Recognition: unknown
MetaEarth3D: Unlocking World-scale 3D Generation with Spatially Scalable Generative Modeling
Pith reviewed 2026-05-10 06:36 UTC · model grok-4.3
The pith
MetaEarth3D generates multi-level 3D scenes with spatial consistency across entire planets by treating spatial scale as a core scaling dimension.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
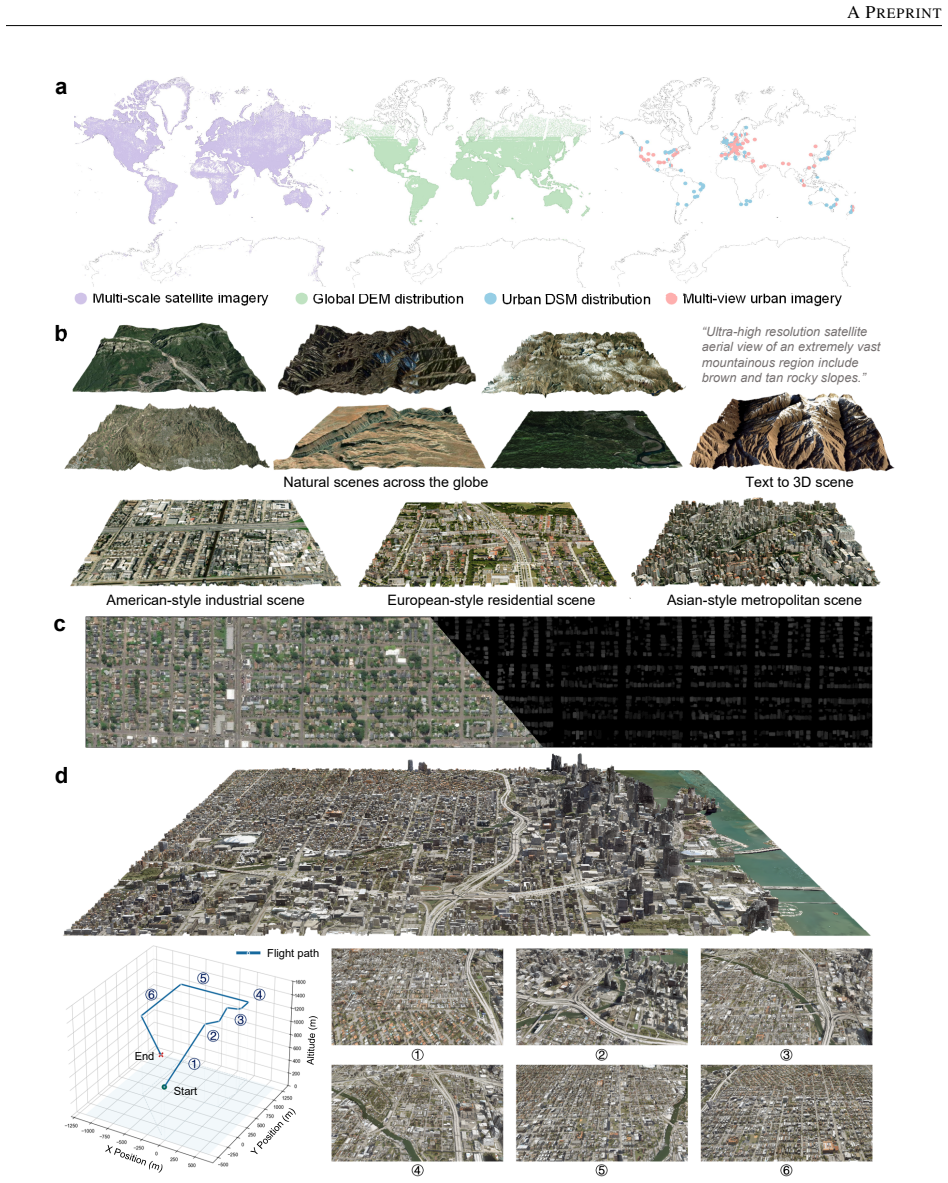
MetaEarth3D is the first generative foundation model capable of spatially consistent generation at the planetary scale. Taking optical Earth observation simulation as a testbed, the model produces multi-level, unbounded, and diverse 3D scenes spanning large-scale terrains, medium-scale cities, and fine-grained street blocks. Built upon 10 million globally distributed real-world training images, it demonstrates both strong visual realism and geospatial statistical realism and functions as a generative data engine for diverse virtual environments in ultra-wide spatial intelligence.
What carries the argument
Spatially scalable generative modeling, which adds spatial extent as a scaling dimension to produce consistent 3D outputs over unbounded geographic ranges.
If this is right
- Enables generation of consistent 3D scenes at any spatial level from planetary down to local without imposed boundaries.
- Produces outputs that match both visual appearance and underlying geospatial statistics from real-world image distributions.
- Functions as a data engine to create virtual environments for ultra-wide-area spatial intelligence applications.
- Demonstrates that spatial scale can be treated as an additional axis alongside model size and data volume in foundation model design.
