Recognition: unknown
PASTA: A Patch-Agnostic Twofold-Stealthy Backdoor Attack on Vision Transformers
Pith reviewed 2026-05-10 01:56 UTC · model grok-4.3
The pith
A trigger placed on any patch can activate a hidden backdoor in vision transformers while remaining invisible in pixels and attention maps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PASTA achieves backdoor activation from arbitrary patches by strengthening the Trigger Radiating Effect through multi-location trigger insertion during training and solving a bi-level optimization problem that lets the model and trigger iteratively adapt, preserving stealthiness in both pixel space and attention maps while improving robustness to existing ViT defenses.
What carries the argument
The Trigger Radiating Effect, in which a patch-wise trigger spreads its influence to neighboring patches via long-range dependencies in self-attention, enhanced by multi-location insertion and an adaptive bi-level optimization framework.
If this is right
- The attack reaches 99.13 percent average success rate no matter which patch receives the trigger at inference time.
- Visual stealth improves by a factor of 144.43 and attention stealth by 18.68 relative to prior methods.
- Robustness against leading ViT defenses increases by a factor of 2.79 across tested datasets.
- The method outperforms both CNN-based and earlier ViT-based backdoor attacks in the reported metrics.
Where Pith is reading between the lines
- Similar radiating effects might appear in other attention-based models, suggesting the technique could transfer beyond vision transformers to language or multimodal systems.
- Defenders may need detection methods that scan for coordinated changes across multiple patches rather than single locations.
- The bi-level adaptation process could be studied for whether it introduces new failure modes when the attacker has limited access to the training process.
Load-bearing premise
Multi-location trigger insertion during training can reliably strengthen the radiating effect across patches without harming stealthiness, and the bi-level optimization will converge to a solution that works for unseen models, datasets, and trigger placements.
What would settle it
An experiment showing that attack success rate drops sharply below 90 percent when the trigger is placed at a patch position never used in the multi-location training phase, or that a current state-of-the-art defense successfully flags the model with high accuracy.
Figures











read the original abstract
Vision Transformers (ViTs) have achieved remarkable success across vision tasks, yet recent studies show they remain vulnerable to backdoor attacks. Existing patch-wise attacks typically assume a single fixed trigger location during inference to maximize trigger attention. However, they overlook the self-attention mechanism in ViTs, which captures long-range dependencies across patches. In this work, we observe that a patch-wise trigger can achieve high attack effectiveness when activating backdoors across neighboring patches, a phenomenon we term the Trigger Radiating Effect (TRE). We further find that inter-patch trigger insertion during training can synergistically enhance TRE compared to single-patch insertion. Prior ViT-specific attacks that maximize trigger attention often sacrifice visual and attention stealthiness, making them detectable. Based on these insights, we propose PASTA, a twofold stealthy patch-wise backdoor attack in both pixel and attention domains. PASTA enables backdoor activation when the trigger is placed at arbitrary patches during inference. To achieve this, we introduce a multi-location trigger insertion strategy to enhance TRE. However, preserving stealthiness while maintaining strong TRE is challenging, as TRE is weakened under stealthy constraints. We therefore formulate a bi-level optimization problem and propose an adaptive backdoor learning framework, where the model and trigger iteratively adapt to each other to avoid local optima. Extensive experiments show that PASTA achieves 99.13% attack success rate across arbitrary patches on average, while significantly improving visual and attention stealthiness (144.43x and 18.68x) and robustness (2.79x) against state-of-the-art ViT defenses across four datasets, outperforming CNN- and ViT-based baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PASTA, a patch-agnostic backdoor attack on Vision Transformers that achieves high attack success rates (claimed 99.13% average ASR) for arbitrary trigger locations at inference time. It introduces the Trigger Radiating Effect (TRE) observed in self-attention, strengthens it via multi-location trigger insertion during training, and uses a bi-level optimization framework with an adaptive learning procedure to jointly optimize the model and trigger for twofold stealth (pixel-domain visual and attention-domain). Experiments across four datasets report substantial gains in stealthiness (144.43x visual, 18.68x attention) and robustness (2.79x) over CNN- and ViT-based baselines while outperforming prior attacks.
