Deep FinResearch Bench: Evaluating AI's Ability to Conduct Professional Financial Investment Research
Pith reviewed 2026-05-09 23:56 UTC · model grok-4.3
The pith
A new benchmark shows AI-generated financial investment reports still fall short of professional standards in rigor, accuracy, and verifiability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Deep FinResearch Bench defines evaluation metrics for qualitative rigor, quantitative forecasting accuracy, and claim verifiability, then applies an automated scorer to show that frontier AI agents produce financial research reports that remain inferior to those authored by human professionals in each of the three measured dimensions.
What carries the argument
Deep FinResearch Bench, an evaluation framework consisting of qualitative and quantitative metrics plus automated scoring applied to AI and human financial reports.
If this is right
- Domain-specialized training or tool integration for finance will be required before AI agents can match professional output quality.
- Standardized benchmarks like this one can serve as objective targets for iterative improvement of deep research agents.
- Financial firms may continue to rely primarily on human analysts for report generation until AI performance closes the measured gaps.
- The three-dimensional structure provides concrete directions for targeted capability upgrades in qualitative analysis, numerical forecasting, and evidence grounding.
Where Pith is reading between the lines
- The benchmark could be adapted to test AI performance in adjacent professional domains such as legal due diligence or medical literature synthesis.
- Integrating live market data feeds or regulatory databases into the agent pipeline might directly address shortfalls in quantitative accuracy.
- Human professionals could use the same scoring system to audit their own reports or to identify routine tasks suitable for AI assistance.
- Repeated application of the benchmark over time would track whether general-purpose model scaling alone closes the gap or whether finance-specific architectures are needed.
Load-bearing premise
The chosen metrics and automated scoring procedure accurately reflect the full set of qualities that define professional financial research quality without systematic bias or omission.
What would settle it
A new AI agent whose generated reports receive equal or higher scores than professional human reports across all three benchmark dimensions when evaluated by the same automated procedure would falsify the claim that current agents fall short.
Figures



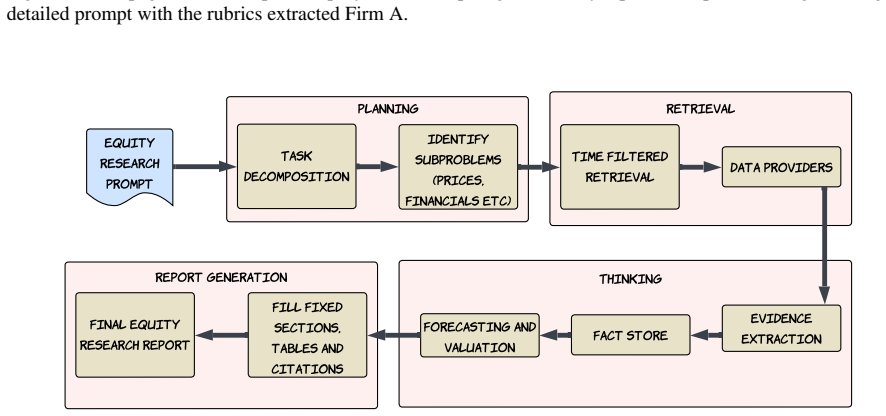





read the original abstract
We introduce Deep FinResearch Bench, a practical and comprehensive evaluation framework for deep research (DR) agents in financial investment research. The benchmark assesses three dimensions of report quality: qualitative rigor, quantitative forecasting and valuation accuracy, and claim credibility and verifiability. Particularly, we define corresponding qualitative and quantitative evaluation metrics and implement an automated scoring procedure to enable scalable assessment. Applying the benchmark to financial reports from frontier DR agents and comparing them with reports authored by financial professionals, we find that AI-generated reports still fall short across these dimensions. These findings underscore the need for domain-specialized DR agents tailored to finance, and we hope the work establishes a foundation for standardized benchmarking of DR agents in financial research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Deep FinResearch Bench, a practical evaluation framework for deep research (DR) agents performing financial investment research. It defines three core dimensions of report quality—qualitative rigor, quantitative forecasting and valuation accuracy, and claim credibility/verifiability—along with corresponding metrics and an automated scoring procedure for scalable assessment. The authors apply the benchmark to reports generated by frontier DR agents and compare them against reports authored by financial professionals, concluding that AI-generated reports fall short across all dimensions and underscoring the need for domain-specialized agents.