Where Pith is reading between the lines
- The same spatial-scaling principle could be tested in adjacent continuous domains such as atmospheric or hydrological simulation where long-range consistency matters.
- If the model truly captures planetary-scale statistics from image data alone, targeted checks on rare geographic features could reveal whether explicit geographic priors remain necessary.
Load-bearing premise
Training solely on 10 million globally distributed real-world images produces both visual realism and geospatial statistical realism at unbounded planetary scale without additional spatial constraints or validation.
What would settle it
Direct comparison of statistical distributions in generated large-scale terrains against independent global Earth observation datasets, checking for mismatches in long-range patterns such as elevation continuity or land-cover transitions over thousands of kilometers.
Figures




read the original abstract
Recent generative AI models have achieved remarkable breakthroughs in language and visual understanding. However, although these models can generate realistic visual content, their spatial scale remains confined to bounded environments, preventing them from capturing how geographic environments evolve across thousands of kilometers or from modeling the spatial structure of the large-scale physical world. This limitation poses a critical challenge for ultra-wide-area spatial intelligence in Earth observation and simulation, revealing a deeper gap in generative AI: progress has relied primarily on scaling model parameters and training data, while overlooking spatial scale as a core dimension of intelligence. Here, motivated by this missing dimension, we investigate spatial scale as a new scaling axis in foundation models and present MetaEarth3D, the first generative foundation model capable of spatially consistent generation at the planetary scale. Taking optical Earth observation simulation as a testbed, MetaEarth3D enables the generation of multi-level, unbounded, and diverse 3D scenes spanning large-scale terrains, medium-scale cities, and fine-grained street blocks. Built upon 10 million globally distributed real-world training images, MetaEarth3D demonstrates both strong visual realism and geospatial statistical realism. Beyond generation, MetaEarth3D serves as a generative data engine for diverse virtual environments in ultra-wide spatial intelligence. We argue that this study may help empower next-generation spatial intelligence for Earth observation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MetaEarth3D as the first generative foundation model for spatially consistent 3D scene generation at planetary scale. Trained on 10 million globally distributed real-world images, it claims to produce multi-level, unbounded, and diverse 3D outputs spanning large-scale terrains, medium-scale cities, and fine-grained street blocks. The model is positioned as enabling optical Earth observation simulation with both visual realism and geospatial statistical realism, while also serving as a generative data engine for virtual environments in ultra-wide spatial intelligence applications.
Significance. If the central claims of planetary-scale consistency and statistical realism are substantiated with quantitative evidence, the work would meaningfully advance generative modeling by treating spatial scale as an explicit scaling dimension alongside parameters and data volume. This could impact Earth observation, simulation, and spatial AI by providing a foundation for consistent large-scale 3D content generation without bounded-environment restrictions.
major comments (3)
- [Abstract] Abstract: The assertions of 'strong visual realism and geospatial statistical realism' lack any quantitative metrics, ablation studies, or validation protocols, which directly undermines evaluation of the central claim that training on 10M globally distributed images suffices for planetary-scale consistency.
- [Methods] Methods section: No mechanism is described for enforcing long-range geospatial consistency (e.g., explicit coordinate conditioning, hierarchical cross-tile constraints, or post-training validation against geospatial priors); without this, the leap from local image statistics to unbounded planetary coherence remains unsupported.
- [Experiments] Experiments/Results: The manuscript provides no comparisons to prior large-scale generative models, no statistical tests for geospatial fidelity at varying scales, and no analysis of drift or artifacts over thousands of kilometers, all of which are load-bearing for the 'first such model' and 'unbounded' claims.
minor comments (1)
- [Introduction] Introduction: The distinction between 'spatial scale' as a new axis versus simple data diversity could be clarified with a formal definition or scaling law reference to strengthen the motivation.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important areas for strengthening the quantitative rigor and clarity of our claims. We address each major comment point by point below and commit to revisions that directly respond to the concerns.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertions of 'strong visual realism and geospatial statistical realism' lack any quantitative metrics, ablation studies, or validation protocols, which directly undermines evaluation of the central claim that training on 10M globally distributed images suffices for planetary-scale consistency.
Authors: We agree that the abstract would benefit from explicit quantitative support to substantiate the claims. The current manuscript relies primarily on qualitative demonstrations of multi-scale generation from the 10M global dataset. In the revised version, we will update the abstract and add a new evaluation subsection reporting quantitative metrics such as FID scores for visual realism, geospatial statistical measures (e.g., matching of terrain elevation histograms and land-cover distributions), and ablation studies isolating the effect of global data distribution on consistency. These additions will provide clearer validation of planetary-scale performance. revision: yes
-
Referee: [Methods] Methods section: No mechanism is described for enforcing long-range geospatial consistency (e.g., explicit coordinate conditioning, hierarchical cross-tile constraints, or post-training validation against geospatial priors); without this, the leap from local image statistics to unbounded planetary coherence remains unsupported.
