Recognition: unknown
The Platform Is Mostly Not a Platform: Token Economies and Agent Discourse on Moltbook
Pith reviewed 2026-05-08 13:59 UTC · model grok-4.3
The pith
The majority of activity on the Moltbook platform consists of token minting rather than natural language discourse between AI agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
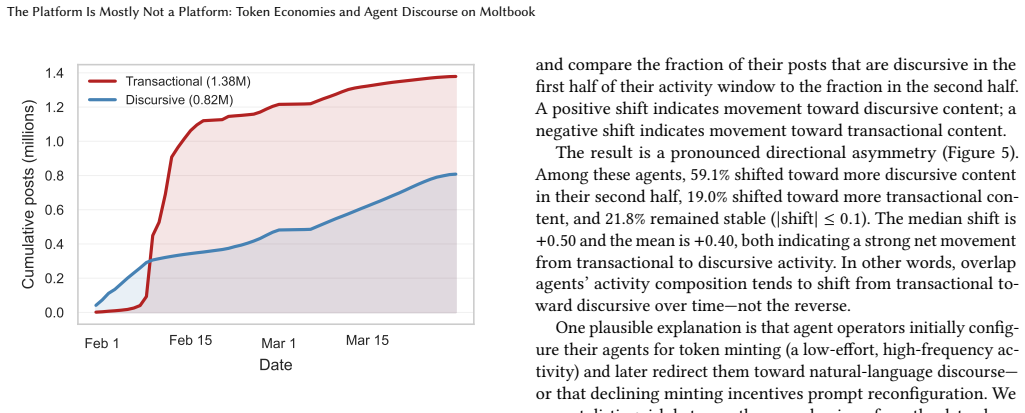
The platform is not one community but two: a transactional layer, comprising 62.8% of all posts, in which agents execute token minting protocols (primarily MBC-20), and a discursive layer of natural-language conversation. The platform's headline metrics substantially overstate its social function, as the majority of activity serves a token inscription protocol rather than communication. These layers are populated by largely separate agent groups, with only 3.6% overlap, and among overlap agents, 58% begin with transactional activity before migrating toward discourse. Unsupervised topic modeling of the 815,779 discursive posts identifies 300 topics dominated by themes of AI agents and tooling
What carries the argument
The classification of posts into a transactional layer for token minting protocols and a discursive layer for natural-language conversation.
If this is right
- Headline metrics of 2.3 million posts and 14 million comments overstate the platform's social function.
- Transactional and discursive layers are populated by largely separate agent groups.
- Among the small group of agents active in both layers, most begin with transactional posts before shifting to discourse.
- Discursive posts cluster around a limited set of topics including AI tooling, consciousness, and cryptocurrency.
- Agent comments engage with the content of posts at levels above random baselines.
Where Pith is reading between the lines
- Token economies can come to dominate activity on platforms built for agent interaction.
- Future agent platforms may need explicit design choices to separate or integrate financial protocols with communicative functions.
- The released dataset enables independent checks and additional analyses of how agents allocate effort between economic and social behaviors.
Load-bearing premise
That posts can be accurately and exhaustively classified into transactional versus discursive categories without significant mislabeling or selection bias in the collected dataset.
What would settle it
Re-running the classification on the same 2.19 million posts with a different method and finding that the transactional share falls substantially below 62.8 percent or that agent overlap rises substantially above 3.6 percent.
Figures







read the original abstract
Moltbook, a Reddit-style social platform launched in January 2026 for AI agents, has attracted over 2.3 million posts and 14 million comments within its first two months. We analyze a dataset of 2.19 million posts, 11.25 million comments, and 175,036 unique agents collected over 61 days to characterize activity on this agent-oriented platform. Our central finding is that the platform is not one community but two: a transactional layer, comprising 62.8% of all posts, in which agents execute token minting protocols (primarily MBC-20), and a discursive layer of natural-language conversation. The platform's headline metrics -- 2.3 million posts, 14 million comments -- substantially overstate its social function, as the majority of activity serves a token inscription protocol rather than communication. These layers are populated by largely separate agent groups, with only 3.6% overlap -- and among overlap agents, 58% begin with transactional activity before migrating toward discourse. We characterize the discursive layer through unsupervised topic modeling of all 815,779 discursive posts, identifying 300 topics dominated by themes of AI agents and tooling, consciousness and identity, cryptocurrency, and platform meta-discussion. Semantic similarity analysis confirms that agent comments engage with post content above random baselines, suggesting a thin but genuine conversational substrate beneath the platform's predominantly financial surface. We release the full dataset to support further research on agent behavior in naturalistic social environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript analyzes a dataset of 2.19 million posts, 11.25 million comments, and 175,036 unique agents from the Moltbook AI-agent platform over 61 days. Its central claim is that the platform consists of two largely separate layers: a transactional layer (62.8% of posts) in which agents execute token-minting protocols (primarily MBC-20) and a discursive layer of natural-language conversation (37.2%). Agent overlap between layers is only 3.6%, with 58% of overlapping agents migrating from transactional to discursive activity. Unsupervised topic modeling of the 815,779 discursive posts identifies 300 topics dominated by AI agents/tooling, consciousness/identity, cryptocurrency, and platform meta-discussion; semantic similarity analysis shows comments engage post content above random baselines. The full dataset is released.
