Reinforcing privacy reasoning in LLMs via normative simulacra from fiction
Pith reviewed 2026-05-10 02:12 UTC · model grok-4.3
The pith
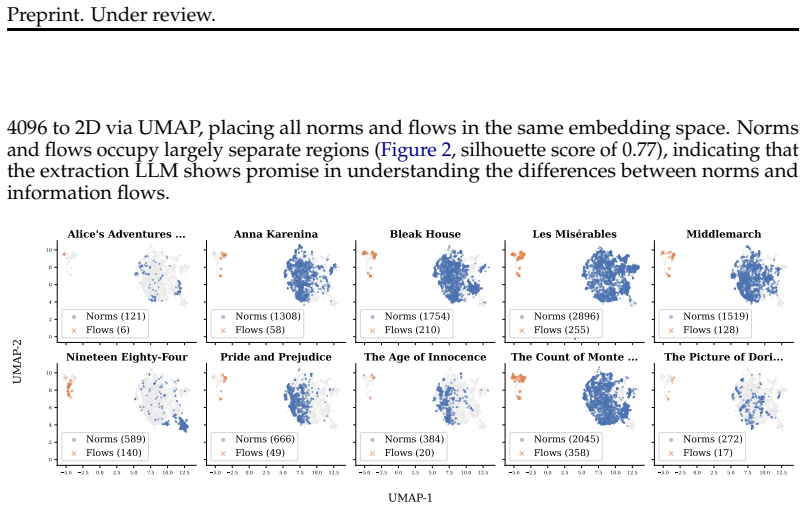
Fiction novels supply privacy norms that, when used to train LLMs with supervised learning plus GRPO, produce judgments aligning with human expectations across real contexts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Extracting normative simulacra from fiction novels and applying them through supervised learning followed by GRPO reinforcement learning with a composite reward function and per-completion contrastive scoring produces LLMs whose privacy reasoning transfers to real-world domains, as evidenced by the highest scores on law compliance benchmarks and the strongest correlation with crowdsourced human privacy expectations across seven models and five CI-aligned benchmarks.
What carries the argument
Normative simulacra extracted from fiction novels, used as grounding for a composite reward in GRPO that combines programmatic signals for clarity, completeness, consistency, and context with an LLM judge checking fidelity to the held-out source universe.
If this is right
- Supervised fine-tuning alone creates a conservative bias toward restricting information flow and improves detection of privacy situations but does not raise the accuracy of the resulting judgments.
- Adding GRPO with normative grounding from fiction produces the strongest results on law compliance and human-alignment metrics.
- Per-completion contrastive scoring against both correct and randomly chosen wrong normative universes reduces overfitting to specific source texts.
- The approach works across multiple base models and distinct societal contexts represented in the evaluation benchmarks.
Where Pith is reading between the lines
- Similar extraction of structured norms from fiction could be tested for other alignment goals such as fairness or safety reasoning.
- If fiction provides broad coverage of social situations, the method might generalize to novel contexts better than training on limited real-world examples alone.
- The contrastive scoring technique could be adapted to other domains where models need to condition outputs on specific rule sets rather than memorize examples.
Load-bearing premise
Normative simulacra drawn from fiction novels contain generalizable privacy rules that will produce accurate judgments when applied to real-world situations outside the original stories.
What would settle it
Run the trained models on a privacy decision task drawn from a societal context absent from the fiction corpus, such as data practices in contemporary social media, and compare the outputs against fresh crowdsourced human expectations; a clear mismatch while ungrounded baselines perform comparably would falsify the transfer claim.
