Surrogate Functionals for Machine-Learned Orbital-Free Density Functional Theory
Pith reviewed 2026-05-10 01:16 UTC · model grok-4.3
The pith
Surrogate functionals let machine-learned OF-DFT recover ground-state densities without orthonormalization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
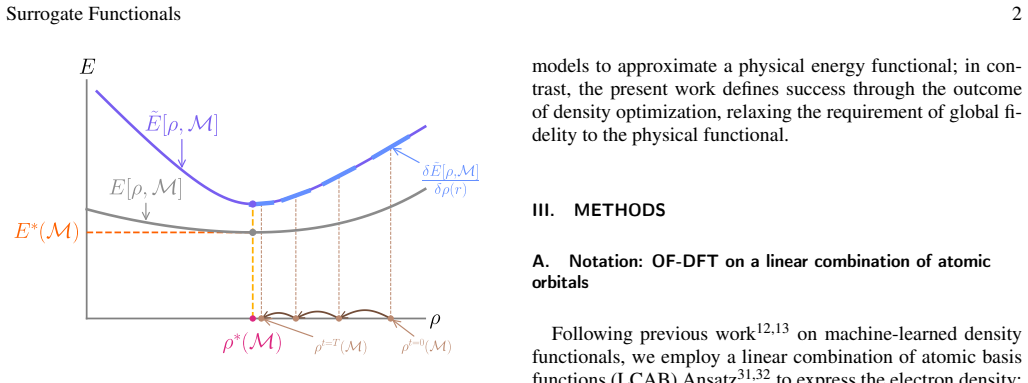
Surrogate functionals are machine-learned energy functionals defined not by universal physical fidelity but by the requirement that density optimization with a fixed procedure yields the true ground-state density. Training uses only ground-state densities and a gradient-descent-improvement loss that promotes exponential convergence to the ground state, combined with adaptive sampling that concentrates learning on the trajectories actually visited during inference. On QM9 and QMugs this produces density errors competitive with or improving upon fully supervised machine-learned OF-DFT while eliminating the O(N^3) orthonormalization step and its associated scaling costs.
What carries the argument
The gradient-descent-improvement loss, which trains the functional so that each step of density optimization reduces the distance to the ground state.
If this is right
- Density optimization requires only simple gradient steps with no O(N^3) orthonormalization.
- Training data collection is limited to reference ground-state densities.
- Runtime improves for larger molecules because the cubic-cost step is removed.
- Machine-learned OF-DFT becomes feasible for system sizes where full Kohn-Sham calculations remain prohibitive.
Where Pith is reading between the lines
- The adaptive sampling around inference trajectories could be reused in other iterative physics simulations to reduce data needs.
- If exponential convergence holds broadly, surrogate training might cut overall data requirements for ML models in quantum chemistry.
- The framework suggests hybrid ML-traditional optimization pipelines where the learned functional guides fast density updates.
Load-bearing premise
Minimizing the gradient-descent-improvement loss guarantees that density optimization will converge exponentially to the true ground-state density.
What would settle it
A test molecule where gradient-descent optimization of the surrogate functional produces a final density whose error substantially exceeds the reported benchmark errors relative to the reference ground-state density.
Figures


read the original abstract
We introduce surrogate functionals: machine-learned energy functionals for orbital-free density functional theory (OF-DFT) which are defined not by universal fidelity to a physical reference, but merely by the requirement that density optimization with a fixed procedure yields the true ground-state density. Helpfully, training surrogate functionals requires only ground-state densities, no energies or gradients away from the ground state. We here propose a gradient-descent-improvement loss that guarantees exponential convergence of the density to the ground state, and combine it with an adaptive sampling scheme that concentrates learning around the optimization trajectories actually visited during inference. On the QM9 and QMugs benchmarks, surrogate functionals achieve density errors competitive with or improving upon the state of the art for fully supervised machine-learned OF-DFT, while eliminating the need for the $O(N^3)$ orthononormalization step required by prior work, yielding improved runtime scaling for larger systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces surrogate functionals for machine-learned orbital-free density functional theory (OF-DFT). These functionals are defined by the property that a fixed density optimization procedure recovers the true ground-state density, rather than by direct fidelity to a physical energy functional. Training uses only ground-state densities via a proposed gradient-descent-improvement loss claimed to ensure exponential convergence, paired with an adaptive sampling scheme focused on inference trajectories. Benchmarks on QM9 and QMugs report density errors competitive with or better than prior fully supervised ML OF-DFT methods, while removing the O(N^3) orthonormalization step for improved scaling.
