Recognition: unknown
Adaptive Test-Time Compute Allocation with Evolving In-Context Demonstrations
Pith reviewed 2026-05-09 23:52 UTC · model grok-4.3
The pith
A test-time method builds a pool of successful responses from easy queries then uses semantic similarity to evolve in-context examples for harder ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that jointly adapting compute allocation and generation distributions at test time yields better performance with lower total cost: a warm-up phase first identifies easy queries and assembles a pool of their successful responses; an adaptive phase then concentrates further samples on unresolved queries while reshaping each generation by conditioning on successful responses from semantically related queries in the pool.
What carries the argument
Evolving in-context demonstrations, which select successful responses from the test-set pool by semantic similarity to condition generation for each new unresolved query.
If this is right
- Accuracy rises on math, coding, and reasoning benchmarks relative to static test-time methods.
- Total number of model calls needed to reach a target performance level drops.
- Compute is automatically redirected away from queries that have already been solved correctly.
- Each generation for a difficult query is conditioned on a changing, query-specific set of prior successes rather than a fixed prompt.
Where Pith is reading between the lines
- The same warm-up-plus-similarity idea could be applied to other modalities or to open-ended generation tasks where success is harder to verify automatically.
- If semantic similarity proves reliable, future systems might maintain a running pool across multiple related tasks rather than resetting per benchmark.
- The approach implicitly treats the test set as a source of training signal at inference time, which may change how benchmarks are constructed or protected.
Load-bearing premise
That a warm-up run on the test set itself can identify enough easy queries and assemble a pool of successful responses whose semantic similarity to harder queries is sufficient to improve generation without introducing bias or leakage.
What would settle it
An experiment in which the warm-up phase yields too few successful examples or in which semantic matching produces no accuracy gain over repeated sampling from the base distribution would falsify the claimed benefit.
Figures

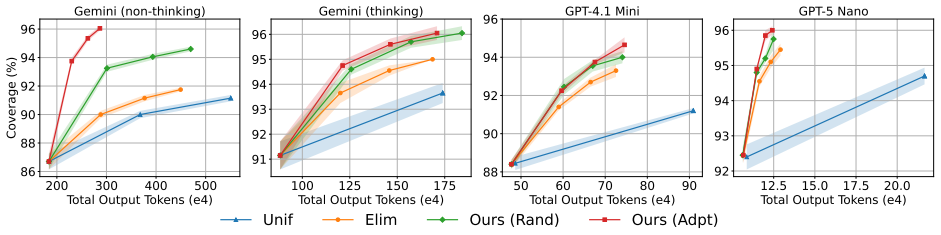






read the original abstract
While scaling test-time compute can substantially improve model performance, existing approaches either rely on static compute allocation or sample from fixed generation distributions. In this work, we introduce a test-time compute allocation framework that jointly adapts where computation is spent and how generation is performed. Our method begins with a warm-up phase that identifies easy queries and assembles an initial pool of question-response pairs from the test set itself. An adaptive phase then concentrates further computation on unresolved queries while reshaping their generation distributions through evolving in-context demonstrations -- conditioning each generation on successful responses from semantically related queries rather than resampling from a fixed distribution. Experiments across math, coding, and reasoning benchmarks demonstrate that our approach consistently outperforms existing baselines while consuming substantially less inference-time compute.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a test-time compute allocation framework for language models. It begins with a warm-up phase that identifies easy queries and assembles a pool of question-response pairs drawn from the test set itself. An adaptive phase then focuses additional computation on unresolved queries while conditioning generation on semantically similar successful responses from the pool as evolving in-context demonstrations, rather than resampling from a fixed distribution. The authors claim this yields consistent outperformance over existing baselines across math, coding, and reasoning benchmarks while consuming substantially less inference-time compute.
