Recognition: unknown
A Note on TurboQuant and the Earlier DRIVE/EDEN Line of Work
Pith reviewed 2026-05-10 05:09 UTC · model grok-4.3
The pith
TurboQuant_mse is a special case of EDEN with fixed scale S=1, and TurboQuant_prod is suboptimal to direct EDEN quantization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
EDEN extends the earlier DRIVE scheme to any number of bits per coordinate and optimizes a scalar scale parameter S separately for biased and unbiased quantization modes. TurboQuant_mse is obtained by fixing that S to one, a choice that is generally suboptimal though it becomes close to optimal for large dimensions. TurboQuant_prod applies a biased (b-1)-bit step with S=1 followed by an unbiased one-bit residual quantizer that itself has higher error than one-bit EDEN; this chaining is inferior to unbiased b-bit EDEN applied directly to the input. The note also observes that some analysis in TurboQuant overlaps with EDEN, including the link between random rotations and the shifted Beta分布, as
What carries the argument
EDEN's scalar scale parameter S, which is chosen via Lloyd-Max optimization to minimize mean squared error for either biased or unbiased quantization.
If this is right
- Biased EDEN with its optimized S achieves lower error than TurboQuant_mse.
- Unbiased EDEN achieves lower error than TurboQuant_prod, often equivalent to more than one additional bit.
- Randomized Hadamard transforms can replace uniform random rotations in both EDEN and TurboQuant.
- The optimal S for biased EDEN approaches one as the dimension grows large.
Where Pith is reading between the lines
- Future quantizer designs should prioritize tuning the scale parameter over fixing it at one.
- The shared analytical connection to the shifted Beta distribution indicates this tool is becoming standard for analyzing high-dimensional quantization error.
- Practitioners could improve results from TurboQuant-style code by switching to EDEN's parameter selection rather than adopting the fixed-S restriction.
Load-bearing premise
Re-implementations of EDEN match the performance originally reported and that experimental setups allow direct comparison without hidden differences.
What would settle it
A controlled test in which TurboQuant_prod achieves strictly lower mean squared error than unbiased b-bit EDEN on identical inputs and total bit budget would falsify the suboptimality claim.
Figures







read the original abstract
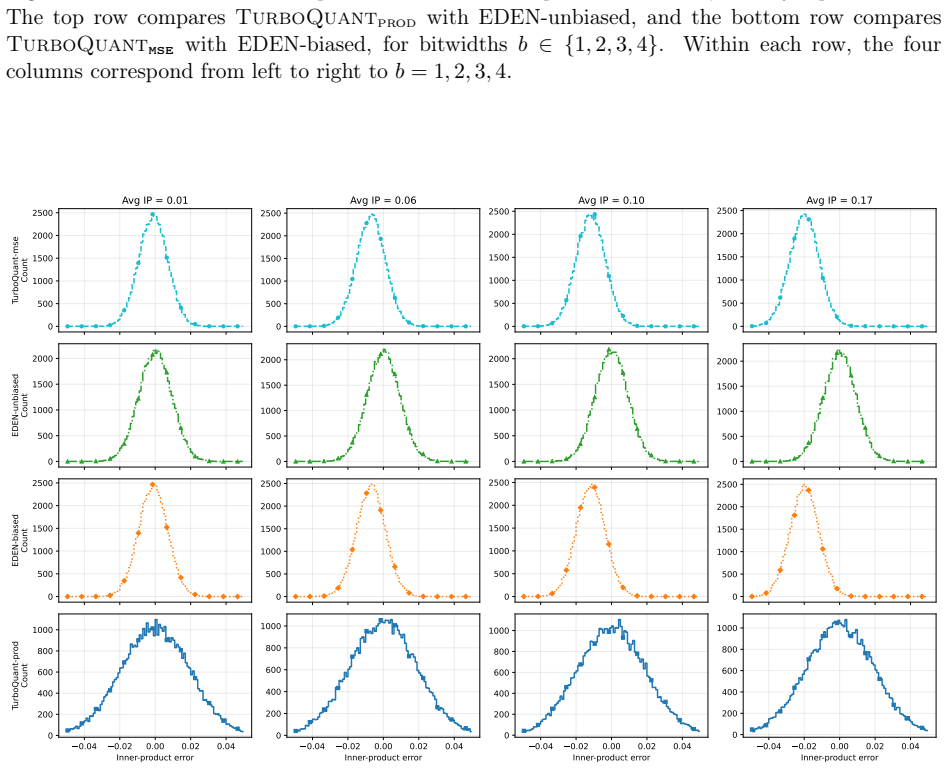
