Recognition: unknown
Self-Improving Tabular Language Models via Iterative Group Alignment
Pith reviewed 2026-05-10 03:01 UTC · model grok-4.3
The pith
Tabular language models can self-improve by iteratively partitioning their own generations into quality groups and aligning on the differences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
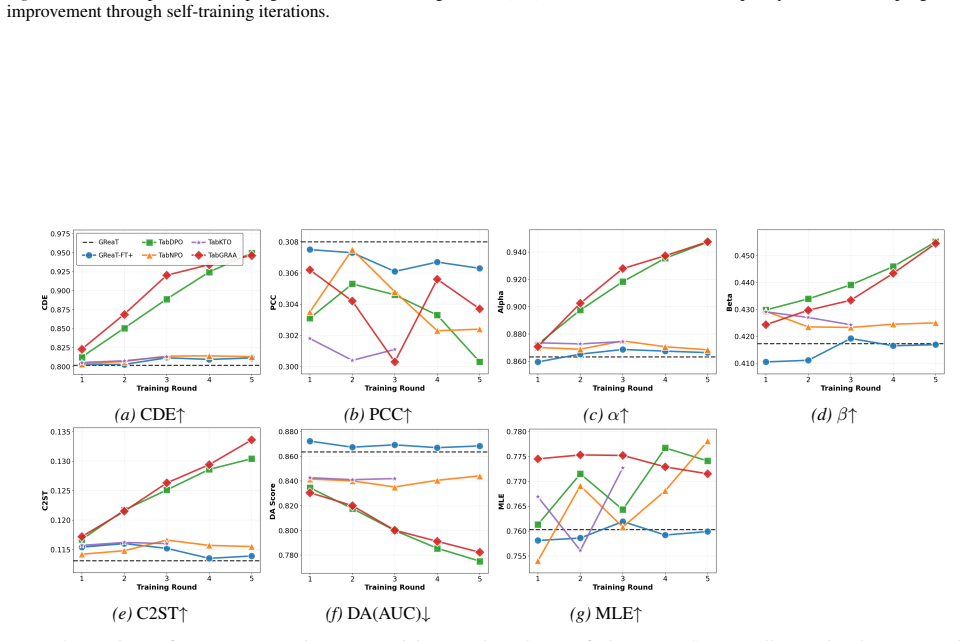
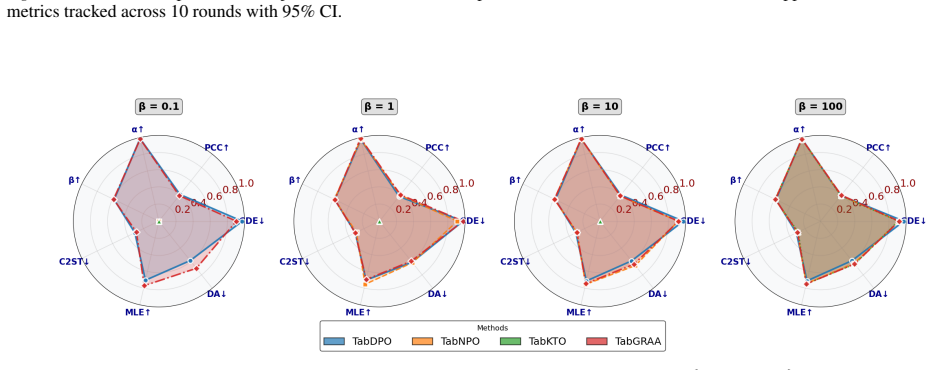
TabGRAA lets language models for tabular data move from static supervised fine-tuning to iterative self-improvement by using an automated quality signal, such as a two-sample distinguishability classifier or distance-based reward, to partition each round of generated samples into high- and low-quality groups and then optimizing a group-relative advantage objective that strengthens realistic structure while suppressing artifacts; the resulting model is fine-tuned solely on these self-generated signals, establishing a virtuous cycle that improves data quality without exposing additional real records.
What carries the argument
The group-relative advantage objective that contrasts high-quality versus low-quality groups identified by a modular automated quality signal.
If this is right
- TabGRAA outperforms prior language-model and statistical methods on fidelity, utility, and privacy measures.
- Performance reaches or exceeds that of diffusion-based tabular synthesizers.
- Tabular synthesis advances from static replication to dynamic self-improving generation.
- The framework keeps data-leakage risk limited to the initial supervised fine-tuning step.
Where Pith is reading between the lines
- The same partitioning-and-alignment loop could be tested on other structured data types where an automated quality signal exists.
