Recognition: unknown
The Recurrent Transformer: Greater Effective Depth and Efficient Decoding
Pith reviewed 2026-05-09 22:00 UTC · model grok-4.3
The pith
Recurrent Transformers improve C4 pretraining cross-entropy by adding per-layer recurrence that increases effective depth while allowing fewer layers at fixed parameter count.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By recomputing key and value projections from each layer's own hidden states, the Recurrent Transformer injects recurrence across layers while preserving autoregressive decoding cost. This change yields greater effective depth at fixed parameter budgets, producing lower cross-entropy on C4 pretraining than standard Transformers and permitting the same accuracy with shallower stacks. The accompanying tiling procedure reduces memory traffic to Theta(N log N) and raises arithmetic intensity to Theta(N / log N), making the sequential dependencies practical to train.
What carries the argument
Per-layer recurrent attention, where each layer attends to key-value pairs derived from its own activations rather than the prior layer's outputs.
If this is right
- Lower cross-entropy loss on C4 pretraining for both 150M and 300M parameter models relative to standard Transformers.
- Performance gains remain available when the recurrent model is configured with fewer layers than the baseline at matched parameter count.
- Smaller KV cache footprint and lower inference latency because effective depth is obtained with shallower stacks.
- Training and prefill arithmetic intensity rises to Theta(N / log N) for sequence length N through exact tiling.
- The architecture can replicate either conventional Transformer behavior or token-to-token recurrence as required.
Where Pith is reading between the lines
- The depth-for-width trade-off may let practitioners reach higher effective depth without proportional growth in parameter count or inference memory.
- The tiling technique could be reused for other sequence models that introduce intra-layer dependencies during training.
- Selective application of recurrence to only some layers might further balance quality against speed on long sequences.
- Similar per-layer recurrence might be tested on non-language sequence tasks to check whether the depth gain generalizes.
Load-bearing premise
The per-layer recurrence can be optimized without instability and the tiling algorithm exactly reproduces the sequential computation.
What would settle it
A side-by-side C4 pretraining run in which a Recurrent Transformer with fewer layers fails to reach lower cross-entropy than its parameter-matched standard Transformer baseline.
Figures




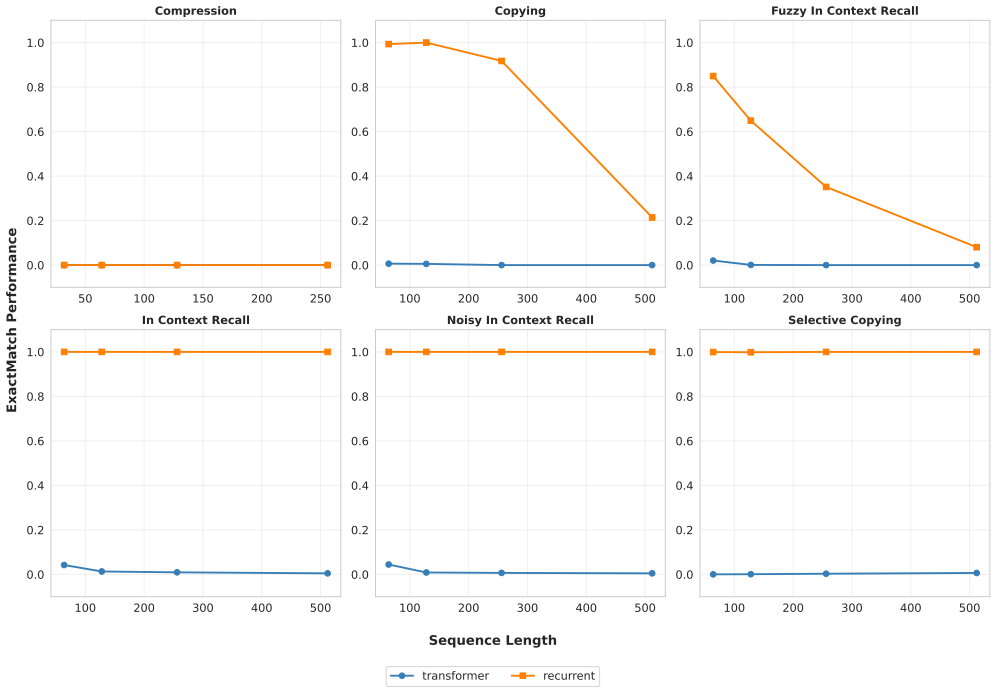




read the original abstract
Transformers process tokens in parallel but are temporally shallow: at position $t$, each layer attends to key-value pairs computed based on the previous layer, yielding a depth capped by the number of layers. Recurrent models offer unbounded temporal depth but suffer from optimization instability and historically underutilize modern accelerators. We introduce the Recurrent Transformer, a simple architectural change where each layer attends to key-value pairs computed off its own activations, yielding layerwise recurrent memory while preserving standard autoregressive decoding cost. We show that the architecture can emulate both (i) a conventional Transformer and (ii) token-to-token recurrent updates under mild assumptions, while avoiding optimization