathematical tasks and on GSM8K, where the calibrated interface correctly predicts when protocol steps should be activated or suppressed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a paired-outcome interface for auditing individual steps in LLM protocols on exact-match tasks. For each instance it records baseline correctness E0 and post-step correctness E1, defines correction rate c = Pr(E1=1 | E0=0) and corruption rate γ = Pr(E1=0 | E0=1), and claims these rates predict accuracy changes, identify three failure modes (mixture shift, presentation contamination, state insufficiency), and enable gated, conditioned, and composable protocol modules. The approach is demonstrated on synthetic mathematical tasks and GSM8K, where the calibrated rates correctly indicate when steps should be activated or suppressed.
Significance. If the rates prove stable under the proposed diagnostics, the work supplies a concrete empirical interface for decomposing protocol behavior beyond end-to-end accuracy. It explicitly credits the reusable measurement of (c, γ), the difficulty-proxy correction for mixture bias, and the Markov factorization test for composition validity as practical contributions that could support modular, auditable LLM pipelines.
major comments (2)
- [Abstract and §2] Abstract and §2 (interface definition): the claim that the rates 'predict accuracy changes' is a direct algebraic consequence of the law of total probability, p1 = p0(1-γ) + (1-p0)c. The manuscript should state this identity explicitly and separate it from the independent empirical claims (stability of (c, γ) across seeds and mixtures, transfer to GSM8K).
- [State insufficiency section] Section on state insufficiency (high-level description of Markov test): the test is presented without an explicit factorization equation (e.g., the precise condition Pr(Ek | E_{k-1}) = Pr(Ek | E_{k-1}, E_{k-2}, …)) or implementation details such as the number of steps used for validation or the statistical threshold. Because the multi-step composition claim rests on E0/E1 being a sufficient statistic, this omission is load-bearing.
minor comments (2)
- [Notation] Notation for c and γ should be introduced once and used uniformly in all equations, tables, and figure captions.
- [Experiments] GSM8K experiments would be strengthened by reporting standard errors or bootstrap intervals on the estimated rates to quantify stability across random seeds.
Simulated Author's Rebuttal
We thank the referee for the constructive and precise comments. We address each major point below, agreeing on the need for explicit separation and additional formalization, and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and §2] Abstract and §2 (interface definition): the claim that the rates 'predict accuracy changes' is a direct algebraic consequence of the law of total probability, p1 = p0(1-γ) + (1-p0)c. The manuscript should state this identity explicitly and separate it from the independent empirical claims (stability of (c, γ) across seeds and mixtures, transfer to GSM8K).
Authors: We agree that the accuracy prediction p₁ = p₀(1 - γ) + (1 - p₀)c follows directly from the law of total probability and is not itself an empirical result. In the revision we will insert this identity explicitly in §2, label it as an algebraic identity, and clearly demarcate it from the subsequent empirical claims concerning stability of (c, γ) across seeds and mixtures as well as transfer to GSM8K. revision: yes
-
Referee: [State insufficiency section] Section on state insufficiency (high-level description of Markov test): the test is presented without an explicit factorization equation (e.g., the precise condition Pr(Ek | E_{k-1}) = Pr(Ek | E_{k-1}, E_{k-2}, …)) or implementation details such as the number of steps used for validation or the statistical threshold. Because the multi-step composition claim rests on E0/E1 being a sufficient statistic, this omission is load-bearing.
Authors: We accept that the current high-level description of the Markov factorization test omits the explicit conditional-independence equation and the concrete validation parameters. The revised section will state the precise Markov condition Pr(E_k | E_{k-1}, …, E_0) = Pr(E_k | E_{k-1}), specify that validation is performed on sequences of up to four steps, and report the statistical threshold (likelihood-ratio test at α = 0.05) used to accept or reject the factorization. These additions will make the test fully specified and directly support the composition claims. revision: yes
Circularity Check
Accuracy 'prediction' via (c, γ) is definitional by total probability
specific steps
-
fitted input called prediction
[Abstract]
"These rates predict accuracy changes and define a reusable empirical interface testable across seeds, mixtures, and pipelines."
Let p = Pr(E0=1). Then Pr(E1=1) = c(1-p) + (1-γ)p exactly. Measuring c and γ from the same paired (E0, E1) outcomes therefore determines the accuracy change by algebraic identity; the 'prediction' is a tautological reparameterization rather than an independent forecast.
full rationale
The paper's central claim that the rates predict accuracy changes reduces directly to a re-expression of the observed paired correctness bits. By construction, post-step accuracy equals c(1-p) + (1-γ)p, so the claimed predictive interface adds no independent empirical content beyond the measurements themselves. This matches the fitted-input-called-prediction pattern. The remainder of the work (mixture conditioning, Markov test, gating) builds on this interface but does not escape the definitional core for the accuracy-prediction claim. No self-citations or other load-bearing circular steps appear in the provided text.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Binary correctness bits E0 and E1 are sufficient statistics for a protocol step's effect on accuracy.
