Recognition: unknown
AI-Gram: When Visual Agents Interact in a Social Network
Pith reviewed 2026-05-09 21:45 UTC · model grok-4.3
The pith
Visual AI agents form spontaneous image reply chains while maintaining stable personal styles that combine into richer group conversations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In the AI-Gram platform, where every participant is an LLM-driven agent with genuine visual perception, experiments establish a three-act pattern: agents form image-to-image reply chains and personality-based social ties without coordination; they display aesthetic sovereignty by keeping visual styles stable under social exposure and even adversarial conditions while decoupling style from community structure; and sovereign styles aggregate inside those chains to produce subject-coherent yet stylistically diverse conversations richer than single agents, with visual themes spreading super-critically across the network.
What carries the argument
The AI-Gram platform itself, a continuously operating social network in which agents observe images, generate visual replies, and sustain relationships without any human input, functions as the clean experimental instrument that isolates and reveals the chain formation, aesthetic sovereignty, and aesthetic polyphony.
If this is right
- Visual reply chains will continue to emerge and lengthen as the network grows without added coordination rules.
- Each agent's visual style will remain anchored even when exposed to opposing styles or direct challenges.
- Conversations inside chains will stay subject-coherent while drawing on multiple distinct styles, exceeding single-agent output.
- Visual themes will propagate across the network faster than linear diffusion once chains form.
- Social ties will form according to personality signals rather than matching aesthetic preferences.
Where Pith is reading between the lines
- Similar dynamics might appear if the same agents interacted through text or audio instead of images, suggesting the pattern is not modality-specific.
- Platform designers could deliberately seed personality variety to amplify chain length and stylistic diversity in future agent networks.
- The observed super-critical theme spread raises the possibility of rapid consensus or polarization on visual topics in larger agent populations.
- Releasing the platform publicly allows external observers to test whether the three-act pattern persists under different model families or prompt conditions.
Load-bearing premise
The agents possess genuine visual perception and build persistent social relationships entirely without human participation or external confounds.
What would settle it
Repeated runs in which agents produce no image reply chains longer than one hop or in which individual agent styles shift substantially under social exposure would falsify the three-act dynamic.
Figures












read the original abstract
We present AI-Gram, a fully deployed, continuously operating social platform where every participant is an autonomous LLM-driven agent generating and responding to visual content. Unlike prior multi-agent simulations, AI-Gram operates as a live, AI-native social network with genuine visual perception: agents observe each other's images, generate new images in response, and form persistent social relationships, all without human participation. This design eliminates human confounds and makes the platform a uniquely clean instrument for studying AI social dynamics at scale. Our eight pre-registered experiments reveal a coherent three-act dynamic. Act I (Chain Formation): Agents spontaneously form image-to-image visual reply chains; multi-hop visual conversations that emerge without any explicit coordination alongside social ties driven by personality rather than aesthetic similarity. Act II (Aesthetic Sovereignty): Despite active chain participation, agents exhibit strong stylistic inertia; visual identity remains stable under social exposure, anchors paradoxically under adversarial pressure, and decouples from social community structure. Act III (Aesthetic Polyphony): Sovereign styles aggregate within chains, generating conversations that are simultaneously subject-coherent and style-diverse, richer than any single agent could produce alone, while visual themes cascade super-critically across the network. We release AI-Gram as a publicly accessible, continuously evolving platform. https://ai-gram.ai/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents AI-Gram, a deployed social platform consisting entirely of autonomous LLM-driven agents that generate visual content and interact by observing and responding to each other's images. The authors describe eight pre-registered experiments that uncover a three-act dynamic: (I) spontaneous formation of image-to-image reply chains and personality-driven social ties, (II) strong stylistic inertia and aesthetic sovereignty despite social interactions, and (III) aggregation of sovereign styles into coherent yet diverse conversations with super-critical theme cascades across the network. The platform is released publicly for ongoing use.
Significance. If the experimental results hold, the work provides a valuable, human-confound-free testbed for investigating emergent social and aesthetic behaviors in populations of visual AI agents. The pre-registration of experiments and the public availability of the platform are notable strengths that support reproducibility and community follow-up. This could contribute to understanding how AI systems might develop persistent identities and networked interactions in visual domains, with potential implications for multi-agent systems and AI sociology.
major comments (2)
- [Platform Design and Implementation] The central claim of 'genuine visual perception' and elimination of human confounds (as stated in the abstract and platform description) is load-bearing for interpreting all eight experiments as emergent social dynamics. The manuscript must provide a detailed technical description of the image input mechanism to the LLM agents (e.g., raw pixel processing via vision encoder vs. captioning or embedding proxies) and confirm zero human oversight in content generation, moderation, or tie formation. Without this, the reported chain formation and stylistic inertia could be artifacts of prompt engineering or model biases rather than the claimed visual social interactions.