Significance. If the automated scoring and metrics prove reliable, the benchmark could serve as a useful standardized tool for tracking progress in AI-driven financial research, providing concrete evidence of current gaps relative to human professionals and motivating targeted improvements in agent design. The work's emphasis on practical, multi-dimensional evaluation in a high-stakes domain like finance adds value beyond generic LLM benchmarks, though its impact hinges on addressing validation gaps.
major comments (2)
- [Automated scoring procedure and evaluation methodology] The central finding that AI reports fall short depends on the automated scoring procedure faithfully capturing professional financial research quality. The manuscript defines the metrics and procedure but provides no calibration against human expert judgment (e.g., no inter-rater reliability with blinded professional raters, no ablation on potential biases such as formulaic AI structure or hallucinated sources, and no validation that the automation weights dimensions as professionals would). This is load-bearing for the comparison claim.
- [Benchmark application and results] Insufficient detail is given on data selection, ground-truth construction for quantitative accuracy (e.g., how forecasts are validated against actual outcomes), and error analysis. Without these, it is difficult to determine whether the reported performance gap is robust or sensitive to choices in report sampling and metric implementation.
minor comments (1)
- The abstract and high-level description would benefit from a concise table summarizing the exact metrics per dimension and the automated scoring rules to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the strengths and limitations of our evaluation framework. We address each major point below, indicating planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Automated scoring procedure and evaluation methodology] The central finding that AI reports fall short depends on the automated scoring procedure faithfully capturing professional financial research quality. The manuscript defines the metrics and procedure but provides no calibration against human expert judgment (e.g., no inter-rater reliability with blinded professional raters, no ablation on potential biases such as formulaic AI structure or hallucinated sources, and no validation that the automation weights dimensions as professionals would). This is load-bearing for the comparison claim.
Authors: We agree that external validation of the automated scoring is important for the reliability of the central claims. The three dimensions and associated metrics were derived from standard practices in professional investment research and informal consultations with domain experts. However, a full-scale inter-rater reliability study with blinded professionals was not performed in this work. In the revision we will expand the methodology section to (1) document the expert input used to set dimension weights, (2) include a sensitivity analysis that varies the weights and examines impact on the AI-versus-human gap, and (3) explicitly discuss potential automation biases such as over-penalizing formulaic structure or unverifiable citations. We will also add this validation gap as a stated limitation and a priority for follow-up research. revision: partial
-
Referee: [Benchmark application and results] Insufficient detail is given on data selection, ground-truth construction for quantitative accuracy (e.g., how forecasts are validated against actual outcomes), and error analysis. Without these, it is difficult to determine whether the reported performance gap is robust or sensitive to choices in report sampling and metric implementation.
Authors: We will substantially expand the experimental section. The revision will specify the exact criteria used to select the 20 companies and corresponding reports (market-cap range, sector balance, report date window), the public data sources employed for ground-truth construction (earnings releases, analyst consensus, and price data from standard financial databases), and the precise temporal alignment between forecast horizons and realized outcomes. We will also add a dedicated error-analysis subsection that breaks down the most frequent failure modes observed in the AI reports (e.g., unsupported valuation multiples, omitted risk factors) and quantifies their contribution to the aggregate scores. These additions should allow readers to evaluate the robustness of the reported performance differences. revision: yes
Circularity Check
No circularity: benchmark definition and application are independent
full rationale
The paper introduces Deep FinResearch Bench by defining three quality dimensions (qualitative rigor, quantitative forecasting/valuation accuracy, claim credibility), corresponding metrics, and an automated scoring procedure, then applies the benchmark to compare frontier DR agent reports against professional financial reports. No equations, derivations, fitted parameters, or predictions appear. No self-citations are invoked as load-bearing premises, and the central claim (AI reports fall short) follows directly from applying the externally defined procedure rather than reducing to a self-referential fit or renamed input. The evaluation framework is presented as a self-contained tool without any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Tianyu Zhou, Pinqiao Wang, Yilin Wu, and Hongyang Yang
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information pro- cessing systems, 36:46595–46623. Tianyu Zhou, Pinqiao Wang, Yilin Wu, and Hongyang Yang. 2024. Finrobot: Ai agent for equity research and valuation with large language models.arXiv preprint arXiv:2411.08804. Fengbin Zhu, Xiang Yao Ng, Ziyang Liu, Chang Liu, Xianwei ...
-
[2]
A Appendix A.1 Limitations Deep research agents are advancing at a fast pace
Findeepresearch: Evaluating deep research agents in rigorous financial analysis.arXiv preprint arXiv:2510.13936. A Appendix A.1 Limitations Deep research agents are advancing at a fast pace. This study mainly explored the commercial deep research agents, which is more likely adopted in business uses of big corporations, for financial in- vestment research...