This note clarifies the relationship between the recent TurboQuant work and the earlier DRIVE (NeurIPS 2021) and EDEN (ICML 2022) schemes. DRIVE is a 1-bit quantizer that EDEN extended to any $b>0$ bits per coordinate; we refer to them collectively as EDEN. First, TurboQuant$_{\text{mse}}$ is a special case of EDEN obtained by fixing EDEN's scalar scale parameter to $S=1$. EDEN supports both biased and unbiased quantization, each optimized by a different $S$ (chosen via methods described in the EDEN works). The fixed choice $S=1$ used by TurboQuant is generally suboptimal, although the optimal $S$ for biased EDEN converges to $1$ as the dimension grows; accordingly TurboQuant$_{\text{mse}}$ approaches EDEN's behavior for large $d$. Second, TurboQuant$_{\text{prod}}$ combines a biased $(b-1)$-bit EDEN step with an unbiased 1-bit QJL quantization of the residual. It is suboptimal in three ways: (1) its $(b-1)$-bit step uses the suboptimal $S=1$; (2) its 1-bit unbiased residual quantization has worse MSE than (unbiased) 1-bit EDEN; (3) chaining a biased $(b-1)$-bit step with a 1-bit unbiased residual step is inferior to unbiasedly quantizing the input directly with $b$-bit EDEN. Third, some of the analysis in the TurboQuant work mirrors that of the EDEN works: both exploit the connection between random rotations and the shifted Beta distribution, use the Lloyd-Max algorithm, and note that Randomized Hadamard Transforms can replace uniform random rotations. Experiments support these claims: biased EDEN (with optimized $S$) is more accurate than TurboQuant$_{\text{mse}}$, and unbiased EDEN is markedly more accurate than TurboQuant$_{\text{prod}}$, often by more than a bit (e.g., 2-bit EDEN beats 3-bit TurboQuant$_{\text{prod}}$). We also repeat all accuracy experiments from the TurboQuant paper, showing that EDEN outperforms it in every setup we have tried.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that TurboQuant_mse is a special case of EDEN obtained by fixing the scalar scale parameter S=1, that TurboQuant_prod is suboptimal in three specific ways (suboptimal S=1 in the (b-1)-bit step, inferior 1-bit residual quantization, and chaining biased/unbiased steps instead of direct unbiased b-bit quantization), that some analysis techniques (random rotations, shifted Beta distribution, Lloyd-Max, Randomized Hadamard Transforms) overlap with prior DRIVE/EDEN work, and that new experiments repeating TurboQuant setups show biased and unbiased EDEN outperforming TurboQuant_mse and TurboQuant_prod respectively, often by more than one effective bit.
Significance. This clarification note is useful for the quantization literature in machine learning, as it positions the earlier EDEN framework as more general and optimal while documenting overlaps in technique. The mathematical arguments follow directly from the scheme definitions and are parameter-free in their core claims. The repetition of prior experimental setups adds direct comparability. If the re-implementations are faithful, the note helps avoid redundant development and highlights EDEN's advantages.
