Recognition: unknown
Air-Know: Arbiter-Calibrated Knowledge-Internalizing Robust Network for Composed Image Retrieval
Pith reviewed 2026-05-10 02:04 UTC · model grok-4.3
The pith
Air-Know uses an offline MLLM expert to build a clean anchor set, internalizes its logic in a lightweight proxy, and diverts data into separate streams to break the vicious cycle of noise identification in composed image retrieval.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Air-Know proposes the Expert-Proxy-Diversion decoupling paradigm in which External Prior Arbitration employs Multimodal Large Language Models as an offline expert to construct a high-precision anchor dataset, Expert Knowledge Internalization efficiently transfers the expert's discriminative logic to a lightweight proxy arbiter, and Dual Stream Reconciliation uses the proxy's matching confidence to divert training data into a clean alignment stream and a representation feedback reconciliation stream, thereby preventing the self-dependent vicious cycle and representation pollution that plague existing robust methods under noisy triplet conditions.
What carries the argument
The Expert-Proxy-Diversion decoupling paradigm, which separates offline expert arbitration from online proxy training and data diversion to prevent interdependence between the learner and the noise arbiter.
If this is right
- Air-Know significantly outperforms existing state-of-the-art robust methods under the Noisy Triplet Correspondence setting on multiple Composed Image Retrieval benchmark datasets.
- The network remains competitive with strong methods on traditional clean Composed Image Retrieval tasks without noise.
- The decoupling prevents catastrophic representation pollution by removing the direct dependence between the training learner and the noise identification process.
- The approach handles semantic ambiguities such as partial matching without relying on the small-loss hypothesis that fails in this domain.
Where Pith is reading between the lines
- The knowledge-internalization step suggests that large multimodal models can serve as one-time teachers whose logic is distilled into smaller, faster models for ongoing use in retrieval pipelines.
- If the anchor-construction step generalizes beyond image-text pairs, the same expert-proxy structure could apply to other noisy multimodal correspondence tasks such as video-text or audio-text retrieval.
- Improvements in future Multimodal Large Language Models would raise anchor quality and therefore lift the entire training process without requiring changes to the main retrieval network.
Load-bearing premise
Multimodal Large Language Models can reliably construct a high-precision anchor dataset that correctly identifies reliable triplets even when composed queries contain semantic ambiguities such as partial matching.
What would settle it
Manually auditing a sample of the MLLM-generated anchor dataset for mislabeled triplets on queries with partial matches, or measuring whether swapping the MLLM expert for a weaker model causes Air-Know's performance to fall back to the level of prior robust baselines on NTC benchmarks.
Figures




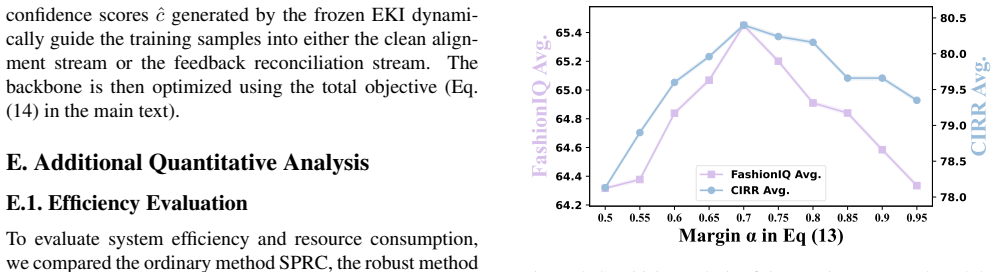
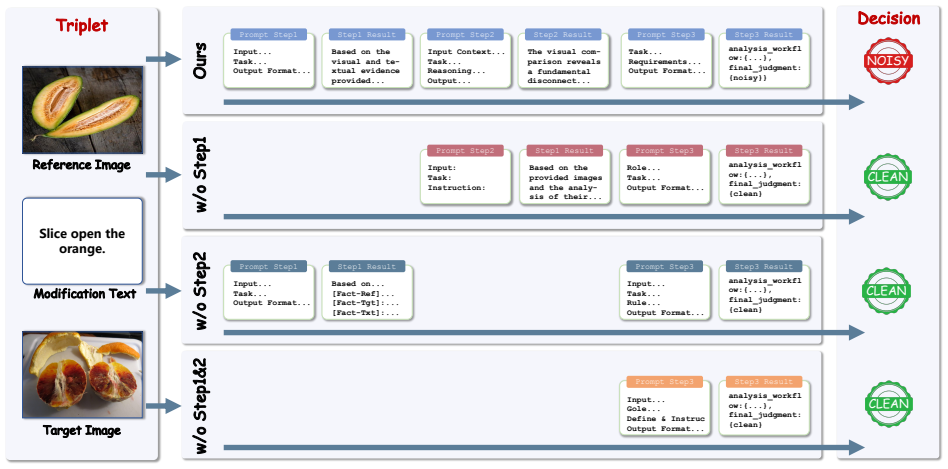





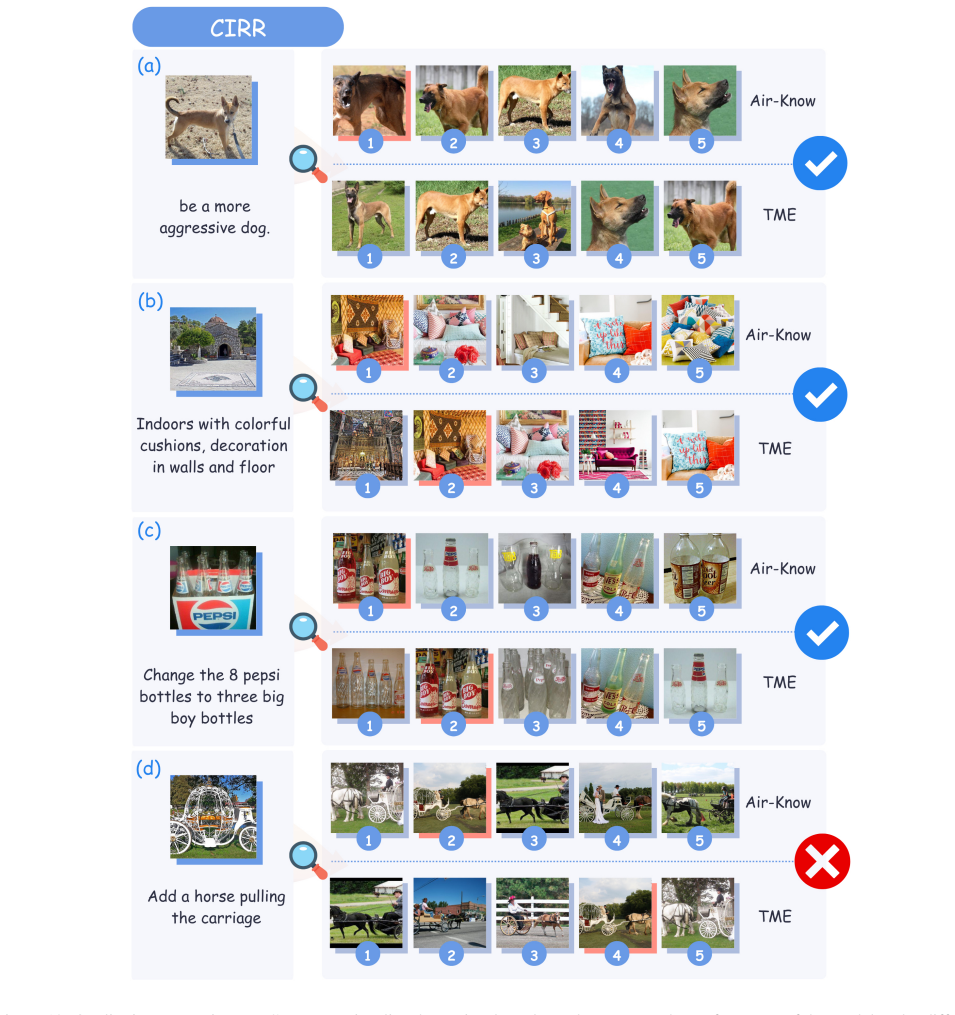

read the original abstract