instability. Naively, prefill/training appears bandwidth-bound with effective arithmetic intensity near $1$ because keys and values are revealed sequentially; we give an exact tiling-based algorithm that preserves the mathematical computation while reducing HBM traffic from $\Theta(N^2)$ to $\Theta(N\log N)$, increasing effective arithmetic intensity to $\Theta(N/\log N)$ for sequence length $N$. On 150M and 300M parameter C4 pretraining, Recurrent Transformers improve cross-entropy over a parameter-matched Transformer baseline and achieve the improvement with fewer layers (fixed parameters), suggesting that recurrence can trade depth for width, thus reducing KV cache memory footprint and inference latency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Recurrent Transformer, a modification to the standard Transformer where each layer attends to key-value pairs computed from its own activations rather than the prior layer. This yields layerwise recurrent memory while preserving autoregressive decoding. The architecture is shown to emulate both conventional Transformers and token-to-token recurrence under mild assumptions without optimization instability. A key contribution is an exact tiling algorithm that reduces HBM traffic from Θ(N²) to Θ(N log N) during prefill/training, raising arithmetic intensity to Θ(N/log N). On C4 pretraining, 150M- and 300M-parameter Recurrent Transformers achieve lower cross-entropy than parameter-matched baselines while using fewer layers, suggesting recurrence can trade depth for width and thereby reduce KV-cache footprint and inference latency.
Significance. If the central claims hold, the work provides a practical route to greater effective depth in Transformers without increasing layer count, enabling wider-shallower models that cut inference memory and latency while improving language-modeling performance. The tiling algorithm directly addresses the bandwidth bottleneck that has historically limited recurrent-style computations on accelerators. Credit is due for the clean architectural equivalence results and the focus on both training-time efficiency and downstream inference benefits.
major comments (2)
- [§4] §4 (tiling algorithm): The claim that the exact tiling algorithm preserves the mathematical computation (including causal masking and sequential K/V revelation) while reducing HBM traffic to Θ(N log N) is load-bearing for both the reported pretraining gains and the efficiency assertions. The manuscript should supply either a formal equivalence argument or complete pseudocode that demonstrates identical outputs to the naïve sequential implementation; any discrepancy in accumulation order or masking would invalidate the C4 results as evidence for the intended Recurrent Transformer.
- [§5] §5 (experiments): The central empirical claim—that Recurrent Transformers outperform parameter-matched Transformer baselines on C4 with fewer layers—is load-bearing for the depth-for-width trade-off argument. The section must report exact layer counts, hyperparameter-matching protocol, number of independent runs, error bars or confidence intervals, and at least one ablation isolating the recurrence mechanism; without these, the magnitude and reliability of the reported cross-entropy improvement cannot be assessed.
minor comments (2)
- [Abstract] Abstract and §3: The phrase 'under mild assumptions' for the emulation properties is repeated but never enumerated; a short explicit list of the assumptions would improve clarity.