Figures

















read the original abstract
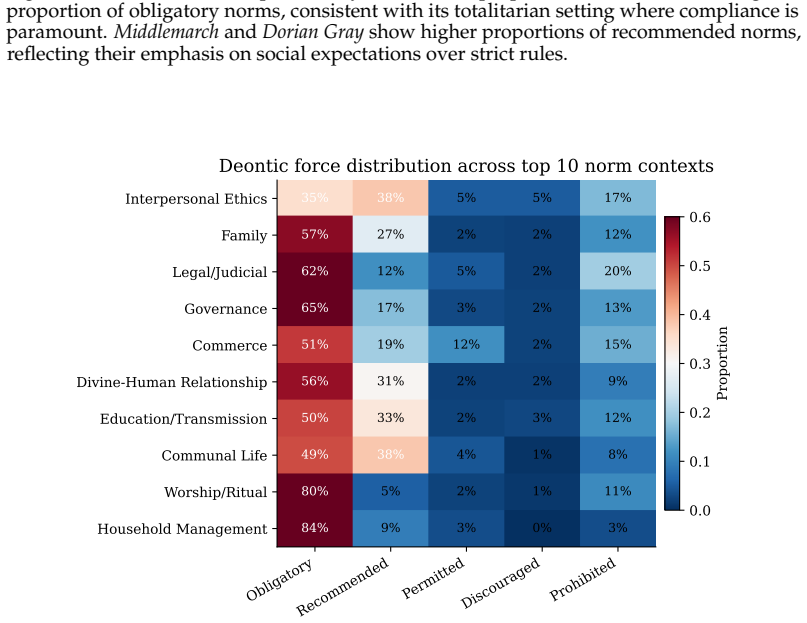
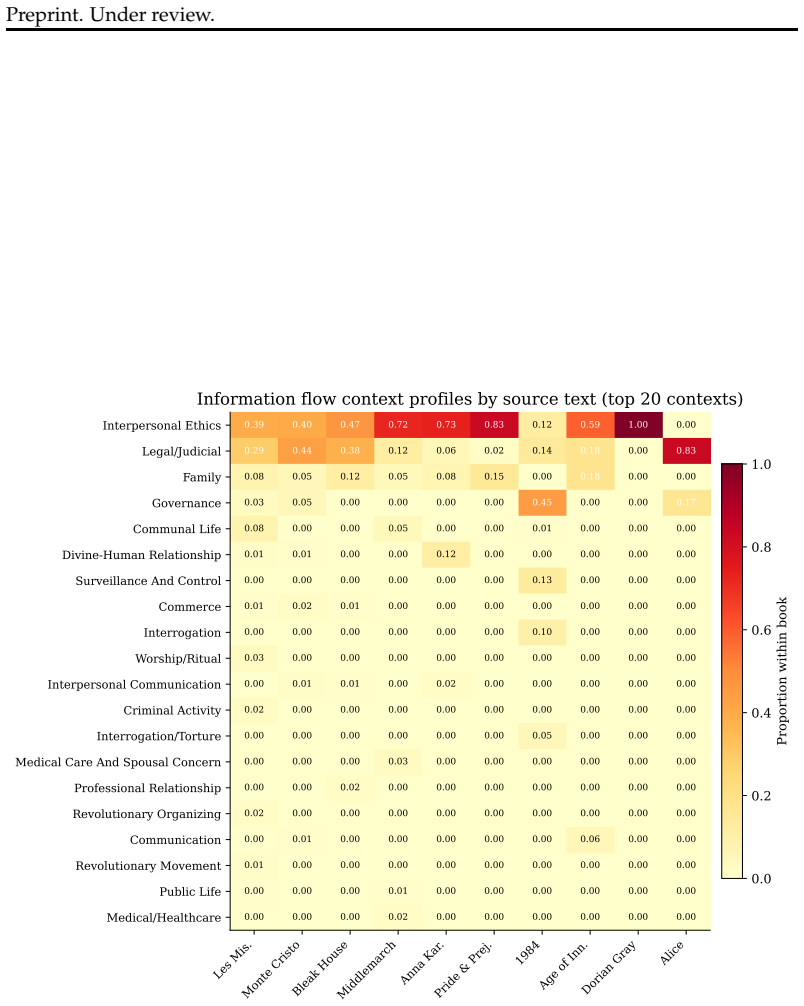
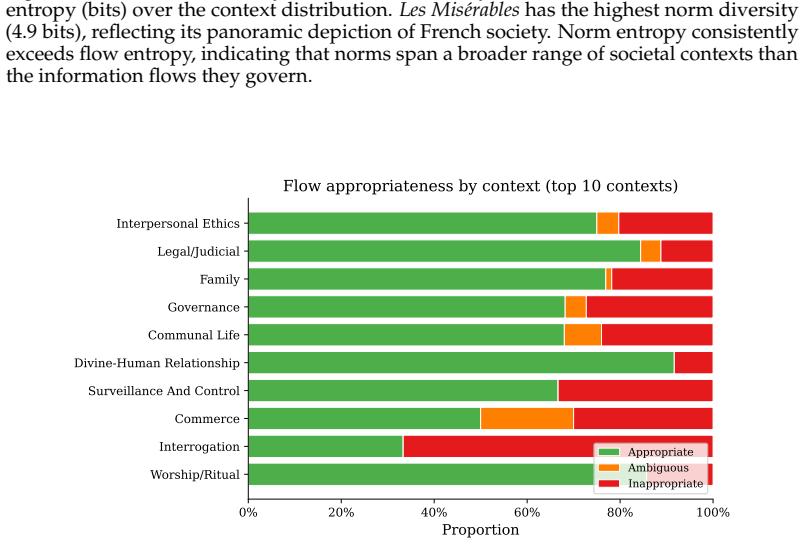
Information handling practices of LLM agents are broadly misaligned with the contextual privacy expectations of their users. Contextual Integrity (CI) provides a principled framework, defining privacy as the appropriate flow of information within context-relative norms. However, existing approaches either double inference cost via supervisor-assistant architectures, or fine-tune on narrow task-specific data. We propose extracting normative simulacra (structured representations of norms and information flows) from fiction novels and using them to fine-tune LLMs via supervised learning followed by GRPO reinforcement learning. Our composite reward function combines programmatic signals, including task clarity (subsuming schema validity, construct discrimination, and extraction confidence), structural completeness, internal consistency, and context identification, with an LLM judge that evaluates whether the model's privacy reasoning is grounded in the held-out normative universe of the source text. To mitigate overfitting, we introduce per-completion contrastive scoring: each completion is evaluated against both the correct normative universe and a randomly selected wrong one, teaching the model to condition on context rather than memorize source-specific norms. We evaluate on five CI-aligned benchmarks spanning distinct societal contexts and ablate the contributions of RL and normative grounding. Across seven models, SFT introduces a conservative prior toward restricting information flow, improving recognition of privacy-relevant situations but not the correctness of privacy judgments. GRPO with normative grounding achieves the highest score on a law compliance benchmark and strongest correlation with crowdsourced human privacy