Do Emotions Influence Moral Judgment in Large Language Models?
Pith reviewed 2026-05-10 02:58 UTC · model grok-4.3
The pith
Positive emotions raise moral acceptability ratings in large language models while negative emotions lower them, sometimes reversing binary judgments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
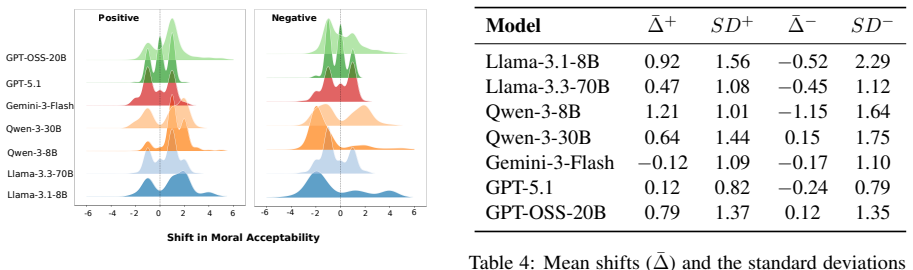
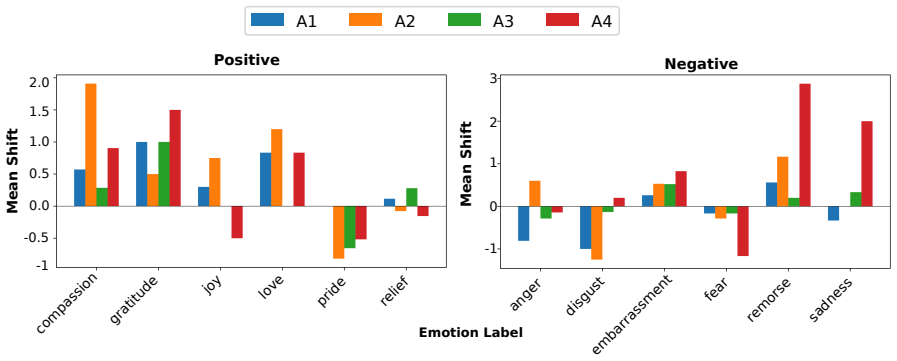
The paper establishes that an emotion-induction pipeline applied to moral situations causes LLMs to alter their assessments of moral acceptability in a valence-dependent manner, with positive emotions increasing and negative emotions decreasing ratings, including up to 20% binary judgment reversals, an inverse relationship between susceptibility and model capability, and occasional deviations from valence expectations such as remorse increasing acceptability, while a parallel human study reveals no comparable systematic influence.
What carries the argument
The emotion-induction pipeline, which embeds targeted emotional states into prompts describing moral dilemmas to quantify resulting changes in acceptability judgments.
Load-bearing premise
The emotion-induction pipeline successfully injects the intended emotion without introducing unrelated prompt artifacts that independently alter moral judgments.
What would settle it
Re-running the moral acceptability ratings with prompts that match the emotional versions in length and structure but contain no emotion words and finding no systematic shifts or judgment reversals.
Figures











read the original abstract
Large language models have been extensively studied for emotion recognition and moral reasoning as distinct capabilities, yet the extent to which emotions influence moral judgment remains underexplored. In this work, we develop an emotion-induction pipeline that infuses emotion into moral situations and evaluate shifts in moral acceptability across multiple datasets and LLMs. We observe a directional pattern: positive emotions increase moral acceptability and negative emotions decrease it, with effects strong enough to reverse binary moral judgments in up to 20% of cases, and with susceptibility scaling inversely with model capability. Our analysis further reveals that specific emotions can sometimes behave contrary to what their valence would predict (e.g., remorse paradoxically increases acceptability). A complementary human annotation study shows humans do not exhibit these systematic shifts, indicating an alignment gap in current LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops an emotion-induction pipeline to infuse emotions into moral situations and evaluates resulting shifts in moral acceptability judgments across multiple datasets and LLMs. It reports a directional pattern in which positive emotions increase moral acceptability and negative emotions decrease it, with effects strong enough to reverse binary judgments in up to 20% of cases and with susceptibility scaling inversely with model capability. Specific emotions sometimes deviate from valence predictions (e.g., remorse increasing acceptability), and a complementary human annotation study finds no such systematic shifts in humans, indicating an alignment gap.