Significance. If the claimed exponential convergence holds and the adaptive sampling proves robust, the approach offers a practical advance for ML-OF-DFT by lowering supervision requirements and computational cost for larger systems. The removal of the orthonormalization bottleneck is a clear engineering benefit. The reported benchmark performance supports the central claim of competitive accuracy, but substantiation of the theoretical guarantees would elevate the contribution's impact in the field.
major comments (3)
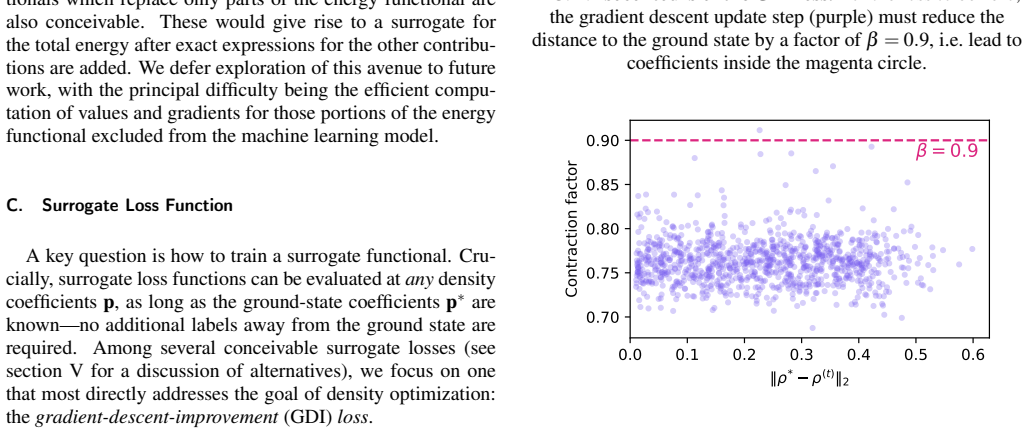
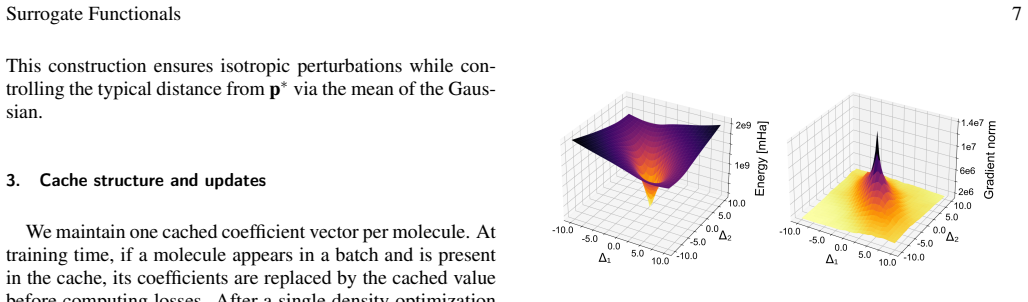
- [Section describing the gradient-descent-improvement loss (around the loss definition)] The gradient-descent-improvement loss is presented as guaranteeing exponential convergence to the ground-state density. No formal derivation, proof, or convergence analysis (e.g., rate constants or dependence on step size) is provided, and the numerical results lack error bars or explicit verification of the exponential rate. This property is load-bearing for the method's reliability and the claim of reduced supervision.
