Distance-Misaligned Training in Graph Transformers and Adaptive Graph-Aware Control
Pith reviewed 2026-05-08 12:14 UTC · model grok-4.3
The pith
An oracle adaptive controller that receives the task's target graph distance nearly matches the best fixed bias and beats neutral baselines on mixed and local tasks in Graph Transformers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
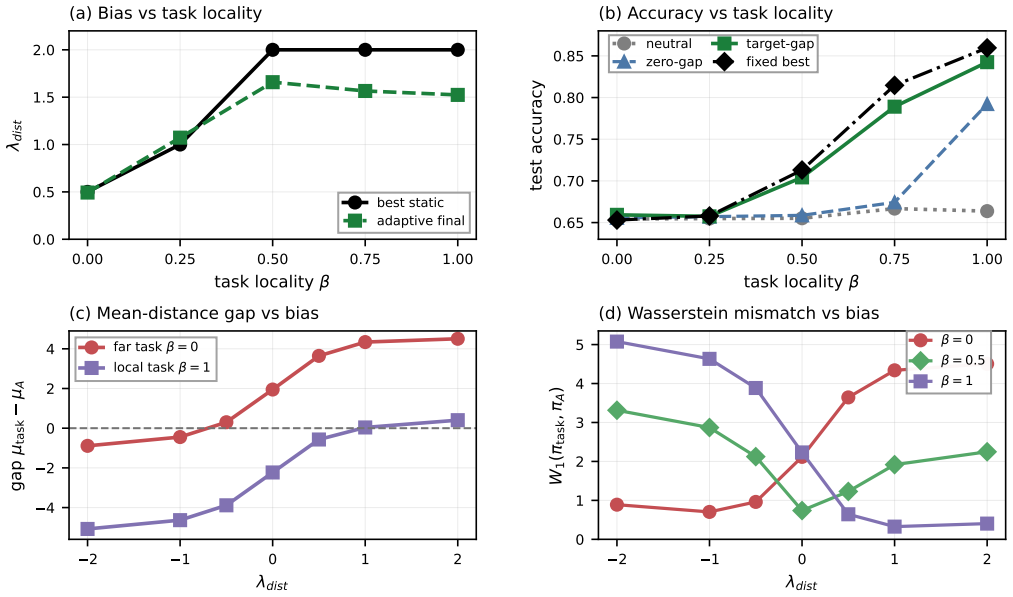
On contextual stochastic block model graphs with labels formed by mixtures of local and far-shell signals, Graph Transformers exhibit distance-misaligned training whenever the model's allocation of attention or message passing fails to match the graph distance that carries the label information. The preferred bias changes systematically with the degree of task locality. An oracle adaptive controller given offline access to the task-side distance target nearly matches the performance of the best fixed bias across regimes and strongly improves over a neutral baseline on mixed and local tasks, whereas a task-agnostic zero-gap controller is weaker.
What carries the argument
Distance-misaligned training, the mismatch between the graph distance containing label-relevant information and the distances at which the Graph Transformer allocates its communication.
If this is right
- The optimal graph-distance bias for a Graph Transformer depends on the locality of the task labels.
- Supplying an adaptive controller with the correct distance target allows performance close to the best fixed setting without manual tuning per regime.
- Adaptation by itself is insufficient; the controller must be given the right target distance rather than a neutral or zero-gap objective.
- Distance-resolved analysis of attention or message passing can diagnose why a Graph Transformer succeeds or fails on a given task.
Where Pith is reading between the lines
- If real-world graphs exhibit similar mixtures of local and long-range label signals, distance-aware controllers could reduce the need for task-specific architecture search.
- The benchmark setup could be extended to measure how distance misalignment interacts with other Graph Transformer components such as positional encodings.
- Controllers that estimate the required distance target from a small labeled subset might remove the need for an oracle while retaining most of the benefit.
Load-bearing premise
The synthetic contextual stochastic block model benchmark with controllable mixtures of local and far-shell signals faithfully reproduces the distance-related failure modes that appear in real Graph Transformer applications.
