Recognition: unknown
Bounded Ratio Reinforcement Learning
Pith reviewed 2026-05-10 04:46 UTC · model grok-4.3
The pith
The BRRL framework derives an analytic optimal policy that guarantees monotonic performance improvement in on-policy reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the closed-form solution to the regularized constrained problem in BRRL ensures monotonic performance improvement, while the BPO algorithm that minimizes advantage-weighted divergence to this solution admits a lower bound on its expected performance expressed directly in terms of the BPO loss value.
What carries the argument
Bounded Policy Optimization (BPO), the algorithm that minimizes an advantage-weighted divergence between the current policy and the analytic optimum obtained from the BRRL regularized constrained problem.
If this is right
- Any policy obtained by BPO is guaranteed a performance floor that depends only on the value of the minimized loss.
- The BRRL derivation supplies a principled explanation for the empirical success of PPO's clipped surrogate.
- The same bounded-ratio construction connects trust-region policy optimization directly to the Cross-Entropy Method.
- The group-relative extension GBPO inherits the same monotonicity and bounding properties when applied to LLM fine-tuning.
Where Pith is reading between the lines
- The explicit lower bound could be monitored during training as an online diagnostic for whether further updates are still productive.
- Because the ratio bound is independent of the particular policy parameterization, similar constructions might stabilize other on-policy or hybrid RL methods.
- The analytic link to CEM suggests possible new algorithms that alternate between sampling-based proposals and the closed-form ratio update.
Load-bearing premise
That advantage-weighted divergence minimization in BPO produces a policy whose performance is well-approximated by the derived lower bound when the policy class is parameterized and cannot exactly match the analytic optimum.
What would settle it
Run BPO on a simple MuJoCo locomotion task, compute the lower bound from the observed loss at each update, and check whether measured returns ever fall below that bound or show non-monotonic drops.
Figures







read the original abstract
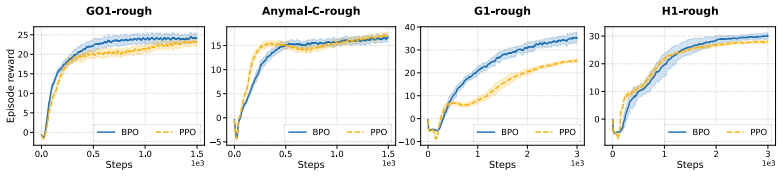
Proximal Policy Optimization (PPO) has become the predominant algorithm for on-policy reinforcement learning due to its scalability and empirical robustness across domains. However, there is a significant disconnect between the underlying foundations of trust region methods and the heuristic clipped objective used in PPO. In this paper, we bridge this gap by introducing the Bounded Ratio Reinforcement Learning (BRRL) framework. We formulate a novel regularized and constrained policy optimization problem and derive its analytical optimal solution. We prove that this solution ensures monotonic performance improvement. To handle parameterized policy classes, we develop a policy optimization algorithm called Bounded Policy Optimization (BPO) that minimizes an advantage-weighted divergence between the policy and the analytic optimal solution from BRRL. We further establish a lower bound on the expected performance of the resulting policy in terms of the BPO loss function. Notably, our framework also provides a new theoretical lens to interpret the success of the PPO loss, and connects trust region policy optimization and the Cross-Entropy Method (CEM). We additionally extend BPO to Group-relative BPO (GBPO) for LLM fine-tuning. Empirical evaluations of BPO across MuJoCo, Atari, and complex IsaacLab environments (e.g., Humanoid locomotion), and of GBPO for LLM fine-tuning tasks, demonstrate that BPO and GBPO generally match or outperform PPO and GRPO in stability and final performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Bounded Ratio Reinforcement Learning (BRRL) framework, which defines a novel regularized constrained policy optimization problem whose analytic optimum is derived and proven to yield monotonic performance improvement. For parameterized policies, it proposes Bounded Policy Optimization (BPO) that minimizes an advantage-weighted divergence to this optimum and derives a lower bound on the resulting policy's expected return expressed in terms of the BPO loss. The work also reinterprets PPO through this lens, connects BRRL to TRPO and CEM, extends the method to Group-relative BPO (GBPO) for LLM fine-tuning, and reports empirical results on MuJoCo, Atari, IsaacLab, and LLM tasks showing BPO/GBPO matching or exceeding PPO/GRPO.