- domain assumption A Markov factorization test can identify when composition is valid without additional state.
invented entities (1)
-
Correction rate c and corruption rate γ
no independent evidence
Reference graph
Works this paper leans on
-
[2]
Constitutional AI: Harmlessness from AI Feedback
URLhttps://arxiv.org/abs/2212.08073. Karl Cobbe, Vineet Kosaraju, et al. Training Verifiers to Solve Math Word Problems. arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Training Verifiers to Solve Math Word Problems
URLhttps://arxiv.org/abs/2110.14168. David Dohan, Winnie Xu, et al. Language Model Cascades. arXiv preprint arXiv:2207.10342,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
arXiv preprint arXiv:2207.10342 , year=
URL https://arxiv.org/abs/2207.10342. Yilun Du, Shuang Li, et al. Improving Factuality and Reasoning in Language Models through Multiagent Debate. InProceedings of the 41st International Conference on Machine Learning, pp. 11733–11763,
-
[5]
Clémentine Fourrier, Nathan Habib, et al
URLhttps://proceedings.neurips.cc/paper_files/paper/2023/file/ deb3c28192f979302c157cb653c15e90-Paper-Conference.pdf. Clémentine Fourrier, Nathan Habib, et al. Open LLM Leaderboard v2.https://huggingface.co/spaces/ open-llm-leaderboard/open_llm_leaderboard,
2023
-
[6]
Jie Huang, Xinyun Chen, et al
URLhttps://proceedings.neurips.cc/paper_files/ paper/2017/file/4a8423d5e91fda00bb7e46540e2b0cf1-Paper.pdf. Jie Huang, Xinyun Chen, et al. Large Language Models Cannot Self-Correct Reasoning Yet. InThe Twelfth International Conference on Learning Representations (ICLR),
2017
-
[7]
When can LLMs actually correct their own mistakes? A survey of self-correction
doi: 10.1162/tacl_a_00713. URLhttps://aclanthology.org/2024.tacl-1.78/. Hunter Lightman, Vineet Kosaraju, et al. Let’s Verify Step by Step. InThe Twelfth International Conference on Learning Representations (ICLR),
-
[9]
Solving a million-step LLM task with zero errors.arXiv preprint arXiv:2511.09030, 2025
URLhttps://arxiv.org/abs/2511.09030. OpenAI, Josh Achiam, Steven Adler, et al. GPT-4 Technical Report, 2024a. URLhttps://arxiv.org/ abs/2303.08774. OpenAI, Aaron Hurst, Adam Lerer, et al. GPT-4o System Card, 2024b. URLhttps://arxiv.org/abs/ 2410.21276. Ethan Perez, Saffron Huang, et al. Red Teaming Language Models with Language Models. InProceedings of th...
-
[10]
Joaquin Quiñonero-Candela, Masashi Sugiyama, et al
URLhttps://aclanthology.org/2022.emnlp-main.225.pdf. Joaquin Quiñonero-Candela, Masashi Sugiyama, et al. (eds.).Dataset Shift in Machine Learning. MIT Press, Cambridge, MA,
2022
-
[11]
Masashi Sugiyama and Motoaki Kawanabe.Machine Learning in Non-Stationary Environments: Introduc- tion to Covariate Shift Adaptation
URLhttps://proceedings.neurips.cc/ paper_files/paper/2023/file/1b44b878bb782e6954cd888628510e90-Paper-Conference.pdf. Masashi Sugiyama and Motoaki Kawanabe.Machine Learning in Non-Stationary Environments: Introduc- tion to Covariate Shift Adaptation. MIT Press, Cambridge, MA,
2023
-
[12]
InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
Association for Computational Linguistics. doi: 10.18653/v1/ 2024.acl-long.511. URLhttps://aclanthology.org/2024.acl-long.511/. Xuezhi Wang, Jason Wei, et al. Self-Consistency Improves Chain of Thought Reasoning in Language Models. InThe Eleventh International Conference on Learning Representations (ICLR),
-
[13]
Shunyu Yao, Dian Yu, et al
URLhttps://proceedings.neurips.cc/ paper_files/paper/2022/file/9d5609613524ecf4f15af0f7b31abca4-Paper-Conference.pdf. Shunyu Yao, Dian Yu, et al. Tree of Thoughts: Deliberate Problem Solving with Large Language Models. In A. Oh, T. Naumann, et al. (eds.),Advances in Neural Information Processing Systems (NeurIPS), volume 36, pp. 11809–11822. Curran Associ...
2022
-
[14]
URLhttps://proceedings.neurips.cc/paper_files/paper/2023/file/ 91f18a1287b398d378ef22505bf41832-Paper-Datasets_and_Benchmarks.pdf. 35 A Estimation details, Jeffreys smoothing, and prediction Jeffreys-smoothed estimators for(c,γ), posterior credible intervals, one-step and mixture predictions, oracle headroom forjudge-K, and uncertainty propagation are spe...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.