Recognition: unknown
AeSlides: Incentivizing Aesthetic Layout in LLM-Based Slide Generation via Verifiable Rewards
Pith reviewed 2026-05-10 02:14 UTC · model grok-4.3
The pith
Reinforcement learning with verifiable rewards enables LLMs to produce aesthetically superior slide layouts using minimal training data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is that a GRPO-based reinforcement learning framework, guided by a suite of verifiable metrics for slide layout quality, can directly optimize LLM slide generation for aesthetic coherence. These metrics enable accurate, low-cost supervision of key issues including aspect ratio compliance, whitespace, element collisions, and visual imbalance. Training on GLM-4.7-Flash with 5K prompts improves aspect ratio compliance from 36% to 85%, reduces whitespace by 44%, element collisions by 43%, and visual imbalance by 28%, while increasing human quality scores from 3.31 to 3.56 and outperforming baselines and even Claude-Sonnet-4.5.
What carries the argument
Verifiable metrics quantifying layout aesthetics, employed as rewards within GRPO reinforcement learning to supervise slide generation models.
Load-bearing premise
The verifiable metrics capture the full range of what humans find aesthetically pleasing in slide layouts without significant bias or omission.
What would settle it
Blind human preference tests showing that slides generated by the trained model are not preferred over those from baseline methods, or a low correlation between the metric scores and human ratings.
Figures























read the original abstract
Large language models (LLMs) have demonstrated strong potential in agentic tasks, particularly in slide generation. However, slide generation poses a fundamental challenge: the generation process is text-centric, whereas its quality is governed by visual aesthetics. This modality gap leads current models to frequently produce slides with aesthetically suboptimal layouts. Existing solutions typically rely either on heavy visual reflection, which incurs high inference cost yet yields limited gains; or on fine-tuning with large-scale datasets, which still provides weak and indirect aesthetic supervision. In contrast, the explicit use of aesthetic principles as supervision remains unexplored. In this work, we present AeSlides, a reinforcement learning framework with verifiable rewards for Aesthetic layout supervision in Slide generation. We introduce a suite of meticulously designed verifiable metrics to quantify slide layout quality, capturing key layout issues in an accurate, efficient, and low-cost manner. Leveraging these verifiable metrics, we develop a GRPO-based reinforcement learning method that directly optimizes slide generation models for aesthetically coherent layouts. With only 5K training prompts on GLM-4.7-Flash, AeSlides improves aspect ratio compliance from 36% to 85%, while reducing whitespace by 44%, element collisions by 43%, and visual imbalance by 28%. Human evaluation further shows a substantial improvement in overall quality, increasing scores from 3.31 to 3.56 (+7.6%), outperforming both model-based reward optimization and reflection-based agentic approaches, and even edging out Claude-Sonnet-4.5. These results demonstrate that such a verifiable aesthetic paradigm provides an efficient and scalable approach to aligning slide generation with human aesthetic preferences. Our repository is available at https://github.com/ympan0508/aeslides.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AeSlides, a GRPO-based reinforcement learning framework that optimizes LLM slide generation using a suite of verifiable, rule-based metrics for layout quality (aspect-ratio compliance, whitespace area, element collisions, and visual imbalance). Trained on only 5K prompts with GLM-4.7-Flash, it reports large gains on these proxies (aspect-ratio compliance 36% to 85%, whitespace reduced 44%, collisions 43%, imbalance 28%) plus a human quality score increase from 3.31 to 3.56 (+7.6%), outperforming model-based reward optimization, reflection-based agents, and even Claude-Sonnet-4.5.
Significance. If the four metrics are faithful low-bias proxies for human aesthetic judgment, the work demonstrates an efficient, low-cost alternative to visual reflection loops or large-scale fine-tuning for aligning text-centric LLMs with visual layout preferences. The public repository supports reproducibility.
major comments (2)
- [Abstract] Abstract: the human evaluation reports only a 0.25-point gain on an apparent 5-point scale (+7.6%). Without reported details on the rating protocol, number of raters, inter-rater agreement, statistical significance, or whether raters were instructed to penalize the exact failure modes captured by the four metrics, the modest delta provides weak evidence that the verifiable metrics align with human aesthetic preferences rather than proxy overfitting.
- [Results] Results (quantitative and human evaluation sections): large metric improvements are shown, but no ablation or failure-case analysis demonstrates that optimizing the four metrics cannot produce degenerate layouts (e.g., overly sparse or rigidly gridded slides) that score well on the proxies yet receive low human ratings. Such analysis is load-bearing for the central claim that the verifiable-reward paradigm improves true aesthetic quality.
minor comments (1)
- [Abstract] Abstract: the baselines ('model-based reward optimization' and 'reflection-based agentic approaches') are mentioned without even one-sentence characterizations; a brief parenthetical description would clarify the comparison.
