Recognition: unknown
Accelerating trajectory optimization with Sobolev-trained diffusion policies
Pith reviewed 2026-05-10 02:36 UTC · model grok-4.3
The pith
A first-order Sobolev loss on trajectories and feedback gains trains diffusion policies that warm-start trajectory optimization without compounding errors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We derive a first-order loss for Sobolev learning of diffusion-based policies using both trajectories and feedback gains. The resulting policy avoids compounding errors, and so can learn from very few trajectories to provide initial guesses reducing solving time by 2× to 20×. Incorporating first-order information enables predictions with fewer diffusion steps, reducing inference latency.
What carries the argument
A first-order Sobolev loss applied to diffusion policies that are trained on both optimal trajectories and the feedback gains supplied by gradient-based trajectory optimization solvers.
If this is right
- The policy can be trained on a handful of prior solves and still produce effective warm-starts for new instances.
- Trajectory optimization solvers converge between 2 and 20 times faster when started from the learned guesses.
- Generating each initial guess requires fewer diffusion steps, lowering the computational cost of warm-starting.
- The method applies directly to any gradient-based solver that returns both trajectories and feedback gains.
Where Pith is reading between the lines
- The same first-order training signal could be added to other imitation-learning methods that already have access to sensitivity information.
- Fewer diffusion steps may make the approach viable for real-time warm-starting inside model-predictive control loops.
- The technique suggests a broader pattern: derivative supervision can mitigate distribution shift in long-horizon policy rollouts.
- Hybrid pipelines could alternate between the learned initializer and the optimizer's own refinement steps without full retraining.
Load-bearing premise
Training on trajectories together with their feedback gains through a first-order Sobolev loss is enough to keep policy rollouts inside the training distribution on new problems.
What would settle it
Apply the trained policy to a collection of trajectory optimization problems whose dynamics or constraints lie outside the training set and check whether small deviations grow into compounding errors or whether solve-time reductions fall below 2×.
Figures



read the original abstract
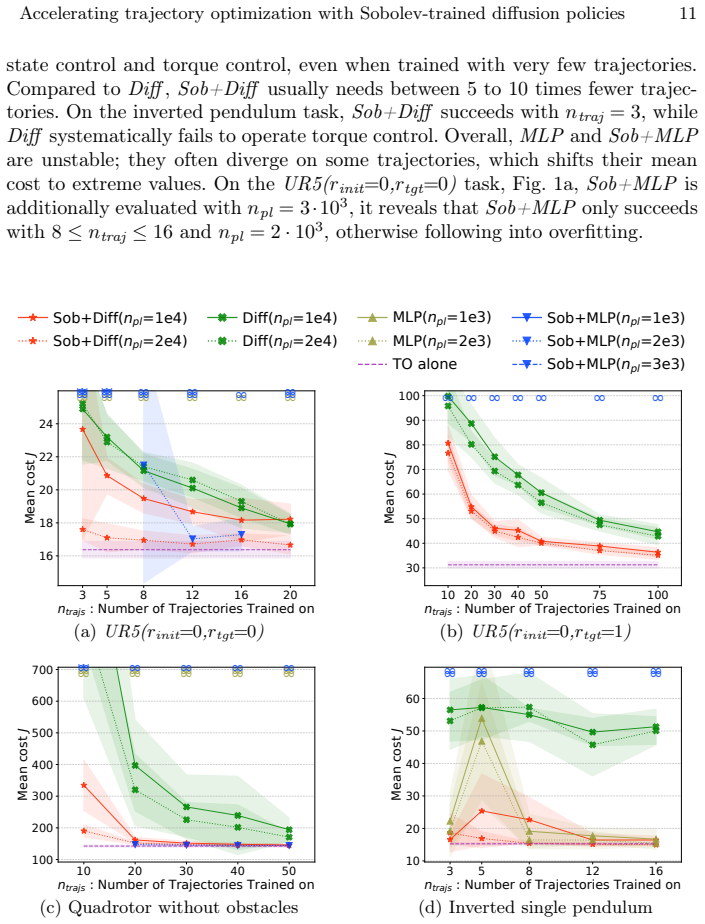
Trajectory Optimization (TO) solvers exploit known system dynamics to compute locally optimal trajectories through iterative improvements. A downside is that each new problem instance is solved independently; therefore, convergence speed and quality of the solution found depend on the initial trajectory proposed. To improve efficiency, a natural approach is to warm-start TO with initial guesses produced by a learned policy trained on trajectories previously generated by the solver. Diffusion-based policies have recently emerged as expressive imitation learning models, making them promising candidates for this role. Yet, a counterintuitive challenge comes from the local optimality of TO demonstrations: when a policy is rolled out, small non-optimal deviations may push it into situations not represented in the training data, triggering compounding errors over long horizons. In this work, we focus on learning-based warm-starting for gradient-based TO solvers that also provide feedback gains. Exploiting this specificity, we derive a first-order loss for Sobolev learning of diffusion-based policies using both trajectories and feedback gains. Through comprehensive experiments, we demonstrate that the resulting policy avoids compounding errors, and so can learn from very few trajectories to provide initial guesses reducing solving time by $2\times$ to $20 \times$. Incorporating first-order information enables predictions with fewer diffusion steps, reducing inference latency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes training diffusion policies for warm-starting gradient-based trajectory optimization (TO) solvers via a first-order Sobolev loss that incorporates both optimal trajectories and the associated feedback gains. The central claim is that this training prevents compounding errors during closed-loop rollout, enabling effective few-shot learning from very few TO trajectories and yielding 2×–20× reductions in solver time, while also permitting fewer diffusion steps at inference to reduce latency.
