Recognition: 2 theorem links
· Lean TheoremMixture of Sequence: Theme-Aware Mixture-of-Experts for Long-Sequence Recommendation
Pith reviewed 2026-05-15 17:26 UTC · model grok-4.3
The pith
A theme-aware mixture-of-experts model splits long user sequences into coherent theme-specific subsequences to filter interest shifts and improve recommendations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
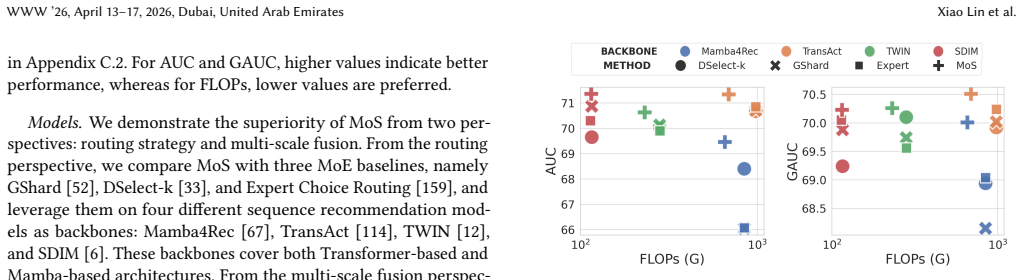
The Mixture of Sequence (MoS) framework is a model-agnostic MoE approach that extracts theme-specific and multi-scale subsequences from noisy raw user sequences. It employs a theme-aware routing mechanism to adaptively learn the latent themes of user sequences and organizes these sequences into multiple coherent subsequences. Each subsequence contains only sessions aligned with a specific theme. A multi-scale fusion mechanism then leverages three types of experts to capture global sequence characteristics, short-term user behaviors, and theme-specific semantic patterns.
What carries the argument
Theme-aware routing that groups sessions into theme-coherent subsequences, paired with multi-scale expert fusion for global, short-term, and semantic views.
If this is right
- Predictions rely only on sessions that match the active theme, reducing the impact of misleading shifts.
- The model remains compatible with many existing sequential backbones because the routing and fusion layers sit on top.
- Computational cost drops relative to standard MoE baselines because each expert processes shorter, cleaner subsequences.
- SOTA results hold across multiple datasets while reporting fewer total floating-point operations.
Where Pith is reading between the lines
- The same routing logic could extend to other sequential tasks that show periodic reappearance of patterns, such as next-basket prediction in retail.
- Increasing the number of themes or adding a hierarchical scale might handle extremely long histories with more frequent shifts.
- Combining the router with explicit user profile features could make theme discovery more stable on cold-start users.
Load-bearing premise
User interests remain stable inside short sessions and shift in patterns that a learned router can reliably separate into distinct latent themes without losing key signals.
What would settle it
A controlled test on standard long-sequence benchmarks where replacing the theme-aware router with random session grouping produces equal or higher accuracy and lower FLOPs than the full MoS model.
Figures








read the original abstract
Sequential recommendation has rapidly advanced in click-through rate prediction due to its ability to model dynamic user interests. A key challenge, however, lies in modeling long sequences: users often exhibit significant interest shifts, introducing substantial irrelevant or misleading information. Our empirical analysis corroborates this challenge and uncovers a recurring behavioral pattern in long sequences (\textit{session hopping}): user interests remain stable within short temporal spans (\textit{sessions}) but shift drastically across sessions and may reappear after multiple sessions. To address this challenge, we propose the Mixture of Sequence (MoS) framework, a model-agnostic MoE approach that achieves accurate predictions by extracting theme-specific and multi-scale subsequences from noisy raw user sequences. First, MoS employs a theme-aware routing mechanism to adaptively learn the latent themes of user sequences and organizes these sequences into multiple coherent subsequences. Each subsequence contains only sessions aligned with a specific theme, thereby effectively filtering out irrelevant or even misleading information introduced by user interest shifts in session hopping. In addition, to alleviate potential information loss, we introduce a multi-scale fusion mechanism, which leverages three types of experts to capture global sequence characteristics, short-term user behaviors, and theme-specific semantic patterns. Together, these two mechanisms endow MoS with the ability to deliver accurate recommendations from multi-faceted and multi-scale perspectives. Experimental results demonstrate that MoS consistently achieves the SOTA performance while introducing fewer FLOPs compared with other MoE counterparts, providing strong evidence of its excellent balance between utility and efficiency. The code is available at https://github.com/xiaolin-cs/MoS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Mixture of Sequence (MoS) framework, a model-agnostic Mixture-of-Experts approach for long-sequence recommendation. It identifies a recurring 'session hopping' pattern in which user interests remain stable within short temporal sessions but shift drastically across sessions. MoS employs a theme-aware routing mechanism to adaptively learn latent themes and extract coherent theme-specific subsequences that filter irrelevant information, together with a multi-scale fusion mechanism that combines experts capturing global sequence characteristics, short-term behaviors, and theme-specific patterns. The paper claims that this yields state-of-the-art performance while using fewer FLOPs than other MoE baselines, with code released at https://github.com/xiaolin-cs/MoS.