- Models might reach usable performance from smaller initial real datasets by bootstrapping improvements from their own synthetic outputs.
- Combining the approach with existing tabular-specific architectures could produce hybrid generators that inherit both self-correction and domain constraints.
Load-bearing premise
The chosen automated quality signal can reliably separate high-quality from low-quality generated samples without introducing systematic bias or circular feedback at each iteration.
What would settle it
Running multiple iterations of TabGRAA on a benchmark dataset yields no improvement or a decline in fidelity and utility metrics relative to the initial fine-tuned model.
Figures



















read the original abstract
While language models have been adapted for tabular data generation, two fundamental limitations remain: (1) static fine-tuning produces models that cannot learn from their own generated samples and adapt to self-correct, and (2) autoregressive objectives preserve local token coherence but neglect global statistical properties, degrading tabular quality. Reinforcement learning offers a potential solution but requires designing reward functions that balance competing objectives -- impractical for tabular data. To fill the gap, we introduce TabGRAA (Tabular Group-Relative Advantage Alignment), the first self-improving framework for tabular data generation via automated feedback. At each iteration, TabGRAA uses an \emph{automated quality signal} -- such as a two-sample distinguishability classifier or a distance-based reward -- to partition newly generated samples into high- and low-quality groups, then optimizes a group-relative advantage objective that reinforces realistic patterns while penalizing artifacts. The specific signal is a modular choice rather than a fixed component of the framework. This establishes a virtuous feedback cycle, where the quality signal is re-computed against newly \emph{generated synthetic} samples at each round; the language model is only fine-tuned on these self-generated signals, so no additional real record is exposed during alignment, mitigating data-leakage risk beyond the initial supervised fine-tuning. Experiments show TabGRAA outperforms existing methods in fidelity, utility, and privacy, while matching or exceeding diffusion-based synthesizers, advancing tabular synthesis from static statistical replication to dynamic, self-improving generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TabGRAA, a self-improving framework for tabular language models via iterative group alignment. It uses an automated quality signal (e.g., two-sample distinguishability classifier or distance-based reward) to partition self-generated samples into high- and low-quality groups at each iteration, then optimizes a group-relative advantage objective to reinforce realistic global statistics while penalizing artifacts. The approach relies only on self-generated signals after initial fine-tuning, claims to establish a virtuous feedback cycle without additional real data exposure, and reports outperformance over existing methods in fidelity, utility, and privacy while matching or exceeding diffusion-based synthesizers.
Significance. If the central empirical claims hold with proper validation, this would represent a meaningful advance in tabular data synthesis by moving beyond static fine-tuning to dynamic self-correction and adaptation. The modular quality signal and privacy-preserving use of only self-generated samples after initial tuning are notable strengths that could reduce data leakage risks and improve adaptability for downstream tasks.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): The central claim that TabGRAA 'outperforms existing methods in fidelity, utility, and privacy' and 'matches or exceeds diffusion-based synthesizers' is load-bearing for the paper's contribution, yet the abstract provides no quantitative results, error bars, baseline details, ablation studies, or specific metrics, preventing verification of support for the stated advances.
- [§3.2] §3.2 (Automated Quality Signal): The assumption that the modular quality signal (distinguishability classifier or distance reward) reliably partitions samples without introducing circular feedback or artifacts when recomputed solely on new synthetic outputs is central to the virtuous cycle and self-improvement claim, but the manuscript provides no argument, proof, or experiment addressing distribution shift, reward hacking, or bias reinforcement from the LM's own patterns.
minor comments (2)
- [§3] The group-relative advantage objective is described conceptually but would benefit from an explicit equation or pseudocode to clarify the reinforcement/penalty mechanics across groups.
- [§4] Figure captions and table descriptions (if present in §4) should explicitly state the number of runs, random seeds, and statistical significance tests used for the reported outperformance.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address each major comment point by point below, providing honest responses and indicating the revisions we will incorporate to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): The central claim that TabGRAA 'outperforms existing methods in fidelity, utility, and privacy' and 'matches or exceeds diffusion-based synthesizers' is load-bearing for the paper's contribution, yet the abstract provides no quantitative results, error bars, baseline details, ablation studies, or specific metrics, preventing verification of support for the stated advances.