Simulated Author's Rebuttal
We are grateful to the referee for their insightful comments, which have helped us improve the clarity and rigor of our presentation. Below, we provide point-by-point responses to the major comments and indicate the revisions made to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the human evaluation reports only a 0.25-point gain on an apparent 5-point scale (+7.6%). Without reported details on the rating protocol, number of raters, inter-rater agreement, statistical significance, or whether raters were instructed to penalize the exact failure modes captured by the four metrics, the modest delta provides weak evidence that the verifiable metrics align with human aesthetic preferences rather than proxy overfitting.
Authors: We agree that the abstract and results section would benefit from more details on the human evaluation to substantiate the alignment between our metrics and human preferences. In the revised manuscript, we have expanded the description of the human evaluation protocol, including the rating scale, number of raters, inter-rater agreement, and statistical tests. We have also clarified the instructions given to raters, which emphasized evaluating layout quality in terms of the aspects our metrics target. Although the gain is modest, it is positive and accompanies substantial proxy improvements, providing supporting evidence for our approach. The full details are now included in the main text and appendix. revision: yes
-
Referee: [Results] Results (quantitative and human evaluation sections): large metric improvements are shown, but no ablation or failure-case analysis demonstrates that optimizing the four metrics cannot produce degenerate layouts (e.g., overly sparse or rigidly gridded slides) that score well on the proxies yet receive low human ratings. Such analysis is load-bearing for the central claim that the verifiable-reward paradigm improves true aesthetic quality.
Authors: We recognize that demonstrating the absence of degenerate layouts is important to validate that the proxy metrics truly capture aesthetic quality. The original manuscript did not include a dedicated failure-case analysis. We have now added such an analysis in the revised version, where we examine slides with high metric scores but lower human ratings. Our review indicates that such cases are rare and typically stem from content issues rather than the layout degeneracies described. We also include an ablation on metric combinations to show that optimizing all four metrics together produces the best human-evaluated results without introducing sparsity or rigidity problems. This addition directly addresses the concern and bolsters the central claim. revision: yes
Circularity Check
No significant circularity: independent metrics and external human validation
full rationale
The paper designs a suite of rule-based verifiable metrics (aspect ratio compliance, whitespace, collisions, visual imbalance) as explicit aesthetic proxies and applies GRPO to optimize the base LLM directly against them. Reported metric improvements are the direct, expected outcome of reward maximization rather than any claimed independent prediction or derivation. The central aesthetic claim is supported by a separate human evaluation (scores rising from 3.31 to 3.56) that is not reducible to the metrics themselves. No self-citations, uniqueness theorems, or ansatzes are invoked in a load-bearing manner; the derivation chain from metric definition through RL training to human-rated quality remains self-contained and externally falsifiable.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The designed verifiable metrics provide accurate and efficient quantification of slide layout quality that aligns with human preferences.
Reference graph
Works this paper leans on
-
[1]
Isabel Cachola, Silviu Cucerzan, Allen Herring, Vuksan Mijovic, Erik Oveson, and Sujay Kumar Jauhar. 2024. Knowledge-Centric Templatic Views of Documents. InFindings of the Association for Computational Linguistics: EMNLP 2024. 15460– 15476
2024
-
[2]
Dan Friedman and Adji Bousso Dieng. 2023. The Vendi Score: A Diversity Evaluation Metric for Machine Learning.Transactions on Machine Learning Research(2023)
2023
-
[3]
Tsu-Jui Fu, William Yang Wang, Daniel McDuff, and Yale Song. 2022. DOC2PPT: Automatic Presentation Slides Generation from Scientific Documents. InProceed- ings of the AAAI Conference on Artificial Intelligence, Vol. 36. 634–642
2022
-
[4]
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A Smith, Wei-Chiu Ma, and Ranjay Krishna. 2024. BLINK: Multimodal Large Language Models Can See but Not Perceive. InEuropean Conference on Computer Vision. Springer, 148–166
2024
-
[5]
Chang Gao, Chujie Zheng, Xiong-Hui Chen, Kai Dang, Shixuan Liu, Bowen Yu, An Yang, Shuai Bai, Jingren Zhou, and Junyang Lin. 2025. Soft Adaptive Policy Optimization.arXiv preprint arXiv:2511.20347(2025)
work page internal anchor Pith review arXiv 2025
-
[6]
Jiaxin Ge, Zora Zhiruo Wang, Xuhui Zhou, Yi-Hao Peng, Sanjay Subramanian, Qinyue Tan, Maarten Sap, Alane Suhr, Daniel Fried, Graham Neubig, et al. 2025. AutoPresent: Designing Structured Visuals from Scratch. InProceedings of the Computer Vision and Pattern Recognition Conference. 2902–2911