Composed Image Retrieval (CIR) has attracted significant attention due to its flexible multimodal query method, yet its development is severely constrained by the Noisy Triplet Correspondence (NTC) problem. Most existing robust learning methods rely on the "small loss hypothesis", but the unique semantic ambiguity in NTC, such as "partial matching", invalidates this assumption, leading to unreliable noise identification. This entraps the model in a self dependent vicious cycle where the learner is intertwined with the arbiter, ultimately causing catastrophic "representation pollution". To address this critical challenge, we propose a novel "Expert-Proxy-Diversion" decoupling paradigm, named Air-Know (ArbIteR calibrated Knowledge iNternalizing rObust netWork). Air-Know incorporates three core modules: (1) External Prior Arbitration (EPA), which utilizes Multimodal Large Language Models (MLLMs) as an offline expert to construct a high precision anchor dataset; (2) Expert Knowledge Internalization (EKI), which efficiently guides a lightweight proxy "arbiter" to internalize the expert's discriminative logic; (3) Dual Stream Reconciliation (DSR), which leverages the EKI's matching confidence to divert the training data, achieving a clean alignment stream and a representation feedback reconciliation stream. Extensive experiments on multiple CIR benchmark datasets demonstrate that Air-Know significantly outperforms existing SOTA methods under the NTC setting, while also showing strong competitiveness in traditional CIR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Air-Know, a robust network for Composed Image Retrieval addressing the Noisy Triplet Correspondence (NTC) problem via an 'Expert-Proxy-Diversion' decoupling paradigm. It consists of three modules: External Prior Arbitration (EPA) using offline Multimodal Large Language Models (MLLMs) to generate a high-precision anchor dataset, Expert Knowledge Internalization (EKI) to distill the expert logic into a lightweight proxy arbiter, and Dual Stream Reconciliation (DSR) to separate training data into a clean alignment stream and a representation feedback stream. The authors claim that this approach significantly outperforms existing SOTA methods under the NTC setting while remaining competitive in traditional CIR on multiple benchmark datasets.
Significance. If the experimental claims hold, the work provides a meaningful advance in robust multimodal retrieval by explicitly decoupling the arbiter from the learner to avoid self-reinforcing noise cycles, a common failure mode when semantic ambiguities invalidate small-loss assumptions. The use of external offline experts for anchor construction and subsequent internalization offers a reusable template for other noisy supervision settings in vision-language tasks.
major comments (2)
- [Abstract and §3.1] Abstract and §3.1 (EPA module): The central claim of SOTA outperformance under NTC depends on the EPA module reliably producing high-precision anchors despite the very semantic ambiguities (e.g., partial matching) that the abstract states invalidate the small-loss hypothesis. No quantitative validation, error analysis, or prompting details are supplied showing MLLM robustness on NTC-specific partial-match cases; if MLLM judgments contain systematic errors here, the logic internalized by EKI and the diversion performed by DSR will propagate those errors, recreating representation pollution.
