Recognition: unknown
Micro-DualNet: Dual-Path Spatio-Temporal Network for Micro-Action Recognition
Pith reviewed 2026-05-10 00:06 UTC · model grok-4.3
The pith
A dual-path network with parallel spatial-then-temporal and temporal-then-spatial routes plus adaptive per-body-part routing improves recognition of subtle micro-actions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
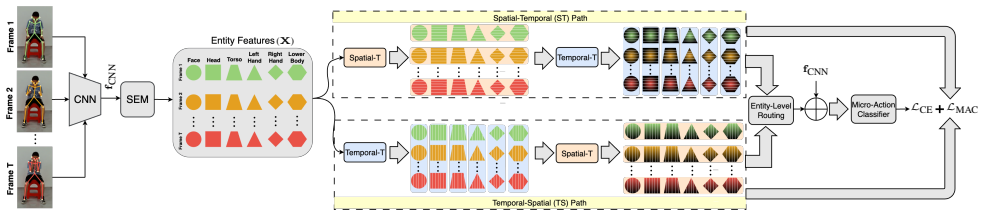
Micro-actions display diverse spatio-temporal characteristics that no single decomposition order can capture, so a dual-path network running an ST pathway and a TS pathway in parallel, combined with entity-level adaptive routing that lets each body part select its preferred order and a Mutual Action Consistency loss that enforces cross-path agreement, accommodates this diversity and delivers competitive results on MA-52 together with state-of-the-art performance on iMiGUE.
What carries the argument
Dual parallel ST and TS pathways that process anatomically-grounded spatial entities, with entity-level adaptive routing deciding the processing order per body part and Mutual Action Consistency loss maintaining coherence.
If this is right
- Each body part can be assigned an optimal processing order rather than a uniform fusion strategy.
- Cross-path consistency enforcement improves recognition when spatial and temporal cues conflict.
- Performance gains appear on datasets that emphasize subtle localized movements.
- The architecture scales to multiple entity types without requiring hand-designed fusion weights.
Where Pith is reading between the lines
- The same dual-order idea could be tested on other short-duration fine-grained video tasks such as micro-gestures or facial micro-expressions.
- If routing preferences prove stable across datasets, the method might reduce the need for dataset-specific hyperparameter tuning of temporal modeling.
- Extending the routing to operate at the pixel level rather than body-part level could reveal whether the benefit is truly entity-driven.
Load-bearing premise
Micro-actions inherently require more than one fixed spatio-temporal decomposition order and entity-level routing can stably learn the right preference for each body part.
What would settle it
A single-path network matching or exceeding the dual-path accuracy on the iMiGUE dataset would show that the diversity claim and the need for dual routes do not hold.
Figures

read the original abstract
Micro-actions are subtle, localized movements lasting 1-3 seconds such as scratching one's head or tapping fingers. Such subtle actions are essential for social communication, ubiquitously used in natural interactions, and thus critical for fine-grained video understanding, yet remain poorly understood by current computer vision systems. We identify a fundamental challenge: micro-actions exhibit diverse spatio-temporal characteristics where some are defined by spatial configurations while others manifest through temporal dynamics. Existing methods that commit to a single spatio-temporal decomposition cannot accommodate this diversity. We propose a dual-path network that processes anatomically-grounded spatial entities through parallel Spatial-Temporal (ST) and Temporal-Spatial (TS) pathways. The ST path captures spatial configurations before modeling temporal dynamics, while the TS path inverts this order to prioritize temporal dynamics. Rather than fixed fusion, we introduce entity-level adaptive routing where each body part learns its optimal processing preference, complemented by Mutual Action Consistency (MAC) loss that enforces cross-path coherence. Extensive experiments demonstrate competitive performance on MA-52 dataset and state-of-the-art results on iMiGUE dataset. Our work reveals that architectural adaptation to the inherent complexity of micro-actions is essential for advancing fine-grained video understanding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Micro-DualNet, a dual-path spatio-temporal network for micro-action recognition. It processes anatomically-grounded spatial entities via parallel Spatial-Temporal (ST) and Temporal-Spatial (TS) pathways, introduces entity-level adaptive routing to learn per-body-part processing preferences, and employs a Mutual Action Consistency (MAC) loss to enforce cross-path coherence. The work claims that this architecture accommodates the diverse spatio-temporal characteristics of micro-actions (lasting 1-3 seconds) better than single-decomposition methods, reporting competitive performance on the MA-52 dataset and state-of-the-art results on the iMiGUE dataset.