Significance. If the observed shifts prove robust to controls for prompt artifacts and are supported by statistical evidence, the work would provide empirical evidence of an emotion-driven divergence between LLM and human moral reasoning. The inverse scaling observation would be particularly valuable, as it runs counter to typical capability trends and could inform targeted alignment strategies for less capable models.
major comments (2)
- [Abstract] Abstract: The directional effects and 20% reversal rate are reported without any mention of statistical tests, error bars, sample sizes, or explicit controls for prompt length, lexical specificity, or narrative framing. These omissions make it impossible to determine whether the claimed shifts are reliable or attributable to the intended emotional induction.
- [Abstract] Abstract (emotion-induction pipeline description): The pipeline is presented as cleanly infusing emotion, yet no validation is described to rule out confounds such as altered prompt length or structural changes that independently affect moral judgments via known LLM sensitivities (e.g., sycophancy or recency). Without length-matched neutral controls or valence-neutral but structurally identical prompts, the central claim that emotions (rather than artifacts) drive the reversals cannot be isolated.
minor comments (1)
- [Abstract] The abstract would benefit from explicit quantification of effect sizes and dataset/model counts to allow readers to gauge the scope of the 20% reversal claim.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback on our manuscript. We address each major comment below and have revised the abstract and methods sections to improve transparency regarding statistical reporting and controls for potential confounds.
read point-by-point responses
-
Referee: [Abstract] Abstract: The directional effects and 20% reversal rate are reported without any mention of statistical tests, error bars, sample sizes, or explicit controls for prompt length, lexical specificity, or narrative framing. These omissions make it impossible to determine whether the claimed shifts are reliable or attributable to the intended emotional induction.
Authors: We agree that the abstract should explicitly reference the statistical analyses and controls to allow immediate assessment of reliability. The main text reports results from paired statistical tests (e.g., McNemar tests for judgment reversals) with sample sizes exceeding 400 scenarios per condition across models, standard errors shown in figures, and prompt-length matching via token-count equalization plus fixed narrative templates. We will revise the abstract to include a concise statement on these elements and the use of length- and structure-matched controls. revision: yes
-
Referee: [Abstract] Abstract (emotion-induction pipeline description): The pipeline is presented as cleanly infusing emotion, yet no validation is described to rule out confounds such as altered prompt length or structural changes that independently affect moral judgments via known LLM sensitivities (e.g., sycophancy or recency). Without length-matched neutral controls or valence-neutral but structurally identical prompts, the central claim that emotions (rather than artifacts) drive the reversals cannot be isolated.
Authors: We acknowledge that the abstract does not detail the validation steps. The Methods section describes length-matched neutral controls (identical token counts and sentence structure, differing only in the inserted emotion phrase) and includes ablation experiments replacing emotional terms with valence-neutral but structurally parallel phrases to isolate lexical effects. We will expand the abstract to mention these controls and add a short appendix subsection summarizing the ablation results confirming that structural changes alone do not reproduce the observed directional shifts. revision: yes
Circularity Check
No circularity: purely empirical observational study
full rationale
The paper reports results from running an emotion-induction pipeline on LLMs across moral-dilemma datasets, measuring directional shifts in acceptability ratings and reversal rates, plus a human annotation contrast. No equations, fitted parameters, or first-principles derivations appear; the central claims are direct experimental observations rather than quantities defined in terms of the paper's own outputs. Self-citations, if present, are not invoked to establish uniqueness theorems or to smuggle ansatzes. The work is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM responses to moral prompts reflect genuine moral judgments rather than surface-level pattern matching
Reference graph
Works this paper leans on
-
[1]
Moral foundations of large language models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP 2024). Ilias Chalkidis, Abhik Jana, Dirk Hartung, Michael Bommarito, Ion Androutsopoulos, Daniel Katz, and Nikolaos Aletras. 2022. LexGLUE: A benchmark dataset for legal language understanding in English. InProceeding...
