Saying More Than They Know: A Framework for Quantifying Epistemic-Rhetorical Miscalibration in Large Language Models
Pith reviewed 2026-05-15 00:21 UTC · model grok-4.3
The pith
Large language models produce rhetorical patterns whose intensity exceeds their epistemic grounding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LLM-generated texts produce tricolon at nearly twice the expert rate while human authors produce erotema at more than twice the LLM rate. Performed hesitancy markers appear at twice the human density in LLM output. Form-meaning divergence is significantly elevated in LLM texts relative to both human groups, and rhetorical devices are distributed significantly more uniformly across LLM documents.
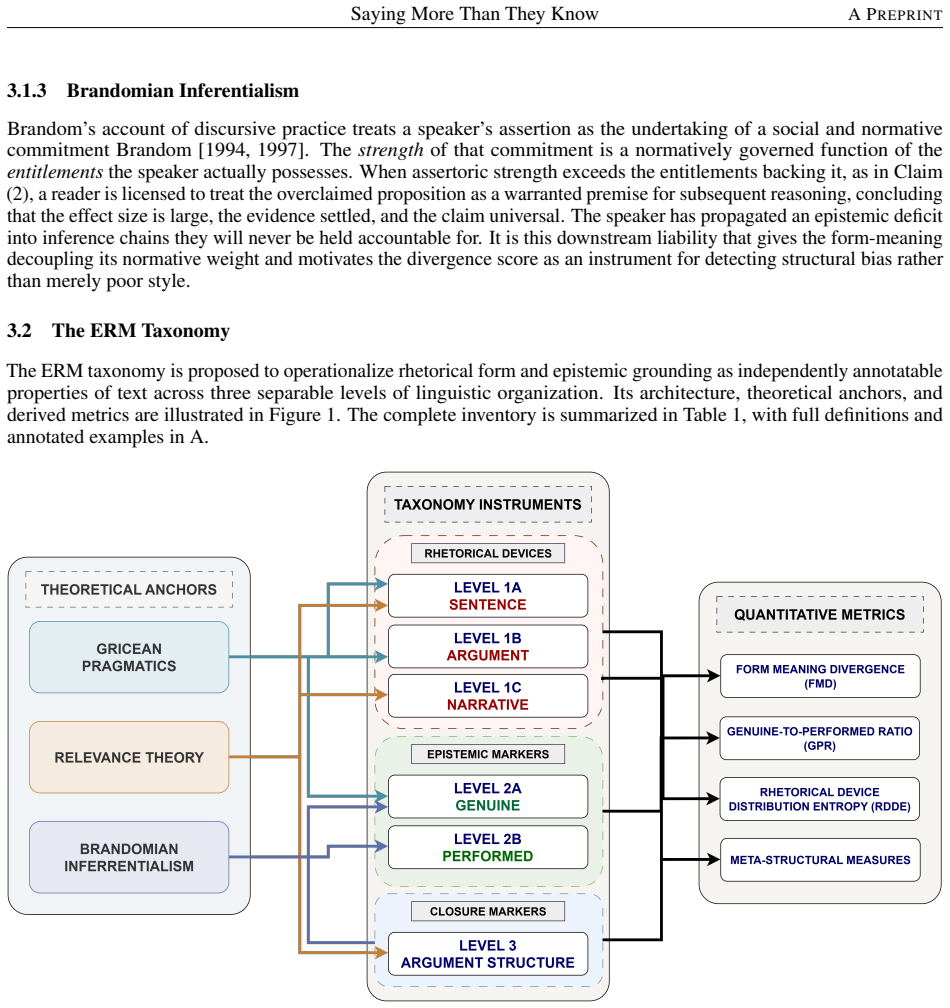
What carries the argument
Triadic epistemic-rhetorical marker (ERM) taxonomy operationalized through form-meaning divergence (FMD), genuine-to-performed epistemic ratio (GPR), and rhetorical device distribution entropy (RDDE) metrics.
Load-bearing premise
The triadic ERM taxonomy and its operationalization via FMD, GPR, and RDDE metrics accurately isolate epistemic-rhetorical miscalibration without bias from corpus construction, annotation rules, or LLM generation artifacts.
What would settle it
An independent corpus of argumentative texts in which form-meaning divergence scores show no significant elevation for LLM outputs relative to human outputs would falsify the claim of systematic miscalibration.