Significance. If the performance claims and necessity of the dual adaptive design are substantiated, the paper would offer a targeted architectural solution to a recognized gap in fine-grained video understanding, particularly for subtle actions relevant to social interaction analysis. The entity-level routing and MAC loss represent a concrete mechanism for handling action diversity without fixed fusion, which could influence subsequent work on adaptive spatio-temporal models if supported by rigorous controls.
major comments (2)
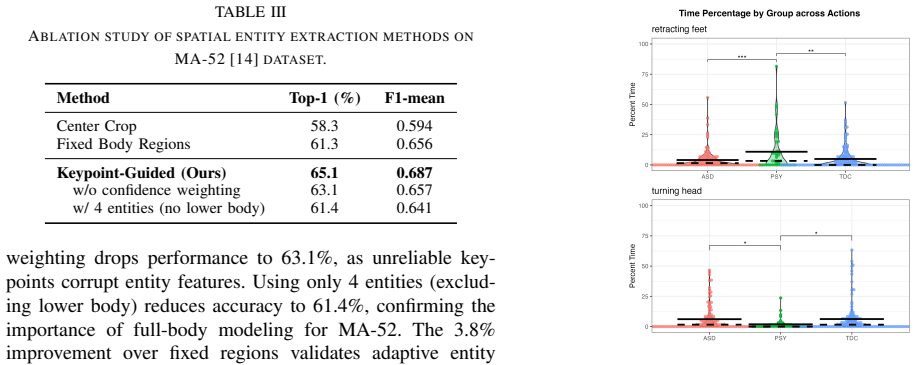
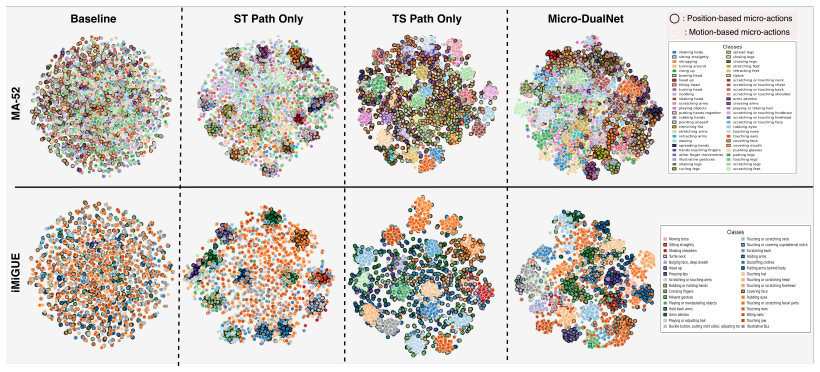
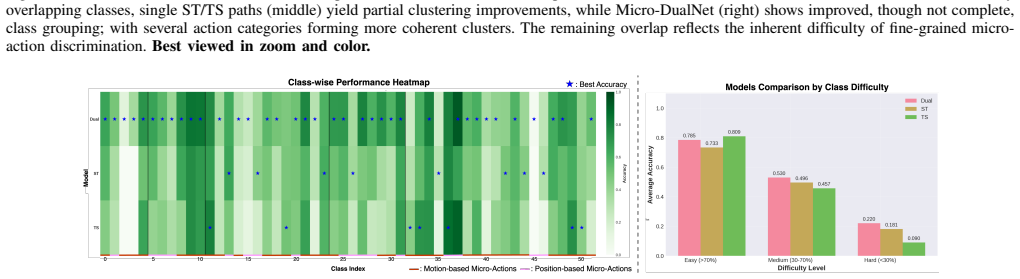
- [Abstract and Introduction] The abstract and introduction assert that micro-actions exhibit diverse spatio-temporal characteristics unaccommodated by any single decomposition and that entity-level adaptive routing learns stable preferences, yet no ablation results are referenced comparing the full dual-path model against single ST-path, single TS-path, or fixed equal-weight fusion baselines. This comparison is load-bearing for the central claim that the dual construction is required.
