Recognition: unknown
Enhancing ASR Performance in the Medical Domain for Dravidian Languages
Pith reviewed 2026-05-10 17:11 UTC · model grok-4.3
The pith
A hybrid confidence mechanism for mixing real and synthetic speech cuts medical ASR error rates in Telugu and Kannada.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The hybrid confidence-aware approach with learnable weights substantially reduces recognition errors: Telugu Word Error Rate decreases from 24.3% to 15.8% and Kannada Word Error Rate drops from 31.7% to 25.4%, both significantly outperforming standard fine-tuning baselines when paired with a 5-gram KenLM language model.
What carries the argument
The hybrid confidence mechanism that combines static perceptual and acoustic similarity metrics with dynamic model entropy to determine training-sample weights for real and TTS synthetic data.
If this is right
- Learnable-weight confidence aggregation enables more effective use of heterogeneous real and synthetic data sources than fixed-weight or direct fine-tuning methods.
- The framework delivers measurable error reduction on morphologically complex Dravidian languages in a specialized vocabulary domain.
- Post-decoding correction with a 5-gram statistical language model provides further gains on top of the confidence-weighted training.
- The method improves ASR performance where annotated medical data are limited by leveraging generated speech under controlled weighting.
Where Pith is reading between the lines
- The same weighting strategy could be tested on other low-resource languages or additional specialized domains such as legal or technical speech.
- Reducing dependence on costly real medical recordings by safely incorporating TTS data could lower the barrier to building domain-specific ASR systems.
- The confidence scores themselves might serve as a diagnostic for data quality when applied to new TTS systems or out-of-domain test sets.
Load-bearing premise
The TTS-generated synthetic speech is representative enough of real medical-domain speech that weighting it via the hybrid confidence mechanism will not introduce harmful biases or errors into the trained ASR model.
What would settle it
Training the model only on real medical recordings and testing exclusively on a large held-out set of real medical recordings would show whether the reported gains remain when synthetic data are completely removed.
Figures

read the original abstract
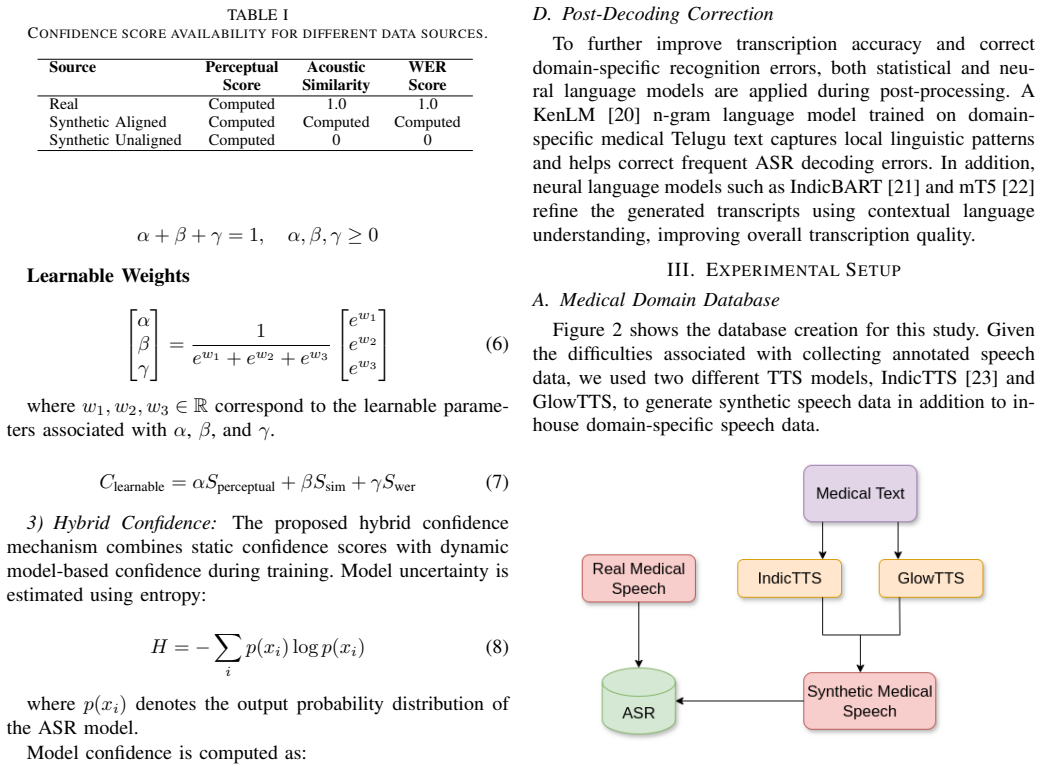
Automatic Speech Recognition (ASR) for low-resource Dravidian languages like Telugu and Kannada faces significant challenges in specialized medical domains due to limited annotated data and morphological complexity. This work proposes a novel confidence-aware training framework that integrates real and synthetic speech data through a hybrid confidence mechanism combining static perceptual and acoustic similarity metrics with dynamic model entropy. Unlike direct fine-tuning approaches, the proposed methodology employs both fixed-weight and learnable-weight confidence aggregation strategies to guide sample weighting during training, enabling effective utilization of heterogeneous data sources. The framework is evaluated on Telugu and Kannada medical datasets containing both real recordings and TTS-generated synthetic speech. A 5-gram KenLM language model is applied for post-decoding correction. Results