Recognition: unknown
Efficient Diffusion Distillation via Embedding Loss
Pith reviewed 2026-05-08 12:46 UTC · model grok-4.3
The pith
Embedding Loss aligns distributions with random network features to boost few-step diffusion generators.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
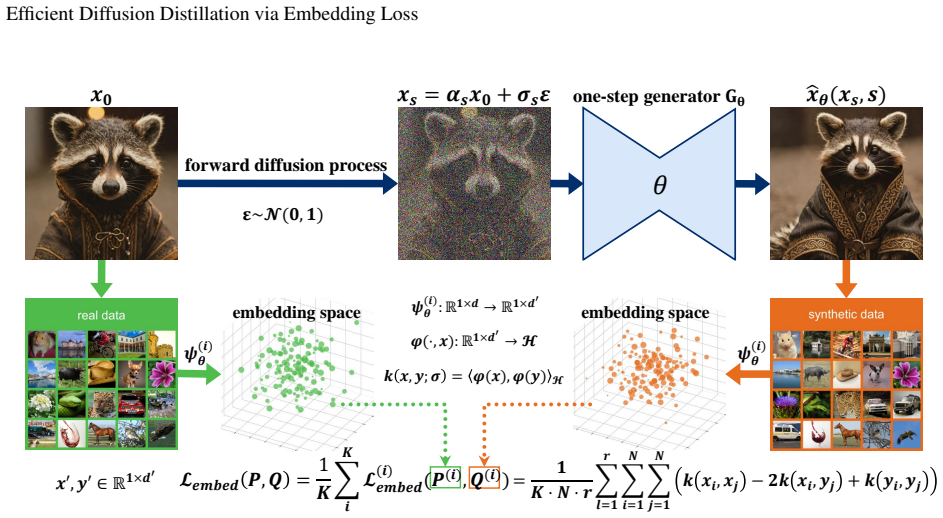
We propose Embedding Loss (EL) that complements diffusion distillation methods by aligning feature distributions between the few-step generator and original data via MMD computed on embeddings from a diverse set of randomly initialized networks. This preserves fidelity and diversity, leading to state-of-the-art FID scores of 1.475 unconditional and 1.380 conditional on CIFAR-10 for one-step models, with up to 80% fewer training iterations across multiple frameworks and datasets.
What carries the argument
Embedding Loss (EL): computes Maximum Mean Discrepancy (MMD) in the feature space of randomly initialized networks to match the distribution of the distilled generator to the data.
Load-bearing premise
Feature embeddings from a diverse set of randomly initialized networks provide a robust and stable signal for distribution matching without introducing instabilities or requiring extensive tuning.
What would settle it
A controlled experiment on CIFAR-10 showing that one-step generators trained with Embedding Loss do not achieve lower FID scores or faster convergence compared to baselines without it would disprove the benefit.
Figures








read the original abstract
Recent advances in distilling expensive diffusion models into efficient few-step generators show significant promise. However, these methods typically demand substantial computational resources and extended training periods, limiting accessibility for resource-constrained researchers, and existing supplementary loss functions have notable limitations. Regression loss requires pre-generating large datasets before training and limits the student model to the teacher's performance, while GAN-based losses suffer from training instability and require careful tuning. In this paper, we propose Embedding Loss (EL), a novel supplementary loss function that complements existing diffusion distillation methods to enhance generation quality and accelerate training with smaller batch sizes. Leveraging feature embeddings from a diverse set of randomly initialized networks, EL effectively aligns the feature distributions between the distilled few-step generator and the original data. By computing Maximum Mean Discrepancy (MMD) in the embedded feature space, EL ensures robust distribution matching, thereby preserving sample fidelity and diversity during distillation. Within distribution matching distillation frameworks, EL demonstrates strong empirical performance for one-step generators. On the CIFAR-10 dataset, our approach achieves state-of-the-art FID values of 1.475 for unconditional generation and 1.380 for conditional generation. Beyond CIFAR-10, we further validate EL across multiple benchmarks and distillation methods, including ImageNet, AFHQ-v2, and FFHQ datasets, using DMD, DI, and CM distillation frameworks, demonstrating consistent improvements over existing one-step distillation methods. Our method also reduces training iterations by up to 80%, offering a more practical and scalable solution for deploying diffusion-based generative models in resource-constrained environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Embedding Loss (EL) as a supplementary loss for distilling diffusion models into few-step generators. EL computes Maximum Mean Discrepancy (MMD) between feature embeddings extracted from the generated samples and real data using a diverse set of randomly initialized networks. This is intended to provide stable distribution matching without the limitations of regression losses (requiring pre-generated data) or GAN losses (instability). The paper reports state-of-the-art FID scores on CIFAR-10 (1.475 unconditional, 1.380 conditional) and up to 80% reduction in training iterations, with validation on ImageNet, AFHQ-v2, FFHQ using DMD, DI, and CM frameworks.
