Recognition: unknown
Causal Disentanglement for Full-Reference Image Quality Assessment
Pith reviewed 2026-05-09 22:04 UTC · model grok-4.3
The pith
Causal disentanglement separates image content from distortions to enable accurate full-reference quality assessment even without labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Degradation estimation is formulated as a causal disentanglement process guided by intervention on latent representations. Content invariance between reference and distorted images is exploited to decouple degradation and content representations. A masking module models the causal relationship between content and degradation features to extract content-influenced degradation features. Quality scores are predicted from these features via supervised regression or label-free dimensionality reduction, yielding competitive performance on standard IQA benchmarks in fully supervised, few-label, and label-free regimes and superior cross-domain generalization on non-standard natural image domains.
What carries the argument
Causal disentanglement process that intervenes on latent representations to separate degradation features from content, using a masking module to capture content-influenced degradations.
If this is right
- Quality prediction remains effective in the complete absence of labeled scores by reducing the dimensionality of the extracted degradation features.
- The same pipeline can be retrained on any new image domain without requiring human quality ratings for that domain.
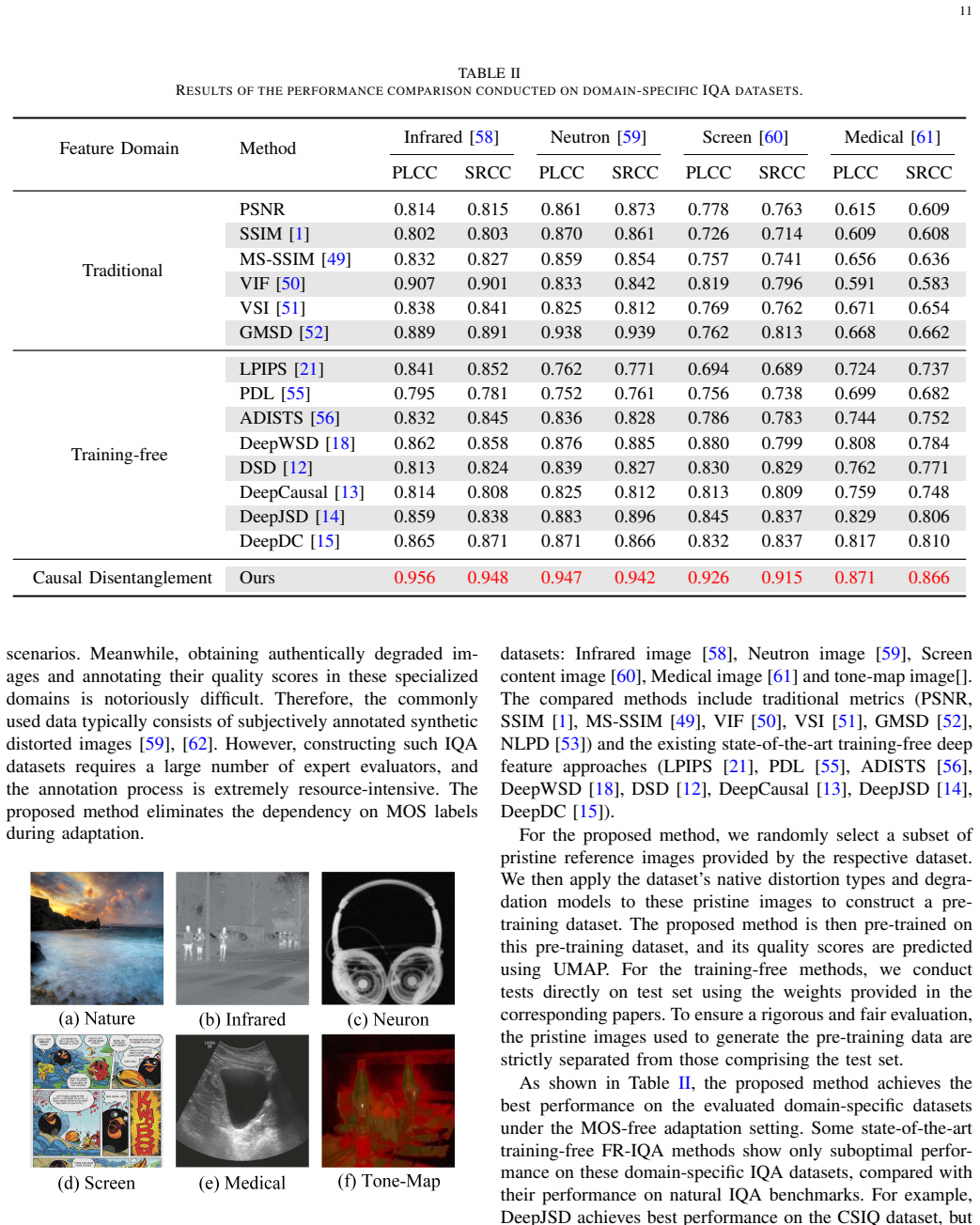
- Cross-domain results improve on underwater, radiographic, medical, neutron, and screen-content images relative to existing training-free baselines.