show that the hybrid confidence-aware approach with learnable weights substantially reduces recognition errors: Telugu Word Error Rate (WER) decreases from 24.3% to 15.8% (8.5% absolute improvement), while Kannada WER drops from 31.7% to 25.4% (6.3% absolute improvement), both significantly outperforming standard fine-tuning baselines. These findings confirm that combining adaptive confidence-aware training with statistical language modeling delivers superior performance for domain-specific ASR in morphologically complex Dravidian languages.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a hybrid confidence-aware training framework for ASR in the medical domain for low-resource Dravidian languages Telugu and Kannada. It integrates real recordings with TTS-generated synthetic speech by combining static perceptual/acoustic similarity metrics with dynamic model entropy for sample weighting, comparing fixed-weight and learnable-weight aggregation strategies, and applies a 5-gram KenLM for post-decoding correction. The central empirical claim is that the learnable-weight variant yields absolute WER reductions of 8.5% (Telugu: 24.3% to 15.8%) and 6.3% (Kannada: 31.7% to 25.4%) over standard fine-tuning baselines.
Significance. If the reported WER gains prove robust and reproducible, the work would be moderately significant for low-resource, domain-specific ASR by showing how adaptive weighting can leverage synthetic data in morphologically complex languages. The combination of confidence mechanisms with language-model rescoring is a practical contribution, but the absence of dataset statistics, TTS specifications, and distribution-matching checks limits its immediate utility and generalizability.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experiments): The manuscript reports specific WER values and claims of statistical outperformance without providing dataset sizes, number of utterances/speakers, vocabulary coverage for medical terms, or the statistical tests used to establish significance of the 8.5% and 6.3% absolute improvements. These details are load-bearing for attributing gains to the hybrid method rather than data artifacts or baseline differences.
- [§3] §3 (Methodology): The hybrid confidence mechanism is described only at a high level; the exact definitions of the static perceptual and acoustic similarity metrics, the TTS system and its training data, and the optimization procedure for learnable weights are not given. Without these, it is impossible to verify whether the weighting reliably down-weights harmful synthetic samples whose Dravidian phonetics or medical terminology diverge from real recordings.
- [§4] §4 (Experiments): No quantitative analysis (e.g., distribution distances, phoneme error rates on synthetic vs. real medical speech, or ablation on confidence components) is presented to confirm that the TTS synthetic data is representative enough of real medical-domain Dravidian speech for the confidence scores to mitigate rather than amplify domain mismatch. This directly underpins the skeptic's concern and the central claim.
minor comments (2)
- Define all acronyms (ASR, WER, TTS, LM, KenLM) on first use and ensure consistent notation for confidence scores across sections.
- Add a table summarizing dataset statistics (train/dev/test splits, hours of real vs. synthetic speech) to support the reported results.