expectations, demonstrating that fiction-derived normative simulacra can teach contextual privacy reasoning that transfers to real-world domains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that normative simulacra extracted from fiction novels can be used to fine-tune LLMs via SFT followed by GRPO reinforcement learning. A composite reward combines programmatic signals (task clarity, structural completeness, internal consistency, context identification) with an LLM judge that grounds reasoning in the held-out source normative universe; per-completion contrastive scoring against randomly selected wrong universes is introduced to promote context conditioning over memorization. Ablations of RL and normative grounding are performed, and the method is evaluated on five CI-aligned benchmarks spanning distinct societal contexts. GRPO with normative grounding is reported to achieve the highest score on a law compliance benchmark and the strongest correlation with crowdsourced human privacy expectations, supporting transfer of contextual privacy reasoning to real-world domains.
Significance. If the transfer results hold after addressing evaluation gaps, the work would demonstrate a scalable route to instill generalizable privacy norms in LLMs without task-specific labeled data or supervisor-assistant architectures. The contrastive scoring mechanism and explicit ablations of RL versus normative grounding are concrete strengths that make the contribution falsifiable and reproducible in principle.
major comments (3)
- [Abstract] Abstract and evaluation description: the reported improvements on the law compliance benchmark and human correlation are presented without statistical tests, confidence intervals, exact train/test splits, or full ablation tables. This makes it impossible to determine whether the gains attributed to GRPO with normative grounding are statistically reliable or merely reflect variance.