- [§4 Experiments] §4 Experiments: The abstract asserts 'extensive experiments' demonstrate significant outperformance, yet supplies no concrete metrics, baselines, NTC construction protocol, ablation results on the three modules, or statistical tests. Without these, the strength of evidence for the load-bearing claim cannot be assessed.
minor comments (2)
- [Title and Abstract] The title and abstract acronym ('ArbIteR calibrated Knowledge iNternalizing rObust netWork') is inventive but the capitalization pattern is non-standard and may confuse readers; a conventional expansion would improve clarity.
- [Abstract] The abstract would be strengthened by including at least one key quantitative result (e.g., recall@K improvement on a named dataset) to support the performance claims.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below with clarifications and commit to revisions that strengthen the evidence and transparency of the work.
read point-by-point responses
-
Referee: [Abstract and §3.1] Abstract and §3.1 (EPA module): The central claim of SOTA outperformance under NTC depends on the EPA module reliably producing high-precision anchors despite the very semantic ambiguities (e.g., partial matching) that the abstract states invalidate the small-loss hypothesis. No quantitative validation, error analysis, or prompting details are supplied showing MLLM robustness on NTC-specific partial-match cases; if MLLM judgments contain systematic errors here, the logic internalized by EKI and the diversion performed by DSR will propagate those errors, recreating representation pollution.
Authors: We agree that explicit validation of the EPA module's reliability on partial-match cases is essential to support the decoupling claims. In the revised manuscript we will expand §3.1 with a new subsection containing: (i) quantitative precision/recall metrics on a held-out set of manually annotated NTC triplets focused on partial matching, (ii) a categorized error analysis of MLLM judgments with representative failure cases, and (iii) the exact prompting templates and temperature settings used for the offline MLLM. These additions will demonstrate that the external expert maintains high fidelity on the targeted ambiguities, thereby justifying safe knowledge internalization by EKI and clean diversion by DSR. revision: yes
-
Referee: [§4 Experiments] §4 Experiments: The abstract asserts 'extensive experiments' demonstrate significant outperformance, yet supplies no concrete metrics, baselines, NTC construction protocol, ablation results on the three modules, or statistical tests. Without these, the strength of evidence for the load-bearing claim cannot be assessed.
Authors: We acknowledge that the experimental section requires greater explicitness. Although the manuscript already reports results across multiple benchmarks, the revision will expand §4 to include: the full NTC construction protocol (including how partial-match noise is synthetically introduced while preserving semantic structure), complete tables listing all baselines with numerical metrics, module-wise ablation studies quantifying the contribution of EPA, EKI, and DSR, and statistical significance tests (paired t-tests with p-values). These additions will be placed in the main text and supplementary material to allow full assessment of the claims. revision: yes
Circularity Check
No significant circularity; external MLLM decouples the process
full rationale
The paper's core derivation introduces an external offline MLLM in the EPA module to generate the anchor dataset before any proxy training or diversion occurs. This explicitly breaks the self-dependent vicious cycle described in the abstract. No load-bearing step reduces by construction to its own inputs: there are no self-definitional relations, no fitted parameters renamed as predictions, and no uniqueness theorems or ansatzes imported via self-citation. The outperformance claims rest on benchmark experiments that are independent of the internal logic. The method is self-contained against external validation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multimodal Large Language Models can serve as an offline expert to construct a high-precision anchor dataset for composed image queries despite semantic ambiguities
invented entities (4)
-
Expert-Proxy-Diversion decoupling paradigm
no independent evidence
-
External Prior Arbitration (EPA) module
no independent evidence
-
Expert Knowledge Internalization (EKI) module
no independent evidence
-
Dual Stream Reconciliation (DSR) module
no independent evidence
Forward citations
Cited by 4 Pith papers
-
ConeSep: Cone-based Robust Noise-Unlearning Compositional Network for Composed Image Retrieval
ConeSep tackles noisy triplet correspondences in composed image retrieval by introducing geometric fidelity quantization to locate noise, negative boundary learning for semantic opposites, and targeted unlearning via ...
-
OmniTrend: Content-Context Modeling for Scalable Social Popularity Prediction
OmniTrend predicts popularity by combining separate content attractiveness and contextual exposure predictors using cross-modal and exogenous signals.
-
HotComment: A Benchmark for Evaluating Popularity of Online Comments
HotComment is a new multimodal benchmark that quantifies online comment popularity via content quality assessment, interaction-based prediction, and agent-simulated user engagement, accompanied by the StyleCmt stylist...
-
CurEvo: Curriculum-Guided Self-Evolution for Video Understanding
CurEvo integrates curriculum guidance into self-evolution to structure autonomous improvement of video understanding models, yielding gains on VideoQA benchmarks.