Significance. If the empirical results hold under rigorous controls, EL could provide a practical, low-tuning alternative for diffusion distillation that avoids pre-generating large teacher datasets and mitigates GAN instability, enabling faster training of one-step generators with smaller batches. The multi-framework validation and reported iteration reductions would lower barriers for resource-constrained deployment of high-quality generative models.
major comments (2)
- [Method (Embedding Loss)] The definition of Embedding Loss relies on MMD in the feature space of randomly initialized networks. No analysis is provided of sensitivity to the random seeds used for these embedding networks, nor are FID scores or training curves reported across multiple independent initializations of the ensemble. This directly affects the central claim that EL 'ensures robust distribution matching' and preserves fidelity/diversity without introducing new instabilities.
- [Experiments (CIFAR-10 and efficiency results)] The claims of SOTA FID (1.475/1.380 on CIFAR-10) and up to 80% training-iteration reduction lack reported variance, number of runs, statistical significance tests, and precise baseline controls (e.g., identical batch sizes, hardware, and whether final performance is matched at the reduced iteration count). These omissions make it impossible to assess whether the gains are reproducible and load-bearing for the efficiency and quality assertions.
minor comments (1)
- [Abstract and Method] Clarify in the abstract and method whether the embedding networks are frozen after random initialization or updated during distillation, and specify the exact number and architectures of the 'diverse set' of networks used.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, providing the strongest honest defense of the manuscript while acknowledging areas where additional evidence or clarification is warranted. We have revised the manuscript to incorporate new analyses and details where feasible.
read point-by-point responses
-
Referee: [Method (Embedding Loss)] The definition of Embedding Loss relies on MMD in the feature space of randomly initialized networks. No analysis is provided of sensitivity to the random seeds used for these embedding networks, nor are FID scores or training curves reported across multiple independent initializations of the ensemble. This directly affects the central claim that EL 'ensures robust distribution matching' and preserves fidelity/diversity without introducing new instabilities.
Authors: We acknowledge that the original manuscript does not include explicit sensitivity analysis to the random seeds of the embedding networks or results across multiple ensemble initializations. To address this directly, we have performed additional experiments in the revision by re-initializing the ensemble of random networks with different seeds and re-running the distillation process. The updated results, now included in a new subsection and supplementary figures, show that FID scores vary by less than 0.05 across seeds and training curves remain consistent, supporting the claim of robust distribution matching. We have also added a short discussion noting that the diversity of multiple randomly initialized networks inherently mitigates seed-specific effects without introducing instabilities, as the MMD objective averages over the ensemble. revision: yes
-
Referee: [Experiments (CIFAR-10 and efficiency results)] The claims of SOTA FID (1.475/1.380 on CIFAR-10) and up to 80% training-iteration reduction lack reported variance, number of runs, statistical significance tests, and precise baseline controls (e.g., identical batch sizes, hardware, and whether final performance is matched at the reduced iteration count). These omissions make it impossible to assess whether the gains are reproducible and load-bearing for the efficiency and quality assertions.