Significance. If the analytic derivation, monotonicity proof, and lower-bound argument remain valid under parameterization, the framework supplies a principled foundation that could explain PPO's empirical success and yield more stable on-policy methods with explicit performance guarantees. The connections to existing algorithms and the extension to LLM fine-tuning are additional strengths; reproducible code or machine-checked proofs would further elevate the contribution.
major comments (2)
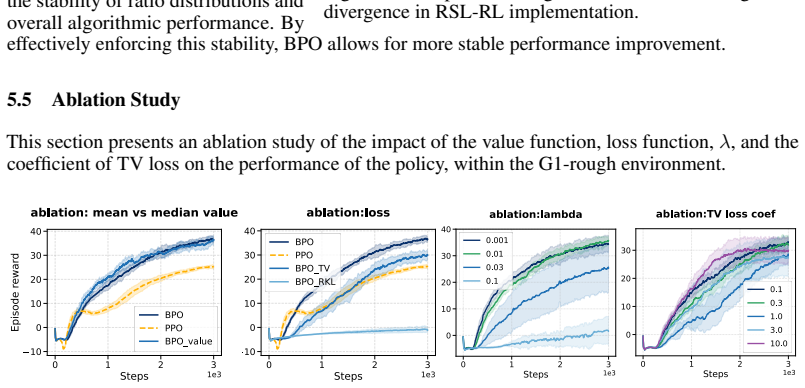
- [BPO lower-bound derivation (post-Theorem on monotonic improvement)] The lower-bound claim (abstract and the derivation following the BPO objective) is obtained by substituting the exact analytic minimizer into the performance-difference lemma and replacing the divergence term with the BPO loss. When the policy class is restricted (e.g., neural networks), the residual divergence is nonzero; the manuscript provides no explicit error term or robustness analysis showing that this residual cannot make the bound arbitrarily loose or negative, undermining the assertion that the BPO loss directly controls practical performance.
- [Section on BPO algorithm and performance bound] The monotonic-improvement guarantee is proven for the analytic optimum under the BRRL constrained problem. The extension to BPO for parameterized policies relies on the lower bound being informative, yet no finite-sample or approximation-error analysis is supplied to confirm that the bound remains positive or useful when the policy cannot exactly attain the analytic solution.
minor comments (2)
- [BRRL formulation] Notation for the advantage-weighted divergence and the regularizer in the BRRL objective could be clarified with an explicit comparison table to the PPO clipped surrogate.
- [Experiments] Empirical sections report final performance but lack details on the number of random seeds, statistical tests, or sensitivity to the BPO hyper-parameters (e.g., the divergence coefficient).
Simulated Author's Rebuttal
We thank the referee for the careful review and constructive feedback on our manuscript. We address each major comment below, clarifying the scope of our theoretical results and indicating planned revisions.
read point-by-point responses
-
Referee: [BPO lower-bound derivation (post-Theorem on monotonic improvement)] The lower-bound claim (abstract and the derivation following the BPO objective) is obtained by substituting the exact analytic minimizer into the performance-difference lemma and replacing the divergence term with the BPO loss. When the policy class is restricted (e.g., neural networks), the residual divergence is nonzero; the manuscript provides no explicit error term or robustness analysis showing that this residual cannot make the bound arbitrarily loose or negative, undermining the assertion that the BPO loss directly controls practical performance.
Authors: We agree that the lower bound is derived under the assumption of exact attainment of the analytic minimizer from the BRRL problem. For parameterized policies, BPO minimizes a surrogate that controls the divergence to this optimum, so the performance lower bound is expressed in terms of the achieved (nonzero) BPO loss value. The bound remains valid and non-vacuous whenever the loss is driven sufficiently small by optimization, consistent with the performance-difference lemma. We will revise the relevant section and abstract to explicitly note the approximation gap, state the conditions under which the bound is tight, and clarify that it provides a practical control on performance rather than an absolute monotonicity guarantee. revision: partial
-
Referee: [Section on BPO algorithm and performance bound] The monotonic-improvement guarantee is proven for the analytic optimum under the BRRL constrained problem. The extension to BPO for parameterized policies relies on the lower bound being informative, yet no finite-sample or approximation-error analysis is supplied to confirm that the bound remains positive or useful when the policy cannot exactly attain the analytic solution.