Authors: We agree that the abstract would be strengthened by including key quantitative highlights to support the central claims. In the revised manuscript, we will update the abstract to report specific metrics such as fidelity improvements (e.g., reduced Wasserstein distance or MMD scores), utility gains (e.g., downstream classifier accuracy), and privacy metrics (e.g., membership inference attack success rates), along with references to error bars from multiple experimental runs. Section 4 already contains comprehensive tables with these results, including comparisons to baselines and diffusion-based synthesizers, ablation studies on the group alignment components, and statistical details. We will add a brief summary of baseline methods and the number of runs in the abstract to improve verifiability while preserving its concise nature. revision: yes
-
Referee: [§3.2] §3.2 (Automated Quality Signal): The assumption that the modular quality signal (distinguishability classifier or distance reward) reliably partitions samples without introducing circular feedback or artifacts when recomputed solely on new synthetic outputs is central to the virtuous cycle and self-improvement claim, but the manuscript provides no argument, proof, or experiment addressing distribution shift, reward hacking, or bias reinforcement from the LM's own patterns.
Authors: We acknowledge that the manuscript does not include a formal proof against distribution shift or reward hacking, which is a valid concern for any self-referential quality signal in iterative RL settings. However, the experiments demonstrate empirical stability through consistent metric improvements across iterations without observed degradation. To address this directly, we will revise §3.2 to expand the discussion of the modular signal's design, including how initial mixed real-synthetic training of the distinguishability classifier helps anchor against LM-specific artifacts, and how the group-relative advantage objective penalizes low-quality patterns. We will also add targeted experiments in §4 that monitor signal accuracy, data statistics, and potential bias reinforcement over iterations, using held-out real data for validation. This provides stronger empirical grounding for the virtuous cycle claim. revision: partial
Circularity Check
No circularity: framework uses modular external-style signals on self-generated data without reducing claims to input tautologies
full rationale
The paper presents TabGRAA as an iterative alignment procedure that applies a user-chosen automated quality signal (e.g., distinguishability classifier or distance metric) to partition model outputs and then performs group-relative advantage optimization. No equations, definitions, or self-citations are exhibited that make the claimed improvement equivalent to the inputs by construction; the signal is explicitly modular and recomputed on fresh synthetics, while the initial supervised fine-tuning is treated as a separate, non-iterative step. Experimental claims of outperformance are therefore independent of any definitional loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Automated quality signals such as distinguishability classifiers or distance metrics can partition generated tabular samples into meaningfully high- and low-quality groups
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2406.12120 , year=
Adding conditional control to diffusion models with reinforcement learning , author=. arXiv preprint arXiv:2406.12120 , year=
-
[2]
arXiv preprint arXiv:2502.13833 , year=
Contrastive Learning-Based privacy metrics in Tabular Synthetic Datasets , author=. arXiv preprint arXiv:2502.13833 , year=
-
[3]
arXiv preprint arXiv:2404.08254 , year=
Balanced mixed-type tabular data synthesis with diffusion models , author=. arXiv preprint arXiv:2404.08254 , year=
-
[5]
arXiv preprint arXiv:2307.03577 , year=
Cuts: Customizable tabular synthetic data generation , author=. arXiv preprint arXiv:2307.03577 , year=
-
[6]
arXiv preprint arXiv:2504.16438 , year=
Private federated learning using preference-optimized synthetic data , author=. arXiv preprint arXiv:2504.16438 , year=
-
[7]
Exposing privacy gaps: Membership inference attack on preference data for llm alignment , author=. arXiv preprint arXiv:2407.06443 , year=