- Fully supervised, few-shot, and unsupervised variants all reach competitive accuracy on standard IQA benchmarks.
Where Pith is reading between the lines
- The same content-degradation split could be reused for related tasks such as blind image restoration or distortion-specific editing where labels are also scarce.
- Extending the invariance assumption to video frames or multi-view images would allow the method to handle temporal or viewpoint changes without new labels.
- Controlled synthetic experiments that vary only one distortion type while holding scene content fixed could directly measure how cleanly the masking module isolates each degradation.
Load-bearing premise
The content shown in the reference image stays exactly the same in the distorted version, so any difference can be cleanly attributed to degradation alone.
What would settle it
Constructing a test set of reference-distorted pairs where the underlying scene content is deliberately altered between the pair and checking whether the method's quality predictions become no better than random.
Figures












read the original abstract
Existing deep network-based full-reference image quality assessment (FR-IQA) models typically work by performing pairwise comparisons of deep features from the reference and distorted images. In this paper, we approach this problem from a different perspective and propose a novel FR-IQA paradigm based on causal inference and decoupled representation learning. Unlike typical feature comparison-based FR-IQA models, our approach formulates degradation estimation as a causal disentanglement process guided by intervention on latent representations. We first decouple degradation and content representations by exploiting the content invariance between the reference and distorted images. Second, inspired by the human visual masking effect, we design a masking module to model the causal relationship between image content and degradation features, thereby extracting content-influenced degradation features from distorted images. Finally, quality scores are predicted from these degradation features using either supervised regression or label-free dimensionality reduction. Extensive experiments demonstrate that our method achieves highly competitive performance on standard IQA benchmarks across fully supervised, few-label, and label-free settings. Furthermore, we evaluate the approach on diverse non-standard natural image domains with scarce data, including underwater, radiographic, medical, neutron, and screen-content images. Benefiting from its ability to perform scenario-specific training and prediction without labeled IQA data, our method exhibits superior cross-domain generalization compared to existing training-free FR-IQA models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a causal disentanglement framework for full-reference image quality assessment (FR-IQA). It decouples degradation and content representations by exploiting content invariance between reference and distorted images, employs a masking module inspired by human visual masking to capture causal content-degradation relationships, and predicts quality via supervised regression or label-free dimensionality reduction on the resulting degradation features. Experiments are reported to show competitive performance on standard IQA benchmarks across fully supervised, few-shot, and label-free regimes, plus superior cross-domain generalization on non-standard domains (underwater, radiographic, medical, neutron, screen-content) compared to training-free baselines.
Significance. If the empirical claims hold, the work provides a useful new paradigm for FR-IQA that supports label-free operation and improved generalization in data-scarce specialized domains. The explicit modeling of visual masking as a causal mechanism and the dual supervised/label-free pathways are strengths that could influence future representation-learning approaches to perceptual quality.
major comments (2)
- [§3] §3 (causal disentanglement and masking module): the intervention on latent representations is described at a conceptual level but lacks an explicit causal graph, do-operator formalization, or identifiability argument showing that content invariance plus masking isolates degradation features; this is load-bearing for the label-free dimensionality-reduction claim.
- [§4] §4 (experiments): the reported tables do not include error bars, statistical significance tests, or ablations isolating the masking module's contribution versus plain invariance decoupling; without these, the 'highly competitive' and 'superior cross-domain generalization' claims cannot be fully verified.
minor comments (3)
- [§3.2] Notation for the masking module (e.g., how the content-influenced degradation feature is computed from the reference and distorted latents) should be formalized with an equation rather than prose description.