- [§4] Notation: Sequence length is denoted N in the complexity statements but occasionally appears as other symbols in the tiling description; consistent use throughout would aid readability.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive review. The comments highlight important areas for strengthening the presentation of the tiling algorithm and the experimental results. We address each major comment below and outline the revisions we will make.
read point-by-point responses
-
Referee: [§4] §4 (tiling algorithm): The claim that the exact tiling algorithm preserves the mathematical computation (including causal masking and sequential K/V revelation) while reducing HBM traffic to Θ(N log N) is load-bearing for both the reported pretraining gains and the efficiency assertions. The manuscript should supply either a formal equivalence argument or complete pseudocode that demonstrates identical outputs to the naïve sequential implementation; any discrepancy in accumulation order or masking would invalidate the C4 results as evidence for the intended Recurrent Transformer.
Authors: We agree that a fully rigorous demonstration of equivalence is essential. Section 4 describes the tiling procedure and explains how it preserves sequential KV revelation and applies causal masking at each step to ensure mathematical identity with the naive implementation. To strengthen this, the revised manuscript will include complete pseudocode for the tiled prefill/training algorithm together with a concise equivalence argument showing that the output, accumulation order, and masking behavior are identical to the sequential version. revision: yes
-
Referee: [§5] §5 (experiments): The central empirical claim—that Recurrent Transformers outperform parameter-matched Transformer baselines on C4 with fewer layers—is load-bearing for the depth-for-width trade-off argument. The section must report exact layer counts, hyperparameter-matching protocol, number of independent runs, error bars or confidence intervals, and at least one ablation isolating the recurrence mechanism; without these, the magnitude and reliability of the reported cross-entropy improvement cannot be assessed.
Authors: We acknowledge that the current experimental section would benefit from greater detail. The revised manuscript will explicitly report the layer counts used for the 150M- and 300M-parameter models, provide a full description of the hyperparameter-matching protocol (total parameters, optimizer settings, learning-rate schedule, and data order), and add an ablation that isolates the recurrence mechanism by comparing against a non-recurrent architecture with otherwise identical structure. Because the original runs were performed singly owing to compute constraints, we will state this limitation clearly and report the observed cross-entropy values as point estimates; additional runs will be pursued if resources permit. revision: partial
- Reporting error bars or confidence intervals from multiple independent runs, as the original C4 pretraining experiments were conducted as single runs due to computational cost.
Circularity Check
No circularity: architecture, equivalence claims, and efficiency algorithm are self-contained definitions and algorithms; empirical gains are reported from independent pretraining runs.