Reference graph
Works this paper leans on
-
[1]
Learning with noisy triplet corre- spondence for composed image retrieval
Shuxian Li, Changhao He, Xiting Liu, Joey Tianyi Zhou, Xi Peng, and Peng Hu. Learning with noisy triplet corre- spondence for composed image retrieval. InCVPR, pages 19628–19637, 2025. 2, 3, 6, 7
2025
-
[2]
Habit: Chrono- synergia robust progressive learning framework for com- posed image retrieval
Zixu Li, Yupeng Hu, Zhiwei Chen, Shiqi Zhang, Qinlei Huang, Zhiheng Fu, and Yinwei Wei. Habit: Chrono- synergia robust progressive learning framework for com- posed image retrieval. InAAAI, pages 6762–6770, 2026. 6, 7
2026
-
[3]
arXiv preprint arXiv:2603.29291 (2026)
Guozhi Qiu, Zhiwei Chen, Zixu Li, Qinlei Huang, Zhiheng Fu, Xuemeng Song, and Yupeng Hu. Melt: Improve com- posed image retrieval via the modification frequentation- rarity balance network.arXiv preprint arXiv:2603.29291,
-
[4]
Intent: Invariance and discrimination-aware noise mitigation for robust com- posed image retrieval
Zhiwei Chen, Yupeng Hu, Zhiheng Fu, Zixu Li, Jiale Huang, Qinlei Huang, and Yinwei Wei. Intent: Invariance and discrimination-aware noise mitigation for robust com- posed image retrieval. InAAAI, pages 20463–20471, 2026. 2, 6, 7
2026
-
[5]
Chat-driven text generation and interaction for person retrieval
Zequn Xie, Chuxin Wang, Yeqiang Wang, Sihang Cai, Shulei Wang, and Tao Jin. Chat-driven text generation and interaction for person retrieval. InEMNLP, pages 5259– 5270, 2025
2025
-
[6]
Sentence-level prompts benefit composed image retrieval
Xinxing Xu, Yong Liu, Salman Khan, Fahad Khan, Wang- meng Zuo, Rick Siow Mong Goh, Chun-Mei Feng, et al. Sentence-level prompts benefit composed image retrieval. InICLR, 2024. 6, 7
2024
-
[7]
arXiv preprint arXiv:2604.01617 (2026)
Qianyun Yang, Zhiwei Chen, Yupeng Hu, Zixu Li, Zhi- heng Fu, and Liqiang Nie. Stable: Efficient hybrid nearest neighbor search via magnitude-uniformity and cardinality- robustness.arXiv preprint arXiv:2604.01617, 2026
-
[8]
Queries are not alone: Clustering text embeddings for video search
Peiyang Liu, Xi Wang, Ziqiang Cui, and Wei Ye. Queries are not alone: Clustering text embeddings for video search. InACM SIGIR, pages 874–883, 2025
2025
-
[9]
Qure: Query-relevant re- trieval through hard negative sampling in composed image retrieval
Jaehyun Kwak, Ramahdani Muhammad Izaaz Inhar, Se- Young Yun, and Sung-Ju Lee. Qure: Query-relevant re- trieval through hard negative sampling in composed image retrieval. InICML, pages 32063–32077. PMLR, 2025. 6, 7
2025
-
[10]
Retrieval-based unsupervised noisy label detection on text data
Peiyang Liu, Jinyu Yang, Lin Wang, Sen Wang, Yunlai Hao, and Huihui Bai. Retrieval-based unsupervised noisy label detection on text data. InACM CIKM, pages 4099–4104, 2023
2023
-
[11]
Conquer: Context-aware representation with query enhancement for text-based person search,
Zequn Xie. Conquer: Context-aware representation with query enhancement for text-based person search.arXiv preprint arXiv:2601.18625, 2026
-
[12]
Core-mmrag: Cross-source knowledge recon- ciliation for multimodal rag
Yang Tian, Fan Liu, Jingyuan Zhang, Yupeng Hu, Liqiang Nie, et al. Core-mmrag: Cross-source knowledge recon- ciliation for multimodal rag. InACL, pages 32967–32982, 2025
2025
-
[13]
Hdnet: A hybrid domain network with multi-scale high-frequency information en- hancement for infrared small target detection.IEEE TGRS, 2025
Mingzhu Xu, Chenglong Yu, Zexuan Li, Haoyu Tang, Yu- peng Hu, and Liqiang Nie. Hdnet: A hybrid domain network with multi-scale high-frequency information en- hancement for infrared small target detection.IEEE TGRS, 2025
2025
-
[14]
Transforming time and space: efficient video super- resolution with hybrid attention and deformable transform- ers.The Visual Computer, pages 1–12, 2025
Linling Jiang, Xin Wang, Fan Zhang, and Caiming Zhang. Transforming time and space: efficient video super- resolution with hybrid attention and deformable transform- ers.The Visual Computer, pages 1–12, 2025
2025
-
[15]
Llava steering: Vi- sual instruction tuning with 500x fewer parameters through modality linear representation-steering
Jinhe Bi, Yujun Wang, Haokun Chen, Xun Xiao, Artur Hecker, V olker Tresp, and Yunpu Ma. Llava steering: Vi- sual instruction tuning with 500x fewer parameters through modality linear representation-steering. InACL, pages 15230–15250, 2025
2025
-
[16]
Reassessing layer pruning in LLMs: New insights and methods
Yao Lu, Hao Cheng, Yujie Fang, Zeyu Wang, Jiaheng Wei, Dongwei Xu, Qi Xuan, and Zhaowei Zhu. Reassessing layer pruning in LLMs: New insights and methods. In ICLR, 2026