What would settle it
Measuring whether an adaptive controller that receives the empirical distance at which labels correlate with node features improves Graph Transformer accuracy on real node-classification tasks whose label locality can be quantified in advance.
Figures
read the original abstract
Graph Transformers can mix information globally, but this flexibility also creates failure modes: some tasks require long-range communication while others are better served by local interaction. We study this through a synthetic node-classification benchmark on contextual stochastic block model graphs, where labels are generated by a controllable mixture of local and far-shell signals. We define distance-misaligned training as a mismatch between where label-relevant information lies and where the model allocates communication over graph distance. On this benchmark, we find three points. First, the preferred graph-distance bias changes systematically with task locality. Second, an oracle adaptive controller, given offline access to the task-side distance target, nearly matches the best fixed bias across regimes and strongly improves over a neutral baseline on mixed and local tasks. Third, a task-agnostic zero-gap controller is weaker, indicating that adaptation alone is not enough and that the control target matters. These results suggest that distance-resolved diagnosis is useful for understanding Graph Transformer failures and for designing graph-aware control.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces distance-misaligned training in Graph Transformers and studies it via a synthetic node-classification benchmark on contextual stochastic block model graphs whose labels are generated from controllable mixtures of local and far-shell signals. It reports three empirical observations: preferred graph-distance bias varies systematically with task locality; an oracle adaptive controller given offline access to the task-side distance target nearly matches the best fixed bias across regimes and improves over neutral baselines on mixed and local tasks; and a task-agnostic zero-gap controller is weaker, showing that adaptation alone is insufficient without the correct control target. The work concludes that distance-resolved diagnosis aids understanding of Graph Transformer failures and design of graph-aware control.
Significance. If the synthetic benchmark faithfully reproduces distance-related communication failures that occur in real Graph Transformers, the results would offer a useful diagnostic framework and motivate adaptive control mechanisms that outperform fixed biases on tasks with varying locality. The controllable mixture design is a clear strength, enabling systematic isolation of local versus global signal effects. However, the absence of quantitative results, error bars, or real-world validation in the reported findings limits the strength of the conclusions.
major comments (2)
- [Abstract and Experimental Section] The abstract and experimental claims rest on three empirical points, yet no quantitative results, error bars, statistical tests, or parameter values for the contextual SBM graph and label-mixture generation are supplied; this directly undermines assessment of whether the oracle controller nearly matches the best fixed bias or improves over neutral baselines.
- [Benchmark Design] The central claim that the oracle adaptive controller improvements are diagnostic of Graph Transformer distance-misalignment (rather than benchmark-specific) depends on the unvalidated assumption that controllable local/far-shell label mixtures reproduce actual spectral or attention-pattern failures (e.g., over-smoothing on long-range dependencies); no comparison to real-world graphs or attention maps is provided to support this.
minor comments (2)
- [Abstract] The term 'zero-gap controller' is used without an accompanying definition, equation, or reference to its implementation details.
- [Results] Figure or table captions for the reported controller comparisons should explicitly state the number of runs, random seeds, and exact task-locality parameter settings used.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The comments correctly identify gaps in quantitative reporting and in linking the synthetic benchmark to real-world Graph Transformer behavior. We address both points below and have prepared revisions that incorporate additional numerical results, error bars, and a strengthened discussion of the benchmark's scope.
read point-by-point responses
-
Referee: [Abstract and Experimental Section] The abstract and experimental claims rest on three empirical points, yet no quantitative results, error bars, statistical tests, or parameter values for the contextual SBM graph and label-mixture generation are supplied; this directly undermines assessment of whether the oracle controller nearly matches the best fixed bias or improves over neutral baselines.