major comments (1)
- Experiments section: the quantitative claims (e.g., 2-bit EDEN beating 3-bit TurboQuant_prod, and EDEN outperforming in every repeated TurboQuant setup) depend on the fidelity of the authors' EDEN re-implementation to the original DRIVE (NeurIPS 2021) and EDEN (ICML 2022) papers, including exact scale optimization for S, rotation handling, Lloyd-Max application, and residual quantization. Any deviation would undermine the empirical support for suboptimality; the manuscript should supply additional implementation details or pointers to code to allow independent verification.
minor comments (1)
- The collective reference to DRIVE and EDEN as 'EDEN' is introduced clearly in the abstract but could be reinforced with a brief reminder in the first paragraph of the main text for readers who encounter the note in isolation.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and recommendation of minor revision. We address the sole major comment below.
read point-by-point responses
-
Referee: Experiments section: the quantitative claims (e.g., 2-bit EDEN beating 3-bit TurboQuant_prod, and EDEN outperforming in every repeated TurboQuant setup) depend on the fidelity of the authors' EDEN re-implementation to the original DRIVE (NeurIPS 2021) and EDEN (ICML 2022) papers, including exact scale optimization for S, rotation handling, Lloyd-Max application, and residual quantization. Any deviation would undermine the empirical support for suboptimality; the manuscript should supply additional implementation details or pointers to code to allow independent verification.
Authors: We agree that additional details are warranted to support independent verification. In the revised manuscript we will expand the Experiments section with explicit descriptions of: (i) the scale-optimization procedure for S (following the exact method in the EDEN paper, including the closed-form expressions and numerical search ranges used), (ii) rotation implementation via Randomized Hadamard Transforms with the same seed handling as the original DRIVE/EDEN code, (iii) application of the Lloyd-Max algorithm to obtain the quantization levels and thresholds, and (iv) the precise residual computation and 1-bit QJL step used for the TurboQuant_prod baseline. We will also add a direct pointer to the public code repository containing the exact scripts that produced the reported numbers. revision: yes
Circularity Check
No significant circularity; claims rest on explicit formulation comparison and new experiments against independently published baselines.
full rationale
The note states that TurboQuant_mse is EDEN with S fixed to 1 and lists three explicit suboptimality reasons for TurboQuant_prod (suboptimal S=1, inferior 1-bit residual, and biased+unbiased chaining vs direct unbiased b-bit). These are presented as direct consequences of the method definitions rather than derived from fitted parameters or self-citation alone. Experiments are newly run by repeating TurboQuant setups and comparing against the authors' re-implementation of the prior DRIVE/EDEN methods (NeurIPS 2021, ICML 2022). Because the baseline methods are externally published and the note supplies independent analysis plus fresh empirical comparisons, no step reduces by construction to the paper's own inputs. Minor self-citation to the authors' prior line of work exists but is not load-bearing for the central clarification.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 2 Pith papers
-
Provable Quantization with Randomized Hadamard Transform
Dithered quantization after a single randomized Hadamard transform yields unbiased estimates whose MSE asymptotically equals that of dense random rotations, specifically (π√3/2 + o(1))·4^{-b} for b-bit TurboQuant.
-
Quantizing With Randomized Hadamard Transforms: Efficient Heuristic Now Proven
Two randomized Hadamard transforms suffice to make coordinate marginals O(d^{-1/2})-close to Gaussian for most quantization methods, with three needed for vector quantization to match uniform random rotations asymptotically.