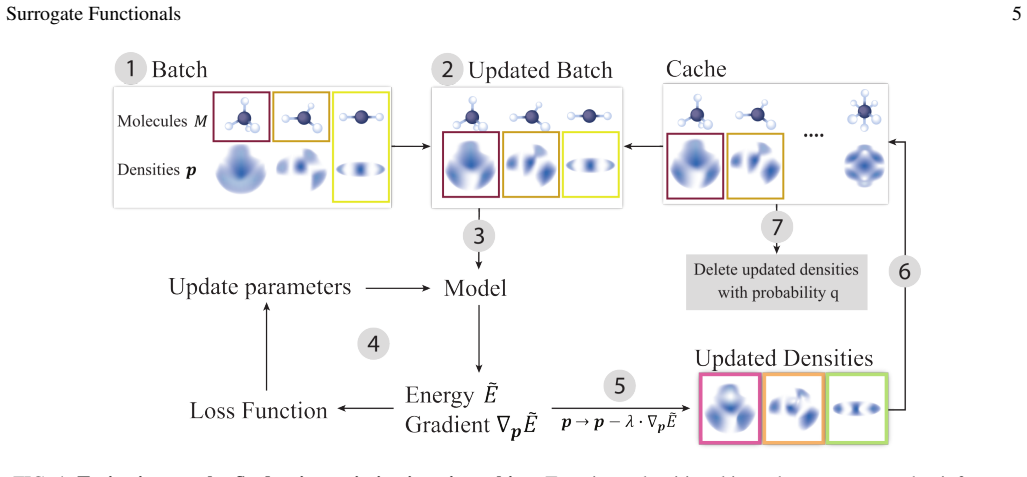
- [Section on the adaptive sampling scheme] The adaptive sampling scheme is asserted to concentrate learning on optimization trajectories visited at inference time. The manuscript provides no ablation studies, coverage analysis, or comparison to non-adaptive sampling to demonstrate that this avoids under-sampling of relevant density regions, which is central to the generalization argument.
- [Benchmark results section and associated tables] Benchmark results on QM9 and QMugs claim competitive or improved density errors versus state-of-the-art supervised ML-OF-DFT. However, the tables lack error bars, details on the number of independent runs, or statistical tests, making it difficult to assess whether reported improvements are significant or robust.
minor comments (2)
- [Introduction or early methods] Notation for the surrogate functional and the optimization procedure could be clarified with an explicit equation early in the methods section to aid readability.
- [Results or discussion] The abstract mentions 'improved runtime scaling' but the main text would benefit from a brief scaling plot or asymptotic analysis beyond the removal of the O(N^3) step.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We have carefully considered each point and provide point-by-point responses below. Where appropriate, we will revise the manuscript to address the concerns raised.
read point-by-point responses
-
Referee: [Section describing the gradient-descent-improvement loss (around the loss definition)] The gradient-descent-improvement loss is presented as guaranteeing exponential convergence to the ground-state density. No formal derivation, proof, or convergence analysis (e.g., rate constants or dependence on step size) is provided, and the numerical results lack error bars or explicit verification of the exponential rate. This property is load-bearing for the method's reliability and the claim of reduced supervision.
Authors: We appreciate the referee pointing out the need for a more rigorous treatment of the convergence properties. The gradient-descent-improvement loss is constructed such that each optimization step reduces the distance to the ground-state density in a way that leads to exponential decay under the assumption that the surrogate functional provides a sufficiently accurate direction. However, we agree that a formal derivation is missing from the current manuscript. In the revised version, we will include a new subsection with a proof sketch showing exponential convergence with a rate that depends on the learning rate and the Lipschitz constant of the surrogate. We will also add error bars to the convergence plots and report measured convergence rates from the numerical experiments to verify the exponential behavior. revision: yes
-
Referee: [Section on the adaptive sampling scheme] The adaptive sampling scheme is asserted to concentrate learning on optimization trajectories visited at inference time. The manuscript provides no ablation studies, coverage analysis, or comparison to non-adaptive sampling to demonstrate that this avoids under-sampling of relevant density regions, which is central to the generalization argument.