Significance. If the empirical claims hold under rigorous validation, the work would be significant for demonstrating a practical, location-independent backdoor that exploits ViT self-attention propagation without sacrificing detectability, thereby exposing limitations in current ViT defenses and motivating new defense strategies focused on attention patterns and multi-location triggers.
major comments (3)
- [§3.2] §3.2 (Bi-level Optimization): The formulation and adaptive framework are described at a high level only, with no explicit description of the inner/outer loop objectives, alternation schedule, convergence criteria, or hyperparameter sensitivity analysis. This is load-bearing for the central claim because the 99.13% ASR for arbitrary patches and the reported stealth multipliers rest on the optimization reliably avoiding local optima and producing a generalizable trigger.
- [§4] §4 (Experiments): The abstract and results report aggregate metrics (99.13% ASR, 144.43x visual stealth, 2.79x robustness) without specifying data splits, number of random seeds/runs, statistical significance tests, or exact baseline implementations and hyperparameter settings. This undermines assessment of whether the outperformance and generalization across datasets and models are robust rather than artifacts of a narrow regime.
- [§2, §3.1] §2 and §3.1 (TRE and multi-location insertion): The Trigger Radiating Effect is introduced as an empirical observation without a precise quantitative definition or measurement protocol (e.g., how attention propagation is quantified across neighboring patches). No ablation is shown on the number of insertion locations versus stealth degradation, which directly tests the weakest assumption that multi-location training strengthens TRE without undermining the twofold stealth constraints.
minor comments (2)
- [§3] Notation for trigger patterns and insertion locations should be formalized (e.g., via a clear mathematical definition) to improve reproducibility.
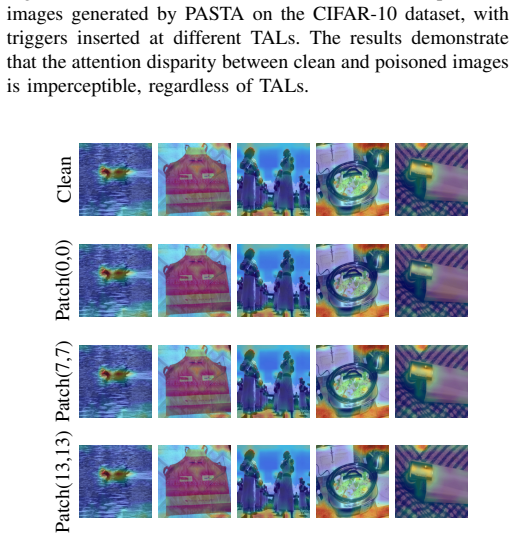
- [§4] Figures showing attention maps and visual examples would benefit from consistent scaling and inclusion of failure cases or edge patches to illustrate the claimed patch-agnostic property.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which highlight important areas for clarification and strengthening of the manuscript. We address each major comment point by point below. We agree that additional technical details are required in the bi-level optimization, experimental reporting, and TRE analysis sections, and we will revise the manuscript accordingly to improve rigor and reproducibility.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Bi-level Optimization): The formulation and adaptive framework are described at a high level only, with no explicit description of the inner/outer loop objectives, alternation schedule, convergence criteria, or hyperparameter sensitivity analysis. This is load-bearing for the central claim because the 99.13% ASR for arbitrary patches and the reported stealth multipliers rest on the optimization reliably avoiding local optima and producing a generalizable trigger.
Authors: We acknowledge that §3.2 presents the bi-level optimization and adaptive framework at a high level. In the revised manuscript, we will add the full mathematical formulation: the outer objective minimizes the combined clean loss and stealth penalties while the inner objective optimizes the trigger pattern under the multi-location insertion constraint. We will specify the alternation schedule (e.g., 5 inner steps per outer iteration), convergence criteria (loss plateau over 3 consecutive outer epochs with threshold 1e-4), and a hyperparameter sensitivity analysis (varying learning rates, λ_vis, and λ_att over ranges reported in an expanded Table). These additions will substantiate how the framework avoids local optima and yields the observed generalizable triggers. revision: yes
-
Referee: [§4] §4 (Experiments): The abstract and results report aggregate metrics (99.13% ASR, 144.43x visual stealth, 2.79x robustness) without specifying data splits, number of random seeds/runs, statistical significance tests, or exact baseline implementations and hyperparameter settings. This undermines assessment of whether the outperformance and generalization across datasets and models are robust rather than artifacts of a narrow regime.