2026
-
[17]
Prior knowledge in- tegration via llm encoding and pseudo event regulation for video moment retrieval
Yiyang Jiang, Wengyu Zhang, Xulu Zhang, Xiao-Yong Wei, Chang Wen Chen, and Qing Li. Prior knowledge in- tegration via llm encoding and pseudo event regulation for video moment retrieval. InACM MM, pages 7249–7258,
-
[18]
Chenglin Li, Qianglong Chen, Zhi Li, Feng Tao, Yicheng Li, Hao Chen, Fei Yu, and Yin Zhang. Optimizing instruc- tion synthesis: Effective exploration of evolutionary space with tree search.arXiv preprint arXiv:2410.10392, 2024. 2
-
[19]
Honglin Lin, Chonghan Qin, Zheng Liu, Qizhi Pei, Yu Li, Zhanping Zhong, Xin Gao, Yanfeng Wang, Conghui He, and Lijun Wu. Scientific image synthesis: Benchmark- ing, methodologies, and downstream utility.arXiv preprint arXiv:2601.17027, 2026
-
[20]
InACL Findings, pages 8950–8970, 2025
Yunyao Zhang, Zikai Song, Hang Zhou, Wenfeng Ren, Yi- Ping Phoebe Chen, Junqing Yu, and Wei Yang.ga− s3: Comprehensive social network simulation with group agents. InACL Findings, pages 8950–8970, 2025
2025
-
[21]
Yuanjun Zhang, Fuzel Ahamed Shaik, Suvojit Acharjee, Fahad Khalid, and Mourad Oussalah. Towards reliable mul- timodal disaster severity assessment through preference op- timization and explainable vision-language reasoning.Re- liability Engineering & System Safety, page 112674, 2026
2026
-
[22]
Cotextor: Training-free modular multi- lingual text editing via layered disentanglement and depth- aware fusion
Zhenyu Yu, MOHD Y AMANI IDNA IDRIS, Pei Wang, and Rizwan Qureshi. Cotextor: Training-free modular multi- lingual text editing via layered disentanglement and depth- aware fusion. InNeurIPS, 2025
2025
-
[23]
Delving deeper: Hierarchi- cal visual perception for robust video-text retrieval,
Zequn Xie, Boyun Zhang, Yuxiao Lin, and Tao Jin. Delving deeper: Hierarchical visual perception for robust video-text retrieval.arXiv preprint arXiv:2601.12768, 2026
-
[24]
Topological federated clustering via gravitational po- tential fields under local differential privacy.AAAI, 40(28): 24044–24051, 2026
Yunbo Long, Jiaquan Zhang, Xi Chen, and Alexandra Brin- trup. Topological federated clustering via gravitational po- tential fields under local differential privacy.AAAI, 40(28): 24044–24051, 2026
2026
-
[25]
Jiaye Lin, Yifu Guo, Yuzhen Han, Sen Hu, Ziyi Ni, Licheng Wang, Mingguang Chen, Hongzhang Liu, Ronghao Chen, Yangfan He, et al. Se-agent: Self-evolution trajectory op- timization in multi-step reasoning with llm-based agents. arXiv preprint arXiv:2508.02085, 2025
-
[26]
Coupled mamba: Enhanced multimodal fusion with coupled state space model.NeurIPS, 37:59808–59832, 2024
Wenbing Li, Hang Zhou, Junqing Yu, Zikai Song, and Wei Yang. Coupled mamba: Enhanced multimodal fusion with coupled state space model.NeurIPS, 37:59808–59832, 2024
2024
-
[27]
FLARE: Fully Integration of Vision-Language Representations for Deep Cross-Modal Understanding
Zheng Liu, Mengjie Liu, Jingzhou Chen, Jingwei Xu, Bin Cui, Conghui He, and Wentao Zhang. Fusion: Fully inte- gration of vision-language representations for deep cross- modal understanding.arXiv preprint arXiv:2504.09925, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Autogenic language embedding for coherent point tracking
Zikai Song, Ying Tang, Run Luo, Lintao Ma, Junqing Yu, Yi-Ping Phoebe Chen, and Wei Yang. Autogenic language embedding for coherent point tracking. InACM MM, pages 2021–2030, 2024
2021
-
[29]
Erase: Bypassing collaborative detection of ai counterfeit via comprehensive artifacts elimination.IEEE TDSC, pages 1–18, 2026
Qianyun Yang, Peizhuo Lv, Yingjiu Li, Shengzhi Zhang, Yuxuan Chen, Zhiwei Chen, Zixu Li, and Yupeng Hu. Erase: Bypassing collaborative detection of ai counterfeit via comprehensive artifacts elimination.IEEE TDSC, pages 1–18, 2026
2026
-
[30]
Open multimodal retrieval- augmented factual image generation.arXiv preprint arXiv:2510.22521, 2025
Yang Tian, Fan Liu, Jingyuan Zhang, Wei Bi, Yu- peng Hu, and Liqiang Nie. Open multimodal retrieval- augmented factual image generation.arXiv preprint arXiv:2510.22521, 2025
-
[31]
Prism: Self-pruning intrinsic selection method for training- free multimodal data selection, 2025
Jinhe Bi, Yifan Wang, Danqi Yan, Aniri, Wenke Huang, Zengjie Jin, Xiaowen Ma, Artur Hecker, Mang Ye, Xun Xiao, Hinrich Schuetze, V olker Tresp, and Yunpu Ma. Prism: Self-pruning intrinsic selection method for training- free multimodal data selection, 2025. 2
2025
-
[32]
Transformer tracking with cyclic shifting window attention