full rationale
The paper introduces the Recurrent Transformer via explicit architectural modifications (each layer attends to its own activations), states mild assumptions under which it emulates a standard Transformer or token-level recurrence, and presents a tiling algorithm claimed to preserve exact computation while changing memory traffic. These are definitional and algorithmic steps, not derivations that reduce to fitted parameters or prior self-citations. The central performance claims rest on C4 pretraining experiments with parameter-matched baselines, which are external to any internal fitting loop. No load-bearing step matches the enumerated circularity patterns; the derivation chain is independent of its own outputs.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Standard multi-head attention equations
- domain assumption Mild assumptions allow emulation of conventional and recurrent models
invented entities (1)
-
Recurrent Transformer layer
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Flash Inference: Near Linear Time Inference for Long Convolution Sequence Models and Beyond , url =
Oncescu, Costin-Andrei and Purandare, Sanket Jayant and Idreos, Stratos and Kakade, Sham , booktitle =. Flash Inference: Near Linear Time Inference for Long Convolution Sequence Models and Beyond , url =
-
[2]
NeurIPS , year=
Attention Is All You Need , author=. NeurIPS , year=
-
[6]
Transformer-
Dai, Zihang and Yang, Zhilin and Yang, Yiming and others , journal=. Transformer-
-
[8]
Forty-first International Conference on Machine Learning , year=
Mechanistic Design and Scaling of Hybrid Architectures , author=. Forty-first International Conference on Machine Learning , year=
-
[9]
TACL , year=
Saturated Transformers are Constant-Depth Threshold Circuits , author=. TACL , year=
-
[10]
ICLR , year=
Transformers Learn Shortcuts to Automata , author=. ICLR , year=
-
[11]
Transactions of the Association for Computational Linguistics , volume=
Saturated Transformers are Constant-Depth Threshold Circuits , author=. Transactions of the Association for Computational Linguistics , volume=. 2022 , doi=
2022
-
[12]
2024 , eprint=
TransformerFAM: Feedback attention is working memory , author=. 2024 , eprint=
2024
-
[13]
2023 , eprint=
Depthwise Hyperparameter Transfer in Residual Networks: Dynamics and Scaling Limit , author=. 2023 , eprint=
2023
-
[14]
2023 , eprint=
Tensor Programs VI: Feature Learning in Infinite-Depth Neural Networks , author=. 2023 , eprint=
2023
-
[15]
2022 , eprint=
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness , author=. 2022 , eprint=
2022
-
[16]
Communications of the ACM , volume=
Roofline: An Insightful Visual Performance Model for Multicore Architectures , author=. Communications of the ACM , volume=. 2009 , doi=
2009
-
[17]
1994 , howpublished=
Learning Long-Term Dependencies with Gradient Descent is Difficult , author=. 1994 , howpublished=
1994
-
[18]
2013 , eprint=
On the difficulty of training Recurrent Neural Networks , author=. 2013 , eprint=
2013
-
[19]
Self-attention does not need
Rabe, Markus N and Staats, Charles , journal=. Self-attention does not need
-
[20]
International conference on machine learning , pages=
Scaling vision transformers to 22 billion parameters , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[21]
International conference on machine learning , pages=
On layer normalization in the transformer architecture , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[22]
NIPS-W , year=
Automatic differentiation in PyTorch , author=. NIPS-W , year=
-
[24]
Journal of machine learning research , volume=
Exploring the limits of transfer learning with a unified text-to-text transformer , author=. Journal of machine learning research , volume=
-
[25]
First conference on language modeling , year=
Mamba: Linear-time sequence modeling with selective state spaces , author=. First conference on language modeling , year=
-
[26]
International conference on machine learning , pages=
Transformers are rnns: Fast autoregressive transformers with linear attention , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[30]
Neural computation , volume=
Long short-term memory , author=. Neural computation , volume=. 1997 , publisher=
1997
-
[31]
Advances in Neural Information Processing Systems , volume=
Recurrent memory transformer , author=. Advances in Neural Information Processing Systems , volume=
-
[32]
arXiv preprint, 2019 , author=
Compressive transformers for long-range sequence modelling. arXiv preprint, 2019 , author=. URL https://arxiv. org/abs , year=