- [§4.3] The abstract and introduction cite 'existing training-free FR-IQA models' but the experimental section should explicitly list which specific baselines (e.g., NIQE, BRISQUE variants, or recent zero-shot methods) are used for the cross-domain comparison.
- [§5] A short discussion of failure cases or domains where content invariance breaks (e.g., heavy geometric distortion) would strengthen the generalization analysis.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and positive overall assessment. We address each major comment below and indicate the planned revisions.
read point-by-point responses
-
Referee: [§3] §3 (causal disentanglement and masking module): the intervention on latent representations is described at a conceptual level but lacks an explicit causal graph, do-operator formalization, or identifiability argument showing that content invariance plus masking isolates degradation features; this is load-bearing for the label-free dimensionality-reduction claim.
Authors: We agree that the current presentation in §3 remains largely conceptual. In the revision we will add an explicit causal graph diagram, a do-operator formalization of the latent intervention, and a concise identifiability argument that shows how content invariance together with the masking module isolates the degradation features. These additions will directly support the label-free dimensionality-reduction pathway. revision: yes
-
Referee: [§4] §4 (experiments): the reported tables do not include error bars, statistical significance tests, or ablations isolating the masking module's contribution versus plain invariance decoupling; without these, the 'highly competitive' and 'superior cross-domain generalization' claims cannot be fully verified.
Authors: We accept that error bars, significance tests, and targeted ablations would strengthen verifiability. We will augment the tables with standard deviations computed over multiple random seeds and include paired statistical significance tests for the main comparisons. We will also insert a new ablation subsection that directly compares the full model (invariance + masking) against a plain invariance-decoupling baseline, thereby isolating the masking module's contribution. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper's core pipeline—decoupling degradation and content representations via content invariance (a standard FR-IQA premise), applying an explicit masking module to model content-degradation causality, and predicting scores via supervised regression or label-free dimensionality reduction—contains no self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations. The abstract and description present these as design choices with independent mechanisms (invariance exploitation, visual masking inspiration, and standard reduction techniques), not reductions to the method's own outputs by construction. No uniqueness theorems, ansatzes smuggled via prior self-work, or renamings of known results are invoked as load-bearing. The claims rest on empirical benchmarks rather than tautological derivations, making the chain self-contained against external evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Content invariance between reference and distorted images allows decoupling of degradation and content representations
invented entities (1)
-
Masking module
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Image quality assessment: from error visibility to structural similarity,
Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli, “Image quality assessment: from error visibility to structural similarity,”IEEE transactions on Image Processing, vol. 13, no. 4, pp. 600–612, 2004. 1, 10, 11
2004
-
[2]
Fsim: A feature similarity index for image quality assessment,
L. Zhang, L. Zhang, X. Mou, and D. Zhang, “Fsim: A feature similarity index for image quality assessment,”IEEE Transactions on Image Processing, vol. 20, no. 8, pp. 2378–2386, 2011. 1
2011
-
[3]
Full-reference image quality assessment by combining global and local distortion measures,
A. Saha and Q. J. Wu, “Full-reference image quality assessment by combining global and local distortion measures,”Signal Processing, vol. 128, pp. 186–197, 2016. 1
