Recognition: unknown
FB-NLL: A Feature-Based Approach to Tackle Noisy Labels in Personalized Federated Learning
Pith reviewed 2026-05-10 02:48 UTC · model grok-4.3
The pith
FB-NLL groups users for personalized federated learning by the spectral structure of their local feature covariances in one shot before training begins.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
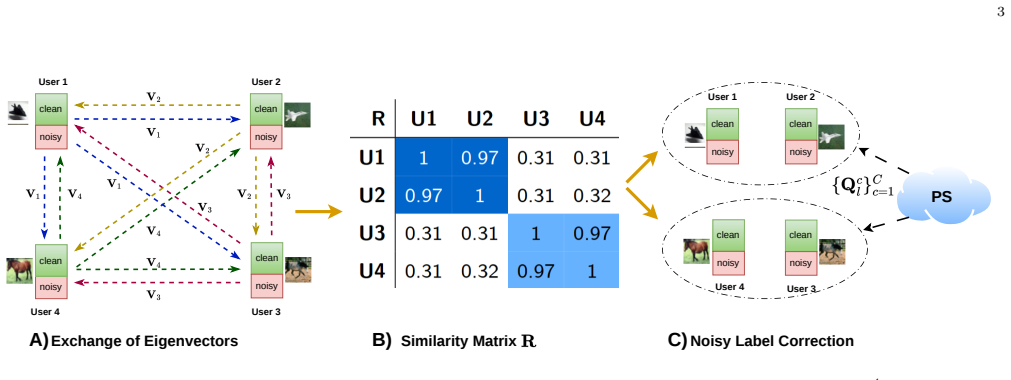
FB-NLL decouples user clustering from iterative training dynamics by exploiting the intrinsic heterogeneity of local feature spaces, characterizing each user through the spectral structure of the covariances of their feature representations and leveraging subspace similarity to identify task-consistent user groupings in a one-shot, label-agnostic manner prior to training, then applies a feature-consistency-based detection and correction strategy to mitigate noisy labels within clusters without estimating noise transition matrices.
What carries the argument
Spectral structure of covariances of local feature representations, measured by subspace similarity to perform one-shot label-agnostic clustering.
If this is right
- Clustering occurs once before any model training, eliminating repeated communication rounds required by dynamics-based methods.
- Noisy-label correction works inside clusters using only directional alignment in feature space, without estimating stochastic noise matrices.
- The framework remains model-independent and can be combined with any existing noise-robust training routine.
- Performance stability improves across varying noise levels because grouping decisions never rely on corrupted updates.
Where Pith is reading between the lines
- Publicly available feature extractors could be shared in advance to standardize representations and strengthen subspace matching across users.
- Periodic re-clustering on fresh feature batches could handle concept drift without restarting the entire federated process.
- The same covariance-spectral test might serve as a diagnostic tool to detect when a user's data distribution has shifted enough to warrant reassignment.
Load-bearing premise
The intrinsic heterogeneity of local feature spaces is strong enough to recover task-consistent user groupings even when the downstream model and label noise are unknown.
What would settle it
Running the subspace-similarity clustering on a dataset whose users share tasks yet possess deliberately mismatched feature distributions, then checking whether the resulting groups produce no accuracy gain over a single global model.
Figures


read the original abstract
Personalized Federated Learning (PFL) aims to learn multiple task-specific models rather than a single global model across heterogeneous data distributions. Existing PFL approaches typically rely on iterative optimization-such as model update trajectories-to cluster users that need to accomplish the same tasks together. However, these learning-dynamics-based methods are inherently vulnerable to low-quality data and noisy labels, as corrupted updates distort clustering decisions and degrade personalization performance. To tackle this, we propose FB-NLL, a feature-centric framework that decouples user clustering from iterative training dynamics. By exploiting the intrinsic heterogeneity of local feature spaces, FB-NLL characterizes each user through the spectral structure of the covariances of their feature representations and leverages subspace similarity to identify task-consistent user groupings. This geometry-aware clustering is label-agnostic and is performed in a one-shot manner prior to training, significantly reducing communication overhead and computational costs compared to iterative baselines. Complementing this, we introduce a feature-consistency-based detection and correction strategy to address noisy labels within clusters. By leveraging directional alignment in the learned feature space and assigning labels based on class-specific feature subspaces, our method mitigates corrupted supervision without requiring estimation of stochastic noise transition matrices. In addition, FB-NLL is model-independent and integrates seamlessly with existing noise-robust training techniques. Extensive experiments across diverse datasets and noise regimes demonstrate that our framework consistently outperforms state-of-the-art baselines in terms of average accuracy and performance stability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents FB-NLL, a feature-centric framework for personalized federated learning (PFL) under noisy labels. It decouples user clustering from iterative training by characterizing each user through the spectral structure of the covariances of their local feature representations and using subspace similarity to identify task-consistent groupings in a one-shot, label-agnostic manner prior to training. It further introduces a feature-consistency-based detection and correction mechanism for noisy labels within clusters, relying on directional alignment and class-specific feature subspaces in the learned space. The approach is claimed to be model-independent, to reduce communication overhead, and to integrate with existing noise-robust techniques, with experiments across datasets and noise regimes showing consistent outperformance over state-of-the-art baselines.