Significance. If the empirical results hold, the work offers a practical, model-agnostic way to mitigate interest-shift noise in long user sequences by exploiting stable intra-session themes and multi-scale experts, potentially improving the accuracy-efficiency trade-off in sequential recommendation. The open-source code is a clear positive for reproducibility. The significance is limited, however, by the absence of concrete experimental support for the core assumptions and performance claims.
major comments (2)
- [Abstract] Abstract: the central claim that 'MoS consistently achieves the SOTA performance while introducing fewer FLOPs compared with other MoE counterparts' is presented without any reference to datasets, baselines, metrics (AUC, NDCG, etc.), ablation tables, or statistical significance tests. This absence directly undermines verification of both the utility and efficiency assertions that constitute the paper's main contribution.
- [Abstract] Abstract: the theme-aware routing is asserted to 'adaptively learn the latent themes' and thereby filter misleading information from session hopping, yet no intra-/inter-session similarity statistics, theme coherence scores, or ablation isolating learned routing versus random routing is supplied. If the router fails to recover stable themes accurately, subsequence extraction becomes a source of information loss rather than a gain, rendering both the SOTA accuracy and the reported FLOPs reduction claims unsupported.
minor comments (1)
- [Abstract] The phrase 'session hopping' is introduced in italics without a formal definition or citation to prior session-based modeling literature; a brief operational definition would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and the need for stronger empirical grounding of our claims. We address each comment below and have updated the manuscript to incorporate additional details and analyses.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'MoS consistently achieves the SOTA performance while introducing fewer FLOPs compared with other MoE counterparts' is presented without any reference to datasets, baselines, metrics (AUC, NDCG, etc.), ablation tables, or statistical significance tests. This absence directly undermines verification of both the utility and efficiency assertions that constitute the paper's main contribution.
Authors: The abstract is intentionally concise as a high-level summary. The full manuscript provides the requested details in Section 5, with results across multiple public datasets, standard metrics including AUC and NDCG, comparisons to MoE and other baselines, ablation tables, FLOPs measurements, and statistical significance tests. To improve accessibility, we have revised the abstract to briefly reference the evaluation setting on public benchmarks with AUC/NDCG metrics and direct readers to the experimental section for full tables and analyses. revision: yes
-
Referee: [Abstract] Abstract: the theme-aware routing is asserted to 'adaptively learn the latent themes' and thereby filter misleading information from session hopping, yet no intra-/inter-session similarity statistics, theme coherence scores, or ablation isolating learned routing versus random routing is supplied. If the router fails to recover stable themes accurately, subsequence extraction becomes a source of information loss rather than a gain, rendering both the SOTA accuracy and the reported FLOPs reduction claims unsupported.
Authors: The manuscript already includes an empirical analysis of the session-hopping pattern and demonstrates the routing's value through end-to-end gains and component ablations. We agree that more targeted diagnostics would strengthen the argument. In the revision we have added intra-/inter-session similarity statistics, theme coherence scores, and a new ablation comparing the learned router against random routing; these results confirm that the router recovers coherent themes and that subsequence extraction improves rather than harms performance. revision: yes
Circularity Check
No significant circularity; architectural proposal is self-contained
full rationale
The paper proposes the Mixture of Sequence (MoS) framework as a model-agnostic MoE architecture featuring a theme-aware routing mechanism to organize user sequences into theme-specific subsequences and a multi-scale fusion mechanism with three expert types. These components are motivated by an empirical observation of session-hopping patterns rather than being defined in terms of target performance metrics or reduced to fitted parameters called predictions. No equations or derivations in the provided text reduce the central claims to self-citations, ansatzes smuggled via prior work, or renaming of known results; the SOTA and efficiency claims rest on external experimental comparisons. The derivation chain is therefore independent and self-contained.