Authors: We agree that §4 requires expanded reporting for reproducibility. In the revision, we will detail the exact train/validation/test splits for each of the four datasets (e.g., 80/10/10 for CIFAR-10), report all metrics as mean ± std over 5 independent random seeds, include paired t-tests for statistical significance against baselines, and provide complete hyperparameter tables plus implementation details (including optimizer settings and baseline re-implementations with citations to original code where available). This will confirm the robustness of the 99.13% ASR and the reported multipliers across datasets and models. revision: yes
-
Referee: [§2, §3.1] §2 and §3.1 (TRE and multi-location insertion): The Trigger Radiating Effect is introduced as an empirical observation without a precise quantitative definition or measurement protocol (e.g., how attention propagation is quantified across neighboring patches). No ablation is shown on the number of insertion locations versus stealth degradation, which directly tests the weakest assumption that multi-location training strengthens TRE without undermining the twofold stealth constraints.
Authors: We accept that TRE is presented primarily as an empirical observation. In the revision, we will introduce a precise quantitative definition: TRE is measured as the average self-attention weight from the trigger patch to its k-nearest neighboring patches (k=8) normalized by the global attention sum, computed on clean validation images. We will also add an ablation study in §4 varying the number of insertion locations (1, 4, 9, 16) during training and report the resulting ASR, visual stealth (PSNR/SSIM), attention stealth (attention map L2 distance), and defense robustness for each setting. This will directly validate that multi-location insertion enhances TRE while preserving the twofold stealth under the bi-level constraints. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's central claims derive from empirical observations of the Trigger Radiating Effect in ViT self-attention, followed by a multi-location insertion strategy and bi-level optimization to balance attack success with stealth. These steps are presented as design choices validated through experiments on four datasets, without any reduction of the reported ASR, stealth multipliers, or robustness gains to fitted parameters by construction, self-definitional equations, or load-bearing self-citations. The derivation chain remains independent and externally falsifiable via replication of the attack framework.
Axiom & Free-Parameter Ledger
free parameters (2)
- trigger pattern and insertion locations
- bi-level optimization hyperparameters
axioms (1)
- domain assumption Self-attention in ViTs creates long-range dependencies that allow a patch-wise trigger to influence neighboring patches (Trigger Radiating Effect).
invented entities (1)
-
Trigger Radiating Effect (TRE)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Handwritten digit recognition with a back-propagation network,
Y . LeCun, B. Boser, J. Denker, D. Henderson, R. Howard, W. Hubbard, and L. Jackel, “Handwritten digit recognition with a back-propagation network,” inAdvances in Neural Information Processing Systems, vol. 2, 1989
1989
-
[2]
ImageNet Classifica- tion with Deep Convolutional Neural Networks,
A. Krizhevsky, I. Sutskever, and G. E. Hinton, “ImageNet Classifica- tion with Deep Convolutional Neural Networks,”Advances in Neural Information Processing Systems, vol. 25, 2012
2012
-
[3]
Online Object Tracking: A Bench- mark,
Y . Wu, J. Lim, and M.-H. Yang, “Online Object Tracking: A Bench- mark,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2013, pp. 2411–2418
2013
-
[4]
Improving multiple object tracking with single object tracking,
L. Zheng, M. Tang, Y . Chen, G. Zhu, J. Wang, and H. Lu, “Improving multiple object tracking with single object tracking,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 2453–2462
2021
-
[5]
Object detection with deep learning: A review,
Z.-Q. Zhao, P. Zheng, S.-t. Xu, and X. Wu, “Object detection with deep learning: A review,”IEEE Transactions on Neural Networks and Learning Systems, vol. 30, no. 11, pp. 3212–3232, 2019
2019
-
[6]
Object detection in 20 years: A survey,
Z. Zou, K. Chen, Z. Shi, Y . Guo, and J. Ye, “Object detection in 20 years: A survey,”Proceedings of the IEEE, vol. 111, no. 3, pp. 257–276, 2023
2023
-
[7]
Deep face recognition: A survey,
M. Wang and W. Deng, “Deep face recognition: A survey,”Neurocom- puting, vol. 429, pp. 215–244, 2021
2021
-
[8]
An Image is Worth 16x16 Words: Trans- formers for Image Recognition at Scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An Image is Worth 16x16 Words: Trans- formers for Image Recognition at Scale,” inInternational Conference on Learning Representations, 2021
2021
-
[9]
Gradient-based Learning Applied to Document Recognition,
Y . Lecun, L. Bottou, Y . Bengio, and P. Haffner, “Gradient-based Learning Applied to Document Recognition,”Proceedings of the IEEE, vol. 86, no. 11, pp. 2278–2324, 1998
1998
-
[10]
BadNets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain
T. Gu, B. Dolan-Gavitt, and S. Garg, “Badnets: Identifying Vulnera- bilities in the Machine Learning Model Supply Chain,”arXiv preprint arXiv:1708.06733, 2017
work page internal anchor Pith review arXiv 2017
-
[11]
Targeted Backdoor Attacks on Deep Learning Systems Using Data Poisoning
X. Chen, C. Liu, B. Li, K. Lu, and D. Song, “Targeted Backdoor Attacks on Deep Learning Systems Using Data Poisoning,”arXiv preprint arXiv:1712.05526, 2017
work page internal anchor Pith review arXiv 2017
-
[12]
WaNet - Imperceptible Warping-based Backdoor Attack,
T. A. Nguyen and A. T. Tran, “WaNet - Imperceptible Warping-based Backdoor Attack,” inInternational Conference on Learning Represen- tations, 2021
2021
-
[13]
You Are Catching My Attention: Are Vision Transformers Bad Learners under Backdoor Attacks?