Significance. If the central claims hold, this would be a significant contribution to robust PFL by providing a pre-training, geometry-aware alternative to dynamics-based clustering methods that are vulnerable to noisy labels and corrupted updates. The label-agnostic one-shot clustering and integration with noise-robust training could improve stability and efficiency in heterogeneous, noisy federated settings while lowering communication costs. The model-independence claim, if substantiated, would enhance practical applicability across architectures.
major comments (2)
- [Abstract] Abstract: The central claim that user groupings are recovered via 'the spectral structure of the covariances of their feature representations' in a 'label-agnostic' and 'one-shot manner prior to training' is load-bearing for the decoupling from iterative dynamics, yet no details are supplied on how feature representations are obtained or how the resulting subspaces are made comparable when no shared feature extractor exists and downstream models are unknown. This directly impacts the weakest assumption that intrinsic heterogeneity of local feature spaces suffices to recover task-consistent groupings.
- [Abstract] Abstract: The noisy-label correction is described as using 'directional alignment in the learned feature space and assigning labels based on class-specific feature subspaces' without requiring noise transition matrices, but the manuscript gives no quantitative information on how the feature space is learned under noise, how alignment is measured, or how similarity thresholds are chosen. This is load-bearing for the claim that the strategy mitigates corrupted supervision reliably.
minor comments (1)
- [Abstract] The abstract contains a minor typographical issue ('optimization-such as' lacks spacing or punctuation for readability).
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The comments identify areas where additional clarity on the technical assumptions and implementation would strengthen the presentation. We respond to each major comment below and have made revisions to address them.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that user groupings are recovered via 'the spectral structure of the covariances of their feature representations' in a 'label-agnostic' and 'one-shot manner prior to training' is load-bearing for the decoupling from iterative dynamics, yet no details are supplied on how feature representations are obtained or how the resulting subspaces are made comparable when no shared feature extractor exists and downstream models are unknown. This directly impacts the weakest assumption that intrinsic heterogeneity of local feature spaces suffices to recover task-consistent groupings.
Authors: We thank the referee for highlighting the need for explicit details on feature extraction and subspace comparison. The full manuscript (Section 3.1) specifies that each client independently extracts features by forwarding its local data through the backbone of its local model (using identical initialization or a common pre-trained extractor to ensure matching feature dimensionality, consistent with standard PFL assumptions). The spectral structure is obtained from the eigendecomposition of the local feature covariance matrix, and subspaces are compared via principal angles (or chordal distance on the Grassmann manifold). This geometry-based metric does not require a shared trained extractor or knowledge of downstream models, enabling the one-shot, label-agnostic clustering prior to training. We agree the abstract was overly concise and have expanded it with a brief clause on feature extraction while adding a dedicated paragraph in Section 3.2 clarifying the dimensionality alignment assumption and discussing the case of heterogeneous architectures (via optional local PCA). revision: yes
-
Referee: [Abstract] Abstract: The noisy-label correction is described as using 'directional alignment in the learned feature space and assigning labels based on class-specific feature subspaces' without requiring noise transition matrices, but the manuscript gives no quantitative information on how the feature space is learned under noise, how alignment is measured, or how similarity thresholds are chosen. This is load-bearing for the claim that the strategy mitigates corrupted supervision reliably.