work page 2024
-
[2]
InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL 2020)
GoEmotions: A dataset of fine-grained emo- tions. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL 2020). Dario Di Palma, Alessandro De Bellis, Giovanni Serve- dio, Vito Walter Anelli, Fedelucio Narducci, and Tommaso Di Noia. 2025. LLaMAs have feelings too: Unveiling sentiment and emotion representations in LL...
work page 2020
-
[3]
Moral foundations theory: The pragmatic va- lidity of moral pluralism. InAdvances in experimen- tal social psychology. Elsevier. Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, and 1 others. 2024. The llama 3 herd of models.arXiv preprint arXiv:...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Aligning ai with shared human values.arXiv preprint arXiv:2008.02275. Joe Hoover, Gwenyth Portillo-Wightman, Leigh Yeh, Shreya Havaldar, Aida Mostafazadeh Davani, Ying Lin, Brendan Kennedy, Mohammad Atari, Zahra Kamel, Madelyn Mendlen, Gabriela Moreno, Christina Park, Tingyee E. Chang, Jenna Chin, Chris- tian Leong, Jun Yen Leung, Arineh Mirinjian, and Mo...
work page internal anchor Pith review arXiv 2008
-
[5]
When to make exceptions: Exploring language models as accounts of human moral judgment. In Advances in Neural Information Processing Systems (NeurIPS 2022). Kornraphop Kawintiranon and Lisa Singh. 2022. PoliB- ERTweet: A pre-trained language model for analyz- ing political content on Twitter. InProceedings of the Thirteenth Language Resources and Evaluati...
-
[6]
gpt-oss-120b & gpt-oss-20b Model Card
Moral self-licensing: When being good frees us to be bad.Social and personality psychology compass, 4(5):344–357. Nasrin Mostafazadeh, Nathanael Chambers, Xiaodong He, Devi Parikh, Dhruv Batra, Lucy Vanderwende, Pushmeet Kohli, and James Allen. 2016. A corpus and cloze evaluation for deeper understanding of commonsense stories. InProceedings of the 2016 C...
work page internal anchor Pith review arXiv 2016
-
[7]
Levels of valence.Frontiers in Psychology, V olume 4 - 2013. Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, and 1 others. 2025. Openai gpt-5 sys- tem card.Preprint, arXiv:2601.03267. Preprint. arXiv:2601.03267. Ala N. Tak, Amin Banayeeanzade, Anahita Bolourani, Mina Kian, Robin Jia, and Jonathan Gratch. 2025. Mechanistic interpretability of emotion in...
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[8]
Moral emotions and moral behavior.Annu. Rev. Psychol., 58(1):345–372. Piercarlo Valdesolo and David DeSteno. 2006. Ma- nipulations of emotional context shape moral judg- ment.PSYCHOLOGICAL SCIENCE-CAMBRIDGE- , 17(6):476. Xu Wang, Cheng Li, Yi Chang, Jindong Wang, and Yuan Wu. 2024. Negativeprompt: Leveraging psy- chology for large language models enhancem...
work page internal anchor Pith review Pith/arXiv arXiv 2006
- [9]
- [10]
- [11]
-
[12]
“[Adverb] [exact situation]” (e.g.,angrily, sadly,proudly) The prompt explicitly prohibits explanatory ad- ditions (e.g., “because. . . ” or “due to. . . ”) to ensure emotions function as pure affective signals rather than causal justifications. Models are instructed to select the most natural-sounding template for each emotion while keeping the underlyin...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.