Reference graph
Works this paper leans on
-
[1]
Accelerating Federated Learning with Quick Distributed Mean Estimation
Ran Ben Basat, Shay Vargaftik, Amit Portnoy, Gil Einziger, Yaniv Ben-Itzhak, and Michael Mitzenmacher. Accelerating Federated Learning with Quick Distributed Mean Estimation. In International Conference on Machine Learning, 2024
2024
-
[2]
Preprintinpreparation, 2026
RanBenBasat, WilliamKuszmaul, AmitPortnoy, andShayVargaftik. Preprintinpreparation, 2026. 9
2026
-
[3]
Turboquant and rabitq: What the public story gets wrong
Jianyang Gao. Turboquant and rabitq: What the public story gets wrong. DEV Community, mar 2026. https://dev.to/gaoj0017/turboquant-and-rabitq-what-the-public-story-gets-wrong- 1i00
2026
-
[4]
Rabitq: Quantizing high-dimensional vectors with a theoretical error bound for approximate nearest neighbor search.Proceedings of the ACM on Management of Data, 2(3):1–27, 2024
Jianyang Gao and Cheng Long. Rabitq: Quantizing high-dimensional vectors with a theoretical error bound for approximate nearest neighbor search.Proceedings of the ACM on Management of Data, 2(3):1–27, 2024
2024
-
[5]
Google’s ‘turboquant’ sparks memory stock selloff; industry calls demand con- cerns overblown
Seo Jong-gap. Google’s ‘turboquant’ sparks memory stock selloff; industry calls demand con- cerns overblown. Seoul Economic Daily, 2026. March 26, 2026. Available at article link
2026
-
[6]
GitHub repository, 2022.https://github.com/securefederatedai/ openfederatedlearning/blob/develop/openfl/pipelines/eden_pipeline.py
OpenFL - Secure Federated AI .eden_pipeline.pysource code in OpenFeder- atedLearning. GitHub repository, 2022.https://github.com/securefederatedai/ openfederatedlearning/blob/develop/openfl/pipelines/eden_pipeline.py
2022
-
[7]
Semiconductor stocks plunge on google turboquant — ‘actual effect limited to 2.6x’
Seoul Economic Daily. Semiconductor stocks plunge on google turboquant — ‘actual effect limited to 2.6x’. Seoul Economic Daily, 2026. March 27, 2026. Available at article link
2026
-
[8]
Drive: One-bit distributed mean estimation
Shay Vargaftik, Ran Ben-Basat, Amit Portnoy, Gal Mendelson, Yaniv Ben-Itzhak, and Michael Mitzenmacher. Drive: One-bit distributed mean estimation. InAdvances in Neural Information Processing Systems 34 (NeurIPS 2021), 2021
2021
-
[9]
Eden: Communication-efficient and robust distributed mean estimation for federated learning
Shay Vargaftik, Ran Ben-Basat, Amit Portnoy, Gal Mendelson, Yaniv Ben-Itzhak, and Michael Mitzenmacher. Eden: Communication-efficient and robust distributed mean estimation for federated learning. InProceedings of the 39th International Conference on Machine Learning (ICML 2022), PMLR 162, 2022
2022
-
[10]
VMware Research Group’s EDEN Becomes Part of OpenFL
VMware’s Open Source Team. VMware Research Group’s EDEN Becomes Part of OpenFL. VMware Open Source Blog, Nov 2022.https://blogs.vmware.com/opensource/2022/11/ 16/vmware-research-groups-eden-becomes-part-of-openfl/
2022
-
[11]
Samsung, sk hynix slide as google touts ai memory compression tech ‘turbo- quant’
Ambar Warrick. Samsung, sk hynix slide as google touts ai memory compression tech ‘turbo- quant’. Investing.com, with Reuters credit, 2026. March 25, 2026. Available at article link
2026
-
[12]
Turboquant: Online vector quantization with near-optimal distortion rate
Amir Zandieh, Majid Daliri, Majid Hadian, and Vahab Mirrokni. Turboquant: Online vector quantization with near-optimal distortion rate. InThe Fourteenth International Conference on Learning Representations, 2026. https://openreview.net/forum?id=tO3ASKZlok
2026
-
[13]
QJL: 1-bit quantized JL transform for KV cache quantization with zero overhead, 2024
Amir Zandieh, Majid Daliri, and Insu Han. QJL: 1-bit quantized JL transform for KV cache quantization with zero overhead, 2024
2024
-
[14]
Turboquant: Redefining ai efficiency with extreme com- pression
Amir Zandieh and Vahab Mirrokni. Turboquant: Redefining ai efficiency with extreme com- pression. Google blog, 2026. March 24, 2026. 10
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.