Significance. If substantiated, the result would be significant for learning-based acceleration of TO in robotics and control, as it directly targets the compounding-error vulnerability of standard imitation learning on locally optimal demonstrations. The explicit use of first-order solver information to stabilize rollouts is a targeted contribution that could extend to other optimization-based planners where feedback gains are available.
major comments (3)
- [Experiments] Experiments section: the abstract states that 'comprehensive experiments' demonstrate avoidance of compounding errors and 2×–20× speedups, yet no details are supplied on the quantification of compounding errors (e.g., state-deviation metrics over multi-step rollouts), the choice of baselines (standard diffusion policies, other warm-start methods), data splits, number of problem instances, or statistical significance testing. Without these, the load-bearing claim that Sobolev training suffices for OOD robustness cannot be evaluated.
- [Method / Loss derivation] Loss derivation (first-order Sobolev term): the loss explicitly imports first-order information (feedback gains) from the external TO solver. The manuscript should clarify whether the reported speedups and latency reductions remain when this external information is withheld at test time, or whether the speedup is partly an artifact of the training distribution being generated by the same solver whose gains are reused.
- [Experiments / Discussion] Rollout analysis: the central assumption—that Sobolev training keeps closed-loop states sufficiently close to the training support for the first-order guidance to remain valid—is load-bearing for the 'avoids compounding errors' claim. No quantitative evidence (e.g., histograms of state deviation, failure-case analysis, or comparison of linearization quality inside vs. outside training support) is referenced, leaving the OOD generalization risk unaddressed.
minor comments (2)
- The abstract would be clearer if it named the specific TO solver(s) and problem domains (e.g., quadrotor, manipulator) used to generate the reported speedups.
- Notation for the Sobolev loss (trajectory vs. gain terms) should be introduced with an explicit equation label for easy reference in later sections.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, indicating the revisions we will incorporate to improve clarity and substantiation of our claims.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the abstract states that 'comprehensive experiments' demonstrate avoidance of compounding errors and 2×–20× speedups, yet no details are supplied on the quantification of compounding errors (e.g., state-deviation metrics over multi-step rollouts), the choice of baselines (standard diffusion policies, other warm-start methods), data splits, number of problem instances, or statistical significance testing. Without these, the load-bearing claim that Sobolev training suffices for OOD robustness cannot be evaluated.
Authors: We agree that additional experimental details are necessary to fully support the claims. In the revised manuscript, we will expand the Experiments section with: explicit state-deviation metrics computed over multi-step closed-loop rollouts to quantify compounding errors; a description of all baselines including standard diffusion policies and alternative warm-start methods; details on data splits, the total number of problem instances tested, and the evaluation protocol; and results from statistical significance testing (e.g., paired t-tests or Wilcoxon tests across instances). These additions will enable direct evaluation of the OOD robustness provided by Sobolev training. revision: yes
-
Referee: [Method / Loss derivation] Loss derivation (first-order Sobolev term): the loss explicitly imports first-order information (feedback gains) from the external TO solver. The manuscript should clarify whether the reported speedups and latency reductions remain when this external information is withheld at test time, or whether the speedup is partly an artifact of the training distribution being generated by the same solver whose gains are reused.