-
[8]
arXiv preprint arXiv:2404.05868 , year=
Negative preference optimization: From catastrophic collapse to effective unlearning , author=. arXiv preprint arXiv:2404.05868 , year=
-
[9]
Achiam, Josh and Adler, Steven and Agarwal, Sandhini and Ahmad, Lama and Akkaya, Ilge and Aleman, Florencia Leoni and Almeida, Diogo and Altenschmidt, Janko and Altman, Sam and Anadkat, Shyamal and others , journal=
-
[10]
The Journal of Pediatric Pharmacology and Therapeutics , volume=
The Potential Application of Large Language Models in Pharmaceutical Supply Chain Management , author=. The Journal of Pediatric Pharmacology and Therapeutics , volume=. 2024 , publisher=
2024
-
[11]
International Conference on Machine Learning , pages=
How Faithful is Your Synthetic Data? Sample-Level Metrics for Evaluating and Auditing Generative Models , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[12]
arXiv preprint arXiv:2408.07705 , year=
Enhancing Supply Chain Visibility with Knowledge Graphs and Large Language Models , author=. arXiv preprint arXiv:2408.07705 , year=
-
[13]
Asuncion, Arthur and Newman, David , year=
-
[14]
Nature Communications , volume=
Searching for Exotic Particles in High-Energy Physics with Deep Learning , author=. Nature Communications , volume=. 2014 , publisher=
2014
-
[15]
The Knowledge Engineering Review , volume=
Negotiation in Multi-Agent Systems , author=. The Knowledge Engineering Review , volume=. 1999 , doi=
1999
-
[16]
2020 , eprint=
Google Dataset Search by the Numbers , author=. 2020 , eprint=
2020
-
[17]
arXiv preprint arXiv:2210.06280 , year=
Language Models are Realistic Tabular Data Generators , author=. arXiv preprint arXiv:2210.06280 , year=
-
[18]
Bose, Avishek Joey and Akhound-Sadegh, Tara and Huguet, Guillaume and Fatras, Kilian and Rector-Brooks, Jarrid and Liu, Cheng-Hao and Nica, Andrei Cristian and Korablyov, Maksym and Bronstein, Michael and Tong, Alexander , journal=
-
[19]
Advances in Neural Information Processing Systems , volume=
Language Models are Few-Shot Learners , author=. Advances in Neural Information Processing Systems , volume=
-
[20]
Chawla, Nitesh V and Bowyer, Kevin W and Hall, Lawrence O and Kegelmeyer, W Philip , journal=
-
[22]
Chen, Tianqi and Guestrin, Carlos , booktitle=
-
[23]
IEEE Transactions on Knowledge and Data Engineering , volume=
Economics-Driven Data Management: An Application to the Design of Tabular Data Sets , author=. IEEE Transactions on Knowledge and Data Engineering , volume=. 2007 , publisher=
2007
-
[24]
Proceedings of the 14th International Conference on Availability, Reliability and Security , year=
Fiore, Ugo and De Santis, Alberto and Perla, Francesco and Zanetti, Paolo and Palmieri, Francesco , title=. Proceedings of the 14th International Conference on Availability, Reliability and Security , year=
-
[25]
Mean Flows for One-step Generative Modeling
Mean Flows for One-Step Generative Modeling , author=. arXiv preprint arXiv:2505.13447 , year=
work page internal anchor Pith review arXiv
-
[26]
arXiv preprint arXiv:1604.06737 , year=
Guo, Cheng and Berkhahn, Felix , title=. arXiv preprint arXiv:1604.06737 , year=
-
[27]
Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Zhang, Ruoyu and Xu, Runxin and Zhu, Qihao and Ma, Shirong and Wang, Peiyi and Bi, Xiao and others , journal=
-
[28]
Improved noise schedule for diffusion training
Improved Noise Schedule for Diffusion Training , author=. arXiv preprint arXiv:2407.03297 , year=
-
[29]
A Flexible Generative Model for Heterogeneous Tabular
He, Huan and Xi, Yuanzhe and Chen, Yong and Malin, Bradley and Ho, Joyce and others , booktitle=. A Flexible Generative Model for Heterogeneous Tabular
-
[30]
2023 , organization=
Hegselmann, Stefan and Buendia, Alejandro and Lang, Hunter and Agrawal, Monica and Jiang, Xiaoyi and Sontag, David , booktitle=. 2023 , organization=
2023
-
[31]
Neurocomputing , volume=
Synthetic Data Generation for Tabular Health Records: A Systematic Review , author=. Neurocomputing , volume=. 2022 , publisher=
2022
-
[32]
2023 , organization=
Huang, Rongjie and Huang, Jiawei and Yang, Dongchao and Ren, Yi and Liu, Luping and Li, Mingze and Ye, Zhenhui and Liu, Jinglin and Yin, Xiang and Zhao, Zhou , booktitle=. 2023 , organization=
