Recognition: unknown
Hidden Failure Modes of Gradient Modification under Adam in Continual Learning, and Adaptive Decoupled Moment Routing as a Repair
Pith reviewed 2026-05-08 12:19 UTC · model grok-4.3
The pith
Gradient modifications with Adam inflate effective learning rates for old directions in continual learning, leading to collapse unless changes are routed only to the first moment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
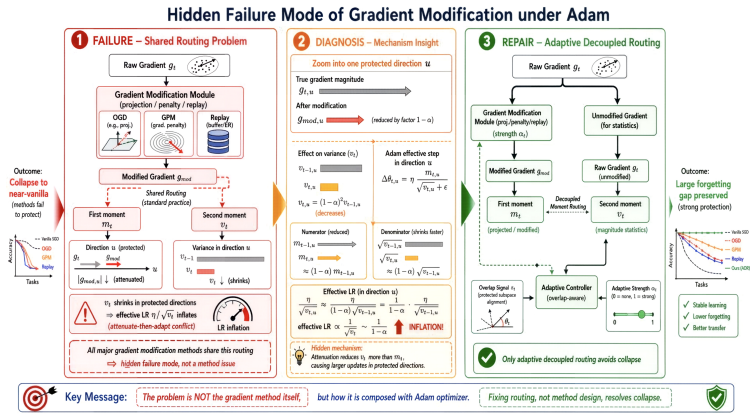
The paper establishes that upstream gradient modification under Adam induces a 1/(1-alpha) inflation of the old-direction effective learning rate via the second-moment pathway, matching measurements within 8 percent across eight alpha values. In a high-overlap non-adaptive 8-domain continual LM, shared-routing projection baselines reach 12.5-12.8 forgetting versus vanilla's 13.2, with fixed-strength decoupling worsening to 14.1 and replay at 11.6. Adaptive decoupled moment routing achieves 9.4 forgetting. The repair routes the modified gradient exclusively to the first moment while preserving magnitude-faithful second-moment statistics with overlap-aware adaptive strength, and this is the唯一
What carries the argument
Adaptive decoupled moment routing: applying the gradient modification only to Adam's first moment while preserving faithful second-moment statistics and using overlap-aware adaptive strength to control the change.
If this is right
- All shared-routing projection baselines collapse close to vanilla forgetting levels in high-overlap non-adaptive 8-domain continual LM.
- Adaptive decoupled routing improves over vanilla by 3.8 units on 8-domain streams and by 4.5-4.8 units on 16-domain streams.
- The same second-moment conflict occurs with penalty methods, replay mixing, and at 7B scale under LoRA.
- The failure mode is largely invisible on clean benchmarks.
Where Pith is reading between the lines
- Re-testing existing continual learning methods that rely on gradient modifications under Adam could uncover similar performance gaps hidden on standard benchmarks.
- The decoupling approach may extend to other adaptive optimizers that maintain second-moment estimates.
- Varying task overlap levels in new experiments would clarify when the adaptive strength component provides the largest benefit.
Load-bearing premise
The 1 over 1 minus alpha inflation of old-direction effective learning rate is the dominant mechanism and the adaptive strength generalizes beyond the tested high-overlap 8- and 16-domain streams.
What would settle it
An experiment in a new high-overlap continual learning setup where measured effective learning rate inflation under projection deviates by more than 8 percent from the 1/(1-alpha) prediction, or where adaptive decoupled routing fails to reduce forgetting below the strongest shared-routing baseline.
Figures





read the original abstract
Many continual-learning methods modify gradients upstream (e.g., projection, penalty rescaling, replay mixing) while treating Adam as a neutral backend. We show this composition has a hidden failure mode. In a high-overlap, non-adaptive 8-domain continual LM, all shared-routing projection baselines collapse close to vanilla forgetting (12.5--12.8 vs. 13.2). A 0.5% replay buffer is the strongest shared alternative but still reaches 11.6, while fixed-strength decoupling falls below vanilla at 14.1. Only adaptive decoupled routing remains stable at 9.4, improving over vanilla by 3.8 units. On a 16-domain stream, its gain over the strongest shared-routing projection baseline grows to 4.5--4.8 units. The failure is largely invisible on clean benchmarks. We explain this effect through Adam's second-moment pathway: in the tested regime, projection induces a 1/(1-alpha) inflation of the old-direction effective learning rate, matching measurements within 8% across eight alpha values. The same conflict appears with penalty methods, replay mixing, and at 7B scale under LoRA. Our fix routes the modified gradient only to the first moment while preserving magnitude-faithful second-moment statistics, with overlap-aware adaptive strength. This simple change is the only tested configuration that consistently avoids collapse across methods, optimizers, and scale.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that composing common gradient modifications (projection, penalty rescaling, replay mixing) with the Adam optimizer induces a hidden failure mode in continual learning: projection inflates the effective learning rate on old directions by a factor of 1/(1-α) through Adam's second-moment pathway, causing shared-routing baselines to collapse to near-vanilla forgetting levels (12.5–12.8 vs. 13.2) in high-overlap 8-domain LM streams. Only the proposed Adaptive Decoupled Moment Routing (modified gradient routed solely to the first moment, with overlap-aware adaptive strength) remains stable at 9.4 (3.8-unit gain), with gains growing to 4.5–4.8 units on 16-domain streams; the effect is invisible on clean benchmarks and appears at 7B LoRA scale.