Authors: We agree that the absence of concrete numbers, error bars, and parameter specifications in the abstract and experimental description limits evaluability. The revised manuscript will report mean accuracies and standard deviations over 10 random seeds for all controller variants, include p-values from paired t-tests against the neutral baseline, and list all contextual SBM parameters (block sizes, intra/inter-block probabilities, mixture weights for local vs. far-shell label generation, and graph size). These additions will allow direct verification of the reported improvements. revision: yes
-
Referee: [Benchmark Design] The central claim that the oracle adaptive controller improvements are diagnostic of Graph Transformer distance-misalignment (rather than benchmark-specific) depends on the unvalidated assumption that controllable local/far-shell label mixtures reproduce actual spectral or attention-pattern failures (e.g., over-smoothing on long-range dependencies); no comparison to real-world graphs or attention maps is provided to support this.
Authors: The referee is correct that we do not provide direct comparisons to real-world graphs or attention visualizations in the current version. The benchmark is intentionally synthetic to enable precise control over the locality of the label signal, which is its primary strength for isolating distance-misalignment effects. In the revision we will add (i) attention-map heatmaps from the trained models on the synthetic graphs and (ii) a discussion section that relates the observed distance-bias preferences to known over-smoothing and long-range dependency issues reported on citation and molecular graphs. We do not claim the benchmark reproduces every real-world failure mode; rather, it demonstrates that distance-resolved control can be beneficial when the task locality is known. Full-scale experiments on multiple real datasets lie outside the scope of the present study but are noted as future work. revision: partial
Circularity Check
No circularity: empirical observations from defined synthetic benchmark
full rationale
The paper reports three direct observational findings from experiments on a contextual stochastic block model benchmark whose label generation is explicitly defined via controllable local/far-shell mixtures. No equations, first-principles derivations, or predictions are shown that reduce to fitted parameters, self-citations, or quantities defined in terms of the reported results. Distance-misaligned training is introduced as a definition, after which the findings are presented as measurements on the benchmark; the chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, and Tie-Yan Liu. Do Transformers Really Perform Badly for Graph Representation? InAdvances in Neural Information Processing Systems, volume 34, pages 28877–28888. Curran Associates, Inc., 2021
work page 2021
-
[2]
Ladislav Ramp ´aˇsek, Michael Galkin, Vijay Prakash Dwivedi, Anh Tuan Luu, Guy Wolf, and Dominique Beaini. Recipe for a General, Powerful, Scalable Graph Transformer.Advances in Neural Information Processing Systems, 35:14501–14515, 2022
work page 2022
-
[3]
Hongkang Li, Meng Wang, Tengfei Ma, Sijia Liu, Zaixi Zhang, and Pin-Yu Chen. What improves the generalization of graph transformers? a theoretical dive into the self-attention and positional encoding. In Proceedings of the 41st International Conference on Machine Learning, volume 235 ofICML’24, pages 28784–28829. JMLR.org, 2024
work page 2024
-
[4]
Less is More: on the Over-Globalizing Problem in Graph Transformers, 2024
Yujie Xing, Xiao Wang, Yibo Li, Hai Huang, and Chuan Shi. Less is More: on the Over-Globalizing Problem in Graph Transformers, 2024. arXiv:2405.01102 [cs]
-
[5]
Relieving the over-aggregating effect in graph trans- formers
Junshu Sun, Wanxing Chang, Chenxue Yang, Qingming Huang, and Shuhui Wang. Relieving the over-aggregating effect in graph trans- formers. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[6]
A closer look at graph transformers: Cross-aggregation and beyond
Jiaming Zhuo, Ziyi Ma, Yintong Lu, Yuwei Liu, Kun Fu, Di Jin, Chuan Wang, Wenning Wu, Zhen Wang, Xiaochun Cao, and Liang Yang. A closer look at graph transformers: Cross-aggregation and beyond. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[7]
Demystifying oversmoothing in attention-based graph neural networks
Xinyi Wu, Amir Ajorlou, Zihui Wu, and Ali Jadbabaie. Demystifying oversmoothing in attention-based graph neural networks. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors, Advances in Neural Information Processing Systems, volume 36, pages 35084–35106. Curran Associates, Inc., 2023
work page 2023
-
[8]
Gbetondji Jean-Sebastien Dovonon, Michael M. Bronstein, and Matt Kusner. Setting the Record Straight on Transformer Oversmoothing. Transactions on Machine Learning Research, 2024
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.