Axiom & Free-Parameter Ledger
free parameters (2)
- number of latent themes
- expert scale configuration
axioms (1)
- domain assumption User interests remain stable within short temporal sessions but shift drastically across sessions (session hopping).
invented entities (2)
-
theme-aware routing mechanism
no independent evidence
-
multi-scale fusion mechanism
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
theme-aware routing mechanism ... maintains a theme codebook W ... computes its cosine similarity with each entry of the codebook ... EMA update ... k-means clustering to obtain k cluster centroids
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
session hopping phenomenon: user interests remain highly consistent within a session but differ substantially across adjacent sessions ... may reappear after several sessions
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Mengting Ai, Tianxin Wei, Yifan Chen, Zhichen Zeng, Ritchie Zhao, Girish Varatkar, Bita Darvish Rouhani, Xianfeng Tang, Hanghang Tong, and Jingrui He. 2025. ResMoE: Space-efficient Compression of Mixture of Experts LLMs via Residual Restoration. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 1. 1–12
work page 2025
- [2]
- [3]
-
[4]
Shuqing Bian, Xingyu Pan, Wayne Xin Zhao, Jinpeng Wang, Chuyuan Wang, and Ji-Rong Wen. 2023. Multi-modal mixture of experts represetation learning for sequential recommendation. InProceedings of the 32nd ACM international conference on information and knowledge management. 110–119
work page 2023
- [5]
-
[6]
Yue Cao, Xiaojiang Zhou, Jiaqi Feng, Peihao Huang, Yao Xiao, Dayao Chen, and Sheng Chen. 2022. Sampling is all you need on modeling long-term user behaviors for CTR prediction. InProceedings of the 31st ACM International Conference on Information & Knowledge Management. 2974–2983
work page 2022
- [7]
-
[8]
Zheng Chai, Qin Ren, Xijun Xiao, et al. 2025. Longer: Scaling up long sequence modeling in industrial recommenders. InProceedings of the Nineteenth ACM Conference on Recommender Systems. 247–256
work page 2025
-
[9]
Jianxin Chang, Chen Gao, Xiangnan He, Depeng Jin, and Yong Li. 2020. Bundle recommendation with graph convolutional networks. InProceedings of the 43rd international ACM SIGIR conference on Research and development in Information Retrieval. 1673–1676
work page 2020
-
[11]
Jianxin Chang, Chen Gao, Yu Zheng, Yiqun Hui, Yanan Niu, Yang Song, Depeng Jin, and Yong Li. 2021. Sequential recommendation with graph neural networks. InProceedings of the 44th international ACM SIGIR conference on research and development in information retrieval. 378–387
work page 2021
-
[12]
Jianxin Chang, Chenbin Zhang, Zhiyi Fu, Xiaoxue Zang, Lin Guan, Jing Lu, Yiqun Hui, Dewei Leng, Yanan Niu, Yang Song, et al. 2023. TWIN: TWo-stage interest network for lifelong user behavior modeling in CTR prediction at kuaishou. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 3785–3794
work page 2023
-
[13]
Hao Chen, Yuanchen Bei, Qijie Shen, Yue Xu, Sheng Zhou, Wenbing Huang, Feiran Huang, Senzhang Wang, and Xiao Huang. 2024. Macro graph neural networks for online billion-scale recommender systems. InProceedings of the ACM web conference 2024. 3598–3608
work page 2024
-
[14]
Hong Chen, Yudong Chen, Xin Wang, et al . 2021. Curriculum disentangled recommendation with noisy multi-feedback.NeurIPS34 (2021), 26924–26936
work page 2021
-
[15]
Huiyuan Chen, Zhe Xu, Chin-Chia Michael Yeh, Vivian Lai, Yan Zheng, Minghua Xu, and Hanghang Tong. 2024. Masked graph transformer for large-scale recommendation. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2502–2506
work page 2024
-
[16]
Xusong Chen, Dong Liu, Zheng-Jun Zha, Wengang Zhou, Zhiwei Xiong, and Yan Li. 2018. Temporal hierarchical attention at category-and item-level for micro- video click-through prediction. InProceedings of the 26th ACM international conference on Multimedia. 1146–1153
work page 2018
-
[17]