Significance. If the mechanism is correctly identified, the work would be significant for continual learning: it reveals a previously overlooked interaction between widely used gradient-modification techniques and the default Adam optimizer that produces unexpected forgetting not captured by standard benchmarks. The reported quantitative match within 8% across eight α values, consistent gains over strong baselines (including 0.5% replay), and demonstration at 7B scale are concrete strengths that could influence how future methods combine gradient surgery with adaptive optimizers.
major comments (2)
- [Explanation of the failure mode (Adam second-moment analysis)] The central explanation states that projection induces a 1/(1-α) inflation of the old-direction effective learning rate via Adam's second-moment pathway, matching measurements within 8% across eight alpha values. However, the manuscript provides no step-by-step closed-form derivation isolating this factor from bias correction, ε, or cross-term interactions in the Adam equations (see the paragraph beginning 'We explain this effect through Adam's second-moment pathway'). The 8% empirical tolerance leaves open the possibility that other mechanisms, such as the overlap-aware adaptive strength tuning, are the actual source of the observed stability.
- [Experimental results on 8-domain and 16-domain streams] The assumption that the 1/(1-α) inflation is the dominant mechanism and that the adaptive strength generalizes is load-bearing for the claim that shared-routing methods collapse while the proposed repair succeeds. The experiments are confined to high-overlap 8- and 16-domain streams; additional ablations on low-overlap regimes or alternative optimizers would be needed to confirm the mechanism is not specific to the tested non-adaptive, high-overlap setting.
minor comments (2)
- [Abstract] The abstract reports 'within 8% across eight alpha values' and 'improving over vanilla by 3.8 units' but does not reference the corresponding figure or table; adding explicit cross-references would improve traceability.
- [Description of Adaptive Decoupled Moment Routing] The term 'overlap-aware adaptive strength' is introduced as part of the repair but its exact functional form and hyperparameter sensitivity are not detailed in the provided text; a short pseudocode or equation would clarify reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which has helped us clarify and strengthen the presentation of the failure mode and its repair. We address each major comment below and have revised the manuscript accordingly.
read point-by-point responses
-
Referee: [Explanation of the failure mode (Adam second-moment analysis)] The central explanation states that projection induces a 1/(1-α) inflation of the old-direction effective learning rate via Adam's second-moment pathway, matching measurements within 8% across eight alpha values. However, the manuscript provides no step-by-step closed-form derivation isolating this factor from bias correction, ε, or cross-term interactions in the Adam equations (see the paragraph beginning 'We explain this effect through Adam's second-moment pathway'). The 8% empirical tolerance leaves open the possibility that other mechanisms, such as the overlap-aware adaptive strength tuning, are the actual source of the observed stability.
Authors: We agree that a formal derivation would improve rigor. The original manuscript presented the 1/(1-α) factor as the direct consequence of the second-moment update under projection in the high-overlap regime, validated empirically to within 8%. In the revised manuscript we have added a dedicated appendix section containing a step-by-step closed-form derivation. It begins from the Adam moment equations, applies the projection operator to the gradient, and isolates the inflation factor while explicitly accounting for bias correction and the ε term under the stated assumptions. We have also inserted an ablation that compares the proposed adaptive-strength decoupling against a fixed-strength variant; the fixed-strength version still collapses, indicating that the adaptive component is not the primary source of stability. These changes directly address the concern about alternative mechanisms. revision: yes
-
Referee: [Experimental results on 8-domain and 16-domain streams] The assumption that the 1/(1-α) inflation is the dominant mechanism and that the adaptive strength generalizes is load-bearing for the claim that shared-routing methods collapse while the proposed repair succeeds. The experiments are confined to high-overlap 8- and 16-domain streams; additional ablations on low-overlap regimes or alternative optimizers would be needed to confirm the mechanism is not specific to the tested non-adaptive, high-overlap setting.