- [Abstract] The experimental claims of competitive results on MA-52 and SOTA on iMiGUE are stated without any reported quantitative metrics (accuracy, F1, etc.), dataset statistics, baseline comparisons, ablation tables, or error bars in the provided text, rendering the performance assertions unevaluable and the soundness of the empirical validation low.
minor comments (1)
- [Abstract] The definition of micro-actions as 'lasting 1-3 seconds' would benefit from a citation to prior literature establishing this temporal scale to ground the problem statement.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas where the manuscript can more clearly substantiate its central claims. We address each major comment below and will revise the manuscript accordingly to improve clarity and empirical grounding.
read point-by-point responses
-
Referee: [Abstract and Introduction] The abstract and introduction assert that micro-actions exhibit diverse spatio-temporal characteristics unaccommodated by any single decomposition and that entity-level adaptive routing learns stable preferences, yet no ablation results are referenced comparing the full dual-path model against single ST-path, single TS-path, or fixed equal-weight fusion baselines. This comparison is load-bearing for the central claim that the dual construction is required.
Authors: We agree that explicit cross-references to these comparisons are needed in the abstract and introduction to support the core architectural claim. The full manuscript includes ablation studies in the experiments section that directly compare the complete dual-path model (with entity-level adaptive routing and MAC loss) against single ST-path, single TS-path, and fixed equal-weight fusion baselines, demonstrating consistent gains from the adaptive dual design. We will revise the introduction to reference these results explicitly (e.g., citing the relevant tables and summarizing the performance deltas) and add a concise mention of the key ablation outcomes to the abstract. revision: yes
-
Referee: [Abstract] The experimental claims of competitive results on MA-52 and SOTA on iMiGUE are stated without any reported quantitative metrics (accuracy, F1, etc.), dataset statistics, baseline comparisons, ablation tables, or error bars in the provided text, rendering the performance assertions unevaluable and the soundness of the empirical validation low.
Authors: We concur that the abstract would be strengthened by including specific quantitative metrics. The manuscript reports detailed results in the experiments section, including accuracy and F1 scores on MA-52 and iMiGUE, dataset statistics, comparisons to multiple baselines, ablation tables, and error bars (standard deviations across runs). We will revise the abstract to incorporate the key numerical results and notable improvements while maintaining conciseness. revision: yes
Circularity Check
No circularity; empirical architecture proposal without derivations
full rationale
The manuscript is an empirical proposal of a dual-path network (ST/TS pathways, entity-level adaptive routing, MAC loss) for micro-action recognition. No equations, derivations, or mathematical steps appear in the abstract or described content. Central claims rest on reported performance on MA-52 and iMiGUE datasets rather than any self-referential fitting, self-definition, or load-bearing self-citation chains. No reduction of a 'prediction' or 'result' to its own inputs by construction is present, satisfying the default expectation for non-circular empirical work.
Axiom & Free-Parameter Ledger
free parameters (2)
- per-entity routing weights
- MAC loss weighting factor
axioms (1)
- domain assumption Micro-actions exhibit diverse spatio-temporal characteristics where some are defined by spatial configurations while others manifest through temporal dynamics.