Authors: We thank the referee for this observation. The adaptive sampling is designed to sample densities along the trajectories generated by the fixed optimization procedure, thereby focusing on regions relevant at inference. To better substantiate this, we will add ablation experiments comparing the adaptive scheme to non-adaptive alternatives, such as sampling from a uniform distribution over density space or from random perturbations. We will also include an analysis of the coverage of the visited density manifold and its impact on generalization performance. revision: yes
-
Referee: [Benchmark results section and associated tables] Benchmark results on QM9 and QMugs claim competitive or improved density errors versus state-of-the-art supervised ML-OF-DFT. However, the tables lack error bars, details on the number of independent runs, or statistical tests, making it difficult to assess whether reported improvements are significant or robust.
Authors: We agree that providing statistical details would improve the reliability of the reported results. In the revised manuscript, we will update the benchmark tables to include error bars representing the standard deviation over multiple independent training runs (we will specify the number, e.g., 3 or 5 runs with different random seeds). We will also add a discussion on the statistical significance of the observed improvements where applicable. revision: yes
Circularity Check
Minor self-definitional element in surrogate definition; training and benchmarks remain independent
specific steps
-
self definitional
[Abstract]
"We introduce surrogate functionals: machine-learned energy functionals for orbital-free density functional theory (OF-DFT) which are defined not by universal fidelity to a physical reference, but merely by the requirement that density optimization with a fixed procedure yields the true ground-state density. ... We here propose a gradient-descent-improvement loss that guarantees exponential convergence of the density to the ground state"
The functional class is defined exactly by the convergence property that the gradient-descent-improvement loss is engineered to produce, so the modeling premise and the training objective are coextensive by construction; however, the actual benchmark performance is measured on external data and does not collapse to this definition.
full rationale
The surrogate is defined by the optimization property it must satisfy, and a loss is constructed to enforce it, but this is a deliberate modeling choice rather than a reduction of results to inputs. Training draws on independent ground-state densities from QM9/QMugs, the loss is newly proposed, and reported density errors plus runtime gains are empirical outcomes not forced by the definition. No self-citation chains, fitted predictions renamed as results, or ansatz smuggling appear in the provided text.
Axiom & Free-Parameter Ledger
free parameters (1)
- neural network parameters
axioms (1)
- domain assumption Ground-state densities from reference calculations are available and accurate
invented entities (1)
-
surrogate functional
no independent evidence
Reference graph
Works this paper leans on
-
[1]
author author W. Kohn \ and\ author L. J. \ Sham ,\ @noop journal journal Physical review \ volume 140 ,\ pages A1133 ( year 1965 ) NoStop
work page 1965
-
[2]
author author L. H. \ Thomas ,\ @noop journal journal Mathematical Proceedings of the Cambridge Philosophical Society \ volume 23 ,\ pages 542 ( year 1927 ) NoStop
work page 1927
-
[3]
author author E. Fermi ,\ @noop journal journal Zeitschrift f \"u r Physik \ volume 48 ,\ pages 73 ( year 1928 ) NoStop
work page 1928
-
[4]