Zikai Song, Junqing Yu, Yi-Ping Phoebe Chen, and Wei Yang. Transformer tracking with cyclic shifting window attention. InCVPR, pages 8791–8800, 2022. 2
2022
-
[33]
Yielding unblemished aesthetics through a unified network for visual imperfec- tions removal in generated images.AAAI, 39(9):9716– 9724, 2025
Zhenyu Yu and Chee Seng Chan. Yielding unblemished aesthetics through a unified network for visual imperfec- tions removal in generated images.AAAI, 39(9):9716– 9724, 2025
2025
-
[34]
Visual instance-aware prompt tuning
Xi Xiao, Yunbei Zhang, Xingjian Li, Tianyang Wang, Xiao Wang, Yuxiang Wei, Jihun Hamm, and Min Xu. Visual instance-aware prompt tuning. InACM MM, pages 2880–
-
[35]
Association for Computing Machinery, Inc, 2025
2025
-
[36]
Prompt-based adaptation in large-scale vision models: A survey.arXiv preprint arXiv:2510.13219, 2025
Xi Xiao, Yunbei Zhang, Lin Zhao, Yiyang Liu, Xiaoying Liao, Zheda Mai, Xingjian Li, Xiao Wang, Hao Xu, Jihun Hamm, et al. Prompt-based adaptation in large-scale vision models: A survey.arXiv preprint arXiv:2510.13219, 2025
-
[37]
Chenglin Li, Qianglong Chen, Zhi Li, Feng Tao, and Yin Zhang. Videocogqa: A controllable benchmark for evalu- ating cognitive abilities in video-language models.arXiv preprint arXiv:2411.09105, 2024
-
[38]
Compact transformer tracker with correla- tive masked modeling
Zikai Song, Run Luo, Junqing Yu, Yi-Ping Phoebe Chen, and Wei Yang. Compact transformer tracker with correla- tive masked modeling. InAAAI, pages 2321–2329, 2023
2023
-
[39]
Collaborative multi-agent scripts generation for enhancing imperfect-information reasoning in murder mystery games, 2026
Keyang Zhong, Junlin Xie, Hefeng Wu, Haofeng Li, and Guanbin Li. Collaborative multi-agent scripts generation for enhancing imperfect-information reasoning in murder mystery games, 2026
2026
-
[40]
Hvd: Human vision- driven video representation learning for text-video retrieval,
Zequn Xie, Xin Liu, Boyun Zhang, Yuxiao Lin, Sihang Cai, and Tao Jin. Hvd: Human vision-driven video rep- resentation learning for text-video retrieval.arXiv preprint arXiv:2601.16155, 2026
-
[41]
Self-paced learning for images of antinuclear antibodies.IEEE TMI, 2025
Yiyang Jiang, Guangwu Qian, Jiaxin Wu, Qi Huang, Qing Li, Yongkang Wu, and Xiao-Yong Wei. Self-paced learning for images of antinuclear antibodies.IEEE TMI, 2025
2025
-
[42]
Tempo- ral coherent object flow for multi-object tracking
Zikai Song, Run Luo, Lintao Ma, Ying Tang, Yi- Ping Phoebe Chen, Junqing Yu, and Wei Yang. Tempo- ral coherent object flow for multi-object tracking. InAAAI, pages 6978–6986, 2025
2025
-
[43]
Yujun Wang, Jinhe Bi, Yunpu Ma, and Soeren Pirk. Ascd: Attention-steerable contrastive decoding for reducing hallu- cination in mllm.arXiv preprint arXiv:2506.14766, 2025
-
[44]
Cot-kinetics: A theoretical modeling assessing lrm reasoning process
Jinhe Bi, Danqi Yan, Yifan Wang, Wenke Huang, Haokun Chen, Guancheng Wan, Mang Ye, Xun Xiao, Hinrich Schuetze, V olker Tresp, et al. Cot-kinetics: A theoretical modeling assessing lrm reasoning process.arXiv preprint arXiv:2505.13408, 2025
-
[45]
Hierarchical consensus hashing for cross-modal re- trieval.IEEE TMM, 26:824–836, 2023
Yuan Sun, Zhenwen Ren, Peng Hu, Dezhong Peng, and Xu Wang. Hierarchical consensus hashing for cross-modal re- trieval.IEEE TMM, 26:824–836, 2023
2023
-
[46]
Dinov3-powered multi-task foundation model for quantitative remote sensing estimation.AAAI, 40(48):41455–41456, 2026
Zhenyu Yu, Mohd Yamani Idna Idris, Pei Wang, and Rizwan Qureshi. Dinov3-powered multi-task foundation model for quantitative remote sensing estimation.AAAI, 40(48):41455–41456, 2026
2026
-
[47]
Multi-modal gradual domain osmosis: Stepwise dynamic learning with batch matching for gradual domain adaptation
Zixi Wang, Yubo Huang, Jingzehua Xu, Jinzhu Wei, Shuai Zhang, and Xin Lai. Multi-modal gradual domain osmosis: Stepwise dynamic learning with batch matching for gradual domain adaptation. InACM MM, page 8959–8967, New York, NY , USA, 2025. Association for Computing Machin- ery. 2
2025
-
[48]
Recon: Enhancing true corre- spondence discrimination through relation consistency for robust noisy correspondence learning
Quanxing Zha, Xin Liu, Shu-Juan Peng, Yiu-ming Cheung, Xing Xu, and Nannan Wang. Recon: Enhancing true corre- spondence discrimination through relation consistency for robust noisy correspondence learning. InCVPR, pages 29680–29689, 2025. 2
2025
-
[49]
Robust multi-view clustering with noisy correspondence.IEEE Transactions on Knowledge and Data Engineering, 36(12):9150–9162, 2024