Authors: We appreciate this observation on the need for quantitative specifics in the noise-correction procedure. Section 4.2 of the manuscript details that the feature space is learned via a short phase of local training (typically 5-10 epochs) on the clustered users using their initial noisy labels. Alignment is quantified by the cosine similarity between each sample's feature vector and its class prototype (the mean feature vector of samples assigned to that class within the cluster). Noisy labels are flagged when this similarity falls below a threshold set to the 10th percentile of intra-cluster alignment scores; flagged samples are then reassigned to the nearest class subspace. We have revised the main text to include these quantitative choices and added an ablation study (new Table in Section 5.3) showing performance sensitivity to the percentile threshold across noise levels. This provides the requested information while preserving the method's independence from noise transition matrix estimation. revision: yes
Circularity Check
No significant circularity detected; derivation is self-contained.
full rationale
The paper proposes a one-shot, label-agnostic clustering step based on the spectral structure of local feature covariances computed prior to any training, followed by a separate feature-consistency label correction performed after a shared feature space is learned. Neither step is defined in terms of the other or fitted to final accuracy by construction. No self-citations, uniqueness theorems, or ansatzes from prior author work are invoked as load-bearing in the provided abstract or claims. The method introduces independent geometric quantities (covariance eigenspectra and subspace similarities) that do not reduce to the inputs or to the downstream personalization performance metric.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Local feature representations exhibit sufficient heterogeneity that their covariance spectral structures separate users by task.
- domain assumption Class-specific feature subspaces remain consistent enough inside a cluster to allow label correction by directional alignment.
Reference graph
Works this paper leans on
-
[1]
Ali and A
A. Ali and A. Arafa. Data similarity-based one-shot clustering for multi-task hierarchical federated learning. In Proc. Asilomar, October 2024
2024
-
[2]
Ali and A
A. Ali and A. Arafa. RCC-PFL: Robust client clustering under noisy labels in personalized federated learning. In Proc. IEEE ICC, June 2025
2025
-
[3]
H. B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas. Communication-efficient learning of deep networks from decentralized data. In Proc. AISTATS, April 2017
2017
-
[4]
A. Tan, H. Yu, L. Cui, and Q. Yang. Towards personalized federated learning. IEEE Trans. Neural Netw. Learn. Syst., 34(12):9587–9603, December 2023
2023
-
[5]
Ghosh, J
A. Ghosh, J. Chung, D. Yin, and K. Ramchandran. An efficient framework for clustered federated learning. IEEE Trans. Inf. Theory, 68(12):8076–8091, December 2022
2022
-
[6]
Sami and B
H. Sami and B. Güler. Over-the-air clustered federated learning. IEEE Trans. Wireless Commun., 23(7):7877–7893, July 2024
2024
-
[7]
Frenay and M
B. Frenay and M. Verleysen. Classification in the presence of label noise: A survey. IEEE Trans. on Neural Netw. and Learn. Syst., 25(5):845–869, May 2014
2014
-
[8]
S. Liu, J. Niles-Weed, N. Razavian, and C. Fernandez-Granda. Early-learning regularization prevents memorization of noisy labels. In Proc. NeurIPS, December 2020
2020
-
[9]
Sattler, K.-R
F. Sattler, K.-R. Müller, and W. Samek. Clustered federated learning: Model-agnostic distributed multitask optimization un- der privacy constraints. IEEE Trans. on Neural Netw. and Learn. Syst., 32(8):3710–3722, August 2021
2021
-
[10]
R. Cai, X. Chen, S. Liu, J. Srinivasa, M. Lee, R. Kompella, and Z. Wang. Many-task federated learning: A new problem setting and a simple baseline. In Proc. IEEE/CVF CVPR W, June 2023
2023
-
[11]
Smith, C.-K
V. Smith, C.-K. Chiang, M. Sanjabi, and A. S Talwalkar. Federated multi-task learning. In Proc. NeurIPS, December 2017
2017
-
[12]
Zhang, G
Y. Zhang, G. Niu, and M. Sugiyama. Learning noise transition matrix from only noisy labels via total variation regularization. In Proc. ICML, July 2021
2021