Figures






read the original abstract
Large language models (LLMs) exhibit systematic miscalibration with rhetorical intensity not proportionate to epistemic grounding. This study tests this hypothesis and proposes a framework for quantifying this decoupling by designing a triadic epistemic-rhetorical marker (ERM) taxonomy. The taxonomy is operationalized through composite metrics of form-meaning divergence (FMD), genuine-to-performed epistemic ratio (GPR), and rhetorical device distribution entropy (RDDE). Applied to 225 argumentative texts spanning approximately 0.6 Million tokens across human expert, human non-expert, and LLM-generated sub-corpora, the framework identifies a consistent, model-agnostic LLM epistemic signature. LLM-generated texts produce tricolon at nearly twice the expert rate ($\Delta = 0.95$), while human authors produce erotema at more than twice the LLM rate. Performed hesitancy markers appear at twice the human density in LLM output. FMD is significantly elevated in LLM texts relative to both human groups ($p < 0.001, \Delta = 0.68$), and rhetorical devices are distributed significantly more uniformly across LLM documents. The findings are consistent with theoretical intuitions derived from Gricean pragmatics, Relevance Theory, and Brandomian inferentialism. The annotation pipeline is fully automatable, making it deployable as a lightweight screening tool for epistemic miscalibration in AI-generated content and as a theoretically motivated feature set for LLM-generated text detection pipelines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLMs exhibit systematic epistemic-rhetorical miscalibration, with rhetorical intensity disproportionate to epistemic grounding. It introduces a triadic ERM taxonomy operationalized via composite metrics FMD, GPR, and RDDE. Applied to 225 argumentative texts (~0.6M tokens) across human expert, human non-expert, and LLM sub-corpora, the framework reports LLM texts using tricolon at nearly twice the expert rate (Δ=0.95), humans using erotema more than twice the LLM rate, performed hesitancy markers at twice human density in LLMs, significantly elevated FMD in LLMs (p<0.001, Δ=0.68), and more uniform rhetorical device distribution in LLM documents. Findings align with Gricean pragmatics, Relevance Theory, and Brandomian inferentialism, with the pipeline presented as automatable for AI content screening.
Significance. If the metrics validly isolate epistemic-rhetorical decoupling independent of stylistic artifacts, the work offers a novel, automatable framework grounded in linguistic theory for detecting miscalibration in LLM outputs. This could strengthen AI-generated text detection pipelines and provide empirical tests of pragmatic theories in computational settings. The model-agnostic results, large corpus size, and reported effect sizes add potential impact for NLP applications in content moderation and evaluation.
major comments (3)
- [Methods] Methods section: The operational definitions, formulas, and validation procedures for FMD, GPR, and RDDE are not provided. Without explicit computation details (e.g., how form-meaning divergence is scored from annotations or how the genuine-to-performed ratio is derived), it is impossible to confirm that the metrics measure epistemic-rhetorical miscalibration rather than LLM stylistic regularities such as repetition or formality patterns. This directly affects interpretation of the central results including FMD Δ=0.68 (p<0.001).
- [Corpus and Annotation] Corpus construction and annotation: No details are given on sampling criteria for the 225 texts, inter-annotator agreement for the ERM taxonomy, or controls for confounders like text length, topic, or LLM prompt design. These omissions leave open the possibility that differences in device rates (e.g., tricolon Δ=0.95) and RDDE uniformity arise from corpus or annotation biases rather than the hypothesized decoupling.
- [Results] Results section: While p-values and effect sizes are reported, the manuscript does not specify the exact statistical tests, sample sizes per comparison, or corrections for multiple testing. This weakens assessment of claims such as significantly more uniform rhetorical device distribution across LLM documents.
minor comments (2)
- [Abstract] Abstract: The token count is stated as 'approximately 0.6 Million tokens'; reporting the exact total would aid reproducibility.
- [Discussion] Discussion: Adding an explicit limitations paragraph addressing potential LLM generation artifacts (e.g., prompt-induced patterns) would strengthen the manuscript.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which has helped us identify areas where the manuscript can be strengthened for clarity and reproducibility. We address each major comment below and will incorporate the suggested revisions in the next version of the paper.
read point-by-point responses
-
Referee: [Methods] Methods section: The operational definitions, formulas, and validation procedures for FMD, GPR, and RDDE are not provided. Without explicit computation details (e.g., how form-meaning divergence is scored from annotations or how the genuine-to-performed ratio is derived), it is impossible to confirm that the metrics measure epistemic-rhetorical miscalibration rather than LLM stylistic regularities such as repetition or formality patterns. This directly affects interpretation of the central results including FMD Δ=0.68 (p<0.001).
Authors: We agree that the current Methods section lacks sufficient explicit detail on the metrics. In the revised manuscript, we will expand this section to include the full operational definitions of the ERM taxonomy, the precise mathematical formulas for computing FMD (form-meaning divergence), GPR (genuine-to-performed epistemic ratio), and RDDE (rhetorical device distribution entropy), along with step-by-step validation procedures, annotation guidelines, and pseudocode for the automatable pipeline. These additions will demonstrate how the metrics isolate epistemic-rhetorical decoupling from purely stylistic factors such as repetition or formality. revision: yes
-
Referee: [Corpus and Annotation] Corpus construction and annotation: No details are given on sampling criteria for the 225 texts, inter-annotator agreement for the ERM taxonomy, or controls for confounders like text length, topic, or LLM prompt design. These omissions leave open the possibility that differences in device rates (e.g., tricolon Δ=0.95) and RDDE uniformity arise from corpus or annotation biases rather than the hypothesized decoupling.
