Silicon Aware Neural Networks
Pith reviewed 2026-05-10 02:59 UTC · model grok-4.3
The pith
Trained differentiable logic gate networks map one-to-one onto custom silicon macros that classify MNIST images at 97 percent accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By converting trained DLGN models to gate-level netlists using a standard cell library and optimizing with an area-based loss, we create silicon implementations that perform MNIST classification with 97% accuracy at 41.8 million inferences per second consuming 83.88 mW.
What carries the argument
The one-to-one mapping from a trained Differentiable Logic Gate Network to a standard-cell netlist, together with an area-minimizing loss that penalizes expected cell area per neuron.
If this is right
- Neural networks built from logic gates can be realized directly in silicon without intermediate FPGA or software layers.
- Training with an area penalty produces smaller, lower-power circuits suitable for edge devices.
- The same conversion flow works for any DLGN that has been trained on discrete logic gates.
- Post-layout power numbers become available early in the design cycle because the netlist is already standard-cell based.
Where Pith is reading between the lines
- The approach could be tested on larger image datasets to check whether accuracy and area scale together.
- Combining the area loss with timing-driven placement might further reduce power without retraining.
- The method opens a path to custom AI accelerators that are generated from software models in a single automated step.
Load-bearing premise
The mapping from trained DLGN to standard-cell netlist preserves functional accuracy and the area loss does not create timing violations or unacceptable accuracy loss in the final layout.
What would settle it
Fabricate the hard macro and measure its actual power draw and classification accuracy on real silicon; deviation from the simulated 97 percent accuracy or 83.88 mW would falsify the claim.
Figures


read the original abstract
Recent work in the machine learning literature has demonstrated that deep learning can train neural networks made of discrete logic gate functions to perform simple image classification tasks at very high speeds on CPU, GPU and FPGA platforms. By virtue of being formed by discrete logic gates, these Differentiable Logic Gate Networks (DLGNs) lend themselves naturally to implementation in custom silicon - in this work we present a method to map DLGNs in a one-to-one fashion to a digital CMOS standard cell library by converting the trained model to a gate-level netlist. We also propose a novel loss function whereby the DLGN can optimize the area, and indirectly power consumption, of the resulting circuit by minimizing the expected area per neuron based on the area of the standard cells in the target standard cell library. Finally, we also show for the first time an implementation of a DLGN as a silicon circuit in simulation, performing layout of a DLGN in the SkyWater 130nm process as a custom hard macro using a Cadence standard cell library and performing post-layout power analysis. We find that our custom macro can perform classification on MNIST with 97% accuracy 41.8 million times a second at a power consumption of 83.88 mW.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to provide a one-to-one mapping from trained Differentiable Logic Gate Networks (DLGNs) to standard-cell netlists in a target CMOS library, introduces a novel loss that minimizes expected cell area per neuron during training, and reports the first post-layout simulation of such a network as a hard macro in SkyWater 130 nm, achieving 97% MNIST accuracy at 41.8 million inferences per second while consuming 83.88 mW.
Significance. If the post-layout netlist is shown to preserve the trained model's accuracy, the work would demonstrate a concrete bridge between differentiable logic-gate networks and standard-cell ASIC flows, enabling high-speed, low-power custom silicon inference without FPGA or processor overhead. The use of a real process design kit and post-layout power analysis strengthens the hardware relevance.
major comments (3)
- [Abstract / Results] Abstract and results: the headline claim of 97% accuracy on the silicon macro is presented without any reported re-evaluation of classification accuracy on the gate-level netlist extracted after place-and-route; the one-to-one mapping plus buffer insertion and routing could alter effective logic or timing, yet no such verification is described.
- [Method] Method (area loss): the novel loss minimizes expected area per neuron, but no ablation is provided that isolates its effect on final accuracy versus a baseline DLGN without the loss; this is load-bearing because the loss directly trades off against the performance numbers reported.
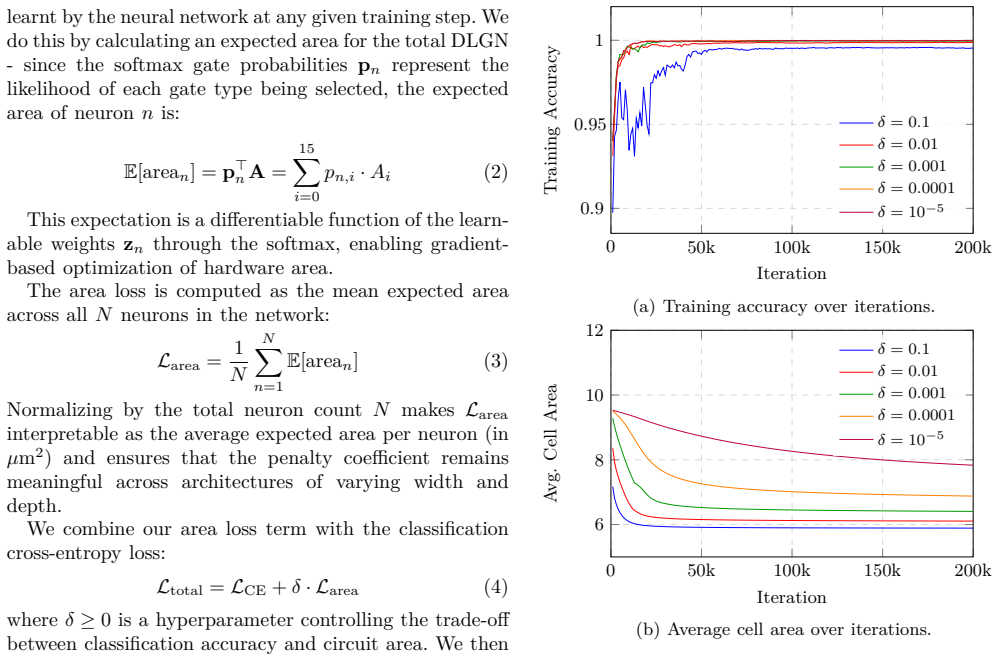
- [Results] Results: the reported figures lack error bars, multiple random seeds, or any sensitivity analysis on clock period versus accuracy, making it impossible to assess whether the 41.8 M inferences/s operating point is robust or merely the maximum frequency before timing violations appear.