-
[3]
7.There are also deep research benchmarks including Deep Research Bench (Du et al., 2025) and FinDeepResearch (Zhu et al., 2025) indicating salient performance boost over the method of using base LLMs with web search only. Table 8 below summarizes the performance comparisons between LLMs with web search and deep research agents on DeepResearch Bench and F...
work page 2025
-
[4]
service growth will be high single-digit
This is a obvious contradiction. DR REPORT “The valuation reflects revenue compound annual growth rates of 8-10%over the next five years. Oper- ating margins are projected tostabilize 32-34%... | Year | Op Margin % | |2025E | 33.5 | ... |2028E |35.1| |2029E |35.3| ” We can barely detect coherence issue in profes- sional reports thought. A reasonable guess...
work page 2025
-
[5]
Synopsys’s ac- quisition of Ansys at $35B
https://www.gov.uk/cma-cases/investigation-into- amazons-marketplace Evidence from Citation: ... Case Timetable: Date Action 3 November CMA commitments decision published and investigation closed In other example, the claim of "Synopsys’s ac- quisition of Ansys at $35B" itself is true based on other sources. However, its citing source cannot be found. We ...
-
[6]
Amazon had approximately 10.6 billion shares outstanding
https://www.prnewswire.com/synopsys-ansys- acquisition Evidence from citation: ... 404 not found In another example, the claim of "Amazon had approximately 10.6 billion shares outstanding" is supported by additional evidence, but not supported by provided citation. DR REPORT Claim: “Amazon had approximately 10.6 billion shares outstanding [1]”
-
[7]
In fiscal Q1 2025, Apple’s Services net sales were $26.34 billion
https://futurumgroup.com/insights/amazon-q1-fy- 2025-earnings Evidence from citation: ... No mention of outstanding shares in the citations. Overall, the aforementioned issues of verifiabil- ity and credibility of the claims and their sources may bring serious doubts from professionals to use AI generated reports in their research tasks. Credibility. In t...
-
[8]
If most expected sections absent/opaque⇒Poor
-
[9]
If≥2 contradictions/uncited claims/major KPI omissions⇒cap at Fair
-
[10]
If valuation lacks explicit linkage from drivers to value⇒cap at Fair
-
[11]
If peer/industry/regulatory context absent⇒downgrade one level
-
[12]
If all sections, KPIs, evidence, and linkages present but no sensitivities⇒Good
-
[13]
If comprehensive + scenario/sensitivity analysis + peer benchmarking⇒Excellent. </instruction> <output_format> Required Output (JSON only; follow the schema exactly) { "grade": "Poor | Fair | Good | Excellent", "summary_reasoning": "<150-250 words covering: coverage of key sections, proportionality, evidence integration, scope vs redundancy, and gaps & im...
-
[14]
Apply the Rubric & Guardrails (below) and determine the final grade
-
[15]
Write Reasoning (180-260 words): Explain the key drivers of your grade with direct references to sections/lines where possible
-
[16]
Because X in Q1, therefore Y in margins
Select 2-3 Evidence Bullets: Quote or concisely paraphrase the most decisive strengths/weaknesses with a section/page cue if available. Grading Scale (choose exactly one) poorFrequent abrupt jumps; list-like paragraphs; key terms undefined or inconsistently used. Multiple unresolved contradictions (narrative↔tables/assumptions) or time-inaccurate “recency...
-
[17]
If assumptions are mostly unstated/opaque⇒Poor
-
[18]
Else, count contradictions (text vs table; claim vs clearly implied historical fact in the report). 3.≥2 contradictions⇒Poor
-
[19]
1 contradiction⇒cap at Fair (unless fully reconciled in text)
-
[20]
Check sensitivities/scenarios on material drivers
-
[21]
None/qualitative only⇒cap at Fair
-
[22]
Check justification (history, peers, sources) and specificity (units/horizons/drivers)
-
[23]
Solid with some quantified sensitivities⇒Good
-
[24]
Comprehensive + robust sensitivities on all material levers⇒Excellent. </instruction> <output_format> Required Output (JSON only; follow the schema exactly) { "grade": "Poor | Fair | Good | Excellent", "summary_reasoning": "<150-250 words focusing on the five pillars: explicitness, justification, specificity, consistency, sensitivity. No fluff .>", "assum...
-
[25]
If no mechanisms/assumptions – Poor
-
[26]
If mechanisms/assumptions exist but no benchmarks/sensitivity – Fair
-
[27]
If mechanisms and assumptions are benchmarked but no scenario analysis – Good
-
[28]
If all of the above + scenario/sensitivity analysis and decision-relevant implications – Excellent. </instruction> <output_format> Required Output (JSON only; follow the schema exactly) { "grade": "Poor | Fair | Good | Excellent", "summary_reasoning": "lt 150 to 250 words covering causal explanation, inference quality, data use, counterpoints/uncertainty,...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.