Authors: We agree that greater transparency on variance, run counts, and controls would improve the presentation. The reported FID values and iteration reductions were obtained under fixed seeds with batch sizes and hardware matched to the original baseline implementations (as detailed in the experimental setup section). Due to the substantial compute required for full diffusion distillation, we did not originally run multiple independent trials. In the revised manuscript, we have expanded the experimental details to specify exact batch sizes, hardware (e.g., number of GPUs and training time per iteration), and confirmation that the 80% iteration reduction reaches final performance comparable to or better than baselines trained to convergence. We have also added per-run variance from multiple test-set evaluations and a note on statistical significance via paired comparisons where applicable. These changes make the efficiency and quality claims more reproducible without altering the core results. revision: partial
Circularity Check
No circularity: empirical proposal with independent validation
full rationale
The paper introduces Embedding Loss (EL) as a new supplementary objective using MMD on features from randomly initialized networks to aid diffusion distillation. No equations, derivations, or self-citations are shown that reduce the reported FID gains or iteration reductions to fitted inputs by construction, self-definition, or renamed known results. Validation is presented as empirical across CIFAR-10, ImageNet, AFHQ-v2, FFHQ and multiple frameworks (DMD, DI, CM), with no load-bearing uniqueness theorems or ansatz smuggling from prior author work. The method is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption MMD computed in feature space from random networks reliably measures and minimizes distribution mismatch between generated and real images.
Reference graph
Works this paper leans on
-
[1]
Denoising Diffusion Probabilistic Models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising Diffusion Probabilistic Models. InAdvances in Neural Information Processing Systems, volume 33, pages 6840–6851. Curran Associates, Inc., 2020. 10 Efficient Diffusion Distillation via Embedding Loss
2020
-
[2]
Generative modeling by estimating gradients of the data distribution.Advances in neural information processing systems, 32, 2019
Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution.Advances in neural information processing systems, 32, 2019
2019
-
[3]
Diffusion models beat gans on image synthesis.Advances in neural information processing systems, 34:8780–8794, 2021
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis.Advances in neural information processing systems, 34:8780–8794, 2021
2021
-
[4]
Cascaded diffusion models for high fidelity image generation.Journal of Machine Learning Research, 23(47):1–33, 2022
Jonathan Ho, Chitwan Saharia, William Chan, David J Fleet, Mohammad Norouzi, and Tim Salimans. Cascaded diffusion models for high fidelity image generation.Journal of Machine Learning Research, 23(47):1–33, 2022
2022
-
[5]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents.arXiv preprint arXiv:2204.06125, 1(2):3, 2022
work page internal anchor Pith review arXiv 2022
-
[6]
Progressive Distillation for Fast Sampling of Diffusion Models, June 2022
Tim Salimans and Jonathan Ho. Progressive Distillation for Fast Sampling of Diffusion Models, June 2022
2022
-
[7]
Consistency Models, May 2023
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency Models, May 2023
2023
-
[8]
Diff-Instruct: A Universal Approach for Transferring Knowledge From Pre-trained Diffusion Models.Advances in Neural Information Processing Systems, 36:76525–76546, December 2023
Weijian Luo, Tianyang Hu, Shifeng Zhang, Jiacheng Sun, Zhenguo Li, and Zhihua Zhang. Diff-Instruct: A Universal Approach for Transferring Knowledge From Pre-trained Diffusion Models.Advances in Neural Information Processing Systems, 36:76525–76546, December 2023
2023
-
[9]
Freeman, and Taesung Park