Z. Yuan, P. Zhou, K. Zou, and Y . Cheng, “You Are Catching My Attention: Are Vision Transformers Bad Learners under Backdoor Attacks?” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 24 605–24 615
2023
-
[14]
TrojViT: Trojan Insertion in Vision Transformers,
M. Zheng, Q. Lou, and L. Jiang, “TrojViT: Trojan Insertion in Vision Transformers,” inProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, 2022, pp. 4025–4034
2022
-
[15]
DBIA: Data-Free Backdoor Attack Against Transformer Networks,
P. Lv, H. Ma, J. Zhou, R. Liang, K. Chen, S. Zhang, and Y . Yang, “DBIA: Data-Free Backdoor Attack Against Transformer Networks,” inIEEE International Conference on Multimedia and Expo, 2023, pp. 2819–2824
2023
-
[16]
Attention-Imperceptible Backdoor Attacks on Vision Transformers,
Z. Wang, R. Wang, and L. Jing, “Attention-Imperceptible Backdoor Attacks on Vision Transformers,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 8, 2025, pp. 8241–8249
2025
-
[17]
Trojaning Attack on Neural Networks,
Y . Liu, S. Ma, Y . Aafer, W.-C. Lee, J. Zhai, W. Wang, and X. Zhang, “Trojaning Attack on Neural Networks,” inNetwork And Distributed System Security Symposium, 2018
2018
-
[18]
Input-Aware Dynamic Backdoor Attack,
T. A. Nguyen and A. Tran, “Input-Aware Dynamic Backdoor Attack,” inAdvances in Neural Information Processing Systems, vol. 33, 2020, pp. 3454–3464
2020
-
[19]
Lira: Learnable, Imperceptible and Robust Backdoor Attacks,
K. Doan, Y . Lao, W. Zhao, and P. Li, “Lira: Learnable, Imperceptible and Robust Backdoor Attacks,” inProceedings of the IEEE/CVF Inter- national Conference on Computer Vision, 2021, pp. 11 966–11 976
2021
-
[20]
DEFEAT: Deep Hidden Feature Backdoor Attacks by Imperceptible Perturbation and Latent Representation Constraints,
Z. Zhao, X. Chen, Y . Xuan, Y . Dong, D. Wang, and K. Liang, “DEFEAT: Deep Hidden Feature Backdoor Attacks by Imperceptible Perturbation and Latent Representation Constraints,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 15 213–15 222
2022
-
[21]
Deep Feature Space Trojan Attack of Neural Networks by Controlled Detoxification,
S. Cheng, Y . Liu, S. Ma, and X. Zhang, “Deep Feature Space Trojan Attack of Neural Networks by Controlled Detoxification,” inProceed- ings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 2, 2021, pp. 1148–1156
2021
-
[22]
An Invisible Black-box Backdoor Attack through Frequency Domain,
T. Wang, Y . Yao, F. Xu, S. An, H. Tong, and T. Wang, “An Invisible Black-box Backdoor Attack through Frequency Domain,” inEuropean Conference on Computer Vision, 2022, pp. 396–413
2022
-
[23]
Fiba: Frequency-injection based Backdoor Attack in Medical Image Analysis,
Y . Feng, B. Ma, J. Zhang, S. Zhao, Y . Xia, and D. Tao, “Fiba: Frequency-injection based Backdoor Attack in Medical Image Analysis,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 20 876–20 885
2022
-
[24]
LADDER: Multi-objective Backdoor Attack via Evolutionary Algorithm,
D. Liu, Y . Qiao, R. Wang, K. Liang, and G. Smaragdakis, “LADDER: Multi-objective Backdoor Attack via Evolutionary Algorithm,” inNet- work and Distributed System Security Symposium, 2025
2025
-
[25]
Low-frequency Black-box Backdoor Attack via Evolutionary Algorithm,
Y . Qiao, D. Liu, R. Wang, and K. Liang, “Low-frequency Black-box Backdoor Attack via Evolutionary Algorithm,” inIEEE/CVF Winter Conference on Applications of Computer Vision, 2025, pp. 7582–7592
2025
-
[26]
Attention Is All You Need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention Is All You Need,” inAdvances in Neural Information Processing Systems, vol. 30, 2017, pp. 5999–6009