Reference graph
Works this paper leans on
-
[1]
Bertasius, H
G. Bertasius, H. Wang, and L. Torresani. Is space-time attention all you need for video understanding? InIcml, volume 2, page 4, 2021
2021
-
[2]
Z. Cao, G. Hidalgo, T. Simon, S.-E. Wei, and Y . Sheikh. Openpose: Realtime multi-person 2d pose estimation using part affinity fields. IEEE Transactions on Pattern Analysis and Machine Intelligence, 43(1):172–186, 2019
2019
-
[3]
Carreira and A
J. Carreira and A. Zisserman. Quo vadis, action recognition? a new model and the kinetics dataset. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6299–6308, 2017
2017
-
[4]
H. Chen, H. Shi, X. Liu, X. Li, and G. Zhao. Smg: A micro-gesture dataset towards spontaneous body gestures for emotional stress state analysis.International Journal of Computer Vision, 131(6):1346– 1366, 2023
2023
-
[5]
Y . Chen, Z. Zhang, C. Yuan, B. Li, Y . Deng, and W. Hu. Channel- wise topology refinement graph convolution for skeleton-based action recognition. InProceedings of the IEEE/CVF International Confer- ence on Computer Vision, pages 13359–13368, 2021
2021
-
[6]
Cheng, Y
K. Cheng, Y . Zhang, X. He, W. Chen, J. Cheng, and H. Lu. Skeleton- based action recognition with shift graph convolutional network. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 183–192, 2020
2020
-
[7]
H. Duan, Y . Zhao, K. Chen, D. Lin, and B. Dai. Revisiting skeleton- based action recognition. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2969–2978, 2022
2022
-
[8]
Feichtenhofer, H
C. Feichtenhofer, H. Fan, J. Malik, and K. He. Slowfast networks for video recognition. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 6202–6211, 2019
2019
-
[9]
Goldman and P
S. Goldman and P. E. Greene. Stereotypies in autism: a video demonstration of their clinical variability.Frontiers in integrative neuroscience, 6:121, 2013
2013
-
[10]
F. Gong, J. Chen, J. Zhu, Q. Bao, F. Gao, R. Gu, and G. Xu. Micro- action recognition via hierarchical fusion and inference. InProceed- ings of the 32nd ACM International Conference on Multimedia, MM ’24, page 11327–11332, New York, NY , USA, 2024. Association for Computing Machinery
2024
-
[11]
Grzadzinski, T
R. Grzadzinski, T. Carr, C. Colombi, K. McGuire, S. Dufek, A. Pick- les, and C. Lord. Measuring changes in social communication behaviors: Preliminary development of the brief observation of social communication change (boscc).Journal of autism and developmental disorders, 46(7):2464–2479, 2016
2016
-
[12]
J. Gu, K. Li, F. Wang, Y . Wei, Z. Wu, H. Fan, and M. Wang. Motion matters: Motion-guided modulation network for skeleton-based micro- action recognition. InProceedings of the 33rd ACM International Conference on Multimedia, 2025
2025
- [13]
-
[14]
D. Guo, K. Li, B. Hu, Y . Zhang, and M. Wang. Benchmarking micro- action recognition: Dataset, methods, and applications.IEEE Transac- tions on Circuits and Systems for Video Technology, 34(7):6238–6252, 2024
2024
-
[15]
K. He, G. Gkioxari, P. Doll ´ar, and R. Girshick. Mask r-cnn. In Proceedings of the IEEE international conference on computer vision, pages 2961–2969, 2017
2017
-
[16]
Gaussian Error Linear Units (GELUs)
D. Hendrycks and K. Gimpel. Gaussian error linear units (gelus). arXiv preprint arXiv:1606.08415, 2016
work page Pith review arXiv 2016
-
[17]
W. Kay, J. Carreira, K. Simonyan, B. Zhang, C. Hillier, S. Vijaya- narasimhan, F. Viola, T. Green, T. Back, P. Natsev, et al. The kinetics human action video dataset.arXiv preprint arXiv:1705.06950, 2017
work page internal anchor Pith review arXiv 2017
-
[18]
Kuehne, H
H. Kuehne, H. Jhuang, E. Garrote, T. Poggio, and T. Serre. Hmdb: a large video database for human motion recognition. In2011 International conference on computer vision, pages 2556–2563. IEEE, 2011
2011
-
[19]
S. R. Leekam, M. R. Prior, and M. Uljarevic. Restricted and repetitive behaviors in autism spectrum disorders: a review of research in the last decade.Psychological bulletin, 137(4):562, 2011
2011
-
[20]
K. Li, D. Guo, G. Chen, C. Fan, J. Xu, Z. Wu, H. Fan, and M. Wang. Prototypical calibrating ambiguous samples for micro-action recognition. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 4815–4823, 2025