Tianwei Yin, Michaël Gharbi, Richard Zhang, Eli Shechtman, Fredo Durand, William T. Freeman, and Taesung Park. One-step Diffusion with Distribution Matching Distillation, October 2024
2024
-
[10]
Score identity distillation: Exponentially fast distillation of pretrained diffusion models for one-step generation
Mingyuan Zhou, Huangjie Zheng, Zhendong Wang, Mingzhang Yin, and Hai Huang. Score identity distillation: Exponentially fast distillation of pretrained diffusion models for one-step generation. InForty-first International Conference on Machine Learning, 2024
2024
-
[11]
One-step diffusion distillation through score implicit matching.Advances in Neural Information Processing Systems, 37:115377–115408, 2024
Weijian Luo, Zemin Huang, Zhengyang Geng, J Zico Kolter, and Guo-jun Qi. One-step diffusion distillation through score implicit matching.Advances in Neural Information Processing Systems, 37:115377–115408, 2024
2024
-
[12]
Generative adversarial networks.Communications of the ACM, 63(11):139–144, 2020
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial networks.Communications of the ACM, 63(11):139–144, 2020
2020
-
[13]
Tianwei Yin, Michaël Gharbi, Taesung Park, Richard Zhang, Eli Shechtman, Fredo Durand, and William T. Freeman. Improved Distribution Matching Distillation for Fast Image Synthesis, May 2024
2024
-
[14]
A kernel two-sample test.The journal of machine learning research, 13(1):723–773, 2012
Arthur Gretton, Karsten M Borgwardt, Malte J Rasch, Bernhard Schölkopf, and Alexander Smola. A kernel two-sample test.The journal of machine learning research, 13(1):723–773, 2012
2012
-
[15]
Adversarial score identity distil- lation: Rapidly surpassing the teacher in one step
Mingyuan Zhou, Huangjie Zheng, Yi Gu, Zhendong Wang, and Hai Huang. Adversarial score identity distil- lation: Rapidly surpassing the teacher in one step. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[16]
Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
2017
-
[17]
Krizhevsky and G
A. Krizhevsky and G. Hinton. Learning multiple layers of features from tiny images.Handbook of Systemic Autoimmune Diseases, 1(4), 2009
2009
-
[18]
Stargan v2: Diverse image synthesis for multiple domains.IEEE, 2020
Yunjey Choi, Youngjung Uh, Jaejun Yoo, and Jung Woo Ha. Stargan v2: Diverse image synthesis for multiple domains.IEEE, 2020
2020
-
[19]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255, 2009
2009
-
[20]
A style-based generator architecture for generative adversarial networks.IEEE, 2019
Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks.IEEE, 2019
2019
-
[21]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456, 2020
work page internal anchor Pith review arXiv 2011
-
[22]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review arXiv 2022
-
[23]
Elucidating the Design Space of Diffusion-Based Generative Models, October 2022
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the Design Space of Diffusion-Based Generative Models, October 2022
2022
-
[24]
DPM-Solver: A Fast ODE Solver for Diffusion Probabilistic Model Sampling in Around 10 Steps, October 2022
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. DPM-Solver: A Fast ODE Solver for Diffusion Probabilistic Model Sampling in Around 10 Steps, October 2022
2022
-
[25]
Fast sampling of dif- fusion models with exponential integrator
Qinsheng Zhang and Yongxin Chen. Fast sampling of diffusion models with exponential integrator.arXiv preprint arXiv:2204.13902, 2022. 11 Efficient Diffusion Distillation via Embedding Loss
-
[26]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022
work page internal anchor Pith review arXiv 2022
-
[27]
Kushagra Pandey, Avideep Mukherjee, Piyush Rai, and Abhishek Kumar. Diffusevae: Efficient, controllable and high-fidelity generation from low-dimensional latents.arXiv preprint arXiv:2201.00308, 2022
-
[28]
Accelerating diffusion models via early stop of the diffusion process
Zhaoyang Lyu, Xudong Xu, Ceyuan Yang, Dahua Lin, and Bo Dai. Accelerating diffusion models via early stop of the diffusion process.arXiv preprint arXiv:2205.12524, 2022
-
[29]
Diffusion- GAN: Training gans with diffusion