minor comments (2)
- The abstract should explicitly name the standard-cell library and the exact tool flow used for synthesis, place-and-route, and power analysis.
- A diagram or table comparing pre-layout versus post-layout gate counts and critical-path delay would clarify the impact of the mapping.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which help strengthen the manuscript. We address each major point below and will revise the paper accordingly where changes are needed.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and results: the headline claim of 97% accuracy on the silicon macro is presented without any reported re-evaluation of classification accuracy on the gate-level netlist extracted after place-and-route; the one-to-one mapping plus buffer insertion and routing could alter effective logic or timing, yet no such verification is described.
Authors: We agree that explicit post-layout verification strengthens the claim. Our synthesis flow uses standard logic-preserving transformations (no logic restructuring or optimization that changes functionality), and inserted buffers are purely for timing. Thus the gate-level netlist remains functionally equivalent to the original DLGN. However, we did not report a separate gate-level simulation of the extracted post-P&R netlist in the submitted version. We will add this verification (extract netlist, run MNIST inference via gate-level simulation, confirm 97% accuracy) to the revised Results and Methods sections. revision: yes
-
Referee: [Method] Method (area loss): the novel loss minimizes expected area per neuron, but no ablation is provided that isolates its effect on final accuracy versus a baseline DLGN without the loss; this is load-bearing because the loss directly trades off against the performance numbers reported.
Authors: We acknowledge the value of an ablation. The area loss was introduced to directly optimize for the target library's cell areas during training, but the submitted manuscript does not compare against an identical DLGN trained without it. We will add an ablation study (train with/without the area term, report final accuracy, total cell area, and power) in the revised Method and Results sections to quantify the accuracy-area trade-off. revision: yes
-
Referee: [Results] Results: the reported figures lack error bars, multiple random seeds, or any sensitivity analysis on clock period versus accuracy, making it impossible to assess whether the 41.8 M inferences/s operating point is robust or merely the maximum frequency before timing violations appear.
Authors: We agree that statistical reporting and sensitivity analysis improve robustness assessment. The 97% accuracy and 41.8 M inferences/s figures come from a single training run and the maximum clock frequency meeting timing in post-layout STA. We will revise the Results section to include (1) accuracy with error bars over multiple random seeds (at least 5), and (2) a plot/table of accuracy versus clock period showing that accuracy remains stable below the reported frequency (as expected for a correctly timed digital circuit). revision: yes
Circularity Check
No significant circularity; performance metrics obtained from external post-layout simulation
full rationale
The paper trains a DLGN using a novel loss that minimizes expected area per neuron drawn from the target standard-cell library, then performs a one-to-one mapping to a gate-level netlist, places and routes it as a hard macro in SkyWater 130 nm, and extracts accuracy, throughput, and power from post-layout simulation. None of the reported figures (97 % MNIST accuracy, 41.8 M inferences/s, 83.88 mW) are obtained by fitting parameters inside the paper and then re-labeling those fits as predictions; the final numbers are produced by an external CAD flow applied to the mapped netlist. No self-definitional equations, fitted-input predictions, or load-bearing self-citations appear in the derivation chain. The area loss influences the training objective but does not mathematically force the post-layout accuracy or power values.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption DLGNs trained on image tasks can be represented as gate-level netlists without functional change
- domain assumption Standard-cell area estimates from the target library are accurate predictors of final layout area
Reference graph
Works this paper leans on
-
[1]
Petersen, Felix and Borgelt, Christian and Kuehne, Hilde and Deussen, Oliver , booktitle=
-
[2]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Petersen, Felix and Kuehne, Hilde and Borgelt, Christian and Welzel, Julian and Ermon, Stefano , title =. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[3]
Edwards, R. Timothy , title =. Workshop on Open-Source EDA Technology (WOSET) , year =
-
[4]
2020 , howpublished =
work page 2020
- [5]
-
[6]
Yaman Umuroglu and Nicholas J. Fraser and Giulio Gambardella and Michaela Blott and Philip Leong and Magnus Jahre and Kees Vissers , title =. Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays , year =
work page 2017
-
[7]
2021 , howpublished =
work page 2021
-
[8]
IEEE Custom Integrated Circuits Conference (CICC) , year =
Xiyuan Tang and others , title =. IEEE Custom Integrated Circuits Conference (CICC) , year =
-
[9]
IEEE Journal of Solid-State Circuits , volume =
Daniel Bankman and Lita Yang and Bert Moons and Mario Verhelst and Boris Murmann , title =. IEEE Journal of Solid-State Circuits , volume =
-
[10]
Aaron Stillmaker and Bevan M. Baas , title =. Integration, the. 2017 , doi =
work page 2017
- [11]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.