Significance. If the empirical results hold after addressing leakage and compute-accounting concerns, the work could provide a practical advance in efficient test-time scaling by jointly adapting allocation and generation distributions via cross-query semantic conditioning. This would differentiate it from static or fixed-distribution baselines and offer a falsifiable path to better performance-compute tradeoffs.
major comments (3)
- [Abstract] Abstract: the central claim of consistent outperformance and substantially lower inference-time compute is stated without any quantitative results, baseline definitions, success criteria for 'unresolved queries,' or explicit controls for test-set leakage, rendering the empirical contribution unevaluable from the provided description.
- [Method] Method description (warm-up and adaptive phases): assembling the demonstration pool directly from the test set and then evaluating on the same set creates a circularity risk in which performance gains may partly reflect reuse of test information rather than generalization. No mechanism is described for preventing cross-query information flow or for streaming per-query operation without batch test-set access.
- [Experiments] Experiments section: the headline efficiency claim requires that the computational cost of the warm-up phase be included in the total reported inference-time compute and still show net savings versus baselines; the manuscript does not clarify whether this accounting is performed.
minor comments (1)
- [Abstract] The abstract introduces 'evolving in-context demonstrations' without a concise definition or example of how the pool is updated across queries; a short clarifying sentence would improve readability.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. We have revised the manuscript to address the concerns about the abstract, potential test-set circularity, and compute accounting. Our responses to each major comment are provided below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of consistent outperformance and substantially lower inference-time compute is stated without any quantitative results, baseline definitions, success criteria for 'unresolved queries,' or explicit controls for test-set leakage, rendering the empirical contribution unevaluable from the provided description.
Authors: We agree that the abstract would benefit from greater specificity. In the revised version we have added concise quantitative highlights (performance deltas and compute ratios versus the primary baselines), explicit definitions of the baselines used, the criterion for marking a query as unresolved, and a brief statement on leakage controls. These additions make the central claims directly evaluable while remaining within length limits. revision: yes
-
Referee: [Method] Method description (warm-up and adaptive phases): assembling the demonstration pool directly from the test set and then evaluating on the same set creates a circularity risk in which performance gains may partly reflect reuse of test information rather than generalization. No mechanism is described for preventing cross-query information flow or for streaming per-query operation without batch test-set access.
Authors: The concern is valid and we have clarified the design. The pool contains only model-generated responses on queries the model itself solved during warm-up; no ground-truth labels are injected. To address streaming and cross-query flow, the revised method section now specifies a sequential, per-query protocol: each new query is processed using only the demonstration pool accumulated from prior queries, with successful generations added on the fly. We have added an explicit streaming algorithm and a limitations paragraph acknowledging that the current implementation assumes access to the full test distribution for the warm-up ordering, which may not hold in strictly online settings. revision: partial
-
Referee: [Experiments] Experiments section: the headline efficiency claim requires that the computational cost of the warm-up phase be included in the total reported inference-time compute and still show net savings versus baselines; the manuscript does not clarify whether this accounting is performed.
Authors: We agree that total inference cost must encompass the warm-up phase. The revised experiments section now states explicitly that all reported FLOPs and token counts include warm-up computation, provides a per-phase breakdown, and confirms that the net savings versus static baselines remain positive after this inclusion. A new table column reports the warm-up overhead as a fraction of total cost. revision: yes
Circularity Check
Warm-up pool assembly from test set makes performance gains dependent on evaluation data access
specific steps
-
fitted input called prediction
[Abstract]
"Our method begins with a warm-up phase that identifies easy queries and assembles an initial pool of question-response pairs from the test set itself. An adaptive phase then concentrates further computation on unresolved queries while reshaping their generation distributions through evolving in-context demonstrations -- conditioning each generation on successful responses from semantically related queries rather than resampling from a fixed distribution."