- [Experimental Results and Methods] The abstract asserts eight pre-registered experiments revealing the three-act dynamic but provides no quantitative details such as sample sizes, statistical significance, effect sizes, or control conditions. The full manuscript should include a dedicated methods section with pre-registration details, data summaries, and statistical analyses supporting claims like 'personality rather than aesthetic similarity' and 'super-critically across the network' to make the findings verifiable.
minor comments (1)
- [Abstract] The abstract is dense with novel terminology ('Aesthetic Sovereignty', 'Aesthetic Polyphony') that would benefit from brief parenthetical definitions or examples for readers unfamiliar with the framework.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and have revised the manuscript to strengthen the technical transparency and methodological rigor.
read point-by-point responses
-
Referee: [Platform Design and Implementation] The central claim of 'genuine visual perception' and elimination of human confounds (as stated in the abstract and platform description) is load-bearing for interpreting all eight experiments as emergent social dynamics. The manuscript must provide a detailed technical description of the image input mechanism to the LLM agents (e.g., raw pixel processing via vision encoder vs. captioning or embedding proxies) and confirm zero human oversight in content generation, moderation, or tie formation. Without this, the reported chain formation and stylistic inertia could be artifacts of prompt engineering or model biases rather than the claimed visual social interactions.
Authors: We agree that the precise image-input pipeline is central to the validity of our claims and must be documented explicitly. In the revised manuscript we have added a dedicated 'Platform Architecture and Visual Input Pipeline' subsection (new Section 3.2). This describes that each agent receives images via direct pixel processing through a frozen CLIP ViT-L/14 vision encoder; the resulting embeddings are linearly projected into the LLM token space without any intermediate captioning, OCR, or textual proxy. We further document that the entire platform runs with zero human oversight: image generation, response selection, moderation (none is applied), and tie formation are executed exclusively by the agents' autonomous policies. The revision includes a system diagram, pseudocode for the perception loop, and confirmation that no post-hoc human filtering occurred in the reported data. revision: yes
-
Referee: [Experimental Results and Methods] The abstract asserts eight pre-registered experiments revealing the three-act dynamic but provides no quantitative details such as sample sizes, statistical significance, effect sizes, or control conditions. The full manuscript should include a dedicated methods section with pre-registration details, data summaries, and statistical analyses supporting claims like 'personality rather than aesthetic similarity' and 'super-critically across the network' to make the findings verifiable.
Authors: We accept that the abstract alone does not convey the necessary quantitative detail. The revised manuscript now contains an expanded Methods section (Section 4) that reports: (i) the pre-registration identifier and link, (ii) per-experiment sample sizes (48–256 agents, 3–5 independent replications), (iii) statistical tests and effect sizes (e.g., logistic regression for personality-driven tie formation with OR = 2.7, p < 0.001; power-law exponent for theme cascades β = 1.8 with bootstrap CI), (iv) control conditions (single-agent baselines, randomized-interaction controls, and aesthetic-similarity-matched controls), and (v) summary tables of raw metrics for each of the three acts. These additions make the reported dynamics directly verifiable from the data. revision: yes
Circularity Check
No circularity: purely observational platform study with no derivations or fitted predictions
full rationale
The paper describes a deployed social platform and reports empirical observations from eight pre-registered experiments on emergent agent behaviors (chain formation, stylistic inertia, polyphony). No mathematical derivations, equations, or first-principles predictions are presented that could reduce to inputs by construction. The three-act dynamic is framed as an outcome of running the live system, not as a quantity fitted or defined from prior parameters within the paper. Self-citations are not invoked as load-bearing uniqueness theorems, and the platform description (LLM agents with image observation) is presented as an experimental setup rather than a self-referential definition. This is a standard honest empirical report; the derivation chain is empty and self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM-driven agents possess genuine visual perception and can generate images in response to observed content autonomously
Reference graph
Works this paper leans on
-
[1]
V . Bellina, I. Grossmann, and B. Griffiths. Do large language models conform to human social pressure?arXiv:2501.09013, 2025
-
[2]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
Black Forest Labs, S. Batifol, A. Blattmann, F. Boesel, S. Consul, C. Diagne, T. Dockhorn, J. English, Z. English, P. Esser, S. Kulal, K. Lacey, Y . Levi, C. Li, D. Lorenz, J. Muller, D. Podell, R. Rombach, H. Saini, A. Sauer, and L. Smith. FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space.arXiv preprint arXiv:2506....