Authors: The monotonic-improvement theorem applies strictly to the exact analytic solution of the BRRL constrained optimization. For BPO we derive a lower bound on expected return expressed directly in terms of the BPO loss; this bound is informative for optimization even when the policy class cannot reach the analytic optimum, because smaller achieved loss values yield tighter performance guarantees. We acknowledge that a full finite-sample or approximation-error analysis is absent and would require additional technical development. We will add a clarifying paragraph in the BPO section and discussion to distinguish the exact guarantee from the parameterized case and to note the empirical support for the bound's utility. revision: partial
Circularity Check
Derivation chain is self-contained with no circular reductions
full rationale
The paper formulates a novel regularized constrained policy optimization problem, derives its closed-form optimal policy, applies the standard performance-difference lemma to prove monotonic improvement for that optimum, then defines BPO as minimizing an advantage-weighted divergence to the optimum and obtains a lower bound on expected return expressed in terms of the resulting BPO loss value. Each step proceeds forward from the stated objective and standard RL identities; the BPO loss appears as the quantity being minimized rather than a fitted parameter whose value is later renamed a prediction, and no load-bearing premise reduces to a self-citation or to an ansatz imported from prior work by the same authors. The PPO reinterpretation is offered as a derived consequence, not an input assumption. The derivation therefore remains non-circular even when the policy class is parameterized.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions on policy class expressivity and advantage estimation accuracy
invented entities (1)
-
Bounded Ratio Reinforcement Learning (BRRL) framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Abdullah Akgül, Gulcin Baykal, Manuel Haußmann, and Melih Kandemir. Overcom- ing non-stationary dynamics with evidential proximal policy optimization.arXiv preprint arXiv:2503.01468, 2025
-
[2]
Learning dexterous in-hand manipulation.The International Journal of Robotics Research, 39(1):3–20, 2020
OpenAI: Marcin Andrychowicz, Bowen Baker, Maciek Chociej, Rafal Jozefowicz, Bob Mc- Grew, Jakub Pachocki, Arthur Petron, Matthias Plappert, Glenn Powell, Alex Ray, et al. Learning dexterous in-hand manipulation.The International Journal of Robotics Research, 39(1):3–20, 2020
2020
-
[3]
Phasic policy gradient
Karl W Cobbe, Jacob Hilton, Oleg Klimov, and John Schulman. Phasic policy gradient. In International Conference on Machine Learning, pages 2020–2027. PMLR, 2021
2020
-
[4]
An approximate ascent approach to prove convergence of ppo
Leif Doering, Daniel Schmidt, Moritz Melcher, Sebastian Kassing, Benedikt Wille, Tilman Aach, and Simon Weissmann. An approximate ascent approach to prove convergence of ppo. arXiv preprint arXiv:2602.03386, 2026
-
[5]
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine
Logan Engstrom, Andrew Ilyas, Shibani Santurkar, Dimitris Tsipras, Firdaus Janoos, Larry Rudolph, and Aleksander Madry. Implementation matters in deep policy gradients: A case study on ppo and trpo.arXiv preprint arXiv:2005.12729, 2020
-
[6]
P3o: Policy-on policy-off policy optimization
Rasool Fakoor, Pratik Chaudhari, and Alexander J Smola. P3o: Policy-on policy-off policy optimization. InUncertainty in artificial intelligence, pages 1017–1027. PMLR, 2020
2020
-
[7]
Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor. InInternational conference on machine learning, pages 1861–1870. PMLR, 2018