The 'prediction' of improved outputs on unresolved test queries is performed by conditioning on a pool of responses that was itself constructed by running the model on the full test set. The outperformance and compute savings therefore reduce to the input of having batch access to the evaluation data for demonstration assembly, rather than arising from a test-time procedure that operates without such access.
full rationale
The paper's central empirical claim of consistent outperformance at lower inference compute rests on a method whose adaptive phase explicitly conditions generations on successful responses harvested from the same test set during an initial warm-up. This step is load-bearing for the headline result because the reshaping of generation distributions for unresolved queries is achieved by direct reuse of test-set information rather than an independent mechanism. No equations or self-citations are visible in the provided text to create additional circularity, but the described procedure reduces the reported gains to a form of in-evaluation data reuse. The derivation chain is therefore partially circular at the level of the performance claim itself.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Active Testing of Large Language Models via Approximate Neyman Allocation
Active testing via surrogate semantic entropy stratification and approximate Neyman allocation reduces MSE by up to 28% versus uniform sampling and saves about 23% of the labeling budget on language and multimodal benchmarks.
Reference graph
Works this paper leans on
-
[1]
Self-improving llm agents at test-time, 2025
Emre Can Acikgoz, Cheng Qian, Heng Ji, Dilek Hakkani-Tür, and Gokhan Tur. Self-improving llm agents at test-time, 2025. URL https://arxiv.org/abs/2510.07841
-
[2]
Chan, Biao Zhang, Ankesh Anand, Zaheer Abbas, Azade Nova, John D Co-Reyes, Eric Chu, Feryal Behbahani, Aleksandra Faust, and Hugo Larochelle
Rishabh Agarwal, Avi Singh, Lei M Zhang, Bernd Bohnet, Luis Rosias, Stephanie C.Y. Chan, Biao Zhang, Ankesh Anand, Zaheer Abbas, Azade Nova, John D Co-Reyes, Eric Chu, Feryal Behbahani, Aleksandra Faust, and Hugo Larochelle. Many-shot in-context learning. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https://op...
2024
-
[3]
Amanda Bertsch, Maor Ivgi, Emily Xiao, Uri Alon, Jonathan Berant, Matthew R. Gormley, and Graham Neubig. In-context learning with long-context models: An in-depth exploration. In Luis Chiruzzo, Alan Ritter, and Lu Wang, editors, Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Huma...
-
[4]
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling
Bradley Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V. Le, Christopher Ré, and Azalia Mirhoseini. Large language monkeys: Scaling inference compute with repeated sampling, 2024. URL https://arxiv.org/abs/2407.21787
work page internal anchor Pith review arXiv 2024
-
[5]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gr...
1901
-
[6]
Pure exploration in multi-armed bandits problems
S \'e bastien Bubeck, R \'e mi Munos, and Gilles Stoltz. Pure exploration in multi-armed bandits problems. In International conference on Algorithmic learning theory, pages 23--37. Springer, 2009
2009
-
[7]
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, Parker Schuh, Kensen Shi, Sashank Tsvyashchenko, Joshua Maynez, Abhishek Rao, Parker Barnes, Yi Tay, Noam Shazeer, Vinodkumar Prabhakaran, Emily Reif, Nan Du, Ben Hutchinson, Reiner Pope, James Bra...
2023
-
[8]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems, 2021. URL https://arxiv.org/abs/2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
Learning how hard to think: Input-adaptive allocation of LM computation
Mehul Damani, Idan Shenfeld, Andi Peng, Andreea Bobu, and Jacob Andreas. Learning how hard to think: Input-adaptive allocation of LM computation. In The Thirteenth International Conference on Learning Representations, 2025
2025
-
[10]
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai D...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Yufeng Du, Minyang Tian, Srikanth Ronanki, Subendhu Rongali, Sravan Babu Bodapati, Aram Galstyan, Azton Wells, Roy Schwartz, Eliu A Huerta, and Hao Peng. Context length alone hurts LLM performance despite perfect retrieval. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors, Findings of the Association for Computati...
-
[12]
Rae, and Laurent Sifre
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katie Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Oriol Vinyals, Jack W. Rae, and Laurent Sifre...