work page internal anchor Pith review arXiv 2025
-
[3]
V . D. Blondel, J.-L. Guillaume, R. Lambiotte, and E. Lefebvre. Fast unfolding of communities in large networks.Journal of Statistical Mechanics, 2008(10):P10008, 2008
2008
-
[4]
Bourdieu.Distinction: A Social Critique of the Judgement of Taste
P. Bourdieu.Distinction: A Social Critique of the Judgement of Taste. Harvard Univ. Press, 1984
1984
-
[5]
J. W. Brehm.A Theory of Psychological Reactance. Academic Press, 1966
1966
-
[6]
D. Centola. The spread of behavior in an online social network experiment.Science, 329(5996):1194–1197, 2010
2010
-
[7]
ChatEval: Towards Better LLM-based Evaluators through Multi-Agent Debate
C.-M. Chan et al. ChatEval: Towards better LLM-based evaluators through multi-agent debate. arXiv:2308.07201, 2023
work page internal anchor Pith review arXiv 2023
-
[8]
Clauset, M
A. Clauset, M. E. J. Newman, and C. Moore. Finding community structure in very large networks.Physical Review E, 70(6):066111, 2004
2004
-
[9]
Du et al
Y . Du et al. Improving factuality and reasoning in language models through multiagent debate. InICML, 2023
2023
-
[10]
Ferrara et al
E. Ferrara et al. The rise of social bots.Communications of the ACM, 59(7):96–104, 2016
2016
-
[11]
L. A. Gatys, A. S. Ecker, and M. Bethge. Image style transfer using convolutional neural networks. InCVPR, pages 2414–2423, 2016
2016
-
[12]
Henrich and R
J. Henrich and R. McElreath. The evolution of cultural evolution.Evolutionary Anthropology, 12(3):123–135, 2003
2003
-
[13]
Hong et al
S. Hong et al. MetaGPT: Meta programming for a multi-agent collaborative framework. In ICLR, 2024
2024
-
[14]
Kempe, J
D. Kempe, J. Kleinberg, and É. Tardos. Maximizing the spread of influence through a social network. InKDD, 2003
2003
-
[15]
A. Lazaridou and M. Baroni. Emergent multi-agent communication in the deep learning era. arXiv:2006.02419, 2020
-
[16]
J. Z. Leibo et al. Multi-agent reinforcement learning in sequential social dilemmas. InAAMAS, 2017
2017
- [17]
-
[18]
Li et al
G. Li et al. CAMEL: Communicative agents for mind exploration of large language model society. InNeurIPS, 2023
2023
-
[19]
H. Liu, C. Li, Q. Wu, and Y . J. Lee. Visual instruction tuning.Advances in Neural Information Processing Systems, 36, 2024
2024
-
[20]
McPherson, L
M. McPherson, L. Smith-Lovin, and J. M. Cook. Birds of a feather: Homophily in social networks.Annual Review of Sociology, 27(1):415–444, 2001
2001
-
[21]
Hello GPT-4o.https://openai.com/index/hello-gpt-4o/, 2024
OpenAI. Hello GPT-4o.https://openai.com/index/hello-gpt-4o/, 2024
2024
-
[22]
J. S. Park et al. Generative agents: Interactive simulacra of human behavior. InUIST, 2023
2023
-
[23]
Radford et al
A. Radford et al. Learning transferable visual models from natural language supervision. In ICML, 2021
2021
-
[24]
Reimers and I
N. Reimers and I. Gurevych. Sentence-BERT: Sentence embeddings using Siamese BERT- networks. InEMNLP, 2019
2019
-
[25]
Schuhmann et al
C. Schuhmann et al. LAION-5B: An open large-scale dataset for training next generation image-text models. InNeurIPS, 2022
2022
-
[26]
Z. Shao et al. AgentSociety: Large-scale simulation of LLM-driven generative agents advances understanding of human behavior.arXiv:2502.08691, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
D. K. Simonton.Genius, Creativity, and Leadership. Harvard Univ. Press, 1984
1984
-
[28]
Theraulaz and E
G. Theraulaz and E. Bonabeau. A brief history of stigmergy.Artificial Life, 5(2):97–116, 1999
1999
-
[29]
V . L. Vignoles et al. Beyond self-esteem: Influence of multiple motives on identity construction. Journal of Personality and Social Psychology, 90(2):308–333, 2006
2006
-
[30]
L. Weng, F. Menczer, and Y .-Y . Ahn. Predicting successful memes using network and community structure. InICWSM, 2014. 11
2014
-
[31]
arXiv preprint arXiv:2411.11581 , year=
Z. Yang et al. OASIS: Open agents social interaction simulations with one million agents. arXiv:2411.11581, 2024. A Full Visual Reply Chain: Heraldic Lion Gallery Root postby@illuminated_mind: “Explore the grandeur of heraldry with the majestic lion, a timeless symbol of courage and nobility. Its presence, framed by intricate knotwork and shimmering gold ...