Authors: We acknowledge the importance of transparency in corpus construction. The revised manuscript will include a dedicated subsection detailing the sampling criteria for selecting the 225 argumentative texts (~0.6M tokens), report inter-annotator agreement statistics (e.g., Cohen's kappa or Fleiss' kappa) for the ERM taxonomy annotations, and describe the controls applied for potential confounders including text length normalization, topic balancing across sub-corpora, and standardization of LLM prompt designs. These additions will help rule out alternative explanations for the observed differences. revision: yes
-
Referee: [Results] Results section: While p-values and effect sizes are reported, the manuscript does not specify the exact statistical tests, sample sizes per comparison, or corrections for multiple testing. This weakens assessment of claims such as significantly more uniform rhetorical device distribution across LLM documents.
Authors: We agree that full statistical reporting is necessary for rigorous evaluation. In the revised Results section, we will explicitly specify the statistical tests used for each comparison (e.g., independent t-tests or Mann-Whitney U tests for FMD and device rates), the exact sample sizes per group (225 texts divided across the three sub-corpora), and the multiple-testing correction applied (e.g., Bonferroni or FDR). This will allow readers to fully assess the robustness of findings such as the elevated FMD (p<0.001, Δ=0.68) and RDDE uniformity. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper proposes a novel triadic ERM taxonomy and operationalizes it via author-defined composite metrics (FMD, GPR, RDDE) explicitly motivated by external linguistic theories (Gricean pragmatics, Relevance Theory, Brandomian inferentialism). These are then applied empirically to a 0.6M-token corpus spanning human expert, human non-expert, and LLM texts, producing statistical comparisons (e.g., tricolon rate Δ=0.95, FMD p<0.001 Δ=0.68). No equations, definitions, or self-citations are present that reduce any reported result to a fitted parameter, self-referential definition, or prior author work by construction. The derivation chain is an independent empirical measurement using a new framework and remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Gricean pragmatics, Relevance Theory, and Brandomian inferentialism provide the theoretical foundation for interpreting the metrics as indicators of epistemic-rhetorical misalignment
invented entities (4)
-
Triadic epistemic-rhetorical marker (ERM) taxonomy
no independent evidence
-
Form-meaning divergence (FMD)
no independent evidence
-
Genuine-to-performed epistemic ratio (GPR)
no independent evidence
-
Rhetorical device distribution entropy (RDDE)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The taxonomy is operationalized through composite metrics of form-meaning divergence (FMD), genuine-to-performed epistemic ratio (GPR), and rhetorical device distribution entropy (RDDE).
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
FMD is significantly elevated in LLM texts relative to both human groups (p < 0.001, Δ = 0.68)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
doi:10.48550/arXiv.2309.00770. Rajesh Ranjan, Shailja Gupta, and Surya Narayan Singh. A Comprehensive Survey of Bias in LLMs: Current Landscape and Future Directions, September
-
[2]
URLhttp://arxiv.org/abs/2409.16430. Su Lin Blodgett, Solon Barocas, Hal Daumé III, and Hanna Wallach. Language (Technology) is Power: A Critical Survey of “Bias” in NLP. In Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault, editors,Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 5454–5476, Online, July
-
[3]
Language (Technology) is Power: A Critical Survey of ``Bias'' in NLP
Association for Computational Linguistics. doi:10.18653/v1/2020.acl-main.485. Ziwei Ji, Tiezheng Yu, Yan Xu, Nayeon Lee, Etsuko Ishii, and Pascale Fung. Towards Mitigating LLM Hallucination via Self Reflection. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Findings of the Association for Computational Linguistics: EMNLP 2023, pages 1827–1843, Sing...
-
[4]
doi:10.18653/v1/2023.findings-emnlp.123
Association for Computational Linguistics. doi:10.18653/v1/2023.findings-emnlp.123. Emily M. Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell. On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? InProceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, FAccT ’21, pages 610–623, New Yo...