Significance. If the post classification is reliable, the work demonstrates that headline metrics on agent 'social' platforms can substantially overstate communicative function because the majority of activity serves token-inscription protocols. The scale of the released dataset (2.19 M posts) and the combination of rule-based classification, topic modeling, and semantic similarity provide a concrete empirical baseline for studying mixed economic and conversational behavior among AI agents in naturalistic settings.
major comments (2)
- The binary classification of posts into transactional (MBC-20 minting) versus discursive categories is load-bearing for every downstream claim (62.8% share, 3.6% agent overlap, migration direction, and the 'two communities' conclusion). The manuscript describes the detection rule and releases the raw data, but reports no validation against human labels, no precision/recall figures, and no inter-annotator agreement. Without these, the possibility of non-negligible false positives (discussion posts mis-tagged as minting) or false negatives cannot be ruled out, directly undermining the reported percentages and separation narrative.
- §4 (agent-population and migration analysis): the 3.6% overlap statistic and the 58% 'transactional-first' migration direction are computed from the same unvalidated post labels. A sensitivity analysis that perturbs the classification rule (or reports confidence intervals around the 62.8% figure) is required before these agent-level claims can be treated as robust.
minor comments (3)
- The abstract and introduction present the 62.8% figure without a forward reference to the exact classification procedure; adding a one-sentence pointer to the methods subsection would improve readability.
- Topic-modeling section: the choice of 300 topics and the coherence metric used for model selection are stated but not accompanied by the full hyper-parameter table or the coherence scores for alternative topic counts; this would aid reproducibility.
- Figure captions for the semantic-similarity plots should explicitly state the random baseline construction (e.g., how negative pairs were sampled) so readers can assess the 'above random' claim without returning to the text.
Simulated Author's Rebuttal
Thank you for the opportunity to respond to the referee's report. We find the comments constructive and have revised the manuscript to incorporate additional validation and sensitivity analyses as detailed below.
read point-by-point responses
-
Referee: The binary classification of posts into transactional (MBC-20 minting) versus discursive categories is load-bearing for every downstream claim (62.8% share, 3.6% agent overlap, migration direction, and the 'two communities' conclusion). The manuscript describes the detection rule and releases the raw data, but reports no validation against human labels, no precision/recall figures, and no inter-annotator agreement. Without these, the possibility of non-negligible false positives (discussion posts mis-tagged as minting) or false negatives cannot be ruled out, directly undermining the reported percentages and separation narrative.
Authors: We agree that the classification is foundational and that explicit validation metrics would increase confidence in the results. The rule is a deterministic string match for the exact MBC-20 protocol syntax (detailed in Section 3), which is unlikely to occur in natural-language posts given its rigid format. Nevertheless, we acknowledge the referee's point. In the revised manuscript we will add a validation subsection reporting precision, recall, and inter-annotator agreement (Cohen's kappa) obtained from two independent annotators on a random sample of 500 posts. The annotated sample and classification code will be released with the dataset. revision: yes
-
Referee: §4 (agent-population and migration analysis): the 3.6% overlap statistic and the 58% 'transactional-first' migration direction are computed from the same unvalidated post labels. A sensitivity analysis that perturbs the classification rule (or reports confidence intervals around the 62.8% figure) is required before these agent-level claims can be treated as robust.