- [Method] Method and evaluation sections: the central transfer claim requires that the five CI-aligned benchmarks are distributionally independent of the fiction corpus. No quantitative measure of distributional shift, list of fiction sources, or benchmark construction details are supplied, so it remains possible that gains arise from cultural or legal overlap rather than genuine generalization of normative simulacra.
- [Method] Reward function description: the LLM judge component evaluates grounding in the held-out normative universe, yet the paper does not report any analysis of possible training-data overlap between the judge model and the source fiction. This leaves the contrastive scoring's effectiveness against memorization partially unverified.
minor comments (1)
- [Method] The composite reward weights are listed as free parameters; a brief statement of how they were chosen or whether they were held constant across the seven models would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments, which highlight important aspects of statistical rigor, benchmark independence, and verification of the reward components. We will revise the manuscript to address these points by expanding the evaluation section with additional analyses and details, while preserving the core contributions of the normative simulacra approach and contrastive scoring.
read point-by-point responses
-
Referee: [Abstract] Abstract and evaluation description: the reported improvements on the law compliance benchmark and human correlation are presented without statistical tests, confidence intervals, exact train/test splits, or full ablation tables. This makes it impossible to determine whether the gains attributed to GRPO with normative grounding are statistically reliable or merely reflect variance.
Authors: We agree that statistical tests, confidence intervals, exact splits, and complete ablation tables are necessary to establish the reliability of the reported gains. In the revised manuscript, we will expand the evaluation section to include bootstrap confidence intervals for all key metrics (law compliance and human correlation), paired statistical significance tests (e.g., t-tests or Wilcoxon signed-rank) comparing GRPO with normative grounding against SFT-only and ablated baselines, the precise train/test splits used across the seven models, and full ablation tables with per-model breakdowns. These will be referenced concisely in the abstract. revision: yes
-
Referee: [Method] Method and evaluation sections: the central transfer claim requires that the five CI-aligned benchmarks are distributionally independent of the fiction corpus. No quantitative measure of distributional shift, list of fiction sources, or benchmark construction details are supplied, so it remains possible that gains arise from cultural or legal overlap rather than genuine generalization of normative simulacra.
Authors: We acknowledge that explicit evidence of distributional independence is required to support the transfer claim. The revised paper will add: a complete enumerated list of the fiction sources from which normative simulacra were extracted; a detailed account of benchmark construction (including how the five CI-aligned datasets were selected and annotated to span distinct societal contexts); and quantitative measures of distributional shift, such as average cosine similarity of sentence embeddings between fiction excerpts and benchmark contexts plus n-gram and term-overlap statistics for legal/cultural elements. These additions will allow direct assessment of whether gains reflect genuine generalization. revision: yes
-
Referee: [Method] Reward function description: the LLM judge component evaluates grounding in the held-out normative universe, yet the paper does not report any analysis of possible training-data overlap between the judge model and the source fiction. This leaves the contrastive scoring's effectiveness against memorization partially unverified.
Authors: The contrastive scoring mechanism evaluates each completion against both the correct held-out normative universe and a randomly sampled incorrect one precisely to discourage memorization of source-specific content. We did not include an explicit overlap analysis between the judge model's (proprietary) training data and the fiction corpus, as such data is inaccessible. In the revision we will add a dedicated limitations paragraph acknowledging this constraint and include proxy verification experiments (e.g., testing the judge on fiction excerpts deliberately withheld from any possible overlap). We maintain that the per-completion contrastive design itself provides the primary safeguard against memorization. revision: partial
Circularity Check
No significant circularity; derivation relies on external benchmarks and contrastive training
full rationale
The paper's method extracts normative simulacra from fiction, applies SFT then GRPO with a composite reward (programmatic signals plus LLM judge on held-out source text), and uses per-completion contrastive scoring against wrong normative universes to condition on context. Evaluation occurs on five separate CI-aligned benchmarks with ablations of RL and normative grounding. No quoted equations, self-definitions, or self-citations reduce the transfer claim or benchmark scores to a fitted input or definitional equivalence by construction. The central result is an empirical comparison against held-out data rather than a self-referential loop.