a cker ,\ @noop journal journal Zeitschrift f \
author author C. F. \ Von Weizs \"a cker ,\ @noop journal journal Zeitschrift f \"u r Physik \ volume 96 ,\ pages 431 ( year 1935 ) NoStop
work page 1935
-
[5]
author author M. Chen , author M. Pavanello , author W. Mi , author M. Ihara , \ and\ author S. Manzhos ,\ @noop journal journal Journal of Chemical Theory and Computation \ ( year 2026 ) NoStop
work page 2026
-
[6]
author author J. C. \ Snyder , author M. Rupp , author K. Hansen , author L. Blooston , author K.-R. \ M \"u ller , \ and\ author K. Burke ,\ @noop journal journal The Journal of chemical physics \ volume 139 ,\ pages 224104 ( year 2013 ) NoStop
work page 2013
-
[7]
author author K. Yao \ and\ author J. Parkhill ,\ @noop journal journal J. Chem. Theory Comput. \ volume 12 ,\ pages 1139 ( year 2016 ) NoStop
work page 2016
-
[8]
author author J. Seino , author R. Kageyama , author M. Fujinami , author Y. Ikabata , \ and\ author H. Nakai ,\ @noop journal journal The Journal of chemical physics \ volume 148 ,\ pages 241705 ( year 2018 ) NoStop
work page 2018
-
[9]
author author M. Fujinami , author R. Kageyama , author J. Seino , author Y. Ikabata , \ and\ author H. Nakai ,\ @noop journal journal Chem. Phys. Lett. \ volume 748 ,\ pages 137358 ( year 2020 ) NoStop
work page 2020
-
[10]
author author R. Meyer , author M. Weichselbaum , \ and\ author A. W. \ Hauser ,\ @noop journal journal J. Chem. Theory Comput. \ volume 16 ,\ pages 5685 ( year 2020 ) NoStop
work page 2020
-
[11]
author author R. Remme , author T. Kaczun , author M. Scheurer , author A. Dreuw , \ and\ author F. A. \ Hamprecht ,\ @noop journal journal The Journal of Chemical Physics \ volume 159 ( year 2023 ) NoStop
work page 2023
-
[12]
author author H. Zhang , author S. Liu , author J. You , author C. Liu , author S. Zheng , author Z. Lu , author T. Wang , author N. Zheng , \ and\ author B. Shao ,\ @noop journal journal Nat. Comput. Sci. \ volume 4 ,\ pages 210 ( year 2024 ) NoStop
work page 2024
-
[13]
author author R. Remme , author T. Kaczun , author T. Ebert , author C. A. \ Gehrig , author D. Geng , author G. Gerhartz , author M. K. \ Ickler , author M. V. \ Klockow , author P. Lippmann , author J. S. \ Schmidt , et al. ,\ @noop journal journal Journal of the American Chemical Society \ volume 147 ,\ pages 28851 ( year 2025 ) NoStop
work page 2025
-
[14]
author author Y. LeCun , author S. Chopra , author R. Hadsell , author M. Ranzato , author F. Huang , et al. ,\ @noop journal journal Predicting structured data \ volume 1 ( year 2006 ) NoStop
work page 2006
-
[15]
author author D. Belanger \ and\ author A. McCallum ,\ in\ @noop booktitle International Conference on Machine Learning \ ( organization PMLR ,\ year 2016 )\ pp.\ pages 983--992 ,\ note introduces SPENs: Prediction by minimizing an energy function over outputs. Conceptually identical to finding coefficients minimizing energy. Stop
work page 2016
-
[16]
author author Y. Du \ and\ author I. Mordatch ,\ in\ @noop booktitle Advances in Neural Information Processing Systems ,\ Vol. volume 32 \ ( year 2019 )\ note discusses stability in training EBMs with Langevin dynamics, highly relevant to density optimization stability. Stop
work page 2019
-
[17]
author author W. Grathwohl , author K.-C. \ Wang , author J.-H. \ Jacobsen , author D. Duvenaud , author M. Norouzi , \ and\ author K. Swersky ,\ in\ @noop booktitle International Conference on Learning Representations \ ( year 2020 )\ note relevant for viewing discriminative models through an EBM lens, parallel to learning stability/validity of densities. Stop
work page 2020
-
[18]