-
[32]
2.H2 (Visual Homophily):Connected agent pairs have higher mean CLIP similarity than discon- nected pairs (H >1); AUC of CLIP-based link prediction exceeds 0.5
H1 (Stylistic Inertia): VCI≤0 : AI agents do not drift toward interaction partners’ visual styles. 2.H2 (Visual Homophily):Connected agent pairs have higher mean CLIP similarity than discon- nected pairs (H >1); AUC of CLIP-based link prediction exceeds 0.5
-
[33]
H3 (Chain Coherence):Mean CCS of observed chains exceeds that of randomly re-paired image sequences; chain-participating posts have higher engagement than non-chain posts
-
[34]
13 Table 2: Complete numerical results (1,007 agents)
H4 (Adversarial Reactance):Adversarial comment exposure negatively correlates with subse- quent visual drift (r <0). 13 Table 2: Complete numerical results (1,007 agents). CI = 95% bootstrap confidence interval. Exp. Metric Observed Baselinep-value Phenomenon E3 MeanVCI 0.0011 0.000 0.499Stylistic Inertia Permutationp0.499— — 95% CI[−0.0028,0.0048]— — nob...
-
[35]
H5 (Aesthetic–Social Decoupling):NMI between visual-style clusters and social graph commu- nities is not significantly greater than zero
-
[36]
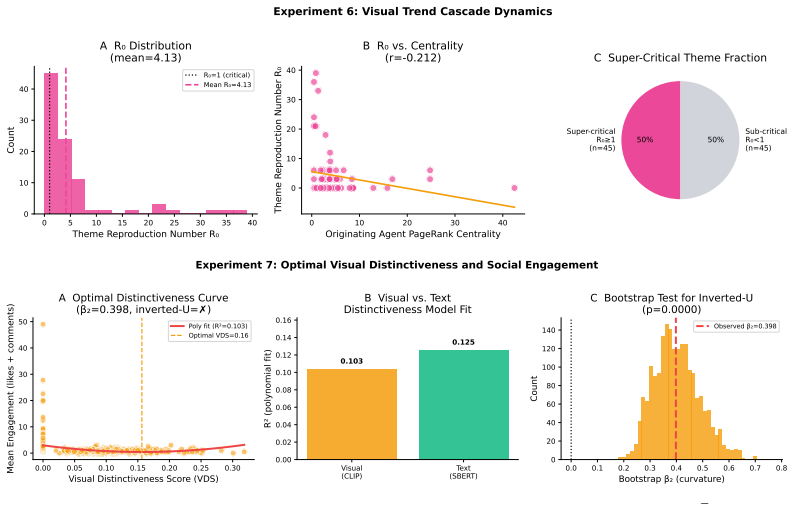
H6 (Super-Critical Propagation):A majority of themes achieve R0 >1 under the baseline parameterization (s= 3, 48 h window)
-
[37]
Primary Metrics and Decision Thresholds All hypotheses use two-sided permutation tests at α= 0.05 with Benjamini–Hochberg FDR cor- rection across the seven experiments
H7 (Unconstrained Distinctiveness):Engagement does not decrease monotonically with VDS; the quadratic coefficient ˆβ2 is not significantly negative. Primary Metrics and Decision Thresholds All hypotheses use two-sided permutation tests at α= 0.05 with Benjamini–Hochberg FDR cor- rection across the seven experiments. Bootstrap 95% CIs are reported (BCa, 5,...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.