-
[5]
Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell
Association for Computing Machinery. ISBN 978-1-4503-8309-7. doi:10.1145/3442188.3445922. Fabian Erhardt. Metacognitive Text Organizastion Semiotic and Rhetorical Agency in LLMs, December
-
[6]
Association for Computational Linguistics. ISBN 979-8-89176-251-0. doi:10.18653/v1/2025.acl-long.1345. Kai V on Fintel and Anthony S Gillies. An Opinionated Guide to Epistemic Modality. In Tamar Szabó Gendler and John Hawthorne, editors,Oxford Studies In Epistemology, pages 32–62. Oxford University Press, December
-
[7]
Scale-Free Networks: Complex Webs in Nature and Technology
doi:10.1093/oso/9780199237067.003.0002. Ziqi Li and Qi Zhang. Linguistic Differences between AI and Human Comments in Weibo: Detect AI-Generated Text through Stylometric Features. InProceedings of the 24th China National Conference on Computational Linguistics, pages 842–851, August
-
[8]
Dongryeol Lee, Yerin Hwang, Yongil Kim, Joonsuk Park, and Kyomin Jung. Are LLM-Judges Robust to Expressions of Uncertainty? Investigating the effect of Epistemic Markers on LLM-based Evaluation. In Luis Chiruzzo, Alan Ritter, and Lu Wang, editors,Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational...
work page 2025
-
[9]
Association for Computational Linguistics. ISBN 979-8-89176-189-6. doi:10.18653/v1/2025.naacl-long.452. David Clausen. HedgeHunter: A System for Hedge Detection and Uncertainty Classification. In Richárd Farkas, Veronika Vincze, György Szarvas, György Móra, and János Csirik, editors,Proceedings of the Fourteenth Confer- ence on Computational Natural Langu...
-
[10]
ISSN 1565-8961. doi:10.4000/14yb8. Herbert P Grice. Logic and Conversation. InSpeech acts, pages 41–58. Brill,
-
[11]
doi:10.1007/s10994-025-06767-4
ISSN 1573-0565. doi:10.1007/s10994-025-06767-4. 18 Saying More Than They KnowA PREPRINT Krishnaram Kenthapadi, Mehrnoosh Sameki, and Ankur Taly. Grounding and Evaluation for Large Language Models: Practical Challenges and Lessons Learned (Survey). InProceedings of the 30th ACM SIGKDD conference on knowledge discovery and data mining, pages 6523–6533,
-
[12]
Association for Computing Machinery. ISBN 978-1-4503-7110-0. doi:10.1145/3375627.3375811. Tempestt Neal, Kalaivani Sundararajan, Aneez Fatima, Yiming Yan, Yingfei Xiang, and Damon Woodard. Surveying Stylometry Techniques and Applications.ACM Computing Surveys (CSuR), 50(6):1–36,
-
[13]
Association for Computing Machinery. ISBN 979-8-4007-1124-4. doi:10.1145/3703323.3703712. Tamas Bisztray, Bilel Cherif, Richard A. Dubniczky, Nils Gruschka, Bertalan Borsos, Mohamed Amine Ferrag, Attila Kovacs, Vasileios Mavroeidis, and Norbert Tihanyi. I Know Which LLM Wrote Your Code Last Summer: LLM generated Code Stylometry for Authorship Attribution....
-
[14]
Association for Computing Machinery. ISBN 979-8-4007-1895-3. doi:10.1145/3733799.3762964. Tharindu Kumarage and Huan Liu. Neural Authorship Attribution: Stylometric Analysis on Large Language Models, August
-
[15]
Wataru Zaitsu, Mingzhe Jin, Shunichi Ishihara, Satoru Tsuge, and Mitsuyuki Inaba
arXiv:2308.07305 [cs]. Wataru Zaitsu, Mingzhe Jin, Shunichi Ishihara, Satoru Tsuge, and Mitsuyuki Inaba. Stylometry can reveal artificial intelligence authorship, but humans struggle: A comparison of human and seven large language models in Japanese. PLOS ONE, 20(10):e0335369, October
-
[16]
doi:10.1371/journal.pone.0335369
ISSN 1932-6203. doi:10.1371/journal.pone.0335369. Zoltan P. Majdik and S. Scott Graham. Rhetoric of/with AI: An Introduction.Rhetoric Society Quarterly, 54(3): 222–231, May
-
[17]
doi:10.1080/02773945.2024.2343264
ISSN 0277-3945, 1930-322X. doi:10.1080/02773945.2024.2343264. Sergey K. Aityan, William Claster, Karthik Sai Emani, Sohni Rais, and Thy Tran. A Lightweight Approach to Detection of AI-Generated Texts Using Stylometric Features, January
- [18]
-
[19]
doi:10.1016/j.eswa.2025.130644
ISSN 0957-4174. doi:10.1016/j.eswa.2025.130644. Ben Medlock and Ted Briscoe. Weakly Supervised Learning for Hedge Classification in Scientific Literature. In Annie Zaenen and Antal van den Bosch, editors,Proceedings of the 45th Annual Meeting of the Association of Computational Linguistics, pages 992–999, Prague, Czech Republic, June
-
[20]
doi:10.5281/zenodo.1212303. Stephen E Toulmin.The uses of argument. Cambridge university press,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.