Yuan Sun, Yang Qin, Yongxiang Li, Dezhong Peng, Xi Peng, and Peng Hu. Robust multi-view clustering with noisy correspondence.IEEE Transactions on Knowledge and Data Engineering, 36(12):9150–9162, 2024
2024
-
[50]
Cross-view graph matching guided anchor alignment for incomplete multi-view clustering.Informa- tion Fusion, 100:101941, 2023
Xingfeng Li, Yinghui Sun, Quansen Sun, Zhenwen Ren, and Yuan Sun. Cross-view graph matching guided anchor alignment for incomplete multi-view clustering.Informa- tion Fusion, 100:101941, 2023
2023
-
[51]
Cross-modal active complementary learning with self-refining correspondence.Advances in neural information processing systems, 36:24829–24840, 2023
Yang Qin, Yuan Sun, Dezhong Peng, Joey Tianyi Zhou, Xi Peng, and Peng Hu. Cross-modal active complementary learning with self-refining correspondence.Advances in neural information processing systems, 36:24829–24840, 2023
2023
-
[52]
Prototype match- ing learning for incomplete multi-view clustering.IEEE Transactions on Image Processing, 34:828–841, 2025
Honglin Yuan, Yuan Sun, Fei Zhou, Jing Wen, Shihua Yuan, Xiaojian You, and Zhenwen Ren. Prototype match- ing learning for incomplete multi-view clustering.IEEE Transactions on Image Processing, 34:828–841, 2025
2025
-
[53]
Incom- plete multi-view clustering with paired and balanced dy- namic anchor learning.IEEE Transactions on Multimedia, 27:1486–1497, 2024
Xingfeng Li, Yuangang Pan, Yuan Sun, Quansen Sun, Yinghui Sun, Ivor W Tsang, and Zhenwen Ren. Incom- plete multi-view clustering with paired and balanced dy- namic anchor learning.IEEE Transactions on Multimedia, 27:1486–1497, 2024. 2
2024
-
[54]
Unsupervised label noise model- ing and loss correction
Eric Arazo, Diego Ortego, Paul Albert, Noel O’Connor, and Kevin McGuinness. Unsupervised label noise model- ing and loss correction. InICML, pages 312–321. PMLR,
-
[55]
A closer look at memorization in deep net- works
Devansh Arpit, Stanisław Jastrz ´kebski, Nicolas Ballas, David Krueger, Emmanuel Bengio, Maxinder S Kanwal, Tegan Maharaj, Asja Fischer, Aaron Courville, Yoshua Bengio, et al. A closer look at memorization in deep net- works. InICML, pages 233–242. PMLR, 2017. 2
2017
-
[56]
Maskcon: Masked con- trastive learning for coarse-labelled dataset
Chen Feng and Ioannis Patras. Maskcon: Masked con- trastive learning for coarse-labelled dataset. InCVPR, pages 19913–19922, 2023. 2
2023
-
[57]
Noisebox: Toward more efficient and effective learning with noisy labels.IEEE TCSVT, 34(11):11914–11928,
Chen Feng, Georgios Tzimiropoulos, and Ioannis Patras. Noisebox: Toward more efficient and effective learning with noisy labels.IEEE TCSVT, 34(11):11914–11928,
-
[58]
Learning with noisy correspon- dence.IJCV, 132(9):3656–3677, 2024
Zhenyu Huang, Peng Hu, Guocheng Niu, Xinyan Xiao, Jiancheng Lv, and Xi Peng. Learning with noisy correspon- dence.IJCV, 132(9):3656–3677, 2024. 2, 3
2024
-
[59]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[60]
Cogvlm: Visual expert for pretrained language models.NeurIPS, 37:121475–121499, 2024
Weihan Wang, Qingsong Lv, Wenmeng Yu, Wenyi Hong, Ji Qi, Yan Wang, Junhui Ji, Zhuoyi Yang, Lei Zhao, Xixuan Song, et al. Cogvlm: Visual expert for pretrained language models.NeurIPS, 37:121475–121499, 2024
2024
-
[61]
Heterogeneous Adaptive Policy Optimization: Tailoring Optimization to Every Token's Nature
Zheng Liu, Mengjie Liu, Siwei Wen, Mengzhang Cai, Bin Cui, Conghui He, and Wentao Zhang. From uniform to het- erogeneous: Tailoring policy optimization to every token’s nature.arXiv preprint arXiv:2509.16591, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[62]
FBS: Modeling Native Parallel Reading inside a Transformer
Tongxi Wang. Fbs: Modeling native parallel reading inside a transformer.arXiv preprint arXiv:2601.21708, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[63]
Curriculum-RLAIF: Curriculum Alignment with Reinforcement Learning from AI Feedback
Mengdi Li, Jiaye Lin, Xufeng Zhao, Wenhao Lu, Peilin Zhao, Stefan Wermter, and Di Wang. Curriculum-rlaif: Curriculum alignment with reinforcement learning from ai feedback.arXiv preprint arXiv:2505.20075, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[64]
Yangliu Hu, Zikai Song, Na Feng, Yawei Luo, Junqing Yu, Yi-Ping Phoebe Chen, and Wei Yang. Sf2t: Self-supervised fragment finetuning of video-llms for fine-grained under- standing.arXiv preprint arXiv:2504.07745, 2025
-
[65]
Stable and explainable personality trait evaluation in large language models with internal activations, 2026