Simulated Author's Rebuttal
We thank the referee for the thorough review and constructive comments on our manuscript. We address each of the major comments below and will revise the manuscript to incorporate additional details and analyses as suggested.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): The manuscript reports specific WER values and claims of statistical outperformance without providing dataset sizes, number of utterances/speakers, vocabulary coverage for medical terms, or the statistical tests used to establish significance of the 8.5% and 6.3% absolute improvements. These details are load-bearing for attributing gains to the hybrid method rather than data artifacts or baseline differences.
Authors: We agree that providing these details is essential for reproducibility and to substantiate the claims. In the revised version, we will add the dataset statistics including the number of utterances and speakers for the Telugu and Kannada medical datasets, vocabulary coverage for medical terms, and describe the statistical tests (e.g., McNemar's test or bootstrap resampling) used to establish the significance of the reported WER improvements. revision: yes
-
Referee: [§3] §3 (Methodology): The hybrid confidence mechanism is described only at a high level; the exact definitions of the static perceptual and acoustic similarity metrics, the TTS system and its training data, and the optimization procedure for learnable weights are not given. Without these, it is impossible to verify whether the weighting reliably down-weights harmful synthetic samples whose Dravidian phonetics or medical terminology diverge from real recordings.
Authors: We acknowledge the need for more precise descriptions in the methodology. The revised manuscript will include the exact mathematical definitions of the static perceptual and acoustic similarity metrics, full specifications of the TTS system (including model architecture, training corpus, and synthesis parameters), and the detailed optimization procedure for the learnable weights, such as the gradient-based update rules and regularization terms. This will enable readers to assess the robustness of the weighting against domain mismatches. revision: yes
-
Referee: [§4] §4 (Experiments): No quantitative analysis (e.g., distribution distances, phoneme error rates on synthetic vs. real medical speech, or ablation on confidence components) is presented to confirm that the TTS synthetic data is representative enough of real medical-domain Dravidian speech for the confidence scores to mitigate rather than amplify domain mismatch. This directly underpins the skeptic's concern and the central claim.
Authors: We recognize that additional quantitative validation would strengthen the central claim. Although the substantial WER reductions observed with the learnable-weight strategy indicate that the hybrid confidence mechanism effectively leverages the synthetic data, we will include in the revision quantitative analyses such as distribution distances (e.g., Wasserstein distance or KL divergence on acoustic features), phoneme error rates comparing synthetic and real speech, and ablations isolating the contribution of each confidence component. These additions will demonstrate that the TTS data is representative and that the weighting mitigates potential mismatches. revision: yes
Circularity Check
No circularity: purely empirical results on held-out test sets
full rationale
The paper presents an empirical ASR training framework that combines real recordings with TTS synthetic data using a hybrid confidence mechanism (static metrics plus model entropy, with fixed vs. learnable weights). Performance is measured directly via WER on separate Telugu and Kannada medical test sets, yielding reported absolute improvements of 8.5% and 6.3%. No equations, derivations, or predictions appear; the central claims are experimental outcomes rather than quantities that reduce to inputs by construction. No self-citation load-bearing steps or ansatz smuggling are present in the described methodology. The work is self-contained against external benchmarks (held-out WER) and does not invoke uniqueness theorems or rename known results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption TTS-generated synthetic speech is sufficiently similar in acoustic and perceptual properties to real medical-domain speech to be useful when re-weighted by the hybrid confidence mechanism.