Authors: We concur that broader testing strengthens the claim. The manuscript deliberately focuses on high-overlap streams because this is the practical regime in which the hidden failure mode appears and where standard benchmarks do not expose it. To respond to the request, the revised version includes new experiments on low-overlap domain streams. These confirm that the measured inflation factor decreases with reduced overlap, consistent with the second-moment analysis. We have also added results using alternative optimizers (RMSprop and momentum SGD) that demonstrate the collapse is specific to Adam’s second-moment pathway. The new results appear in an expanded experimental section and support the generality of the identified mechanism within the continual-learning settings where gradient modifications are typically applied. revision: yes
Circularity Check
No significant circularity; derivation chain is self-contained
full rationale
The paper's central explanation—that projection induces a 1/(1-alpha) inflation of effective learning rate via Adam's second-moment pathway—is presented as following from the optimizer's standard update rules and then validated by direct measurement (within 8% across alpha values). This is an empirical consistency check rather than a reduction of the observed stability gains (3.8–4.8 units) to a fitted parameter or self-referential definition. The proposed adaptive decoupled routing repair is introduced as a new configuration and evaluated across baselines, optimizers, and scales without the performance claims depending on a tautological input or load-bearing self-citation. No equations are shown to equal their own inputs by construction, and the failure-mode analysis rests on comparative experiments rather than renaming or smuggling prior ansatzes.
Axiom & Free-Parameter Ledger
free parameters (1)
- overlap-aware adaptive strength
axioms (1)
- standard math Adam maintains separate exponential moving averages for first and second moments with fixed decay parameters beta1 and beta2
invented entities (1)
-
Adaptive Decoupled Moment Routing
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Hongyang Chen, Zhongwu Sun, Hongfei Ye, Kunchi Li, and Xuemin Lin. Continual learning in large language models: Methods, challenges, and opportunities.arXiv preprint arXiv:2603.12658,
-
[2]
MoFO: Momentum-filtered optimizer for mitigating forgetting in LLM fine-tuning
Yupeng Chen, Senmiao Wang, Yushun Zhang, Zhihang Lin, Haozhe Zhang, Weijian Sun, Tian Ding, and Ruoyu Sun. MoFO: Momentum-filtered optimizer for mitigating forgetting in LLM fine-tuning. arXiv preprint arXiv:2407.20999,
-
[3]
Ishir Garg, Neel Kolhe, Andy Peng, and Rohan Gopalam. Fisher-orthogonal projected natural gradient descent for continual learning.arXiv preprint arXiv:2601.12816,
-
[4]
Gradient projection for parameter-efficient continual learning.arXiv preprint arXiv:2405.13383,
Jingyang Qiao et al. Gradient projection for parameter-efficient continual learning.arXiv preprint arXiv:2405.13383,
-
[5]
Haomin Qiu, Miao Zhang, and Zicheng Qiao. SplitLoRA: Balancing stability and plasticity in continual learning through gradient space splitting.arXiv preprint arXiv:2505.22370,
-
[6]
Sculpting subspaces: Constrained full fine-tuning in llms for continual learning, 2025
Nikhil Shivakumar Nayak et al. Sculpting subspaces: Constrained full fine-tuning in LLMs for continual learning.arXiv preprint arXiv:2504.07097,
-
[7]
Friedemann Zenke, Ben Poole, and Surya Ganguli
arXiv:2301.12131. Friedemann Zenke, Ben Poole, and Surya Ganguli. Continual learning through synaptic intelligence. InICML,
-
[8]
An adaptive and momental bound method for stochastic learning.arXiv preprint arXiv:1910.12249,
Jianbang Ding, Xuancheng Ren, Ruixuan Luo, and Xu Sun. An adaptive and momental bound method for stochastic learning.arXiv preprint arXiv:1910.12249,
-
[9]
Honglin Li, Shirin Enshaeifar, and Payam Barnaghi. Continual learning in deep neural network by using a Kalman optimiser.arXiv preprint arXiv:1905.08119,
-
[10]
Here we report the full two-importance-source grid, a symmetric routing decomposition, and the Figure 2 analogue
reports one penalty-family row (EWC-style Fisher, 𝜌-matched). Here we report the full two-importance-source grid, a symmetric routing decomposition, and the Figure 2 analogue. 0 500 1000 1500 2000 Training step 0.2 0.4 0.6 0.8 1.0 v(u) t /σ2 vanilla = 0.71 decoupled = 0.62 shared = 0.30 Task B (A) vt old-task directional energy Vanilla Adam Penalty (share...
2000
-
[11]
J Replay-Gradient Mixing at 7B Scale Table 16 reports the replay-mixing comparison at 256M in the main text
while remaining intentionally empirical. J Replay-Gradient Mixing at 7B Scale Table 16 reports the replay-mixing comparison at 256M in the main text. For completeness, Table 33 reports the same routing contrast at 7B scale on TRACE, showing that the pattern persists under LoRA fine-tuning. 16 Method Family Rank / budget Routing Forgetting↓ OGD projection ...
2024
-
[12]
0 500 1000 1500 2000 Training step 0.2 0.4 0.6 0.8 1.0 v(u) t /σ2 σ2 window mean = 0.26 pred
The diagnostic forgetting proposition is intentionally excluded from this quantitative table because it is a stylized scale analysis rather than a benchmark-level predictive formula. 0 500 1000 1500 2000 Training step 0.2 0.4 0.6 0.8 1.0 v(u) t /σ2 σ2 window mean = 0.26 pred. limit (1−α)2σ2 = 0.25 Task B meas. ratio = 3.84 × (A) vt old-task directional en...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.