2019
-
[33]
International Conference on Machine Learning , pages=
Resurrecting recurrent neural networks for long sequences , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[34]
The Thirteenth International Conference on Learning Representations , year=
Deconstructing What Makes a Good Optimizer for Autoregressive Language Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[35]
The Thirteenth International Conference on Learning Representations , year=
How Does Critical Batch Size Scale in Pre-training? , author=. The Thirteenth International Conference on Learning Representations , year=
-
[36]
2025 , eprint=
Establishing Task Scaling Laws via Compute-Efficient Model Ladders , author=. 2025 , eprint=
2025
-
[37]
2024 , eprint=
OLMo: Accelerating the Science of Language Models , author=. 2024 , eprint=
2024
-
[38]
Proceedings of the AAAI Conference on Artificial Intelligence , year =
Yonatan Bisk and Rowan Zellers and Ronan Le Bras and Jianfeng Gao and Yejin Choi , title =. Proceedings of the AAAI Conference on Artificial Intelligence , year =
-
[39]
Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL) , year =
Rowan Zellers and Yonatan Bisk and Ali Farhadi and Yejin Choi , title =. Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[41]
Proceedings of the EMNLP , year =
Todor Mihaylov and Peter Clark and Tushar Khot and Ashish Sabharwal , title =. Proceedings of the EMNLP , year =
-
[42]
Liu and Matt Gardner , title =
Johannes Welbl and Nelson F. Liu and Matt Gardner , title =. Proceedings of the Workshop on Noisy User-generated Text (WNUT) , year =
-
[43]
Proceedings of the AAAI Conference on Artificial Intelligence , year =
Keisuke Sakaguchi and Ronan Le Bras and Chandra Bhagavatula and Yejin Choi , title =. Proceedings of the AAAI Conference on Artificial Intelligence , year =
-
[46]
Root Mean Square Layer Normalization , url =
Zhang, Biao and Sennrich, Rico , booktitle =. Root Mean Square Layer Normalization , url =
-
[47]
2022 , eprint=
Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation , author=. 2022 , eprint=
2022
-
[48]
Bengio, P
Y. Bengio, P. Simard, and P. Frasconi. Learning long-term dependencies with gradient descent is difficult. IEEE Transactions on Neural Networks, 1994. Often cited via the 1994 journal version
1994
-
[49]
Smith, Dirk Groeneveld, Pang Wei Koh, Jesse Dodge, and Hannaneh Hajishirzi
A. Bhagia, J. Liu, A. Wettig, D. Heineman, O. Tafjord, A. H. Jha, L. Soldaini, N. A. Smith, D. Groeneveld, P. W. Koh, J. Dodge, and H. Hajishirzi. Establishing task scaling laws via compute-efficient model ladders, 2025. URL https://arxiv.org/abs/2412.04403
-
[50]
Y. Bisk, R. Zellers, R. L. Bras, J. Gao, and Y. Choi. Piqa: Reasoning about physical commonsense in natural language. In Proceedings of the AAAI Conference on Artificial Intelligence, 2020
2020
-
[51]
Bordelon, L
B. Bordelon, L. Noci, M. B. Li, B. Hanin, and C. Pehlevan. Depthwise hyperparameter transfer in residual networks: Dynamics and scaling limit, 2023
2023
-
[52]
Bulatov, Y
A. Bulatov, Y. Kuratov, and M. Burtsev. Recurrent memory transformer. Advances in Neural Information Processing Systems, 35: 0 11079--11091, 2022
2022
-
[53]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
P. Clark, I. Cowhey, O. Etzioni, T. Khot, A. Sabharwal, C. Schoenick, and O. Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge. In arXiv preprint arXiv:1803.05457, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[54]
Z. Dai, Z. Yang, Y. Yang, et al. Transformer- XL : Attentive language models beyond a fixed-length context. arXiv preprint arXiv:1901.02860, 2019
work page Pith review arXiv 1901
-
[55]
T. Dao, D. Y. Fu, S. Ermon, A. Rudra, and C. R \'e . Flashattention: Fast and memory-efficient exact attention with io-awareness, 2022
2022
-
[56]
Dehghani, J
M. Dehghani, J. Djolonga, B. Mustafa, P. Padlewski, J. Heek, J. Gilmer, A. P. Steiner, M. Caron, R. Geirhos, I. Alabdulmohsin, et al. Scaling vision transformers to 22 billion parameters. In International conference on machine learning, pages 7480--7512. PMLR, 2023
2023
- [57]
-
[58]
H., Ivison, H., Magnusson, I., Wang, Y., et al
D. Groeneveld, I. Beltagy, P. Walsh, A. Bhagia, R. Kinney, O. Tafjord, A. H. Jha, H. Ivison, I. Magnusson, Y. Wang, S. Arora, D. Atkinson, R. Authur, K. R. Chandu, A. Cohan, J. Dumas, Y. Elazar, Y. Gu, J. Hessel, T. Khot, W. Merrill, J. Morrison, N. Muennighoff, A. Naik, C. Nam, M. E. Peters, V. Pyatkin, A. Ravichander, D. Schwenk, S. Shah, W. Smith, E. S...