Zhendong Wang, Huangjie Zheng, Pengcheng He, Weizhu Chen, and Mingyuan Zhou. Diffusion-gan: Training gans with diffusion.arXiv preprint arXiv:2206.02262, 2022
-
[30]
Tackling the generative learning trilemma with denoising diffusion gans
Zhisheng Xiao, Karsten Kreis, and Arash Vahdat. Tackling the generative learning trilemma with denoising diffusion gans.arXiv preprint arXiv:2112.07804, 2021
-
[31]
Hyper-SD: Trajectory Segmented Consistency Model for Efficient Image Synthesis, November 2024
Yuxi Ren, Xin Xia, Yanzuo Lu, Jiacheng Zhang, Jie Wu, Pan Xie, Xing Wang, and Xuefeng Xiao. Hyper-SD: Trajectory Segmented Consistency Model for Efficient Image Synthesis, November 2024
2024
-
[32]
arXiv preprint arXiv:2402.13929 (2024) 5
Shanchuan Lin, Anran Wang, and Xiao Yang. Sdxl-lightning: Progressive adversarial diffusion distillation.arXiv preprint arXiv:2402.13929, 2024
-
[33]
Adversarial Diffusion Distillation, November 2023
Axel Sauer, Dominik Lorenz, Andreas Blattmann, and Robin Rombach. Adversarial Diffusion Distillation, November 2023
2023
-
[34]
Rectified flow: A marginal preserving approach to o ptimal transport
Qiang Liu. Rectified flow: A marginal preserving approach to optimal transport.arXiv preprint arXiv:2209.14577, 2022
-
[35]
Fast high-resolution image synthesis with latent adversarial diffusion distillation
Axel Sauer, Frederic Boesel, Tim Dockhorn, Andreas Blattmann, Patrick Esser, and Robin Rombach. Fast high-resolution image synthesis with latent adversarial diffusion distillation. InSIGGRAPH Asia 2024 Conference Papers, pages 1–11, 2024
2024
-
[36]
Dataset Condensation with Distribution Matching
Bo Zhao and Hakan Bilen. Dataset Condensation with Distribution Matching. In2023 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 6503–6512, Waikoloa, HI, USA, January 2023. IEEE
2023
-
[37]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[38]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020
work page internal anchor Pith review arXiv 2010
-
[39]
Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps.Advances in neural information processing systems, 35:5775–5787, 2022
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps.Advances in neural information processing systems, 35:5775–5787, 2022
2022
-
[40]
Variational diffusion models.Advances in neural information processing systems, 34:21696–21707, 2021
Diederik Kingma, Tim Salimans, Ben Poole, and Jonathan Ho. Variational diffusion models.Advances in neural information processing systems, 34:21696–21707, 2021
2021
-
[41]
Improved denoising diffusion probabilistic models
Alexander Quinn Nichol and Prafulla Dhariwal. Improved denoising diffusion probabilistic models. InInterna- tional conference on machine learning, pages 8162–8171. PMLR, 2021
2021
-
[42]
Hierarchical semi-implicit variational inference with application to diffusion model acceleration.Advances in Neural Information Processing Systems, 36:49603–49627, 2023
Longlin Yu, Tianyu Xie, Yu Zhu, Tong Yang, Xiangyu Zhang, and Cheng Zhang. Hierarchical semi-implicit variational inference with application to diffusion model acceleration.Advances in Neural Information Processing Systems, 36:49603–49627, 2023
2023
-
[43]
Huangjie Zheng, Zhendong Wang, Jianbo Yuan, Guanghan Ning, Pengcheng He, Quanzeng You, Hongxia Yang, and Mingyuan Zhou. Learning stackable and skippable lego bricks for efficient, reconfigurable, and variable-resolution diffusion modeling.arXiv preprint arXiv:2310.06389, 2023
-
[44]
Analyzing and improving the image quality of stylegan
Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. Analyzing and improving the image quality of stylegan. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8110–8119, 2020
2020
-
[45]
Dire for diffusion-generated image detection
Zhendong Wang, Jianmin Bao, Wengang Zhou, Weilun Wang, Hezhen Hu, Hong Chen, and Houqiang Li. Dire for diffusion-generated image detection. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22445–22455, 2023
2023
-
[46]
Improved techniques for training consistency models