2023
-
[33]
2016 , publisher=
Johnson, Alistair EW and Pollard, Tom J and Shen, Lu and Lehman, Li-wei H and Feng, Mengling and Ghassemi, Mohammad and Moody, Benjamin and Szolovits, Peter and Anthony Celi, Leo and Mark, Roger G , journal=. 2016 , publisher=
2016
-
[34]
arXiv preprint arXiv:2205.03257 , year=
Synthetic Data--What, Why and How? , author=. arXiv preprint arXiv:2205.03257 , year=
-
[35]
Advances in Neural Information Processing Systems , volume=
Elucidating the Design Space of Diffusion-Based Generative Models , author=. Advances in Neural Information Processing Systems , volume=
-
[36]
Kim, Jayoung and Lee, Chaejeong and Park, Noseong , journal=
-
[37]
Scaling up the Accuracy of Naive-
Kohavi, Ron , booktitle=. Scaling up the Accuracy of Naive-
-
[38]
2022 , publisher=
Kong, Shuming and Cheng, Weiyu and Shen, Yanyan and Huang, Linpeng , journal=. 2022 , publisher=
2022
-
[39]
2023 , organization=
Lee, Chaejeong and Kim, Jayoung and Park, Noseong , booktitle=. 2023 , organization=
2023
-
[40]
arXiv preprint arXiv:2307.03875 , year=
Large Language Models for Supply Chain Optimization , author=. arXiv preprint arXiv:2307.03875 , year=
-
[41]
IEEE Transactions on Knowledge and Data Engineering , year=
Optimization Techniques for Unsupervised Complex Table Reasoning via Self-Training Framework , author=. IEEE Transactions on Knowledge and Data Engineering , year=
-
[42]
Standing on the Shoulders of
Lin, Hsiao-Ying , journal=. Standing on the Shoulders of. 2023 , publisher=
2023
-
[43]
Lipman, Yaron and Chen, Ricky T. Q. and Ben-Hamu, Heli and Nickel, Maximilian and Le, Matt , title=. The Eleventh International Conference on Learning Representations , year=
-
[45]
Liu, Tennison and Qian, Zhaozhi and Berrevoets, Jeroen and van der Schaar, Mihaela , booktitle=
-
[46]
arXiv preprint arXiv:2312.16702 , year=
Rethinking Tabular Data Understanding with Large Language Models , author=. arXiv preprint arXiv:2312.16702 , year=
-
[47]
Proceedings of the 14th Learning Analytics and Knowledge Conference , pages=
Scaling While Privacy Preserving: A Comprehensive Synthetic Tabular Data Generation and Evaluation in Learning Analytics , author=. Proceedings of the 14th Learning Analytics and Knowledge Conference , pages=
-
[48]
2024 , publisher=
Neural Abstractive Summarization for Long Documents , author=. 2024 , publisher=
2024
-
[49]
International Journal of Production Research , pages=
Leveraging Synthetic Data to Tackle Machine Learning Challenges in Supply Chains: Challenges, Methods, Applications, and Research Opportunities , author=. International Journal of Production Research , pages=. 2024 , publisher=
2024
-
[50]
arXiv preprint arXiv:2502.04055 , year=
Long, Yunbo and Xu, Liming and Brintrup, Alexandra , title=. arXiv preprint arXiv:2502.04055 , year=. 2502.04055 , archivePrefix=
-
[51]
Machine learning for synthetic data generation: a review.arXiv preprint arXiv:2302.04062, 2023
Machine Learning for Synthetic Data Generation: A Review , author=. arXiv preprint arXiv:2302.04062 , year=
-
[52]
Margeloiu, Andrei and Jiang, Xiangjian and Simidjievski, Nikola and Jamnik, Mateja , journal=
-
[53]
Annals of Operations Research , volume=
Big Data and Supply Chain Management: A Review and Bibliometric Analysis , author=. Annals of Operations Research , volume=. 2018 , publisher=
2018
-
[54]
arXiv preprint arXiv:2312.10431 , year=
Continuous Diffusion for Mixed-Type Tabular Data , author=. arXiv preprint arXiv:2312.10431 , year=
-
[55]
International Conference on Multimedia Modeling , pages=
Generation of Synthetic Tabular Healthcare Data Using Generative Adversarial Networks , author=. International Conference on Multimedia Modeling , pages=. 2023 , organization=
2023
-
[56]
Statistics & Probability Letters , volume=
Sparse Spatial Autoregressions , author=. Statistics & Probability Letters , volume=. 1997 , publisher=
1997
-
[57]
Electronics , volume=
Exploring Innovative Approaches to Synthetic Tabular Data Generation , author=. Electronics , volume=. 2024 , publisher=
2024
-
[58]
2023 , note=
Poslavskaya, Ekaterina and Korolev, Alexey , title=. 2023 , note=
2023
-
[59]
Applied Artificial Intelligence , volume=