2017
-
[27]
Narcissus: A Practical Clean-Label Backdoor Attack with Limited Information,
Y . Zeng, M. Pan, H. A. Just, L. Lyu, M. Qiu, and R. Jia, “Narcissus: A Practical Clean-Label Backdoor Attack with Limited Information,” inProceedings of the ACM SIGSAC Conference on Computer and Communications Security, 2023, pp. 771–785
2023
-
[28]
Backdoor Attacks on Vision Transformers,
A. Subramanya, A. Saha, S. A. Koohpayegani, A. Tejankar, and H. Pir- siavash, “Backdoor Attacks on Vision Transformers,”arXiv preprint arXiv:2206.08477, 2022
-
[29]
Watch Out! Simple Horizontal Class Backdoor Can Trivially Evade Defense,
H. Ma, S. Wang, Y . Gao, Z. Zhang, H. Qiu, M. Xue, A. Abuadbba, A. Fu, S. Nepal, and D. Abbott, “Watch Out! Simple Horizontal Class Backdoor Can Trivially Evade Defense,” inProceedings of the ACM SIGSAC Conference on Computer and Communications Security, 2024, pp. 4465–4479
2024
-
[30]
BELT: Old-School Backdoor Attacks can Evade the State-of-the-Art Defense with Backdoor Exclusivity Lifting,
H. Qiu, J. Sun, M. Zhang, X. Pan, and M. Yang, “ BELT: Old-School Backdoor Attacks can Evade the State-of-the-Art Defense with Backdoor Exclusivity Lifting,” inIEEE Symposium on Security and Privacy, 2024, pp. 2124–2141
2024
-
[31]
A new Backdoor Attack in CNNs by Training Set Corruption without Label Poisoning,
M. Barni, K. Kallas, and B. Tondi, “A new Backdoor Attack in CNNs by Training Set Corruption without Label Poisoning,” inIEEE International Conference on Image Processing, 2019, pp. 101–105. IEEE TRANSACTIONS ON INFORMATION FORENSICS AND SECURITY , VOL. XX, 2026 13
2019
-
[32]
Reflection Backdoor: A Natural Backdoor Attack on Deep Neural Networks,
Y . Liu, X. Ma, J. Bailey, and F. Lu, “Reflection Backdoor: A Natural Backdoor Attack on Deep Neural Networks,” inEuropean Conference on Computer Vision, 2020, pp. 182–199
2020
-
[33]
Invisible Backdoor Attack with Sample-Specific Triggers,
Y . Li, Y . Li, B. Wu, L. Li, R. He, and S. Lyu, “Invisible Backdoor Attack with Sample-Specific Triggers,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 16 463–16 472
2021
-
[34]
Color Backdoor: A Robust Poisoning Attack in Color Space,
W. Jiang, H. Li, G. Xu, and T. Zhang, “Color Backdoor: A Robust Poisoning Attack in Color Space,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 8133–8142
2023
-
[35]
Rethinking the Backdoor Attacks’ Triggers: A Frequency Perspective,
Y . Zeng, W. Park, Z. M. Mao, and R. Jia, “Rethinking the Backdoor Attacks’ Triggers: A Frequency Perspective,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 16 473–16 481
2021
-
[36]
A Stealthy and Robust Backdoor Attack via Frequency Domain Transform,
R. Hou, T. Huang, H. Yan, L. Ke, and W. Tang, “A Stealthy and Robust Backdoor Attack via Frequency Domain Transform,”World Wide Web, pp. 1–17, 2023
2023
-
[37]
Backdoor Attack with Imperceptible Input and Latent Modification,
K. Doan, Y . Lao, and P. Li, “Backdoor Attack with Imperceptible Input and Latent Modification,” inAdvances in Neural Information Processing Systems, vol. 34, 2021, pp. 18 944–18 957
2021
-
[38]
Imperceptible Backdoor Attack: From Input Space to Feature Representation,
N. Zhong, Z. Qian, and X. Zhang, “Imperceptible Backdoor Attack: From Input Space to Feature Representation,” inProceedings of the International Joint Conference on Artificial Intelligence, 2022, pp. 1736– 1742
2022
-
[39]
A Data-free Backdoor Injection Approach in Neural Networks,
P. Lv, C. Yue, R. Liang, Y . Yang, S. Zhang, H. Ma, and K. Chen, “A Data-free Backdoor Injection Approach in Neural Networks,” in USENIX Security Symposium, 2023, pp. 2671–2688