Axiom & Free-Parameter Ledger
free parameters (1)
- composite reward weights
axioms (2)
- domain assumption Fiction novels contain extractable, structured normative representations of information flow that are relevant to real-world privacy contexts.
- domain assumption An LLM judge can reliably evaluate whether generated reasoning is grounded in a held-out normative universe.
invented entities (1)
-
normative simulacra
no independent evidence
Reference graph
Works this paper leans on
-
[1]
URLhttp://arxiv.org/abs/2602.13840. arXiv:2602.13840 [cs] version: 1. Zhao Cheng, Diane Wan, Matthew Abueg, Sahra Ghalebikesabi, Ren Yi, Eugene Bagdasarian, Borja Balle, Stefan Mellem, and Shawn O’Banion. CI-Bench: Benchmarking Contextual Integrity of AI Assistants on Synthetic Data, September 2024. URL http://arxiv.org/ abs/2409.13903. arXiv:2409.13903 [...
-
[2]
URLhttp://arxiv.org/abs/2306.11644. arXiv:2306.11644 [cs]. Daya Guo, Dejian Yang, He Zhang, Junxiao Song, Runxin Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning.arXiv preprint arXiv:2501.12948, 2025. Joseph Henrich, Steven J. Heine, and Ara Norenzayan. ...
-
[3]
No Secrets Between the Two of Us: Privacy Concerns over Using AI Agents
ISSN 1802-7962. doi: 10.5817/CP2022-4-3. URL https://cyberpsychology.eu/ article/view/14023. Gaspard Michel, Elena V . Epure, Romain Hennequin, and Christophe Cerisara. Evaluating LLMs for Quotation Attribution in Literary Texts: A Case Study of LLaMa3, January 2025. URLhttp://arxiv.org/abs/2406.11380. arXiv:2406.11380 [cs] version: 3. Niloofar Mireshghal...
-
[4]
URLhttp://arxiv.org/abs/2208.05545. arXiv:2208.05545 [cs]. Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc V . Le, and Denny Zhou. Chain-of-Thought Prompting Elicits Reason- ing in Large Language Models.Advances in Neural Information Processing Systems, 35: 24824–24837, December 2022. URL https://proceedings.neu...
-
[5]
doi: 10.18653/v1/2023.acl-long.429
Association for Computational Linguistics. doi: 10.18653/v1/2023.acl-long.429. URLhttps://aclanthology.org/2023.acl-long.429/. A Additional Method Details A.1 Model and Infrastructure We use Qwen2.5-72B (dense) Qwen et al. (2025) for norm extraction, served via vLLM across 2 NVIDIA RTX A6000 GPUs with tensor parallelism. We select Qwen2.5 over the newer Q...
-
[6]
Task clarity( Runcert, w=0.10, composite): Consolidates three facets of model un- certainty. First,schema validity(0.6 pts): does the output parse into the target structured schema? Completions that do not produce valid typed output receive the minimum score. Second,norm/flow discrimination(0.2 pts): does the completion include the has information exchang...
-
[7]
Structural completeness( Rcomplete, w=0.05, continuous): What proportion of tuple components are non-null and substantive? A CI flow specifying all five parameters with context-specific values scores higher than one with vague or missing fields
-
[8]
Scored as the proportion of invariant checks passed
Internal consistency( Rconsist, w=0.05, proportional): Do internal invariants hold? E.g., has information exchange: false must pair with an empty flows array; is new flow: true should pair with an inappropriate or ambiguous judgment. Scored as the proportion of invariant checks passed
-
[9]
Context identification( Rcontext, w=0.20, programmatic): Does the model’s stated societal context match the known context(s) of the source text? For each extracted flow, the model’s stated context is embedded and compared against the full set of individual norm-level context labels in ˆNb via maximum cosine similarity; scores are averaged across flows. Th...