Reference graph
Works this paper leans on
- [1]
-
[3]
Available: https://arxiv.org/abs/2111.03945
[Online]. Available: https://arxiv.org/abs/2111.03945
- [4]
-
[5]
Ghosh, M
S. Ghosh, M. S. Rasooli, M. Levit, P. Wang, J. Xue, D. Manocha, and J. Li, ”Failing Forward: Improving Generative Error Correction for ASR with Synthetic Data and Retrieval Augmentation,” in Findings of the Association for Computational Linguistics: ACL 2025, Vienna, Aus- tria, 2025. [Online]. Available: https://aclanthology.org/2025.findings- acl.125/
2025
- [6]
-
[7]
S. Sathiyamoorthy, N. Mohana, A. Prakash, and H. A. Murthy, ”A Unified Framework for Collecting Text-to-Speech Synthesis Datasets for 22 Indian Languages,” arXiv preprint arXiv:2410.14197, 2024. [Online]. Available: https://arxiv.org/abs/2410.14197
- [8]
-
[9]
Radford, J
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, ”Robust Speech Recognition via Large-Scale Weak Supervi- sion,” in International Conference on Machine Learning (ICML), 2023, pp. 28492–28518
2023
- [10]
-
[11]
Laptev and B
A. Laptev and B. Ginsburg, ”Fast Entropy-Based Methods of Word- Level Confidence Estimation for End-to-End Automatic Speech Recog- nition,” in 2022 IEEE Spoken Language Technology Workshop (SLT), 2023, pp. 152–159
2022
-
[12]
Sequence transduction with recurrent neural networks.arXiv preprint arXiv:1211.3711,
A. Graves, “Sequence Transduction with Recurrent Neural Networks,” arXiv preprint arXiv:1211.3711, 2012
- [13]
-
[14]
N. Ravi, T. R. T, R. T. Chaganti, and V . Arora, ”ASR Confidence Estimation using True Class Lexical Similarity Score,” in Interspeech 2025, 2025, pp. 3658–3662
2025
-
[15]
V . Aggarwal, S. S. Nair, Y . Verma, and Y . Jogi, ”Adopting Whisper for Confidence Estimation,” arXiv preprint arXiv:2502.13446, 2025. [Online]. Available: https://arxiv.org/abs/2502.13446
-
[16]
wav2vec 2.0: A framework for self-supervised learning of speech representations,
A. Baevski, H. Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representa- tions,” arXiv preprint arXiv:2006.11477, 2020. [Online]. Available: https://arxiv.org/abs/2006.11477
-
[17]
Robust Speech Recognition via Large- Scale Weak Supervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust Speech Recognition via Large- Scale Weak Supervision,” OpenAI, 2022. [Online]. Available: https://cdn.openai.com/papers/whisper.pdf
2022
-
[18]
Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks,
A. Graves, S. Fern ´andez, F. Gomez, and J. Schmidhuber, “Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks,” in Proceedings of the 23rd International Conference on Machine Learning, pp. 369–376, 2006
2006
-
[19]
GMM-Based Evaluation of Synthetic Speech Quality Using 2D Classification in Pleasure-Arousal Scale,
J. Pribil, A. Pribilova, and J. Matousek, “GMM-Based Evaluation of Synthetic Speech Quality Using 2D Classification in Pleasure-Arousal Scale,” Applied Sciences, vol. 11, no. 1, p. 2, 2021
2021
-
[20]
Asr error correction and domain adaptation using machine translation,
A. Mani, S. Palaskar, N. V . Meripo, S. Konam, and F. Metze, “Asr error correction and domain adaptation using machine translation,” in *ICASSP 2020 – IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)*, 2020, pp. 6344–6348
2020
-
[21]
KenLM: Faster and Smaller Language Model Queries,
K. Heafield, “KenLM: Faster and Smaller Language Model Queries,” in *Proceedings of the Sixth Workshop on Statistical Machine Translation*, 2011, pp. 7–12
2011
-
[22]
IndicBART: A Pre-trained Model for Indic Natural Language Generation,
R. Dabre, H. Shrotriya, A. Kunchukuttan, R. Puduppully, M. M. Khapra, and P. Kumar, “IndicBART: A Pre-trained Model for Indic Natural Language Generation,” in Findings of the Association for Computational Linguistics: ACL 2022, 2022
2022
-
[23]
mt5: A massively multilingual pre-trained text-to-text transformer
L. Xue et al., “mT5: A Massively Multilingual Pre-Trained Text-to- Text Transformer,” arXiv preprint arXiv:2010.11934, 2021. [Online]. Available: https://arxiv.org/abs/2010.11934
-
[24]
Towards Building Text-To-Speech Systems for the Next Billion Users,
G. K. Kumar, P. S. V , P. Kumar, M. M. Khapra, and K. Nandakumar, “Towards Building Text-To-Speech Systems for the Next Billion Users,” arXiv preprint arXiv:2211.09536, 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.