Xiaoxu Ma, Xiangbo Zhang, and Zhenyu Weng. Stable and explainable personality trait evaluation in large language models with internal activations, 2026
2026
-
[66]
Xiaoliang Fu, Jiaye Lin, Yangyi Fang, Binbin Zheng, Chaowen Hu, Zekai Shao, Cong Qin, Lu Pan, Ke Zeng, and Xunliang Cai. Maspo: Unifying gradient utilization, prob- ability mass, and signal reliability for robust and sample- efficient llm reasoning.arXiv preprint arXiv:2602.17550, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[67]
Expseek: Self-triggered experience seeking for web agents, 2026
Wenyuan Zhang, Xinghua Zhang, Haiyang Yu, Shuaiyi Nie, Bingli Wu, Juwei Yue, Tingwen Liu, and Yongbin Li. Expseek: Self-triggered experience seeking for web agents, 2026
2026
-
[68]
Synthvlm: High-efficiency and high-quality synthetic data for vision language models
Zheng Liu, Hao Liang, Xijie Huang, Wentao Xiong, Qin- han Yu, Linzhuang Sun, Chong Chen, Conghui He, Bin Cui, and Wentao Zhang. Synthvlm: High-efficiency and high-quality synthetic data for vision language models. arXiv preprint arXiv:2407.20756, 3, 2024
-
[69]
Tongxi Wang, Zhuoyang Xia, Xinran Chen, and Shan Liu. Tracking drift: Variation-aware entropy scheduling for non-stationary reinforcement learning.arXiv preprint arXiv:2601.19624, 2026
-
[70]
Multi-objective unlearning in recommender systems via preference guided pareto exploration.IEEE TSC, 2025
Yuyuan Li, Yizhao Zhang, Weiming Liu, Xiaohua Feng, Zhongxuan Han, Chaochao Chen, and Chenggang Yan. Multi-objective unlearning in recommender systems via preference guided pareto exploration.IEEE TSC, 2025
2025
-
[71]
Ultrare: Enhancing receraser for recommendation unlearn- ing via error decomposition.NeurIPS, 36:12611–12625,
Yuyuan Li, Chaochao Chen, Yizhao Zhang, Weiming Liu, Lingjuan Lyu, Xiaolin Zheng, Dan Meng, and Jun Wang. Ultrare: Enhancing receraser for recommendation unlearn- ing via error decomposition.NeurIPS, 36:12611–12625,
-
[72]
Pair: Complementarity-guided disentanglement for composed image retrieval
Zhiheng Fu, Zixu Li, Zhiwei Chen, Chunxiao Wang, Xuemeng Song, Yupeng Hu, and Liqiang Nie. Pair: Complementarity-guided disentanglement for composed image retrieval. InICASSP, pages 1–5. IEEE, 2025. 3
2025
-
[73]
Me- dian: Adaptive intermediate-grained aggregation network for composed image retrieval
Qinlei Huang, Zhiwei Chen, Zixu Li, Chunxiao Wang, Xuemeng Song, Yupeng Hu, and Liqiang Nie. Me- dian: Adaptive intermediate-grained aggregation network for composed image retrieval. InICASSP, pages 1–5. IEEE,
-
[74]
Fash- ion iq: A new dataset towards retrieving images by natural language feedback
Hui Wu, Yupeng Gao, Xiaoxiao Guo, Ziad Al-Halah, Steven Rennie, Kristen Grauman, and Rogerio Feris. Fash- ion iq: A new dataset towards retrieving images by natural language feedback. InCVPR, pages 11307–11317, 2021. 3, 6, 2
2021
-
[75]
Image retrieval on real-life images with pre-trained vision-and-language models
Zheyuan Liu, Cristian Rodriguez-Opazo, Damien Teney, and Stephen Gould. Image retrieval on real-life images with pre-trained vision-and-language models. InICCV, pages 2125–2134, 2021. 6, 2
2021
-
[76]
Finecir: Explicit parsing of fine-grained modification semantics for composed image retrieval,
Zixu Li, Zhiheng Fu, Yupeng Hu, Zhiwei Chen, Haokun Wen, and Liqiang Nie. Finecir: Explicit parsing of fine- grained modification semantics for composed image re- trieval.arXiv preprint arXiv:2503.21309, 2025. 3
-
[77]
Computing nodes for plane data points by constructing cubic polynomial with constraints
Hua Wang and Fan Zhang. Computing nodes for plane data points by constructing cubic polynomial with constraints. CAGD, 111:102308, 2024. 3
2024
-
[78]
ChartVerse: Scaling Chart Reasoning via Reliable Programmatic Synthesis from Scratch
Zheng Liu, Honglin Lin, Chonghan Qin, Xiaoyang Wang, Xin Gao, Yu Li, Mengzhang Cai, Yun Zhu, Zhanping Zhong, Qizhi Pei, et al. Chartverse: Scaling chart reason- ing via reliable programmatic synthesis from scratch.arXiv preprint arXiv:2601.13606, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[79]
Peiyang Liu, Ziqiang Cui, Di Liang, and Wei Ye. Who stole your data? a method for detecting unauthorized rag theft.arXiv preprint arXiv:2510.07728, 2025
-
[80]
Not All Directions Matter: Towards Structured and Task-Aware Low-Rank Model Adaptation
Xi Xiao, Chenrui Ma, Yunbei Zhang, Chen Liu, Zhuxu- anzi Wang, Yanshu Li, Lin Zhao, Guosheng Hu, Tianyang Wang, and Hao Xu. Not all directions matter: Toward struc- tured and task-aware low-rank adaptation.arXiv preprint arXiv:2603.14228, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.