author author Y. Song \ and\ author S. Ermon ,\ @noop journal journal Advances in Neural Information Processing Systems \ volume 32 ( year 2019 ) ,\ note foundational for score-matching. Relevant for gradient-matching losses/gradient-to-ground-state loss. Stop
work page 2019
-
[19]
author author A. J. \ Thakkar ,\ @noop journal journal Phys. Rev. A \ volume 46 ,\ pages 6920 ( year 1992 ) NoStop
work page 1992
-
[20]
author author L.-W. \ Wang \ and\ author M. P. \ Teter ,\ @noop journal journal Physical review. B, Condensed matter \ volume 45 ,\ pages 13196 ( year 1992 ) NoStop
work page 1992
-
[21]
author author C. Huang \ and\ author E. A. \ Carter ,\ @noop journal journal Physical Review B—Condensed Matter and Materials Physics \ volume 81 ,\ pages 045206 ( year 2010 ) NoStop
work page 2010
-
[22]
author author L. A. \ Constantin , author E. Fabiano , author S. Laricchia , \ and\ author F. Della Sala ,\ @noop journal journal Phys. Rev. Lett. \ volume 106 ,\ pages 186406 ( year 2011 ) NoStop
work page 2011
-
[23]
author author Y. Ke , author F. Libisch , author J. Xia , author L.-W. \ Wang , \ and\ author E. A. \ Carter ,\ @noop journal journal Phys. Rev. Lett. \ volume 111 ,\ pages 066402 ( year 2013 ) NoStop
work page 2013
-
[24]
author author K. Luo , author V. V. \ Karasiev , \ and\ author S. Trickey ,\ @noop journal journal Physical Review B \ volume 98 ,\ pages 041111 ( year 2018 ) NoStop
work page 2018
-
[25]
author author X. Shao , author W. Mi , \ and\ author M. Pavanello ,\ @noop journal journal Physical Review B \ volume 104 ,\ pages 045118 ( year 2021 ) NoStop
work page 2021
-
[26]
author author Q. Xu , author C. Ma , author W. Mi , author Y. Wang , \ and\ author Y. Ma ,\ @noop journal journal Nature Communications \ volume 13 ,\ pages 1385 ( year 2022 ) NoStop
work page 2022
-
[27]
author author W. Mi , author K. Luo , author S. Trickey , \ and\ author M. Pavanello ,\ @noop journal journal Chem. Rev. \ volume 123 ,\ pages 12039 ( year 2023 ) NoStop
work page 2023
-
[28]
author author P. Golub \ and\ author S. Manzhos ,\ @noop journal journal Physical Chemistry Chemical Physics \ volume 21 ,\ pages 378 ( year 2019 ) NoStop
work page 2019
-
[29]
author author R. Ramakrishnan , author P. O. \ Dral , author M. Rupp , \ and\ author O. A. \ Von Lilienfeld ,\ @noop journal journal Scientific Data \ volume 1 ,\ pages 1 ( year 2014 ) NoStop
work page 2014
-
[30]
author author C. Isert , author K. Atz , author J. Jim \'e nez-Luna , \ and\ author G. Schneider ,\ @noop journal journal Scientific Data \ volume 9 ,\ pages 273 ( year 2022 ) NoStop
work page 2022
-
[31]
author author A. Grisafi , author A. Fabrizio , author B. Meyer , author D. M. \ Wilkins , author C. Corminboeuf , \ and\ author M. Ceriotti ,\ @noop journal journal ACS central science \ volume 5 ,\ pages 57 ( year 2018 ) NoStop
work page 2018
-
[32]
author author U. A. \ Vergara-Beltran \ and\ author J. I. \ Rodr \' guez ,\ @noop journal journal J. Chem. Phys. \ volume 159 ,\ pages 124102 ( year 2023 ) NoStop
work page 2023
-
[33]
author author T. Tieleman ,\ in\ @noop booktitle International Conference on Machine Learning \ ( year 2008 )\ pp.\ pages 1064--1071 NoStop
work page 2008
-
[34]
author author C. Ying , author T. Cai , author S. Luo , author S. Zheng , author G. Ke , author D. He , author Y. Chen , \ and\ author T.-Y. \ Liu ,\ in\ @noop booktitle Advances in Neural Information Processing Systems ,\ Vol. volume 34 \ ( year 2021 )\ pp.\ pages 28877--28888 NoStop
work page 2021
-
[35]
author author P. Lippmann , author G. Gerhartz , author R. Remme , \ and\ author F. A. \ Hamprecht ,\ in\ @noop booktitle International Conference on Learning Representations \ ( year 2025 ) NoStop
work page 2025
- [36]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.