-
[13]
S. Li, X. Xia, H. Zhang, Y. Zhan, S. Ge, and T. Liu. Estimating noise transition matrix with label correlations for noisy multi- label learning. In Proc. NeurIPS, December 2022
2022
-
[14]
Yue and N
C. Yue and N. K. Jha. CTRL: Clustering training losses for label error detection. IEEE Trans. on Artificial Intelligence, 5(8):4121–4135, August 2024
2024
-
[15]
Patrini, A
G. Patrini, A. Rozza, A. K. Menon, R. Nock, and L. Qu. Making deep neural networks robust to label noise: A loss correction approach. In Proc. IEEE CVPR, July 2017
2017
-
[16]
H. Wei, H. Zhuang, R. Xie, L. Feng, G. Niu, B. An, and Y. Li. Mitigating memorization of noisy labels by clipping the model prediction. In Proc. ICML, July 2023
2023
-
[17]
Jiang, Z
L. Jiang, Z. Zhou, T. Leung, L. Li, and L. Fei-Fei. MentorNet: Learning data-driven curriculum for very deep neural networks on corrupted labels. In Proc. ICML, July 2018
2018
-
[18]
B. Han, Q. Yao, X. Yu, G. Niu, M. Xu, W. Hu, I. Tsang, and M. Sugiyama. Co-teaching: Robust training of deep neural networks with extremely noisy labels. Proc. NeurIPS, December 2018
2018
-
[19]
Fang and M
X. Fang and M. Ye. Robust federated learning with noisy and heterogeneous clients. In Proc. IEEE CVPR, September 2022
2022
-
[20]
Fang and M
X. Fang and M. Ye. Noise-robust federated learning with model heterogeneous clients. IEEE Trans. Mob. Computing, 24(5):4053–4071, May 2025
2025
-
[21]
J. Xu, Z. Chen, T. Q.S. Quek, and K. F. E. Chong. FedCorr: Multi-stage federated learning for label noise correction. In IEEE/CVF CVPR, June 2022
2022
-
[22]
N. Wu, L. Yu, X. Jiang, K.-T. Cheng, and Z. Yan. FedNoRo: Towards noise-robust federated learning by addressing class imbalance and label noise heterogeneity. In Proc. IJCAI, August 2023
2023
-
[23]
Morafah, H
M. Morafah, H. Chang, C. Chen, and B. Lin. Federated learning client pruning for noisy labels. ACM Trans. Model. Perform. Eval. Comput. Syst., 10(2):1–25, May 2025
2025
-
[24]
Y. Lu, L. Chen, Y. Zhang, Y. Zhang, B. Han, Y.-M. Cheung, and H. Wang. Federated learning with extremely noisy clients via negative distillation. In Proc. AAAI, March 2024
2024
-
[25]
S. Yang, H. Park, J. Byun, and C. Kim. Robust federated learning with noisy labels. IEEE Intelligent Systems, 37(2):35– 43, April 2022
2022
-
[26]
Jiang, S
X. Jiang, S. Sun, Y. Wang, and M. Liu. Towards federated learning against noisy labels via local self-regularization. In Proc. ACM Conf. Inf. Knowl. Manag. (CIKM), October 2022
2022
-
[27]
Deep Learning is Robust to Massive Label Noise
D. Rolnick, A. Veit, S. Belongie, and N. Shavit. Deep learning is robust to massive label noise. A vailable online: arXiv:1705.10694
-
[28]
S. Zhou, K. Li, Y. Chen, C. Yang, W. Liang, and A. Y. Zomaya. TrustBCFL: Mitigating data bias in iot through blockchain- enabled federated learning. IEEE IoT-J, 11(15):25648–25662, August 2024
2024
-
[29]
J. Li, G. Li, H. Cheng, Z. Liao, and Y. Yu. FedDiv: Collaborative noise filtering for federated learning with noisy labels. In Proc. AAAI, March 2024
2024
-
[30]
M. M. Amiri, F. Berdoz, and R. Raskar. Fundamentals of task- agnostic data valuation. In Proc. AAAI, June 2023
2023
-
[31]
K. P. Murphy. Probabilistic Machine Learning: An introduction. MIT Press, 2022
2022
-
[32]
T. Lin, L. Kong, S. U Stich, and M. Jaggi. Ensemble distillation for robust model fusion in federated learning. In Proc. NeurIPS, December 2020
2020
-
[33]
J. Li, F. Huang, and H. Huang. Communication-efficient federated bilevel optimization with global and local lower level problems. In Proc. NeurIPS, December 2023
2023
-
[34]
T. Kim, J. Ko, S. Cho, J. Choi, and Se-Young Yun. FINE samples for learning with noisy labels. In Proc. NeurIPS, December 2021
2021
-
[35]
K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In Proc. IEEE CVPR, June 2016
2016
-
[36]
Krizhevsky
A. Krizhevsky. Learning multiple layers of features from tiny images. 2009
2009
-
[37]
Netzer et al
Y. Netzer et al. Reading digits in natural images with unsuper- vised feature learning. In NIPS workshop on deep learning and unsupervised feature learning, December 2011
2011
-
[38]
Dalal and B
N. Dalal and B. Triggs. Histograms of oriented gradients for human detection. In Proc. IEEE CVPR, July 2005
2005
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.