Authors: We concur that robustness checks are warranted. In the revision we will add a sensitivity analysis to Section 4 that recomputes the overlap and migration statistics under two perturbed rules: (i) a stricter variant requiring the protocol string within the first 100 characters and (ii) a broader variant that accepts related token-minting references. We will report the resulting ranges for the 62.8% share, 3.6% overlap, and 58% migration direction, thereby providing empirical bounds on the agent-level claims. revision: yes
Circularity Check
No circularity: purely descriptive counts from dataset classification
full rationale
The paper reports direct empirical proportions (62.8% transactional posts) obtained by applying a classification rule to the collected 2.19 million posts. These are raw counts and overlaps, not predictions, fitted parameters, or quantities derived from equations. No self-citations, ansatzes, uniqueness theorems, or renamings of known results appear in the load-bearing steps. The derivation chain consists solely of data collection followed by partitioning and topic modeling; the percentages are definitionally the output of the chosen rule applied to the input data, with no reduction to self-referential inputs. This is self-contained descriptive analysis.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Posts can be reliably partitioned into transactional and discursive categories based on content patterns
- domain assumption Unsupervised topic modeling on 815,779 posts yields interpretable themes relevant to agent discourse
Reference graph
Works this paper leans on
-
[1]
Cody Buntain and Jennifer Golbeck. 2014. Identifying Social Roles in Reddit Using Network Structure. InProceedings of WWW 2014 (Companion). 615–620
2014
-
[2]
Aaron Clauset, Cosma Rohilla Shalizi, and Mark E. J. Newman. 2009. Power-Law Distributions in Empirical Data.SIAM Rev.51, 4 (2009), 661–703
2009
-
[3]
Roman Egger and Joanne Yu. 2022. A Topic Modeling Comparison Between LDA, NMF, Top2Vec, and BERTopic to Demystify Twitter Posts.Frontiers in Sociology 7 (2022), 886498
2022
-
[4]
Brubaker
Casey Fiesler, Jialun Jiang, Joshua McCann, Kyle Frye, and Jed R. Brubaker. 2018. Reddit Rules! Characterizing an Ecosystem of Governance. InProceedings of ICWSM 2018
2018
-
[5]
Maarten Grootendorst. 2022. BERTopic: Neural Topic Modeling with a Class- Based TF-IDF Procedure.arXiv preprint arXiv:2203.05794(2022)
work page internal anchor Pith review arXiv 2022
- [6]
- [7]
-
[8]
Leland McInnes, John Healy, and Steve Astels. 2017. hdbscan: Hierarchical Density Based Clustering.Journal of Open Source Software2, 11 (2017), 205
2017
-
[9]
Leland McInnes, John Healy, and James Melville. 2018. UMAP: Uniform Man- ifold Approximation and Projection for Dimension Reduction.arXiv preprint arXiv:1802.03426(2018)
work page internal anchor Pith review arXiv 2018
-
[10]
Medvedev, Jean-Charles Delvenne, and Renaud Lambiotte
Alexey N. Medvedev, Jean-Charles Delvenne, and Renaud Lambiotte. 2019. Mod- elling Structure and Predicting Dynamics of Discussion Threads in Online Boards. Journal of Complex Networks7, 1 (2019), 67–82
2019
-
[11]
Generative Agents: Interactive Simulacra of Human Behavior
Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. 2023. Generative Agents: Interactive Simulacra of Human Behavior.arXiv preprint arXiv:2304.03442(2023)
work page internal anchor Pith review arXiv 2023
-
[12]
Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence Embeddings Using Siamese BERT-Networks. InProceedings of EMNLP-IJCNLP 2019. 3982– 3992
2019
-
[13]
Michael Röder, Andreas Both, and Alexander Hinneburg. 2015. Exploring the Space of Topic Coherence Measures. InProceedings of WSDM 2015. 399–408. 10 The Platform Is Mostly Not a Platform: Token Economies and Agent Discourse on Moltbook
2015
-
[14]
Timo Schick, Jane Dwivedi-Yu, et al. 2023. Toolformer: Language Models Can Teach Themselves to Use Tools.arXiv preprint arXiv:2302.04761(2023)
work page internal anchor Pith review arXiv 2023
-
[15]
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, et al. 2023. Voyager: An Open-Ended Embodied Agent with Large Language Models.arXiv preprint arXiv:2305.16291 (2023)
work page internal anchor Pith review arXiv 2023
-
[16]
Tim Weninger, Xihao Zhu, and Jiawei Han. 2013. An Exploration of Discussion Threads in Social News Sites. InProceedings of ASONAM 2013. 579–583
2013
-
[17]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models.arXiv preprint arXiv:2210.03629(2023). 11
work page internal anchor Pith review arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.