-
[10]
Reasoning-to-extraction coherence( Rcohere, w=0.10, continuous): Does the reason- ing trace logically support the structured extraction? Checks that extracted entities (sender, recipient, information type) appear in the reasoning text
-
[11]
Normative grounding( Rground, w=0.50, LLM-judged, per-flow): For each extracted information flow, the k=3 most relevant norms are retrieved from ˆNb via semantic similarity. An LLM judge evaluates three decomposable sub-signals: (a)norm aware- ness, do the model’s invoked norms for this flow semantically match a retrieved 15 Preprint. Under review. norm?;...
work page 2025
-
[12]
**Context/Sphere**: What societal domain does this exchange belong to? Examples include: courtship, family, legal or property relations, commerce, social etiquette, religion, education, governance, military, state or political affairs, workplace, medical settings, surveillance, and other organized social domains
-
[13]
For example, a person may disclose information about themselves
**Actors**: Who is the sender of the information? Who is the recipient? Who is the subject of the information? (These roles may overlap. For example, a person may disclose information about themselves. Actors can be individuals, groups, or institutions.) When possible, identify the specific character or entity occupying each role
-
[14]
**Information Type**: What kind of information is being exchanged? Examples include: personal feelings, financial standing, political beliefs, loyalty or allegiance, misconduct or wrongdoing, social 40 Preprint. Under review. status, personal history, private thoughts, location or movements, and social associations
-
[15]
**Appropriateness** (relative to the fictional society’s expectations): Does the information flow conform to the societal expectations that govern the context in which it occurs? Classify the flow as **appropriate**, **inappropriate**, or **ambiguous**. - "Appropriate": The flow conforms to what participants in that social context expect | even if those n...
-
[16]
**Governing Norms (Societal Expectations)**: What societal expectations govern whether this information flow is appropriate within the fictional context? These norms are the shared understandings|formal or informal| about how information is expected to flow in this context. Norms may be: - Explicit: Clearly stated by characters, codified in laws or instit...
-
[17]
You should provide as many flows as you see in the chunk, focusing on the most significant. 6. For each flow: - Quote the relevant text snippet - Explain what information is being exchanged, by whom, and in what context - Identify the societal context or sphere - Describe the flow direction (who tells what to whom) - Assess appropriateness relative to the...
-
[18]
**Subject**: The actor about whom the information pertains. The subject may be the same as sender (self-disclosure) or a third party (e.g., gossip or reporting about someone else). If the information does not concern a specific person (e.g., general news or public events), use a descriptive label that identifies the topic of the information
-
[19]
This is the active party initiating the flow
**Sender**: The actor who transmits, discloses, or communicates the information. This is the active party initiating the flow
-
[20]
**Recipient**: The actor who receives the information. May be a specific individual, a group (e.g., "the neighborhood"), or "the public."
-
[21]
**Information Type**: The category or nature of the information being exchanged about the subject. Examples include, but are not limited to: - Personal feelings or sentiments - Financial standing or income - Marital intentions or romantic interest - Social reputation or character assessment - Family connections or lineage - Health or physical condition - ...
-
[22]
**Transmission Principle**: The societal expectation or norm that governs HOW the information may flow. This describes the constraint on the flow, not the information itself, but the terms under which the society expects it to be transmitted. These principles arise from the normative societal expectations of the fictional world within the context of the f...
-
[23]
certain" pairs with 7{8, not 3). Do NOT include
0 = no basis in the text; 10 = all components explicitly and unambiguously supported. Must be congruent with the qualitative rating (e.g., "certain" pairs with 7{8, not 3). Do NOT include "source snippet" or "reasoning trace" fields in the output | these are tracked separately. ### Extraction Guidance: - Extract ALL components where possible. If a compone...
-
[24]
**Prescriptive element ("ought")**: The deontic force | must, must not, is expected to, ought to, should, may, is forbidden to, etc. 2. **Norm subject**: The role or class of persons upon whom the obligation falls | expressed as a social role, not a named character. "A gentleman’s daughter," "an unmarried woman of marriageable age," "a man of good standin...