2025
- [21]
-
[22]
K. Li, Y . Wang, G. Peng, G. Song, Y . Liu, H. Li, and Y . Qiao. Uniformer: Unified transformer for efficient spatial-temporal repre- sentation learning. InInternational Conference on Learning Repre- sentations, 2022
2022
-
[23]
Q. Li, X. Huang, H. Chen, F. He, Q. Chen, and Z. Wang. Advancing micro-action recognition with multi-auxiliary heads and hybrid loss optimization. InProceedings of the 32nd ACM International Con- ference on Multimedia, MM ’24, page 11313–11319, New York, NY , USA, 2024. Association for Computing Machinery
2024
-
[24]
J. Lin, C. Gan, and S. Han. Tsm: Temporal shift module for efficient video understanding. InProceedings of the IEEE/CVF international conference on computer vision, pages 7083–7093, 2019
2019
- [25]
-
[26]
X. Liu, H. Shi, H. Chen, Z. Yu, X. Li, and G. Zhao. imigue: An identity-free video dataset for micro-gesture understanding and emotion analysis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10631–10642, 2021
2021
-
[27]
Y . Liu, L. Wang, Y . Wang, X. Ma, and Y . Qiao. Fineaction: A fine-grained video dataset for temporal action localization.IEEE transactions on image processing, 31:6937–6950, 2022
2022
-
[28]
Z. Liu, J. Ning, Y . Cao, Y . Wei, Z. Zhang, S. Lin, and H. Hu. Video swin transformer. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3202–3211, 2022
2022
-
[29]
H. Luo, G. Lin, Y . Yao, Z. Tang, Q. Wu, and X. Hua. Dense semantics- assisted networks for video action recognition.IEEE Transactions on Circuits and Systems for Video Technology, 32(5):3073–3084, 2021
2021
-
[30]
Ma, M.-H
C.-Y . Ma, M.-H. Chen, Z. Kira, and G. AlRegib. Ts-lstm and temporal- inception: Exploiting spatiotemporal dynamics for activity recognition. Signal Processing: Image Communication, 71:76–87, 2019
2019
-
[31]
C. C. Nuckols and C. C. Nuckols. The diagnostic and statistical manual of mental disorders,(dsm-5).Philadelphia: American Psychiatric Association, 2013
2013
-
[32]
S. Ruder. An overview of gradient descent optimization algorithms. arXiv preprint arXiv:1609.04747, 2016
work page Pith review arXiv 2016
-
[33]
H. Shao, S. Qian, and Y . Liu. Temporal interlacing network. InPro- ceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 11966–11973, 2020
2020
-
[34]
L. Shi, Y . Zhang, J. Cheng, and H. Lu. Two-stream adaptive graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12026–12035, 2019
2019
-
[35]
L. Shi, Y . Zhang, J. Cheng, and H. Lu. Skeleton-based action recognition with multi-stream adaptive graph convolutional networks. IEEE Transactions on Image Processing, 29:9532–9545, 2020
2020
-
[36]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
K. Soomro, A. R. Zamir, and M. Shah. Ucf101: A dataset of 101 human actions classes from videos in the wild.arXiv preprint arXiv:1212.0402, 2012
work page internal anchor Pith review arXiv 2012
-
[37]
D. Tran, L. Bourdev, R. Fergus, L. Torresani, and M. Paluri. Learning spatiotemporal features with 3d convolutional networks. InProceed- ings of the IEEE international conference on computer vision, pages 4489–4497, 2015
2015
-
[38]
Van der Maaten and G
L. Van der Maaten and G. Hinton. Visualizing data using t-sne.Journal of machine learning research, 9(11), 2008
2008
-
[39]
L. Wang, B. Huang, Z. Zhao, Z. Tong, Y . He, Y . Wang, Y . Wang, and Y . Qiao. Videomae v2: Scaling video masked autoencoders with dual masking. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14549–14560, 2023
2023
-
[40]
L. Wang, Y . Xiong, Z. Wang, Y . Qiao, D. Lin, X. Tang, and L. Van Gool. Temporal segment networks for action recognition in videos.IEEE transactions on pattern analysis and machine intelligence, 41(11):2740–2755, 2018
2018
-
[41]
H. Wu, X. Ma, and Y . Li. Spatiotemporal multimodal learning with 3d cnns for video action recognition.IEEE Transactions on Circuits and Systems for Video Technology, 32(3):1250–1261, 2021
2021
-
[42]
S. Yan, Y . Xiong, and D. Lin. Spatial temporal graph convolutional networks for skeleton-based action recognition. InProceedings of the AAAI Conference on Artificial Intelligence, volume 32, 2018
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.