2016
-
[4]
Reduced-reference image quality assessment by structural similarity estimation,
A. Rehman and Z. Wang, “Reduced-reference image quality assessment by structural similarity estimation,”IEEE Transactions on Image Pro- cessing, vol. 21, no. 8, pp. 3378–3389, 2012. 1
2012
-
[5]
No-reference image quality assessment in the spatial domain,
A. Mittal, A. K. Moorthy, and A. C. Bovik, “No-reference image quality assessment in the spatial domain,”IEEE Transactions on Image Processing, vol. 21, no. 12, pp. 4695–4708, 2012. 1 15
2012
-
[6]
Image quality assessment: Unifying structure and texture similarity,
K. Ding, K. Ma, S. Wang, and E. P. Simoncelli, “Image quality assessment: Unifying structure and texture similarity,”IEEE transactions on pattern analysis and machine intelligence, vol. 44, no. 5, pp. 2567– 2581, 2020. 1, 2, 10
2020
-
[7]
Comparison of full-reference image quality models for optimiza- tion of image processing systems,
——, “Comparison of full-reference image quality models for optimiza- tion of image processing systems,”International Journal of Computer Vision, vol. 129, no. 4, pp. 1258–1281, 2021. 1
2021
-
[8]
Image quality assessment: Measuring perceptual degradation via distribution measures in deep feature spaces,
X. Liao, X. Wei, M. Zhou, Z. Li, and S. Kwong, “Image quality assessment: Measuring perceptual degradation via distribution measures in deep feature spaces,”IEEE Transactions on Image Processing, vol. 33, pp. 4044–4059, 2024. 1
2024
-
[9]
Per- ceptual attacks of no-reference image quality models with human-in- the-loop,
W. Zhang, D. Li, X. Min, G. Zhai, G. Guo, X. Yang, and K. Ma, “Per- ceptual attacks of no-reference image quality models with human-in- the-loop,”Advances in Neural Information Processing Systems, vol. 35, pp. 2916–2929, 2022. 1
2022
-
[10]
Topiq: A top-down approach from semantics to distortions for image quality assessment,
C. Chen, J. Mo, J. Hou, H. Wu, L. Liao, W. Sun, Q. Yan, and W. Lin, “Topiq: A top-down approach from semantics to distortions for image quality assessment,”IEEE Transactions on Image Processing, vol. 33, pp. 2404–2418, 2024. 1, 3, 10
2024
-
[11]
Image quality assessment: Exploring joint degradation effect of deep network features via kernel representation similarity analysis,
X. Liao, X. Wei, M. Zhou, H.-S. Wong, and S. Kwong, “Image quality assessment: Exploring joint degradation effect of deep network features via kernel representation similarity analysis,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025. 1, 3, 10
2025
-
[12]
Deep self- dissimilarities as powerful visual fingerprints,
I. Kligvasser, T. Shaham, Y . Bahat, and T. Michaeli, “Deep self- dissimilarities as powerful visual fingerprints,”Advances in Neural Information Processing Systems, vol. 34, pp. 3939–3951, 2021. 1, 10, 11
2021
-
[13]
Image quality assessment: Investigating causal perceptual effects with abductive counterfactual inference,
W. Shen, M. Zhou, Y . Chen, X. Wei, Y . Feng, H. Pu, and W. Jia, “Image quality assessment: Investigating causal perceptual effects with abductive counterfactual inference,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 17 990–17 999. 1, 3, 10, 11
2025
-
[14]
Image quality assessment: Measuring perceptual degradation via distribution measures in deep feature spaces,
X. Liao, X. Wei, M. Zhou, Z. Li, and S. Kwong, “Image quality assessment: Measuring perceptual degradation via distribution measures in deep feature spaces,”IEEE Transactions on Image Processing, vol. 33, pp. 4044–4059, 2024. 1, 10, 11
2024
-
[15]
Deepdc: Deep distance correlation as a perceptual image quality evaluator,
H. Zhu, B. Chen, L. Zhu, S. Wang, and W. Lin, “Deepdc: Deep distance correlation as a perceptual image quality evaluator,”IEEE Transactions on Image Processing, vol. 34, pp. 7859–7873, 2025. 1, 3, 10, 11
2025
-
[16]
Very Deep Convolutional Networks for Large-Scale Image Recognition
K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,”arXiv preprint arXiv:1409.1556, 2014. 1, 9
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[17]