-
[25]
**Subject test**: Could you replace the character with a *different* person of the same social role and the norm would still hold? If the norm only makes sense for one specific character, it is a character description, not a norm. 2. **Act test**: Is the prescribed action something that could recur across multiple situations, or does it describe a one-tim...
-
[26]
Identify norms even when implicit | reconstruct the underlying social expectation from narrative evidence (behavior, consequences, narrator commentary, characters’ reflections, institutional practices) 2. Set ‘has prescriptive content: true‘ if the text reveals any operative social norm through any of the five categories of narrative evidence described ab...
-
[27]
**Prescriptive element ("ought")**: The deontic force of the norm | the sense in which the action is prescribed, prohibited, or permitted. In fiction, this is usually implicit | reconstructed from 51 Preprint. Under review. social consequences, narrator commentary, or characters’ reflections. Express it as the society’s expectation: "is expected to," "mus...
-
[28]
**Norm subject**: The role or class of persons **upon whom the obligation expressed in the norm falls**. In fiction, this must be a social role, not a named character: "a gentleman’s daughter," "an unmarried woman of marriageable age," "a man of good standing," "a servant," "a guest," "a widow," "a member of the gentry." The norm subject is the person who...
-
[29]
receive a proposal with courtesy and serious consideration,
**Norm act**: The specific **action** prescribed or proscribed by the norm. State this as a verb phrase describing what the norm subject is required to do or refrain from doing: "receive a proposal with courtesy and serious consideration," "call on a new neighbor within days of their arrival," "obtain parental consent before entering a courtship," "refrai...
-
[30]
when addressed by a suitor of respectable standing,
**Condition of application**: The **circumstances** under which the norm applies to the norm subject. May be: - Relational: "when addressed by a suitor of respectable standing," "toward one’s social superior" - Institutional: "at a ball or assembly," "during a formal introduction" - Temporal: "during the mourning period," "upon first acquaintance" - Situa...
-
[31]
**Social position**: The structural place the person occupies (gentleman, mother, servant, guest, clergyman, widow, heir). This is the basic category
-
[32]
**Relational context**: The relationships and social milieu that activate the norm. A "mother" is too vague | a "mother of unmarried 55 Preprint. Under review. daughters in a society where marriage is the primary means of securing a woman’s future" captures why the matchmaking norm applies to her
-
[33]
**Functional capacity**: The ends, duties, or purposes that flow from the position. A "wealthy gentleman" is demographic; a "wealthy gentleman whose social standing obliges him to participate in and host social gatherings for the local gentry" captures the functional expectation. ### Role Abstraction Heuristic For each character name in a norm, apply thes...
-
[34]
NORM AWARENESS: The model’s extraction includes a "norms invoked" field listing the norms it believes apply to this flow. Do any of those invoked norms semantically match the provided norms from the universe? Semantic equivalence is sufficient | exact wording match is not required. Score from 0.0 (no match at all) to 1.0 (strong semantic match)
-
[35]
FLOW GOVERNANCE: Independently of what norms the model invoked, is this information flow actually governed by any of the provided norms? "Governed" means the norm regulates, constrains, or establishes expectations about information flows of this type | between these kinds of actors, about this kind of information, in this context. Score from 0.0 (flow is ...
-
[36]
**Norm awareness** (norm match score): Do the flow’s norms invoked match any of the retrieved norms? Score 0.0{1.0
-
[37]
**Flow governance** (governance score): Is this flow governed by any of the retrieved norms, regardless of what the model invoked? Score 0.0{1.0
-
[38]
**Appropriateness consistency**: Is the flow’s appropriateness judgment consistent with the governing norm? Provide your evaluation as a JSON object. 60 Preprint. Under review. E.8 GRPO No-Flow Judge Coverage judge for no-flow predictions in GRPO reward. System Prompt: You are an expert in Helen Nissenbaum’s Contextual Integrity framework. You assess whet...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.