Xu Chen, Hongteng Xu, Yongfeng Zhang, et al. 2018. Sequential recommenda- tion with user memory networks. InProceedings of the eleventh ACM interna- tional conference on web search and data mining. 108–116
work page 2018
-
[18]
Yongjun Chen, Zhiwei Liu, Jia Li, Julian McAuley, and Caiming Xiong. 2022. Intent contrastive learning for sequential recommendation. InProceedings of the ACM Web Conference 2022. 2172–2182
work page 2022
-
[19]
Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, et al . 2016. Wide & deep learning for recommender systems. InProceedings of the 1st workshop on deep learning for recommender systems. 7–10
work page 2016
-
[20]
Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, et al
-
[21]
InProceedings of the 1st workshop on deep learning for recommender systems
Wide & deep learning for recommender systems. InProceedings of the 1st workshop on deep learning for recommender systems. 7–10
-
[22]
Zewen Chi, Li Dong, Shaohan Huang, Damai Dai, Shuming Ma, Barun Patra, Saksham Singhal, Payal Bajaj, Xia Song, Xian-Ling Mao, et al. 2022. On the repre- sentation collapse of sparse mixture of experts.Advances in Neural Information Processing Systems35 (2022), 34600–34613
work page 2022
- [23]
-
[24]
Paul Covington, Jay Adams, and Emre Sargin. 2016. Deep neural networks for youtube recommendations. InProceedings of the 10th ACM conference on recommender systems. 191–198
work page 2016
-
[25]
Damai Dai, Chengqi Deng, Chenggang Zhao, et al. 2024. Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models.arXiv preprint arXiv:2401.06066(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Kaize Ding, Zhe Xu, Hanghang Tong, and Huan Liu. 2022. Data augmentation for deep graph learning: A survey.ACM SIGKDD Explorations Newsletter24, 2 (2022), 61–77
work page 2022
-
[27]
Nan Du, Yanping Huang, Andrew M Dai, Simon Tong, Dmitry Lepikhin, Yuanzhong Xu, Maxim Krikun, Yanqi Zhou, Adams Wei Yu, Orhan Firat, et al
-
[28]
In International Conference on Machine Learning
Glam: Efficient scaling of language models with mixture-of-experts. In International Conference on Machine Learning. PMLR, 5547–5569
-
[29]
Wenqi Fan, Yao Ma, Qing Li, Yuan He, Eric Zhao, Jiliang Tang, and Dawei Yin
-
[30]
InThe world wide web conference
Graph neural networks for social recommendation. InThe world wide web conference. 417–426
-
[31]
William Fedus, Barret Zoph, and Noam Shazeer. 2022. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research23, 120 (2022), 1–39
work page 2022
-
[32]
Dongqi Fu, Zhe Xu, Hanghang Tong, and Jingrui He. 2023. Natural and artificial dynamics in gnns: A tutorial. InProceedings of the Sixteenth ACM International Conference on Web Search and Data Mining. 1252–1255
work page 2023
-
[33]
Shijie Geng, Shuchang Liu, Zuohui Fu, Yingqiang Ge, and Yongfeng Zhang. 2022. Recommendation as language processing (rlp): A unified pretrain, personalized prompt & predict paradigm (p5). InProceedings of the 16th ACM Conference on Recommender Systems. 299–315
work page 2022
-
[34]
Huifeng Guo, Ruiming Tang, Yunming Ye, Zhenguo Li, and Xiuqiang He. 2017. DeepFM: a factorization-machine based neural network for CTR prediction. arXiv preprint arXiv:1703.04247(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[35]
Jiayan Guo, Yaming Yang, Xiangchen Song, Yuan Zhang, Yujing Wang, Jing Bai, and Yan Zhang. 2022. Learning multi-granularity consecutive user intent unit for session-based recommendation. InProceedings of the fifteenth ACM International conference on web search and data mining. 343–352
work page 2022
-
[36]
Hussein Hazimeh, Zhe Zhao, Aakanksha Chowdhery, et al . 2021. Dselect-k: Differentiable selection in the mixture of experts with applications to multi-task learning.NeurIPS34 (2021), 29335–29347
work page 2021
-
[37]
Xiangnan He, Kuan Deng, Xiang Wang, Yan Li, Yongdong Zhang, and Meng Wang. 2020. Lightgcn: Simplifying and powering graph convolution network for recommendation. InProceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval. 639–648
work page 2020
-
[40]