2018
-
[8]
Proximal policy optimization with relative pearson divergence
Taisuke Kobayashi. Proximal policy optimization with relative pearson divergence. In2021 IEEE International Conference on Robotics and Automation (ICRA), pages 8416–8421. IEEE, 2021. 13
2021
-
[9]
On information and sufficiency.The annals of mathematical statistics, 22(1):79–86, 1951
Solomon Kullback and Richard A Leibler. On information and sufficiency.The annals of mathematical statistics, 22(1):79–86, 1951
1951
-
[10]
L. D. Landau, E. M. Lifshitz, and L. P. Pitaevskii.Statistical Physics: Theory of the Condensed State, volume 9 ofCourse of Theoretical Physics. Butterworth-Heinemann, Oxford, 1980
1980
-
[11]
Learning quadrupedal locomotion over challenging terrain.Science robotics, 5(47):eabc5986, 2020
Joonho Lee, Jemin Hwangbo, Lorenz Wellhausen, Vladlen Koltun, and Marco Hutter. Learning quadrupedal locomotion over challenging terrain.Science robotics, 5(47):eabc5986, 2020
2020
-
[12]
Neural trust region/proximal policy optimization attains globally optimal policy.Advances in neural information processing systems, 32, 2019
Boyi Liu, Qi Cai, Zhuoran Yang, and Zhaoran Wang. Neural trust region/proximal policy optimization attains globally optimal policy.Advances in neural information processing systems, 32, 2019
2019
-
[13]
Learning robust perceptive locomotion for quadrupedal robots in the wild.Science robotics, 7(62):eabk2822, 2022
Takahiro Miki, Joonho Lee, Jemin Hwangbo, Lorenz Wellhausen, Vladlen Koltun, and Marco Hutter. Learning robust perceptive locomotion for quadrupedal robots in the wild.Science robotics, 7(62):eabk2822, 2022
2022
-
[14]
Central path proximal policy optimization
Nikola Milosevic, Johannes Müller, and Nico Scherf. Central path proximal policy optimization. arXiv preprint arXiv:2506.00700, 2025
-
[15]
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
Mayank Mittal, Pascal Roth, James Tigue, Antoine Richard, Octi Zhang, Peter Du, Antonio Serrano-Muñoz, Xinjie Yao, René Zurbrügg, Nikita Rudin, et al. Isaac lab: A gpu-accelerated simulation framework for multi-modal robot learning.arXiv preprint arXiv:2511.04831, 2025
work page internal anchor Pith review arXiv 2025
-
[16]
Playing Atari with Deep Reinforcement Learning
V olodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin Riedmiller. Playing atari with deep reinforcement learning.arXiv preprint arXiv:1312.5602, 2013
work page internal anchor Pith review arXiv 2013
-
[17]
Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
2022
-
[18]
Rethinking the trust region in LLM reinforcement learning.arXiv preprint arXiv:2602.04879, 2026
Penghui Qi, Xiangxin Zhou, Zichen Liu, Tianyu Pang, Chao Du, Min Lin, and Wee Sun Lee. Rethinking the trust region in llm reinforcement learning.arXiv preprint arXiv:2602.04879, 2026
-
[19]
Real-world humanoid locomotion with reinforcement learning.Science Robotics, 9(89):eadi9579, 2024
Ilija Radosavovic, Tete Xiao, Bike Zhang, Trevor Darrell, Jitendra Malik, and Koushil Sreenath. Real-world humanoid locomotion with reinforcement learning.Science Robotics, 9(89):eadi9579, 2024
2024
-
[20]
Rl baselines3 zoo
Antonin Raffin. Rl baselines3 zoo. https://github.com/DLR-RM/rl-baselines3-zoo , 2020
2020
-
[21]
The cross-entropy method for combinatorial and continuous optimization
Reuven Rubinstein. The cross-entropy method for combinatorial and continuous optimization. Methodology and computing in applied probability, 1(2):127–190, 1999
1999
-
[22]
Trust region policy optimization
John Schulman, Sergey Levine, Pieter Abbeel, Michael Jordan, and Philipp Moritz. Trust region policy optimization. InInternational conference on machine learning, pages 1889–1897. PMLR, 2015