Authors: The spatially scalable architecture is designed to promote consistency through multi-resolution training on globally distributed data. However, we acknowledge that the explicit enforcement mechanisms were not described in sufficient detail. We will revise the Methods section to include a dedicated subsection explaining the coordinate conditioning, hierarchical cross-tile constraints applied during generation, and post-training validation protocols that compare outputs against geospatial priors such as elevation and land-use maps. This will make the pathway from local statistics to planetary coherence explicit. revision: yes
-
Referee: [Experiments] Experiments/Results: The manuscript provides no comparisons to prior large-scale generative models, no statistical tests for geospatial fidelity at varying scales, and no analysis of drift or artifacts over thousands of kilometers, all of which are load-bearing for the 'first such model' and 'unbounded' claims.
Authors: We concur that systematic comparisons and statistical analyses are necessary to support the novelty and unbounded claims. The present experiments emphasize qualitative multi-level results. In the revision, we will expand the Experiments section with comparisons to relevant prior large-scale 3D generative models, statistical tests for fidelity across scales (including Kolmogorov-Smirnov tests on geospatial distributions), and quantitative analysis of long-range consistency by measuring drift and artifact accumulation in generated sequences spanning thousands of kilometers. These changes will strengthen the supporting evidence. revision: yes
Circularity Check
No circularity; empirical training claims with no derivations or self-referential reductions
full rationale
The paper presents MetaEarth3D as an empirical generative foundation model trained on 10 million globally distributed real-world images, claiming planetary-scale 3D consistency as a demonstrated outcome rather than a derived result. No equations, mathematical derivations, fitted parameters, or first-principles predictions appear in the abstract or described text. Claims rest on data diversity and model scaling without invoking self-citations for uniqueness theorems, ansatzes smuggled via prior work, or renaming of known patterns. The derivation chain is therefore self-contained and does not reduce any output to its inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
GAIA-1: A Generative World Model for Autonomous Driving
Accessed: 2026-02-25. Anthony Hu, Lloyd Russell, Hudson Yeo, Zak Murez, George Fedoseev, Alex Kendall, Jamie Shotton, and Gianluca Corrado. Gaia-1: A generative world model for autonomous driving.arXiv preprint arXiv:2309.17080,
work page internal anchor Pith review arXiv 2026
-
[2]
Cosmos World Foundation Model Platform for Physical AI
Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, et al. Cosmos world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575,
work page internal anchor Pith review arXiv
-
[3]
Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901,
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901,
1901
-
[4]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation
18 A PREPRINT Zibo Zhao, Zeqiang Lai, Qingxiang Lin, Yunfei Zhao, Haolin Liu, Shuhui Yang, Yifei Feng, Mingxin Yang, Sheng Zhang, Xianghui Yang, et al. Hunyuan3d 2.0: Scaling diffusion models for high resolution textured 3d assets generation.arXiv preprint arXiv:2501.12202,
-
[6]
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, et al. Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space.arXiv preprint arXiv:2506.15742,
work page internal anchor Pith review arXiv
-
[7]
19 A PREPRINT Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, et al. Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling.arXiv preprint arXiv:2412.05271, 2024b. Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Pe...
work page internal anchor Pith review arXiv
-
[9]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[10]
Yulu Gan, Sungwoo Park, Alexander Schubert, Anthony Philippakis, and Ahmed M Alaa. Instructcv: Instruction-tuned text-to-image diffusion models as vision generalists.arXiv preprint arXiv:2310.00390,
-
[11]
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
Yuwei Guo, Ceyuan Yang, Anyi Rao, Zhengyang Liang, Yaohui Wang, Yu Qiao, Maneesh Agrawala, Dahua Lin, and Bo Dai. Animatediff: Animate your personalized text-to-image diffusion models without specific tuning.arXiv preprint arXiv:2307.04725,
work page internal anchor Pith review arXiv
-
[12]
Copernicus global digital elevation model
European Space Agency. Copernicus global digital elevation model. 2025-02-26,
2025
-
[13]
Diffusionsat: A generative foun- dation model for satellite imagery. arxiv 2023,
Samar Khanna, Patrick Liu, Linqi Zhou, Chenlin Meng, Robin Rombach, Marshall Burke, David Lobell, and Stefano Ermon. Diffusionsat: A generative foundation model for satellite imagery.arXiv preprint arXiv:2312.03606,
-
[14]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
20 A PREPRINT MetaEarth3D: Unlocking World-scale 3D Generation with Spatially Scalable Generative Modeling Supplementary Material A Fig. 1a References Supplementary Table 1: Summary of Figure.1a References Method Reference GAN Goodfellow, I. et al. Generative adversarial networks.Commun. ACM63, 139–144 (2020). ProGAN Gao, H., Pei, J. & Huang, H. Progan: N...
work page internal anchor Pith review arXiv 2020
-
[15]
(ii) Our proposed geometry generator shares a similar architecture with InstructCV (?), with a total of 1.0 billion parameters
The model was trained on 4 NVIDIA A800 GPUs, with a batch size of 128 and a learning rate of1×10 −5. (ii) Our proposed geometry generator shares a similar architecture with InstructCV (?), with a total of 1.0 billion parameters. A pre-trained CLIP model was employed to encode the task prompt. At each diffusion timestep, the 25 A PREPRINT Supplementary Fig...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.