Authors: We welcome the chance to clarify the distinction. The first-order Sobolev term incorporating feedback gains is used only during training to shape the policy; at test time the policy is deployed standalone to produce warm-start trajectories and requires no access to gains or solver internals. The reported speedups are therefore measured under exactly this test-time condition. The training data are generated by the TO solver, which is standard for imitation-learning warm-starters, but the policy itself does not reuse gains at inference. We will add an explicit paragraph in the Method section stating this separation and include an ablation that isolates the contribution of the Sobolev term to the observed speedups and latency reductions. revision: yes
-
Referee: [Experiments / Discussion] Rollout analysis: the central assumption—that Sobolev training keeps closed-loop states sufficiently close to the training support for the first-order guidance to remain valid—is load-bearing for the 'avoids compounding errors' claim. No quantitative evidence (e.g., histograms of state deviation, failure-case analysis, or comparison of linearization quality inside vs. outside training support) is referenced, leaving the OOD generalization risk unaddressed.
Authors: We acknowledge that the current manuscript would be strengthened by quantitative rollout analysis. In the revision we will add a dedicated subsection that presents: histograms of state deviations observed during closed-loop rollouts; a failure-case breakdown; and direct comparisons of linearization quality (e.g., validity of first-order approximations) for states inside versus outside the training support. These results will provide concrete evidence that Sobolev training keeps trajectories sufficiently close to the training distribution, thereby mitigating compounding errors. revision: yes
Circularity Check
No circularity: loss derivation uses external TO gains; speedup claims are experimental
full rationale
The paper derives a first-order Sobolev loss that incorporates trajectory data plus feedback gains supplied by the external TO solver. This loss is not self-definitional or a renaming of the input data. The central claims (avoidance of compounding errors, few-shot learning, and 2-20x speedups) are presented as outcomes of comprehensive experiments on rollout behavior rather than quantities forced by the training distribution or by self-citation. No load-bearing self-citation, uniqueness theorem, or fitted-input-called-prediction pattern appears in the derivation chain. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Diffusion models can be trained via imitation on locally optimal TO trajectories
- domain assumption Feedback gains supply useful first-order information that mitigates compounding errors
Reference graph
Works this paper leans on
-
[1]
Ajay, A., Du, Y., Gupta, A., Tenenbaum, J., Jaakkola, T., Agrawal, P.: Is con- ditional generative modeling all you need for decision-making? arXiv preprint arXiv:2211.15657 (2022)
work page internal anchor Pith review arXiv 2022
-
[2]
In: 6th Annual Learning for Dynamics & Control Conference
Alboni, E., Grandesso, G., Papini, G.P.R., Carpentier, J., Del Prete, A.: Cacto-sl: Using sobolev learning to improve continuous actor-critic with trajectory optimiza- tion. In: 6th Annual Learning for Dynamics & Control Conference. pp. 1452–1463. PMLR (2024)
2024
-
[3]
Advances in neural in- formation processing systems31(2018)
de Avila Belbute-Peres, F., Smith, K., Allen, K., Tenenbaum, J., Kolter, J.Z.: End-to-end differentiable physics for learning and control. Advances in neural in- formation processing systems31(2018)
2018
-
[4]
In: Robotics: Science and systems (RSS 2018) (2018)
Carpentier, J., Mansard, N.: Analytical derivatives of rigid body dynamics algo- rithms. In: Robotics: Science and systems (RSS 2018) (2018)
2018
-
[5]
In: IEEE Inter- national Symposium on System Integrations (SII) (2019)
Carpentier, J., Saurel, G., Buondonno, G., Mirabel, J., Lamiraux, F., Stasse, O., Mansard, N.: The pinocchio c++ library – a fast and flexible implementation of rigid body dynamics algorithms and their analytical derivatives. In: IEEE Inter- national Symposium on System Integrations (SII) (2019)