2015
-
[23]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
John Schulman, Philipp Moritz, Sergey Levine, Michael Jordan, and Pieter Abbeel. High- dimensional continuous control using generalized advantage estimation.arXiv preprint arXiv:1506.02438, 2015
work page internal anchor Pith review arXiv 2015
-
[24]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[25]
arXiv preprint arXiv:2509.10771 , year=
Clemens Schwarke, Mayank Mittal, Nikita Rudin, David Hoeller, and Marco Hutter. Rsl-rl: A learning library for robotics research.arXiv preprint arXiv:2509.10771, 2025
-
[26]
skrl: Modular and flexible library for reinforcement learning.Journal of Machine Learning Research, 24(254):1–9, 2023
Antonio Serrano-Munoz, Dimitrios Chrysostomou, Simon Bøgh, and Nestor Arana- Arexolaleiba. skrl: Modular and flexible library for reinforcement learning.Journal of Machine Learning Research, 24(254):1–9, 2023. 14
2023
-
[27]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Mastering the game of go without human knowledge.Nature, 550(7676):354–359, 2017
David Silver, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou, Aja Huang, Arthur Guez, Thomas Hubert, Lucas Baker, Matthew Lai, Adrian Bolton, et al. Mastering the game of go without human knowledge.Nature, 550(7676):354–359, 2017
2017
-
[29]
Beyond the boundaries of proximal policy optimization.arXiv preprint arXiv:2411.00666, 2024
Charlie B Tan, Edan Toledo, Benjamin Ellis, Jakob N Foerster, and Ferenc Huszár. Beyond the boundaries of proximal policy optimization.arXiv preprint arXiv:2411.00666, 2024
-
[30]
arXiv preprint arXiv:2510.06062 , year=
Jiakang Wang, Runze Liu, Lei Lin, Wenping Hu, Xiu Li, Fuzheng Zhang, Guorui Zhou, and Kun Gai. Aspo: Asymmetric importance sampling policy optimization.arXiv preprint arXiv:2510.06062, 2025
-
[31]
Truly proximal policy optimization
Yuhui Wang, Hao He, and Xiaoyang Tan. Truly proximal policy optimization. InUncertainty in artificial intelligence, pages 113–122. PMLR, 2020
2020
-
[32]
Trust region-guided proximal policy optimization.Advances in Neural Information Processing Systems, 32, 2019
Yuhui Wang, Hao He, Xiaoyang Tan, and Yaozhong Gan. Trust region-guided proximal policy optimization.Advances in Neural Information Processing Systems, 32, 2019
2019
-
[33]
arXiv preprint arXiv:2510.18927 , year=
Zhiheng Xi, Xin Guo, Yang Nan, Enyu Zhou, Junrui Shen, Wenxiang Chen, Jiaqi Liu, Jix- uan Huang, Zhihao Zhang, Honglin Guo, et al. Bapo: Stabilizing off-policy reinforcement learning for llms via balanced policy optimization with adaptive clipping.arXiv preprint arXiv:2510.18927, 2025
-
[34]
Simple policy optimization.arXiv preprint arXiv:2401.16025, 2024
Zhengpeng Xie, Qiang Zhang, and Renjing Xu. Simple policy optimization.arXiv preprint arXiv:2401.16025, 2024
-
[35]
Mastering complex control in moba games with deep reinforcement learning
Deheng Ye, Zhao Liu, Mingfei Sun, Bei Shi, Peilin Zhao, Hao Wu, Hongsheng Yu, Shaojie Yang, Xipeng Wu, Qingwei Guo, et al. Mastering complex control in moba games with deep reinforcement learning. InProceedings of the AAAI conference on artificial intelligence, volume 34, pages 6672–6679, 2020
2020
-
[36]
TTRL: Test-Time Reinforcement Learning
Yuxin Zuo, Kaiyan Zhang, Li Sheng, Shang Qu, Ganqu Cui, Xuekai Zhu, Haozhan Li, Yuchen Zhang, Xinwei Long, Ermo Hua, et al. Ttrl: Test-time reinforcement learning.arXiv preprint arXiv:2504.16084, 2025. 15 A Appendix A.1 Code A vailability Below are the links to our project website and source code. Project website:https://bounded-ratio-rl.github.io/brrl/. ...
work page Pith review arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.