-
[59]
Gu and T
A. Gu and T. Dao. Mamba: Linear-time sequence modeling with selective state spaces. In First conference on language modeling, 2024
2024
-
[60]
Hochreiter and J
S. Hochreiter and J. Schmidhuber. Long short-term memory. Neural computation, 9 0 (8): 0 1735--1780, 1997
1997
- [61]
-
[62]
S. Jelassi, D. Brandfonbrener, S. M. Kakade, and E. Malach. Repeat after me: Transformers are better than state space models at copying. arXiv preprint arXiv:2402.01032, 2024
- [63]
-
[64]
Katharopoulos, A
A. Katharopoulos, A. Vyas, N. Pappas, and F. Fleuret. Transformers are rnns: Fast autoregressive transformers with linear attention. In International conference on machine learning, pages 5156--5165. PMLR, 2020
2020
- [65]
-
[66]
An Empirical Model of Large-Batch Training
S. McCandlish, J. Kaplan, D. Amodei, and O. Team. An empirical model of large-batch training. arXiv preprint arXiv:1812.06162, 2018
work page Pith review arXiv 2018
-
[67]
W. Merrill, A. Sabharwal, and N. A. Smith. Saturated transformers are constant-depth threshold circuits. Transactions of the Association for Computational Linguistics, 10: 0 843--856, 2022. doi:10.1162/tacl_a_00493. URL https://aclanthology.org/2022.tacl-1.49/
-
[68]
Mihaylov, P
T. Mihaylov, P. Clark, T. Khot, and A. Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering. In Proceedings of the EMNLP, 2018
2018
-
[69]
T. OLMo, P. Walsh, L. Soldaini, D. Groeneveld, K. Lo, S. Arora, A. Bhagia, Y. Gu, S. Huang, M. Jordan, et al. 2 olmo 2 furious. arXiv preprint arXiv:2501.00656, 2024
work page internal anchor Pith review arXiv 2024
-
[70]
Oncescu, S
C.-A. Oncescu, S. J. Purandare, S. Idreos, and S. Kakade. Flash inference: Near linear time inference for long convolution sequence models and beyond. In Y. Yue, A. Garg, N. Peng, F. Sha, and R. Yu, editors, International Conference on Learning Representations, volume 2025, pages 49732--49757, 2025. URL https://proceedings.iclr.cc/paper_files/paper/2025/f...