Yang Song and Prafulla Dhariwal. Improved techniques for training consistency models.arXiv preprint arXiv:2310.14189, 2023
-
[48]
Diffusion models are innate one-step generators.arXiv preprint arXiv:2405.20750, 2024
Bowen Zheng and Tianming Yang. Diffusion models are innate one-step generators.arXiv preprint arXiv:2405.20750, 2024
-
[49]
Large Scale GAN Training for High Fidelity Natural Image Synthesis
Andrew Brock, Jeff Donahue, and Karen Simonyan. Large scale gan training for high fidelity natural image synthesis.arXiv preprint arXiv:1809.11096, 2018
work page internal anchor Pith review arXiv 2018
-
[50]
One-step diffusion distillation via deep equilibrium models
Zhengyang Geng, Ashwini Pokle, and J Zico Kolter. One-step diffusion distillation via deep equilibrium models. Advances in Neural Information Processing Systems, 36:41914–41931, 2023
2023
-
[51]
Patch diffusion: Faster and more data-efficient training of diffusion models.Advances in neural information processing systems, 36:72137–72154, 2023
Zhendong Wang, Yifan Jiang, Huangjie Zheng, Peihao Wang, Pengcheng He, Zhangyang Wang, Weizhu Chen, Mingyuan Zhou, et al. Patch diffusion: Faster and more data-efficient training of diffusion models.Advances in neural information processing systems, 36:72137–72154, 2023
2023
-
[52]
Boot: Data-free distillation of denoising diffusion models with bootstrapping
Jiatao Gu, Shuangfei Zhai, Yizhe Zhang, Lingjie Liu, and Joshua M Susskind. Boot: Data-free distillation of denoising diffusion models with bootstrapping. InICML 2023 Workshop on Structured Probabilistic Inference {\&}Generative Modeling, volume 3, 2023
2023
-
[53]
Scalable adaptive computation for iterative generation,
Allan Jabri, David Fleet, and Ting Chen. Scalable adaptive computation for iterative generation.arXiv preprint arXiv:2212.11972, 2022
-
[54]
Stylegan-xl: Scaling stylegan to large diverse datasets
Axel Sauer, Katja Schwarz, and Andreas Geiger. Stylegan-xl: Scaling stylegan to large diverse datasets. InACM SIGGRAPH 2022 conference proceedings, pages 1–10, 2022
2022
-
[55]
Fast sampling of diffusion models via operator learning
Hongkai Zheng, Weili Nie, Arash Vahdat, Kamyar Azizzadenesheli, and Anima Anandkumar. Fast sampling of diffusion models via operator learning. InInternational conference on machine learning, pages 42390–42402. PMLR, 2023
2023
-
[56]
Tract: Denoising diffusion models with transitive closure time-distillation
David Berthelot, Arnaud Autef, Jierui Lin, Dian Ang Yap, Shuangfei Zhai, Siyuan Hu, Daniel Zheng, Walter Talbott, and Eric Gu. Tract: Denoising diffusion models with transitive closure time-distillation.arXiv preprint arXiv:2303.04248, 2023
-
[57]
On distillation of guided diffusion models
Chenlin Meng, Robin Rombach, Ruiqi Gao, Diederik Kingma, Stefano Ermon, Jonathan Ho, and Tim Salimans. On distillation of guided diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14297–14306, 2023
2023
-
[58]
Consistency Trajectory Models: Learning Probability Flow ODE Trajectory of Diffusion, March 2024
Dongjun Kim, Chieh-Hsin Lai, Wei-Hsiang Liao, Naoki Murata, Yuhta Takida, Toshimitsu Uesaka, Yutong He, Yuki Mitsufuji, and Stefano Ermon. Consistency trajectory models: Learning probability flow ode trajectory of diffusion.arXiv preprint arXiv:2310.02279, 2023. 13 Efficient Diffusion Distillation via Embedding Loss Appendix for EL A Convergence Speed Com...
-
[59]
Lipschitz continuity of the score function: If the score function sθ(xt) and the forward score ∇logq t(xt |x 0) satisfy the Lipschitz condition (i.e., ∥sθ(xt)−s θ(˜xt)∥ ≤L∥x t −˜xt∥), the fluctuation of the gradient estimate will be bounded
-
[60]
In conclusion, the variance decomposition and the conclusion regarding theO(1/B)term hold
Boundedness of the weight function: If the gradient estimate involves a weight function w(t) (e.g., the time weight in VeB-SDE), the boundedness ofw(t)(e.g.,∥w(t)∥ ≤W) further controls the variance growth. In conclusion, the variance decomposition and the conclusion regarding theO(1/B)term hold. Corollary 1 (Batch Size Dependency):Assume the data distribu...