2019
-
[6]
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
Chi, C., Feng, S., Du, Y., Xu, Z., Cousineau, E., Burchfiel, B., Song, S.: Dif- fusion policy: Visuomotor policy learning via action diffusion. arXiv preprint arXiv:2303.04137 (2023)
work page internal anchor Pith review arXiv 2023
-
[7]
Advances in neural information processing systems 30(2017)
Czarnecki, W.M., Osindero, S., Jaderberg, M., Swirszcz, G., Pascanu, R.: Sobolev training for neural networks. Advances in neural information processing systems 30(2017)
2017
-
[8]
IEEE Robotics and Automation Letters7(2) (2022)
Dantec, E., Taix, M., Mansard, N.: First order approximation of model predictive control solutions for high frequency feedback. IEEE Robotics and Automation Letters7(2) (2022)
2022
-
[9]
Advanced Robotics31(22), 1225–1237 (2017)
Giftthaler, M., Neunert, M., Stäuble, M., Frigerio, M., Semini, C., Buchli, J.: Au- tomatic differentiation of rigid body dynamics for optimal control and estimation. Advanced Robotics31(22), 1225–1237 (2017)
2017
-
[10]
IEEE Robotics and Automation Letters8(6), 3318–3325 (2023)
Grandesso, G., Alboni, E., Papini, G.P.R., Wensing, P.M., Del Prete, A.: Cacto: Continuous actor-critic with trajectory optimization—towards global optimality. IEEE Robotics and Automation Letters8(6), 3318–3325 (2023)
2023
-
[11]
Advances in neural information processing systems33(2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems33(2020)
2020
-
[12]
Jacobson, D.H., Mayne, D.Q.: Differential dynamic programming (1970)
1970
-
[13]
IEEE Transactions on Robotics (2025)
Jallet, W., Bambade, A., Arlaud, E., El-Kazdadi, S., Mansard, N., Carpentier, J.: ProxDDP: Proximal constrained trajectory optimization. IEEE Transactions on Robotics (2025)
2025
-
[14]
Jallet, W., Bambade, A., El Kazdadi, S., Carpentier, J., Nicolas, M.: aligator, https://github.com/Simple-Robotics/aligator
-
[15]
In: International Conference on Machine Learning
Janner, M., Du, Y., Tenenbaum, J., Levine, S.: Planning with diffusion for flexi- ble behavior synthesis. In: International Conference on Machine Learning. PMLR (2022)
2022
-
[16]
In: 2023 IEEE International Conference on Robotics and Automation (ICRA)
Le Lidec, Q., Jallet, W., Laptev, I., Schmid, C., Carpentier, J.: Enforcing the con- sensus between trajectory optimization and policy learning for precise robot con- trol. In: 2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE (2023)
2023
-
[17]
IEEE Robotics and Automation Let- ters6(2) (2021) 18 T
Le Lidec, Q., Kalevatykh, I., Laptev, I., Schmid, C., Carpentier, J.: Differentiable simulation for physical system identification. IEEE Robotics and Automation Let- ters6(2) (2021) 18 T. Le Hellard, F. Nguimatsia Tiofack, Q. Le Lidec and J. Carpentier
2021
-
[18]
IEEE Transactions on robotics 21(4), 657–667 (2005)
Lee, S.H., Kim, J., Park, F.C., Kim, M., Bobrow, J.E.: Newton-type algorithms for dynamics-based robot movement optimization. IEEE Transactions on robotics 21(4), 657–667 (2005)
2005
-
[19]
The Journal of Machine Learning Research17(1) (2016)
Levine,S.,Finn,C.,Darrell,T.,Abbeel,P.:End-to-endtrainingofdeepvisuomotor policies. The Journal of Machine Learning Research17(1) (2016)
2016
-
[20]
In: International conference on ma- chine learning
Levine, S., Koltun, V.: Guided policy search. In: International conference on ma- chine learning. PMLR (2013)
2013
-
[21]
doi:10.48550/arXiv.2403.05571 , abstract =
Li, A., Ding, Z., Dieng, A.B., Beeson, R.: Diffusolve: Diffusion-based solver for non-convex trajectory optimization. arXiv preprint arXiv:2403.05571 (2024)
-
[22]
In: First International Conference on Informatics in Control, Automation and Robotics
Li, W., Todorov, E.: Iterative linear quadratic regulator design for nonlinear bi- ological movement systems. In: First International Conference on Informatics in Control, Automation and Robotics. vol. 2. SciTePress (2004)
2004
-
[23]
End- to-end and highly-efficient differentiable simulation for robotics,
Lidec, Q.L., Montaut, L., de Mont-Marin, Y., Schramm, F., Carpentier, J.: End- to-end and highly-efficient differentiable simulation for robotics. arXiv preprint arXiv:2409.07107 (2024)
-
[24]