Efficientnet: Rethinking model scaling for con- volutional neural networks,
M. Tan and Q. Le, “Efficientnet: Rethinking model scaling for con- volutional neural networks,” inInternational conference on machine learning. PMLR, 2019, pp. 6105–6114. 1
2019
-
[18]
Deepwsd: Projecting degradations in perceptual space to wasserstein distance in deep feature space,
X. Liao, B. Chen, H. Zhu, S. Wang, M. Zhou, and S. Kwong, “Deepwsd: Projecting degradations in perceptual space to wasserstein distance in deep feature space,” inProceedings of the 30th ACM International Conference on Multimedia, 2022, pp. 970–978. 1, 2, 10, 11
2022
-
[19]
Deepsim: Deep similarity for image quality assessment,
F. Gao, Y . Wang, P. Li, M. Tan, J. Yu, and Y . Zhu, “Deepsim: Deep similarity for image quality assessment,”Neurocomputing, vol. 257, pp. 104–114, 2017. 2
2017
-
[20]
Deep learning of human visual sensitivity in image quality assessment framework,
J. Kim and S. Lee, “Deep learning of human visual sensitivity in image quality assessment framework,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 1676–1684. 2
2017
-
[21]
The unreasonable effectiveness of deep features as a perceptual metric,
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The unreasonable effectiveness of deep features as a perceptual metric,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 586–595. 2, 10, 11
2018
-
[22]
Locally adaptive struc- ture and texture similarity for image quality assessment,
K. Ding, Y . Liu, X. Zou, S. Wang, and K. Ma, “Locally adaptive struc- ture and texture similarity for image quality assessment,” inProceedings of the 29th ACM International Conference on multimedia, 2021, pp. 2483–2491. 2
2021
-
[23]
H. D. Sikka,A Deeper Look at the Unsupervised Learning of Disen- tangled Representations inβ-VAE from the perspective of Core Object Recognition. Harvard University, 2020. 3, 6
2020
-
[24]
Auto-Encoding Variational Bayes
D. P. Kingma and M. Welling, “Auto-encoding variational bayes,”arXiv preprint arXiv:1312.6114, 2013. 3
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[25]
beta-vae: Learning basic visual concepts with a constrained variational framework,
I. Higgins, L. Matthey, A. Pal, C. Burgess, X. Glorot, M. Botvinick, S. Mohamed, and A. Lerchner, “beta-vae: Learning basic visual concepts with a constrained variational framework,” inInternational conference on learning representations, 2017. 3
2017
-
[26]
Causalvae: Disentangled representation learning via neural structural causal mod- els,
M. Yang, F. Liu, Z. Chen, X. Shen, J. Hao, and J. Wang, “Causalvae: Disentangled representation learning via neural structural causal mod- els,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 9593–9602. 3, 4, 6
2021
-
[27]
Scadi: Self-supervised causal disentanglement in latent vari- able models,
H. Nam, “Scadi: Self-supervised causal disentanglement in latent vari- able models,”arXiv preprint arXiv:2311.06567, 2023. 3, 4, 6
-
[28]
Luminance-model-based dct quantization for color image compression,
A. J. Ahumada Jr and H. A. Peterson, “Luminance-model-based dct quantization for color image compression,” inHuman vision, visual processing, and digital display III, vol. 1666. SPIE, 1992, pp. 365–374. 3, 8
1992
-
[29]
Measuring contrast sensitivity,
D. G. Pelli and P. Bex, “Measuring contrast sensitivity,”Vision research, vol. 90, pp. 10–14, 2013. 3, 8
2013
-
[30]
Contrast masking in human vision,
G. E. Legge and J. M. Foley, “Contrast masking in human vision,” Journal of the optical Society of America, vol. 70, no. 12, pp. 1458– 1471, 1980. 3, 8
1980
-
[31]
Perceptually-friendly h. 264/avc video coding based on foveated just-noticeable-distortion model,
Z. Chen and C. Guillemot, “Perceptually-friendly h. 264/avc video coding based on foveated just-noticeable-distortion model,”IEEE Trans- actions on Circuits and Systems for Video Technology, vol. 20, no. 6, pp. 806–819, 2010. 3, 8
2010
-
[32]
Visual interaction perceptual network for blind image quality assessment,
X. Wang, J. Xiong, and W. Lin, “Visual interaction perceptual network for blind image quality assessment,”IEEE Transactions on Multimedia, vol. 25, pp. 8958–8971, 2023. 3
2023
-
[33]