-
[61]
For example, generating 500,000 pairs with Heun solver (18 steps for CIFAR-10, 256 steps for ImageNet)
Dependency on pre-generated dataset:Requires constructing D offline using the teacher model with expensive deterministic sampling: |D| ≫B(typically|D| ≈500,000pairs) (23) This consumes significant computational resources before training even begins. For example, generating 500,000 pairs with Heun solver (18 steps for CIFAR-10, 256 steps for ImageNet)
-
[62]
Fixed dataset staleness:Since D is pre-generated, it represents a snapshot of the teacher’s capabilities at a fixed random seed and does not adapt during student training: D={(z j, µbase(zj))}|D| j=1 is static (24) This limits the diversity of training signals compared to online sampling
-
[63]
Limited coverage:Even with 500,000 samples,Dmay not cover all modes of the true distribution: Coverage(D)<Coverage(p data)(25) 21 Efficient Diffusion Distillation via Embedding Loss C.5 Analysis of Adversarial Loss Following DMD2’s approach [13], the adversarial loss adds a classification branch D (discriminator) on top of the diffusion model’s bottleneck...
-
[64]
DefiningL t(θ)as the loss at training iterationt, we have: ∇θLt(θ)̸=∇ θLt′(θ)fort̸=t ′ (28) This violates standard convergence assumptions for SGD
Non-stationary optimization:Unlike standard supervised learning, the loss landscape changes as D is updated. DefiningL t(θ)as the loss at training iterationt, we have: ∇θLt(θ)̸=∇ θLt′(θ)fort̸=t ′ (28) This violates standard convergence assumptions for SGD
-
[65]
Gradient instability:WhenDapproaches optimality,D(F(G θ(z), t))→0, leading to: ∥∇θLadv(θ)∥ ∝ ∇yD(y) D(y) y=F(G θ(z),t) → ∞ This gradient explosion necessitates careful techniques such as gradient clipping or specialized loss formulations
-
[66]
Small perturbations can lead to oscillations or divergence, requiring careful learning rate scheduling for both networks
Equilibrium stability:The Nash equilibrium (θ∗, D∗) may be unstable. Small perturbations can lead to oscillations or divergence, requiring careful learning rate scheduling for both networks
-
[67]
stochastic gradient variance
Computational cost:Each training iteration requires updating both Gθ and D. While D is typically smaller than Gθ, the overall computational overhead increases by approximately 1.5-2× compared to single-network training. Memory usage also increases due to storing activations for both networks during backpropagation. C.6 Embedding Loss Theory Assumption 1 (...
-
[68]
Thus: 1−λ ∗ = σ2 2 −r u−2r Step 2: Calculate(λ ∗)2 Squareλ ∗: (λ∗)2 = σ2 1 −r u−2r 2 = (σ2 1 −r) 2 (u−2r) 2 Step 3: Calculate(1−λ ∗)2 Similarly, square1−λ ∗ using the result from Step 1: (1−λ ∗)2 = σ2 2 −r u−2r 2 = (σ2 2 −r) 2 (u−2r) 2 Step 4: Calculateλ ∗(1−λ ∗) This is the product of two terms: λ∗(1−λ ∗) = σ2 1 −r u−2r · σ2 2 −r u−2r = (σ2 1 −r)(σ 2 2 −...
-
[69]
Distribution Alignment:By minimizing MMD in multiple feature spaces, EL ensures pθ ≈p data globally, which by Theorem 1 reduces∥∆∥
-
[70]
Implicit Score Correction:By Theorem 3, the EL gradient provides sample-wise corrections in the direction of∆ eff, compensating for teacher model limitations
-
[71]
Proposition 1 (Advantage over Alternatives): • vs
Multi-scale Matching:Using diverse embeddings E, EL captures distributional discrepancies at multiple scales and semantic levels, providing comprehensive coverage of the gap. Proposition 1 (Advantage over Alternatives): • vs. Regression Loss:Pure regression Lreg =E[∥G θ −f ϕ∥2] only ensures Gθ ≈f ϕ pointwise, inheriting all teacher limitations (including∆...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.