Balázs Hidasi, Alexandros Karatzoglou, Linas Baltrunas, and Domonkos Tikk
-
[41]
Session-based recommendations with recurrent neural networks.arXiv preprint arXiv:1511.06939(2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[42]
Yupeng Hou, Binbin Hu, Zhiqiang Zhang, and Wayne Xin Zhao. 2022. Core: simple and effective session-based recommendation within consistent represen- tation space. InProceedings of the 45th international ACM SIGIR conference on research and development in information retrieval. 1796–1801
work page 2022
-
[43]
Yupeng Hou, Shanlei Mu, Wayne Xin Zhao, Yaliang Li, Bolin Ding, and Ji- Rong Wen. 2022. Towards universal sequence representation learning for recommender systems. InProceedings of the 28th ACM SIGKDD conference on knowledge discovery and data mining. 585–593
work page 2022
-
[44]
Robert A Jacobs, Michael I Jordan, Steven J Nowlan, and Geoffrey E Hinton
-
[45]
Adaptive mixtures of local experts.Neural computation3, 1 (1991), 79–87
work page 1991
-
[46]
Baoyu Jing, Yuchen Yan, Kaize Ding, Chanyoung Park, Yada Zhu, Huan Liu, and Hanghang Tong. 2024. Sterling: Synergistic representation learning on bipartite graphs. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 12976–12984
work page 2024
- [47]
-
[50]
Wang-Cheng Kang and Julian McAuley. 2018. Self-attentive sequential recom- mendation. In2018 IEEE international conference on data mining (ICDM). IEEE, 197–206
work page 2018
-
[51]
Diederik P Kingma. 2014. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980(2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[52]
TN Kipf. 2016. Semi-supervised classification with graph convolutional net- works.arXiv preprint arXiv:1609.02907(2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[53]
Ivan Koychev and Ingo Schwab. 2000. Adaptation to drifting user’s interests. In Proceedings of ECML2000 workshop: machine learning in new information age. WWW ’26, April 13–17, 2026, Dubai, United Arab Emirates Xiao Lin et al. 39–46
work page 2000
-
[54]
Johannes Kruse, Kasper Lindskow, et al. 2024. EB-NeRD a large-scale dataset for news recommendation. InProceedings of the Recommender Systems Challenge
work page 2024
-
[55]
Wai Lam and Javed Mostafa. 2001. Modeling user interest shift using a bayesian approach.Journal of the American society for Information Science and Technology 52, 5 (2001), 416–429
work page 2001
-
[56]
Wai Lam, Snehasis Mukhopadhyay, Javed Mostafa, and Mathew Palakal. 1996. Detection of shifts in user interests for personalized information filtering. In Proceedings of the 19th annual international ACM SIGIR conference on Research and development in information retrieval. 317–325
work page 1996
-
[57]
Gyuseok Lee, Yaokun Liu, Yifan Liu, Susik Yoon, Dong Wang, and SeongKu Kang. 2025. Session-Based Recommendation with Validated and Enriched LLM Intents.arXiv preprint arXiv:2508.00570(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, et al. 2020. Gshard: Scaling giant models with conditional computation and automatic sharding.arXiv preprint arXiv:2006.16668(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[59]
Dingcheng Li, Xu Li, Jun Wang, and Ping Li. 2020. Video recommendation with multi-gate mixture of experts soft actor critic. InProceedings of the 43rd International ACM SIGIR conference on research and development in information retrieval. 1553–1556
work page 2020
-
[60]
Honghao Li, Yiwen Zhang, Yi Zhang, Hanwei Li, Lei Sang, and Jieming Zhu
- [61]
-
[62]
Haoxuan Li, Chunyuan Zheng, Wenjie Wang, Hao Wang, Fuli Feng, and Xiao- Hua Zhou. 2024. Debiased recommendation with noisy feedback. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 1576–1586
work page 2024
-
[63]
Jinning Li, Ruipeng Han, Chenkai Sun, Dachun Sun, Ruijie Wang, Jingying Zeng, Yuchen Yan, Hanghang Tong, and Tarek Abdelzaher. 2024. Large language model-guided disentangled belief representation learning on polarized social graphs. In2024 33rd International Conference on Computer Communications and Networks (ICCCN). IEEE, 1–9
work page 2024
-
[64]