Cdinet: Content distortion interaction network for blind image quality assessment,
L. Zheng, Y . Luo, Z. Zhou, J. Ling, and G. Yue, “Cdinet: Content distortion interaction network for blind image quality assessment,”IEEE Transactions on Multimedia, vol. 26, pp. 7089–7100, 2024. 3
2024
-
[34]
Image database tid2013: Peculiarities, results and perspectives,
N. Ponomarenko, L. Jin, O. Ieremeiev, V . Lukin, K. Egiazarian, J. Astola, B. V ozel, K. Chehdi, M. Carli, F. Battistiet al., “Image database tid2013: Peculiarities, results and perspectives,”Signal Processing: Image Com- munication, vol. 30, pp. 57–77, 2015. 4, 5, 10
2015
-
[35]
A statistical evaluation of recent full reference image quality assessment algorithms,
H. R. Sheikh, M. F. Sabir, and A. C. Bovik, “A statistical evaluation of recent full reference image quality assessment algorithms,”IEEE Transactions on Image Processing, vol. 15, no. 11, pp. 3440–3451, 2006. 4, 5, 10
2006
-
[36]
Weakly supervised disentangled generative causal representation learning,
X. Shen, F. Liu, H. Dong, Q. Lian, Z. Chen, and T. Zhang, “Weakly supervised disentangled generative causal representation learning,”Jour- nal of Machine Learning Research, vol. 23, no. 241, pp. 1–55, 2022. 4, 6
2022
-
[37]
Challenging common assumptions in the unsupervised learning of disentangled representations,
F. Locatello, S. Bauer, M. Lucic, G. Raetsch, S. Gelly, B. Sch ¨olkopf, and O. Bachem, “Challenging common assumptions in the unsupervised learning of disentangled representations,” ininternational conference on machine learning. PMLR, 2019, pp. 4114–4124. 5
2019
-
[38]
Pearl,Causality
J. Pearl,Causality. Cambridge university press, 2009. 6
2009
-
[39]
Counterfactual fairness,
M. J. Kusner, J. Loftus, C. Russell, and R. Silva, “Counterfactual fairness,”Advances in neural information processing systems, vol. 30,
-
[40]
Degae: A new pretraining paradigm for low-level vision,
Y . Liu, J. He, J. Gu, X. Kong, and C. Dong, “Degae: A new pretraining paradigm for low-level vision,”Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, pp. 23 292–23 303, 2023. 6
2023
-
[41]
Blind image quality assessment based on geometric order learning,
N.-H. Shin, S.-H. Lee, and C.-S. Kim, “Blind image quality assessment based on geometric order learning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 12 799–12 808. 7
2024
-
[42]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 770–778. 8
2016
-
[43]
Perceptual losses for real-time style transfer and super-resolution,
J. Johnson, A. Alahi, and L. Fei-Fei, “Perceptual losses for real-time style transfer and super-resolution,” inEuropean conference on computer vision. Springer, 2016, pp. 694–711. 9
2016
-
[44]
Photo-realistic single image super-resolution using a generative adversarial network,
C. Ledig, L. Theis, F. Husz ´ar, J. Caballero, A. Cunningham, A. Acosta, A. Aitken, A. Tejani, J. Totz, Z. Wanget al., “Photo-realistic single image super-resolution using a generative adversarial network,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 4681–4690. 9
2017
-
[45]
Image-to- image translation with conditional adversarial networks,
M. Tahmid, M. S. Alam, N. Rao, and K. M. A. Ashrafi, “Image-to- image translation with conditional adversarial networks,” in2023 IEEE 9th International Women in Engineering (WIE) Conference on Electrical and Computer Engineering (WIECON-ECE), 2023, pp. 1–5. 9
2023
-
[46]
Most apparent distortion: full- reference image quality assessment and the role of strategy,
E. C. Larson and D. M. Chandler, “Most apparent distortion: full- reference image quality assessment and the role of strategy,”Journal of electronic imaging, vol. 19, no. 1, pp. 011 006–011 006, 2010. 10
2010
-
[47]
Kadid-10k: A large-scale artificially distorted iqa database,
H. Lin, V . Hosu, and D. Saupe, “Kadid-10k: A large-scale artificially distorted iqa database,” in2019 Eleventh International Conference on Quality of Multimedia Experience (QoMEX). IEEE, 2019, pp. 1–3. 10
2019
-
[48]
Pipal: a large-scale image quality assessment dataset for perceptual im- age restoration,