2023
-
[40]
Flowmur: A stealthy and Practical Audio Backdoor Attack with Limited Knowledge,
J. Lan, J. Wang, B. Yan, Z. Yan, and E. Bertino, “Flowmur: A stealthy and Practical Audio Backdoor Attack with Limited Knowledge,” inIEEE Symposium on Security and Privacy, 2024, pp. 1646–1664
2024
-
[41]
Sneaky Spikes: Uncover- ing Stealthy Backdoor Attacks in Spiking Neural Networks with Neuro- morphic Data,
G. Abad, O. Ersoy, S. Picek, and A. Urbieta, “Sneaky Spikes: Uncover- ing Stealthy Backdoor Attacks in Spiking Neural Networks with Neuro- morphic Data,” inNetwork and Distributed System Security Symposium, 2024
2024
-
[42]
Bad- merging: Backdoor Attacks against Model Merging,
J. Zhang, J. Chi, Z. Li, K. Cai, Y . Zhang, and Y . Tian, “Bad- merging: Backdoor Attacks against Model Merging,”arXiv preprint arXiv:2408.07362, 2024
-
[43]
Strip: A Defence Against Trojan Attacks on Deep Neural Networks,
Y . Gao, C. Xu, D. Wang, S. Chen, D. C. Ranasinghe, and S. Nepal, “Strip: A Defence Against Trojan Attacks on Deep Neural Networks,” in Proceedings of the Annual Computer Security Applications Conference, 2019, pp. 113–125
2019
-
[44]
arXiv preprint arXiv:1811.03728 (2018)
B. Chen, W. Carvalho, N. Baracaldo, H. Ludwig, B. Edwards, T. Lee, I. Molloy, and B. Srivastava, “Detecting Backdoor Attacks on Deep Neural Networks by Activation Clustering,”arXiv preprint arXiv:1811.03728, 2018
-
[45]
Spectral Signatures in Backdoor Attacks,
B. Tran, J. Li, and A. Madry, “Spectral Signatures in Backdoor Attacks,” inAdvances in Neural Information Processing Systems, vol. 31, 2018, pp. 8011–8021
2018
-
[46]
Universal Litmus Patterns: Revealing Backdoor Attacks in CNNs,
S. Kolouri, A. Saha, H. Pirsiavash, and H. Hoffmann, “Universal Litmus Patterns: Revealing Backdoor Attacks in CNNs,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 301–310
2020
-
[47]
Fine-Pruning: Defending against Backdooring Attacks on Deep Neural Networks,
K. Liu, B. Dolan-Gavitt, and S. Garg, “Fine-Pruning: Defending against Backdooring Attacks on Deep Neural Networks,” inInternational Sym- posium on Research in Attacks, Intrusions, and Defenses, 2018, pp. 273– 294
2018
-
[48]
Neural Cleanse: Identifying and Mitigating Backdoor Attacks in Neural Networks,
B. Wang, Y . Yao, S. Shan, H. Li, B. Viswanath, H. Zheng, and B. Y . Zhao, “Neural Cleanse: Identifying and Mitigating Backdoor Attacks in Neural Networks,” inIEEE Symposium on Security and Privacy, 2019, pp. 707–723
2019
-
[49]
DeepInspect: A Black- box Trojan Detection and Mitigation Framework for Deep Neural Networks,
H. Chen, C. Fu, J. Zhao, and F. Koushanfar, “DeepInspect: A Black- box Trojan Detection and Mitigation Framework for Deep Neural Networks,” inProceedings of the International Joint Conference on Artificial Intelligence, 2019, pp. 4658–4664
2019
-
[50]
Defending Neural Backdoors via Generative Distribution Modeling,
X. Qiao, Y . Yang, and H. Li, “Defending Neural Backdoors via Generative Distribution Modeling,” inAdvances in Neural Information Processing Systems, vol. 32, 2019, pp. 14 027–14 036
2019
-
[51]
Neural Attention Distillation: Erasing Backdoor Triggers from Deep Neural Networks,
Y . Li, X. Lyu, N. Koren, L. Lyu, B. Li, and X. Ma, “Neural Attention Distillation: Erasing Backdoor Triggers from Deep Neural Networks,” inInternational Conference on Learning Representations, 2021
2021
-
[52]
Rethinking the Trigger of Backdoor Attack,
Y . Li, T. Zhai, B. Wu, Y . Jiang, Z. Li, and S. Xia, “Rethinking the Trigger of Backdoor Attack,”arXiv preprint arXiv:2004.04692, 2020