2022
-
[13]
Livecodebench: Holistic and contamination free evaluation of large language models for code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=chfJJYC3iL
2025
-
[14]
Best-arm identification algorithms for multi-armed bandits in the fixed confidence setting
Kevin Jamieson and Robert Nowak. Best-arm identification algorithms for multi-armed bandits in the fixed confidence setting. In 2014 48th annual conference on information sciences and systems (CISS), pages 1--6. IEEE, 2014
2014
-
[15]
Why Language Models Hallucinate
Adam Tauman Kalai, Ofir Nachum, Santosh S. Vempala, and Edwin Zhang. Why language models hallucinate, 2025. URL https://arxiv.org/abs/2509.04664
work page internal anchor Pith review arXiv 2025
-
[16]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models, 2020. URL https://arxiv.org/abs/2001.08361
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[17]
Large language models are zero-shot reasoners
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners. In Proceedings of the 36th International Conference on Neural Information Processing Systems, NIPS '22, Red Hook, NY, USA, 2022. Curran Associates Inc. ISBN 9781713871088
2022
-
[18]
Smith, and Hannaneh Hajishirzi
Nathan Lambert, Valentina Pyatkin, Jacob Morrison, LJ Miranda, Bill Yuchen Lin, Khyathi Chandu, Nouha Dziri, Sachin Kumar, Tom Zick, Yejin Choi, Noah A. Smith, and Hannaneh Hajishirzi. R eward B ench: Evaluating reward models for language modeling, April 2025. URL https://aclanthology.org/2025.findings-naacl.96/
2025
-
[19]
Solving quantitative reasoning problems with language models
Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, Yuhuai Wu, Behnam Neyshabur, Guy Gur-Ari, and Vedant Misra. Solving quantitative reasoning problems with language models. In Proceedings of the 36th International Conference on Neural Information Proces...
2022
-
[20]
Let's verify step by step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let's verify step by step. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=v8L0pN6EOi
2024
-
[21]
Qingwen Lin, Boyan Xu, Guimin Hu, Zijian Li, Zhifeng Hao, Keli Zhang, and Ruichu Cai. Cmcts: A constrained monte carlo tree search framework for mathematical reasoning in large language model, December 2025. ISSN 0924-669X. URL https://doi.org/10.1007/s10489-025-07044-6
-
[22]
11 Wendy Johnson and Thomas J Bouchard Jr
Jiachang Liu, Dinghan Shen, Yizhe Zhang, Bill Dolan, Lawrence Carin, and Weizhu Chen. What makes good in-context examples for gpt- 3 ?, 2021. URL https://arxiv.org/abs/2101.06804
-
[23]
Can 1b LLM surpass 405b LLM ? rethinking compute-optimal test-time scaling
Runze Liu, Junqi Gao, Jian Zhao, Kaiyan Zhang, Xiu Li, Biqing Qi, Wanli Ouyang, and Bowen Zhou. Can 1b LLM surpass 405b LLM ? rethinking compute-optimal test-time scaling. In Workshop on Reasoning and Planning for Large Language Models, 2025. URL https://openreview.net/forum?id=CvjX9Lhpze
2025
-
[24]
An optimal algorithm for the thresholding bandit problem, 2016
Andrea Locatelli, Maurilio Gutzeit, and Alexandra Carpentier. An optimal algorithm for the thresholding bandit problem, 2016. URL https://arxiv.org/abs/1605.08671
-
[25]
Self-refine: Iterative refinement with self-feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. Self-refine: Iterative refinement with self-feedback. In Thirty-seventh Conference on Neural Informat...
2023
-
[26]
Adaptive inference-time compute: Llms can predict if they can do better, even mid-generation, 2024
Rohin Manvi, Anikait Singh, and Stefano Ermon. Adaptive inference-time compute: Llms can predict if they can do better, even mid-generation, 2024. URL https://arxiv.org/abs/2410.02725
-
[27]
Marius Mosbach, Tiago Pimentel, Shauli Ravfogel, Dietrich Klakow, and Yanai Elazar. Few-shot fine-tuning vs. in-context learning: A fair comparison and evaluation. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors, Findings of the Association for Computational Linguistics: ACL 2023, pages 12284--12314, Toronto, Canada, July 2023. Association...