Jing Li, Pengjie Ren, Zhumin Chen, Zhaochun Ren, Tao Lian, and Jun Ma. 2017. Neural attentive session-based recommendation. InProceedings of the 2017 ACM on Conference on Information and Knowledge Management. 1419–1428
work page 2017
-
[65]
Jinning Li, Huajie Shao, Dachun Sun, Ruijie Wang, Yuchen Yan, Jinyang Li, Shengzhong Liu, Hanghang Tong, and Tarek Abdelzaher. 2022. Unsupervised belief representation learning with information-theoretic variational graph auto-encoders. InProceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1728–1738
work page 2022
-
[66]
Ting Wei Li, Qiaozhu Mei, and Jiaqi Ma. 2023. A metadata-driven approach to understand graph neural networks.Advances in Neural Information Processing Systems36 (2023), 15320–15340
work page 2023
-
[67]
Yongqi Li, Meng Liu, Jianhua Yin, Chaoran Cui, Xin-Shun Xu, and Liqiang Nie. 2019. Routing micro-videos via a temporal graph-guided recommendation system. InProceedings of the 27th ACM international conference on multimedia. 1464–1472
work page 2019
- [68]
-
[69]
Mingfu Liang, Xi Liu, Rong Jin, Boyang Liu, Qiuling Suo, Qinghai Zhou, Song Zhou, Laming Chen, Hua Zheng, Zhiyuan Li, et al. 2025. External large foun- dation model: How to efficiently serve trillions of parameters for online ads recommendation. InCompanion Proceedings of the ACM on Web Conference 2025. 344–353
work page 2025
-
[70]
Xiao Lin, Jian Kang, Weilin Cong, and Hanghang Tong. 2024. Bemap: Balanced message passing for fair graph neural network. InLearning on Graphs Conference. PMLR, 37–1
work page 2024
-
[71]
Xiao Lin, Zhining Liu, Dongqi Fu, Ruizhong Qiu, and Hanghang Tong. 2024. Backtime: Backdoor attacks on multivariate time series forecasting.Advances in Neural Information Processing Systems37 (2024), 131344–131368
work page 2024
- [72]
- [73]
- [74]
-
[75]
Cheng Liu, Chenhuan Yu, Ning Gui, Zhiwu Yu, and Songgaojun Deng. 2024. SimGCL: graph contrastive learning by finding homophily in heterophily.Knowl- edge and Information Systems66, 3 (2024), 2089–2114
work page 2024
-
[76]
Qiao Liu, Yifu Zeng, Refuoe Mokhosi, and Haibin Zhang. 2018. STAMP: short- term attention/memory priority model for session-based recommendation. In Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 1831–1839
work page 2018
-
[77]
Xin Liu, Zheng Li, Yifan Gao, et al . 2023. Enhancing user intent capture in session-based recommendation with attribute patterns.Advances in Neural Information Processing Systems36 (2023), 30821–30839
work page 2023
-
[78]
Xin Liu, Zheng Li, Yifan Gao, Jingfeng Yang, Tianyu Cao, Zhengyang Wang, Bing Yin, and Yangqiu Song. 2024. Enhancing User Intent Capture in Session- Based Recommendation with Attribute Patterns.Advances in Neural Information Processing Systems36 (2024)
work page 2024
- [79]
-
[80]
Zhining Liu, Rana Ali Amjad, Ravinarayana Adkathimar, Tianxin Wei, and Hanghang Tong. 2025. SelfElicit: Your language model secretly knows where is the relevant evidence. InProceedings of the 63rd Annual Meeting of the Asso- ciation for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, 9153–9173
work page 2025
- [81]
- [82]
-
[83]
Zhining Liu, Ruizhong Qiu, Zhichen Zeng, Hyunsik Yoo, David Zhou, Zhe Xu, Yada Zhu, Kommy Weldemariam, Jingrui He, and Hanghang Tong. 2024. Class-Imbalanced Graph Learning without Class Rebalancing. InForty-first International Conference on Machine Learning
work page 2024
-
[84]
Zhining Liu, Ze Yang, Xiao Lin, Ruizhong Qiu, Tianxin Wei, Yada Zhu, Hendrik Hamann, Jingrui He, and Hanghang Tong. 2025. Breaking Silos: Adaptive Model Fusion Unlocks Better Time Series Forecasting. InProceedings of the 42nd International Conference on Machine Learning, Vol. 267. PMLR, 40022–40042
work page 2025
-
[85]
Jiaqi Ma, Zhe Zhao, Jilin Chen, Ang Li, Lichan Hong, and Ed H Chi. 2019. Snr: Sub-network routing for flexible parameter sharing in multi-task learning. In Proceedings of the AAAI conference on artificial intelligence, Vol. 33. 216–223
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.