Missing Data Imputation for Supervised Learning , author=. Applied Artificial Intelligence , volume=. 2018 , publisher=
2018
-
[60]
International Journal of Production Research , volume=
Financial Ripple Effect in Complex Adaptive Supply Networks: An Agent-Based Model , author=. International Journal of Production Research , volume=. 2024 , publisher=
2024
-
[61]
arXiv preprint arXiv:2408.10548 , year=
Language Modeling on Tabular Data: A Survey of Foundations, Techniques and Evolution , author=. arXiv preprint arXiv:2408.10548 , year=
-
[62]
Sattarov, Timur and Schreyer, Marco and Borth, Damian , booktitle=
-
[63]
IEEE Transactions on Knowledge and Data Engineering , volume=
A Crowdsourcing Framework for Collecting Tabular Data , author=. IEEE Transactions on Knowledge and Data Engineering , volume=. 2019 , publisher=
2019
-
[64]
Shi, Juntong and Xu, Minkai and Hua, Harper and Zhang, Hengrui and Ermon, Stefano and Leskovec, Jure , title=. arXiv preprint arXiv:2410.20626 , year=
-
[65]
Si, Jacob and Ou, Zijing and Qu, Mike and Li, Yingzhen , note=
-
[66]
Solatorio, Aivin V and Dupriez, Olivier , journal=
-
[67]
Suh, Namjoon and Yang, Yuning and Hsieh, Din-Yin and Luan, Qitong and Xu, Shirong and Zhu, Shixiang and Cheng, Guang , journal=
-
[68]
Table Meets
Sui, Yuan and Zhou, Mengyu and Zhou, Mingjie and Han, Shi and Zhang, Dongmei , booktitle=. Table Meets
-
[69]
Improving and generalizing flow-based generative models with minibatch optimal transport
Improving and Generalizing Flow-Based Generative Models with Minibatch Optimal Transport , author=. arXiv preprint arXiv:2302.00482 , year=
work page internal anchor Pith review arXiv
-
[70]
LLaMA: Open and Efficient Foundation Language Models
Touvron, Hugo and Lavril, Thibaut and Izacard, Gautier and Martinet, Xavier and Lachaux, Marie-Anne and Lacroix, Timoth. arXiv preprint arXiv:2302.13971 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[71]
arXiv preprint arXiv:2211.11512 , year=
Bursting the Burden Bubble? An Assessment of Sharma et al.'s Counterfactual-Based Fairness Metric , author=. arXiv preprint arXiv:2211.11512 , year=
-
[72]
arXiv preprint arXiv:2406.17673 , year=
van Breugel, Boris and Crabb. arXiv preprint arXiv:2406.17673 , year=
-
[73]
Why Tabular Foundation Models Should be a Research Priority , author=. arXiv preprint arXiv:2405.01147 , year=
-
[74]
Journal of Industrial Information Integration , volume=
Supply Chain Data Integration: A Literature Review , author=. Journal of Industrial Information Integration , volume=. 2020 , publisher=
2020
-
[75]
Applied Soft Computing , pages=
Challenges and Opportunities of Generative Models on Tabular Data , author=. Applied Soft Computing , pages=. 2024 , publisher=
2024
-
[76]
Wang, Yuxin and Feng, Duanyu and Dai, Yongfu and Chen, Zhengyu and Huang, Jimin and Ananiadou, Sophia and Xie, Qianqian and Wang, Hao , journal=
-
[77]
Chapman--Kolmogorov Equation , year=
-
[78]
A Brief Overview of
Wu, Tianyu and He, Shizhu and Liu, Jingping and Sun, Siqi and Liu, Kang and Han, Qing-Long and Tang, Yang , journal=. A Brief Overview of. 2023 , publisher=
2023
-
[79]
International Journal of Production Economics , volume=
Will Bots Take Over the Supply Chain? Revisiting Agent-Based Supply Chain Automation , author=. International Journal of Production Economics , volume=. 2021 , publisher=
2021
-
[80]
Advances in Neural Information Processing Systems 32 , editor=
Xu, Lei and Skoularidou, Maria and Cuesta-Infante, Alfredo and Veeramachaneni, Kalyan , title=. Advances in Neural Information Processing Systems 32 , editor=. 2019 , publisher=
2019
-
[81]
Computers in Industry , volume=
On Implementing Autonomous Supply Chains: A Multi-Agent System Approach , author=. Computers in Industry , volume=. 2024 , publisher=
2024
-
[82]
IFAC-PapersOnLine , volume=
Multi-Agent Systems and Foundation Models Enable Autonomous Supply Chains: Opportunities and Challenges , author=. IFAC-PapersOnLine , volume=. 2024 , publisher=
2024
-
[83]
Journal of Industrial Information Integration , volume=
Towards Autonomous Supply Chains: Definition, Characteristics, Conceptual Framework, and Autonomy Levels , author=. Journal of Industrial Information Integration , volume=. 2024 , publisher=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.