-
[28]
s1: Simple test-time scaling
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Cand \`e s, and Tatsunori B Hashimoto. s1: Simple test-time scaling. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 20286--20332, 2025
2025
-
[29]
Learning to reason with llms, 2024
OpenAI. Learning to reason with llms, 2024. URL https://openai.com/index/learning-to-reason-with-llms/. Accessed 12-Sep-2024
2024
-
[30]
In-context learning with iterative demonstration selection
Chengwei Qin, Aston Zhang, Chen Chen, Anirudh Dagar, and Wenming Ye. In-context learning with iterative demonstration selection. In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 7441--7455, 2024
2024
-
[31]
Gpqa: A graduate-level google-proof q&a benchmark
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. Gpqa: A graduate-level google-proof q&a benchmark. In First conference on language modeling, 2024
2024
-
[32]
Scaling LLM test-time compute optimally can be more effective than scaling parameters for reasoning
Charlie Victor Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling LLM test-time compute optimally can be more effective than scaling parameters for reasoning. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=4FWAwZtd2n
2025
-
[33]
Reasoning gym: Reasoning environments for reinforcement learning with verifiable rewards
Zafir Stojanovski, Oliver Stanley, Joe Sharratt, Richard Jones, Abdulhakeem Adefioye, Jean Kaddour, and Andreas K \"o pf. Reasoning gym: Reasoning environments for reinforcement learning with verifiable rewards. In The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2025. URL https://openreview.net/fo...
2025
-
[34]
Fast best-of-n decoding via speculative rejection
Hanshi Sun, Momin Haider, Ruiqi Zhang, Huitao Yang, Jiahao Qiu, Ming Yin, Mengdi Wang, Peter Bartlett, and Andrea Zanette. Fast best-of-n decoding via speculative rejection. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https://openreview.net/forum?id=348hfcprUs
2024
-
[35]
Adaptive rectification sampling for test-time compute scaling, 2025
Zhendong Tan, Xingjun Zhang, Chaoyi Hu, Yancheng Pan, and Shaoxun Wang. Adaptive rectification sampling for test-time compute scaling, 2025. URL https://arxiv.org/abs/2504.01317
-
[36]
Multilingual LLM s are better cross-lingual in-context learners with alignment
Eshaan Tanwar, Subhabrata Dutta, Manish Borthakur, and Tanmoy Chakraborty. Multilingual LLM s are better cross-lingual in-context learners with alignment. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors, Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 6292--6307, Toront...
-
[37]
Google Gemini Team. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities, 2025. URL https://arxiv.org/abs/2507.06261
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Jens Tuyls, Dylan J Foster, Akshay Krishnamurthy, and Jordan T. Ash. Representation-based exploration for language models: From test-time to post-training. In The Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=S4PCF1YxoR
2026
-
[39]
Solving math word problems with process- and outcome-based feedback
Jonathan Uesato, Nate Kushman, Ramana Kumar, Francis Song, Noah Siegel, Lisa Wang, Antonia Creswell, Geoffrey Irving, and Irina Higgins. Solving math word problems with process-and outcome-based feedback. arXiv preprint arXiv:2211.14275, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[40]
Junlin Wang, Shang Zhu, Jon Saad-Falcon, Ben Athiwaratkun, Qingyang Wu, Jue Wang, Shuaiwen Leon Song, Ce Zhang, Bhuwan Dhingra, and James Zou. Think deep, think fast: Investigating efficiency of verifier-free inference-time-scaling methods, 2025 a . URL https://arxiv.org/abs/2504.14047
-
[41]
Make every penny count: Difficulty-adaptive self-consistency for cost-efficient reasoning
Xinglin Wang, Shaoxiong Feng, Yiwei Li, Peiwen Yuan, Yueqi Zhang, Chuyi Tan, Boyuan Pan, Yao Hu, and Kan Li. Make every penny count: Difficulty-adaptive self-consistency for cost-efficient reasoning. In Luis Chiruzzo, Alan Ritter, and Lu Wang, editors, Findings of the Association for Computational Linguistics: NAACL 2025, pages 6919--6932, Albuquerque, Ne...