-
[53]
Deepsweep: An Evaluation Framework for Mitigating DNN Backdoor Attacks using Data Augmentation,
H. Qiu, Y . Zeng, S. Guo, T. Zhang, M. Qiu, and B. Thuraisingham, “Deepsweep: An Evaluation Framework for Mitigating DNN Backdoor Attacks using Data Augmentation,” inProceedings of the ACM Asia Conference on Computer and Communications Security, 2021, pp. 363– 377
2021
-
[54]
Backdoor Defense via Adaptively Splitting Poisoned Dataset,
K. Gao, Y . Bai, J. Gu, Y . Yang, and S.-T. Xia, “Backdoor Defense via Adaptively Splitting Poisoned Dataset,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 4005–4014
2023
-
[55]
Neural Polarizer: A Lightweight and Effective Backdoor Defense via Purifying Poisoned Features,
M. Zhu, S. Wei, H. Zha, and B. Wu, “Neural Polarizer: A Lightweight and Effective Backdoor Defense via Purifying Poisoned Features,” in Advances in Neural Information Processing Systems, vol. 36, 2023, pp. 1132–1153
2023
-
[56]
Black-box Backdoor Defense via Zero-shot Image Purification,
Y . Shi, M. Du, X. Wu, Z. Guan, J. Sun, and N. Liu, “Black-box Backdoor Defense via Zero-shot Image Purification,” inAdvances in Neural Information Processing Systems, vol. 36, 2023, pp. 57 336– 57 366
2023
-
[57]
Defending Backdoor Attacks on Vision Transformer via Patch Processing,
K. D. Doan, Y . Lao, P. Yang, and P. Li, “Defending Backdoor Attacks on Vision Transformer via Patch Processing,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 1, 2023, pp. 506–515
2023
-
[58]
Learning Multiple Layers of Features from Tiny Images,
A. Krizhevsky and G. Hinton, “Learning Multiple Layers of Features from Tiny Images,” 2009
2009
-
[59]
Hidden Trigger Backdoor Attacks,
A. Saha, A. Subramanya, and H. Pirsiavash, “Hidden Trigger Backdoor Attacks,” inProceedings of the AAAI Cconference on Artificial Intelli- gence, vol. 34, no. 07, 2020, pp. 11 957–11 965
2020
-
[60]
Stealthy backdoor attack against federated learning through frequency domain by backdoor neu- ron constraint and model camouflage,
Y . Qiao, D. Liu, R. Wang, and K. Liang, “Stealthy backdoor attack against federated learning through frequency domain by backdoor neu- ron constraint and model camouflage,”IEEE Journal on Emerging and Selected Topics in Circuits and Systems, vol. 14, no. 4, pp. 661–672, 2024
2024
-
[61]
Split Adaptation for Pre-trained Vision Transformers ,
L. Wang, B. Shang, Y . Li, P. Mohapatra, W. Dong, X. Wang, and Q. Zhu, “ Split Adaptation for Pre-trained Vision Transformers ,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, Jun. 2025, pp. 20 092–20 102
2025
-
[62]
Nocedal and S
J. Nocedal and S. J. Wright,Numerical Optimization. Springer, 2006
2006
-
[63]
Pareto Local Optima of Multiobjective NK-Landscapes with Correlated Objectives,
S. Verel, A. Liefooghe, L. Jourdan, and C. Dhaenens, “Pareto Local Optima of Multiobjective NK-Landscapes with Correlated Objectives,” inEvolutionary Computation in Combinatorial Optimization, 2011
2011
-
[64]
Decoupled Weight Decay Regularization,
I. Loshchilov and F. Hutter, “Decoupled Weight Decay Regularization,” inInternational Conference on Learning Representations, 2019
2019
-
[65]
Pytorch: An Imperative Style, High- Performance Deep Learning Library,
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, A. Desmaison, A. K ¨opf, E. Yang, Z. DeVito, M. Raison, A. Tejani, S. Chilamkurthy, B. Steiner, L. Fang, J. Bai, and C. Soumith, “Pytorch: An Imperative Style, High- Performance Deep Learning Library,” inAdvances in Neural Information Processing ...