G. Jinjin, C. Haoming, C. Haoyu, Y . Xiaoxing, J. S. Ren, and D. Chao, “Pipal: a large-scale image quality assessment dataset for perceptual im- age restoration,” inEuropean conference on computer vision. Springer, 2020, pp. 633–651. 10
2020
-
[49]
Multiscale structural similarity for image quality assessment,
Z. Wang, E. P. Simoncelli, and A. C. Bovik, “Multiscale structural similarity for image quality assessment,” inThe thrity-seventh asilomar conference on signals, systems & computers, 2003, vol. 2. Ieee, 2003, pp. 1398–1402. 10, 11 16
2003
-
[50]
Image information and visual quality,
H. R. Sheikh and A. C. Bovik, “Image information and visual quality,” IEEE Transactions on image processing, vol. 15, no. 2, pp. 430–444,
-
[51]
Vsi: A visual saliency-induced index for perceptual image quality assessment,
L. Zhang, Y . Shen, and H. Li, “Vsi: A visual saliency-induced index for perceptual image quality assessment,”IEEE Transactions on Image processing, vol. 23, no. 10, pp. 4270–4281, 2014. 10, 11
2014
-
[52]
Gradient magnitude similarity deviation: A highly efficient perceptual image quality index,
W. Xue, L. Zhang, X. Mou, and A. C. Bovik, “Gradient magnitude similarity deviation: A highly efficient perceptual image quality index,” IEEE transactions on image processing, vol. 23, no. 2, pp. 684–695,
-
[53]
Perceptual image quality assessment using a normalized laplacian pyramid,
V . Laparra, J. Ball ´e, A. Berardino, and E. P. Simoncelli, “Perceptual image quality assessment using a normalized laplacian pyramid,”Elec- tronic Imaging, vol. 28, pp. 1–6, 2016. 10, 11
2016
-
[54]
Pieapp: Perceptual image- error assessment through pairwise preference,
E. Prashnani, H. Cai, Y . Mostofi, and P. Sen, “Pieapp: Perceptual image- error assessment through pairwise preference,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 1808–1817. 10
2018
-
[55]
Projected distribution loss for image enhancement,
M. Delbracio, H. Talebei, and P. Milanfar, “Projected distribution loss for image enhancement,” in2021 IEEE International Conference on Computational Photography (ICCP). IEEE, 2021, pp. 1–12. 10, 11
2021
-
[56]
Locally adaptive struc- ture and texture similarity for image quality assessment,
K. Ding, Y . Liu, X. Zou, S. Wang, and K. Ma, “Locally adaptive struc- ture and texture similarity for image quality assessment,” inProceedings of the 29th ACM International Conference on multimedia, 2021, pp. 2483–2491. 10, 11
2021
-
[57]
Decoupled Weight Decay Regularization
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” arXiv preprint arXiv:1711.05101, 2017. 9
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[58]
Study of subjective and objective quality assessment of infrared compressed images,
O. Zelmati, B. Bond ˇzuli´c, B. Pavlovi´c, I. Tot, and S. Merrouche, “Study of subjective and objective quality assessment of infrared compressed images,”Journal of Electrical Engineering, vol. 73, no. 2, pp. 73–87,
-
[59]
Comprehensive quality assessment method for neutron radiographic im- ages based on cnn and visual salience,
Z. Zhang, C.-B. Meng, X.-L. Jiang, C.-Y . Zhao, S. Qiao, and T. Zhang, “Comprehensive quality assessment method for neutron radiographic im- ages based on cnn and visual salience,”Nuclear Science and Techniques, vol. 36, no. 7, p. 118, 2025. 10, 11
2025
-
[60]
Scid: A database for screen content images quality assessment,
Z. Ni, L. Ma, H. Zeng, Y . Fu, L. Xing, and K.-K. Ma, “Scid: A database for screen content images quality assessment,” in2017 International Symposium on Intelligent Signal Processing and Communication Sys- tems (ISPACS). IEEE, 2017, pp. 774–779. 10, 11
2017
-
[61]
Cnn-based medical ultrasound image quality assessment,
S. Zhang, Y . Wang, J. Jiang, J. Dong, W. Yi, and W. Hou, “Cnn-based medical ultrasound image quality assessment,”Complexity, vol. 2021, no. 1, p. 9938367, 2021. 10, 11
2021
-
[62]
Construction of the hyper- spectral image distortion evaluation index for low altitude uavs,
Q. Zhao, H. Liu, W. Tian, and X. Wang, “Construction of the hyper- spectral image distortion evaluation index for low altitude uavs,”Trans. Chin. Soc. Agric. Eng, vol. 20, pp. 67–76, 2022. 11
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.