-
[42]
Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=1PL1NIMMrw
2023
-
[43]
Chi, Quoc V Le, and Denny Zhou
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, brian ichter, Fei Xia, Ed H. Chi, Quoc V Le, and Denny Zhou. Chain of thought prompting elicits reasoning in large language models. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors, Advances in Neural Information Processing Systems, 2022. URL https://openreview.net/forum?i...
2022
-
[44]
On the role of temperature sampling in test-time scaling.arXiv preprint arXiv:2510.02611, 2025
Yuheng Wu, Azalia Mirhoseini, and Thierry Tambe. On the role of temperature sampling in test-time scaling, 2025. URL https://arxiv.org/abs/2510.02611
-
[45]
Rethinking the unsolvable: When in-context search meets test-time scaling, 2025
Fanzeng Xia, Yidong Luo, Tinko Sebastian Bartels, Yaqi Xu, and Tongxin Li. Rethinking the unsolvable: When in-context search meets test-time scaling, 2025. URL https://arxiv.org/abs/2505.22290
-
[46]
\ k\ NN prompting: Beyond-context learning with calibration-free nearest neighbor inference
Benfeng Xu, Quan Wang, Zhendong Mao, Yajuan Lyu, Qiaoqiao She, and Yongdong Zhang. \ k\ NN prompting: Beyond-context learning with calibration-free nearest neighbor inference. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=fe2S7736sNS
2023
-
[47]
Ziwei Xu, Sanjay Jain, and Mohan Kankanhalli. Hallucination is inevitable: An innate limitation of large language models, 2025. URL https://arxiv.org/abs/2401.11817
-
[48]
Griffiths, Yuan Cao, and Karthik R Narasimhan
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik R Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. In Thirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=5Xc1ecxO1h
2023
-
[49]
Making retrieval-augmented language models robust to irrelevant context
Ori Yoran, Tomer Wolfson, Ori Ram, and Jonathan Berant. Making retrieval-augmented language models robust to irrelevant context. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=ZS4m74kZpH
2024
-
[50]
The lessons of developing process reward models in mathematical reasoning
Zhenru Zhang, Chujie Zheng, Yangzhen Wu, Beichen Zhang, Runji Lin, Bowen Yu, Dayiheng Liu, Jingren Zhou, and Junyang Lin. The lessons of developing process reward models in mathematical reasoning. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors, Findings of the Association for Computational Linguistics: ACL 2025, pa...
-
[51]
Robust outlier arm identification
Yinglun Zhu, Sumeet Katariya, and Robert Nowak. Robust outlier arm identification. In International Conference on Machine Learning, pages 11566--11575. PMLR, 2020
2020
-
[52]
Pure exploration in kernel and neural bandits
Yinglun Zhu, Dongruo Zhou, Ruoxi Jiang, Quanquan Gu, Rebecca Willett, and Robert Nowak. Pure exploration in kernel and neural bandits. Advances in neural information processing systems, 34: 0 11618--11630, 2021
2021
-
[53]
Near instance optimal model selection for pure exploration linear bandits
Yinglun Zhu, Julian Katz-Samuels, and Robert Nowak. Near instance optimal model selection for pure exploration linear bandits. In International Conference on Artificial Intelligence and Statistics, pages 6735--6769. PMLR, 2022
2022
-
[54]
Strategic scaling of test-time compute: A bandit learning approach
Bowen Zuo and Yinglun Zhu. Strategic scaling of test-time compute: A bandit learning approach. In The Fourteenth International Conference on Learning Representations, 2026
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.