In: 11th International Conference on Learning Representations, ICLR 2023 (2023)
Lipman, Y., Chen, R.T., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for gen- erative modeling. In: 11th International Conference on Learning Representations, ICLR 2023 (2023)
2023
-
[25]
Advances in neural information processing systems5(1992)
Mitchell, T.M., Thrun, S.B.: Explanation-based neural network learning for robot control. Advances in neural information processing systems5(1992)
1992
-
[26]
Mordatch, I., Todorov, E., Popović, Z.: Discovery of complex behaviors through contact-invariantoptimization.ACMTransactionsonGraphics(ToG)31(4)(2012)
2012
-
[27]
In: Robotics: Science and Systems
Mordatch, I., Todorov, E.: Combining the benefits of function approximation and trajectory optimization. In: Robotics: Science and Systems. vol. 4 (2014)
2014
-
[28]
arXiv preprint arXiv:2512.03973 (2025)
Nguimatsia Tiofack, F., Le Hellard, T., Schramm, F., Perrin-Gilbert, N., Carpen- tier, J.: Guided flow policy: Learning from high-value actions in offline reinforce- ment learning. arXiv preprint arXiv:2512.03973 (2025)
-
[29]
In: International conference on machine learning
Nichol, A.Q., Dhariwal, P.: Improved denoising diffusion probabilistic models. In: International conference on machine learning. PMLR (2021)
2021
-
[30]
Advances in Neural Information Processing Systems35, 20162–20174 (2022)
Pfrommer, D., Zhang, T., Tu, S., Matni, N.: Tasil: Taylor series imitation learning. Advances in Neural Information Processing Systems35, 20162–20174 (2022)
2022
-
[31]
The International Journal of Robotics Research 33(1), 69–81 (2014)
Posa, M., Cantu, C., Tedrake, R.: A direct method for trajectory optimization of rigid bodies through contact. The International Journal of Robotics Research 33(1), 69–81 (2014)
2014
-
[32]
In: Proceedings of the fourteenth international conference on artificial intelligence and statistics
Ross, S., Gordon, G., Bagnell, D.: A reduction of imitation learning and struc- tured prediction to no-regret online learning. In: Proceedings of the fourteenth international conference on artificial intelligence and statistics. JMLR Workshop and Conference Proceedings (2011)
2011
-
[33]
In: Neural net- works: tricks of the trade
Simard, P.Y., LeCun, Y.A., Denker, J.S., Victorri, B.: Transformation invariance in pattern recognition—tangent distance and tangent propagation. In: Neural net- works: tricks of the trade. Springer (2002)
2002
-
[34]
In: International conference on machine learning
Sohl-Dickstein, J., Weiss, E., Maheswaranathan, N., Ganguli, S.: Deep unsuper- vised learning using nonequilibrium thermodynamics. In: International conference on machine learning. PMLR (2015)
2015
-
[35]
In: 9th Inter- national Conference on Learning Representations, ICLR 2021 (2021)
Song, Y., Sohl-Dickstein, J., Kingma, D.P., Kumar, A., Ermon, S., Poole, B.: Score- based generative modeling through stochastic differential equations. In: 9th Inter- national Conference on Learning Representations, ICLR 2021 (2021)
2021
-
[36]
In: Interna- tional conference on machine learning
Srinivas, S., Fleuret, F.: Knowledge transfer with jacobian matching. In: Interna- tional conference on machine learning. pp. 4723–4731. PMLR (2018) Accelerating trajectory optimization with Sobolev-trained diffusion policies 19
2018
-
[37]
Journal of Dynamic Systems, Measurement, and Control147(6), 061002 (2025)
Wang, R., Sharma, A., Parunandi, K.S., Goyal, R., Mohamed, M.N.G., Chakra- vorty, S.: The search for feedback in reinforcement learning. Journal of Dynamic Systems, Measurement, and Control147(6), 061002 (2025)
2025
-
[38]
Diffusion Policies as an Expressive Policy Class for Offline Reinforcement Learning
Wang, Z., Hunt, J.J., Zhou, M.: Diffusion policies as an expressive policy class for offline reinforcement learning. arXiv preprint arXiv:2208.06193 (2022)
work page internal anchor Pith review arXiv 2022
-
[39]
arXiv preprint arXiv:2502.20382 (2025)
Yang, L., Suh, H., Zhao, T., Graesdal, B.P., Kelestemur, T., Wang, J., Pang, T., Tedrake, R.: Physics-driven data generation for contact-rich manipulation via trajectory optimization. arXiv preprint arXiv:2502.20382 (2025)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.