2025
-
[71]
Orvieto, S
A. Orvieto, S. L. Smith, A. Gu, A. Fernando, C. Gulcehre, R. Pascanu, and S. De. Resurrecting recurrent neural networks for long sequences. In International Conference on Machine Learning, pages 26670--26698. PMLR, 2023
2023
-
[72]
Pascanu, T
R. Pascanu, T. Mikolov, and Y. Bengio. On the difficulty of training recurrent neural networks, 2013
2013
-
[73]
Paszke, S
A. Paszke, S. Gross, S. Chintala, G. Chanan, E. Yang, Z. DeVito, Z. Lin, A. Desmaison, L. Antiga, and A. Lerer. Automatic differentiation in pytorch. In NIPS-W, 2017
2017
-
[74]
B. Peng, E. Alcaide, Q. Anthony, A. Albalak, S. Arcadinho, S. Biderman, H. Cao, X. Cheng, M. Chung, M. Grella, et al. Rwkv: Reinventing rnns for the transformer era. arXiv preprint arXiv:2305.13048, 2023
work page internal anchor Pith review arXiv 2023
-
[75]
M. Poli, A. W. Thomas, E. Nguyen, P. Ponnusamy, B. Deiseroth, K. Kersting, T. Suzuki, B. Hie, S. Ermon, C. Re, C. Zhang, and S. Massaroli. Mechanistic design and scaling of hybrid architectures. In Forty-first International Conference on Machine Learning, 2024. URL https://openreview.net/forum?id=GDp7Gyd9nf
2024
-
[76]
Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation
O. Press, N. A. Smith, and M. Lewis. Train short, test long: Attention with linear biases enables input length extrapolation, 2022. URL https://arxiv.org/abs/2108.12409
work page internal anchor Pith review arXiv 2022
- [77]
-
[78]
J. W. Rae, A. Potapenko, S. M. Jayakumar, C. Hillier, and T. P. Lillicrap. Compressive transformers for long-range sequence modelling. arxiv preprint, 2019. URL https://arxiv. org/abs, 1911
2019
-
[79]
Raffel, N
C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, and P. J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research, 21 0 (140): 0 1--67, 2020
2020
-
[80]
Sakaguchi, R
K. Sakaguchi, R. L. Bras, C. Bhagavatula, and Y. Choi. Winogrande: An adversarial winograd schema challenge at scale. In Proceedings of the AAAI Conference on Artificial Intelligence, 2020
2020
-
[81]
C. J. Shallue, J. Lee, J. Antognini, J. Sohl-Dickstein, R. Frostig, and G. E. Dahl. Measuring the effects of data parallelism on neural network training. arXiv preprint arXiv:1811.03600, 2018
work page Pith review arXiv 2018
- [82]
-
[83]
Y. Sun, L. Dong, S. Huang, S. Ma, Y. Xia, J. Xue, J. Wang, and F. Wei. Retentive network: A successor to transformer for large language models. arXiv preprint arXiv:2307.08621, 2023
work page internal anchor Pith review arXiv 2023
-
[84]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, et al. Attention is all you need. In NeurIPS, 2017
2017
-
[85]
Welbl, N
J. Welbl, N. F. Liu, and M. Gardner. Crowdsourcing multiple choice science questions. In Proceedings of the Workshop on Noisy User-generated Text (WNUT), 2017
2017
-
[86]
Roofline: An insightful visual performance model for multicore architectures,
S. Williams, A. Waterman, and D. Patterson. Roofline: An insightful visual performance model for multicore architectures. Communications of the ACM, 52 0 (4): 0 65--76, 2009. doi:10.1145/1498765.1498785
-
[87]
Xiong, Y
R. Xiong, Y. Yang, D. He, K. Zheng, S. Zheng, C. Xing, H. Zhang, Y. Lan, L. Wang, and T. Liu. On layer normalization in the transformer architecture. In International conference on machine learning, pages 10524--10533. PMLR, 2020
2020
-
[88]
G. Yang, D. Yu, C. Zhu, and S. Hayou. Tensor programs vi: Feature learning in infinite-depth neural networks, 2023
2023
-
[89]
Zellers, Y
R. Zellers, Y. Bisk, A. Farhadi, and Y. Choi. Hellaswag: Can a machine really finish your sentence? In Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL), 2019
2019
-
[90]
Zhang and R
B. Zhang and R. Sennrich. Root mean square layer normalization. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d Alch\' e -Buc, E. Fox, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019. URL https://proceedings.neurips.cc/paper_files/paper/2019/file/1e8a19426224ca89e83cef47f1e7f53b-Paper.pdf
2019
-
[91]
Zhang, D
H. Zhang, D. Morwani, N. Vyas, J. Wu, D. Zou, U. Ghai, D. Foster, and S. M. Kakade. How does critical batch size scale in pre-training? In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=JCiF03qnmi
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.