2019
-
[66]
Training Data-efficient Image Transformers & Distillation Through Attention,
H. Touvron, M. Cord, M. Douze, F. Massa, A. Sablayrolles, and H. Jegou, “Training Data-efficient Image Transformers & Distillation Through Attention,” inInternational Conference on Machine Learning, 2021, pp. 10 347–10 357
2021
-
[67]
Go- ing Deeper with Image Transformers,
H. Touvron, M. Cord, A. Sablayrolles, G. Synnaeve, and H. Jegou, “Go- ing Deeper with Image Transformers,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 32–42
2021
-
[68]
BEiT: Bert Pre-training of Image Transformers,
H. Bao, L. Dong, S. Piao, and F. Wei, “BEiT: Bert Pre-training of Image Transformers,” inInternational Conference on Learning Repre- sentations, 2022
2022
-
[69]
The Unreasonable Effectiveness of Deep Features as a Perceptual Metric,
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The Unreasonable Effectiveness of Deep Features as a Perceptual Metric,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018, pp. 586–595
2018
-
[70]
Invisible Backdoor Attacks on Deep Neural Networks Via Steganography and Regulariza- tion,
S. Li, M. Xue, B. Z. H. Zhao, H. Zhu, and X. Zhang, “Invisible Backdoor Attacks on Deep Neural Networks Via Steganography and Regulariza- tion,”IEEE Transactions on Dependable and Secure Computing, vol. 18, pp. 2088–2105, 2019
2088
-
[71]
Low Frequency Adversarial Perturbation,
C. Guo, J. S. Frank, and K. Q. Weinberger, “Low Frequency Adversarial Perturbation,” inUncertainty in Artificial Intelligence, 2020, pp. 1127– 1137
2020
-
[72]
A Closer Look at Robustness of Vision Transformers to Backdoor Attacks ,
A. Subramanya, S. A. Koohpayegani, A. Saha, A. Tejankar, and H. Pir- siavash, “A Closer Look at Robustness of Vision Transformers to Backdoor Attacks ,” inIEEE/CVF Winter Conference on Applications of Computer Vision, 2024, pp. 3862–3871
2024
-
[73]
Intriguing Properties of Vision Transformers,
M. Naseer, K. Ranasinghe, S. Khan, M. Hayat, F. Khan, and M.-H. Yang, “Intriguing Properties of Vision Transformers,” inAdvances in Neural Information Processing Systems, vol. 34, 2021, pp. 23 296–23 308
2021
-
[74]
Adversarial neuron pruning purifies backdoored deep models,
D. Wu and Y . Wang, “Adversarial neuron pruning purifies backdoored deep models,”Advances in Neural Information Processing Systems, vol. 34, pp. 16 913–16 925, 2021
2021
-
[75]
S. Ren, K. He, R. Girshick, and J. Sun, “Faster r-cnn: Towards real- time object detection with region proposal networks,”arXiv preprint arXiv:1506.01497, 2016. IEEE TRANSACTIONS ON INFORMATION FORENSICS AND SECURITY , VOL. XX, 2026 14
-
[76]
Baddet: Backdoor attacks on object detection,
S.-H. Chan, Y . Dong, J. Zhu, X. Zhang, and J. Zhou, “Baddet: Backdoor attacks on object detection,” inEuropean Conference on Computer Vision. Springer, 2022, p. 396–412. APPENDIXA ETHICALCONSIDERATIONS This study reveals the vulnerability of ViTs to stealthy patch-wise triggers that can activate across arbitrary patches, highlighting the need for stronge...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.