2025
-
[7]
Wenyi Hong, Wenmeng Yu, Xiaotao Gu, Guo Wang, Guobing Gan, Haomiao Tang, Jiale Cheng, Ji Qi, Junhui Ji, Lihang Pan, et al. 2025. GLM-4.5V and GLM-4.1V- Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning.arXiv preprint arXiv:2507.01006(2025)
work page internal anchor Pith review arXiv 2025
-
[8]
Juyong Jiang, Chansung Park, Jiasi Shen, Sunghun Kim, Jianguo Li, Yue Wang, et al. 2026. WebGen-R1: Incentivizing LLMs to Generate Functional and Aesthetic Websites with Reinforcement Learning. (2026). https://openreview.net/forum? id=Zzf6ExJZXj
2026
-
[9]
Kyudan Jung, Hojun Cho, Jooyeol Yun, Soyoung Yang, Jaehyeok Jang, and Jaegul Choo. 2025. Talk to Your Slides: Language-Driven Agents for Efficient Slide Editing.arXiv preprint arXiv:2505.11604(2025)
work page internal anchor Pith review arXiv 2025
-
[10]
Dawei Li, Renliang Sun, Yue Huang, Ming Zhong, Bohan Jiang, Jiawei Han, Xiangliang Zhang, Wei Wang, and Huan Liu. 2026. Preference Leakage: A Con- tamination Problem in LLM-as-a-judge. InThe Fourteenth International Conference on Learning Representations
2026
- [11]
-
[12]
Shih-Yang Liu, Xin Dong, Ximing Lu, Shizhe Diao, Peter Belcak, Mingjie Liu, Min-Hung Chen, Hongxu Yin, Yu-Chiang Frank Wang, Kwang-Ting Cheng, et al
-
[13]
GDPO: Group reward-Decoupled Normalization Policy Optimization for Multi-reward RL Optimization.arXiv preprint arXiv:2601.05242(2026)
work page internal anchor Pith review arXiv 2026
-
[14]
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. 2023. G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment. InProceedings of the 2023 conference on empirical methods in natural language processing. 2511–2522
2023
-
[15]
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. 2025. Understanding R1-Zero-Like Training: A Critical Perspective. InSecond Conference on Language Modeling
2025
-
[16]
Michael Luo, Sijun Tan, Roy Huang, Ameen Patel, Alpay Ariyak, Qingyang Wu, Xiaoxiang Shi, Rachel Xin, Colin Cai, Maurice Weber, Ce Zhang, Li Erran Li, Raluca Ada Popa, and Ion Stoica. 2025. DeepCoder: A Fully Open-Source 14B Coder at O3-mini Level. https://pretty-radio- b75.notion.site/DeepCoder-A-Fully-Open-Source-14B-Coder-at-O3-mini- Level-1cf81902c146...
2025
- [17]
-
[18]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training Language Models to Follow Instructions with Human Feedback.Ad- vances in neural information processing systems35 (2022), 27730–27744
2022
-
[19]
Arjun Panickssery, Samuel R Bowman, and Shi Feng. 2024. LLM Evaluators Recognize and Favor Their Own Generations.Advances in Neural Information Processing Systems37 (2024), 68772–68802
2024
-
[20]
Sohan Patnaik, Rishabh Jain, Balaji Krishnamurthy, and Mausoom Sarkar. 2025. AesthetiQ: Enhancing Graphic Layout Design via Aesthetic-Aware Preference Alignment of Multi-modal Large Language Models. InProceedings of the Computer Vision and Pattern Recognition Conference. 23701–23711
2025
-
[21]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. 2023. Direct Preference Optimization: Your Language Model is Secretly a Reward Model.Advances in neural information processing systems36 (2023), 53728–53741
2023
-
[22]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. 2024. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models.arXiv preprint arXiv:2402.03300(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Patrick E Shrout and Joseph L Fleiss. 1979. Intraclass Correlations: Uses in Assessing Rater Reliability.Psychological bulletin86, 2 (1979), 420
1979
-
[24]
Wenxin Tang, Jingyu Xiao, Wenxuan Jiang, Xi Xiao, Yuhang Wang, Xuxin Tang, Qing Li, Yuehe Ma, Junliang Liu, Shisong Tang, et al. 2025. SlideCoder: Layout- Aware RAG-Enhanced Hierarchical Slide Generation from Design. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 9026–9050
2025
-
[25]
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, SH Cai, Yuan Cao, Y Charles, HS Che, Cheng Chen, Guanduo Chen, et al . 2026. Kimi K2. 5: Visual Agentic Intelligence.arXiv preprint arXiv:2602.02276(2026)
work page internal anchor Pith review arXiv 2026
-
[26]
Shengbang Tong, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, and Saining Xie. 2024. Eyes wide shut? exploring the visual shortcomings of multimodal llms. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 9568–9578
2024
-
[27]
Koki Wataoka, Tsubasa Takahashi, and Ryokan Ri. 2024. Self-Preference Bias in LLM-as-a-Judge. InNeurIPS Safe Generative AI Workshop 2024
2024
-
[28]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-Thought Prompting Elicits Rea- soning in Large Language Models.Advances in neural information processing systems35 (2022), 24824–24837
2022
-
[29]
Xiaojie Xu, Xinli Xu, Sirui Chen, Haoyu Chen, Fan Zhang, and Ying-Cong Chen
-
[30]
InFindings of the Association for Computational Linguistics: EMNLP 2025, Suzhou, China, November 4-9, 2025
PreGenie: An Agentic Framework for High-quality Visual Presentation Generation. InFindings of the Association for Computational Linguistics: EMNLP 2025, Suzhou, China, November 4-9, 2025. 3045–3063
2025
- [31]
-
[32]
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024. SWE-Agent: Agent-Computer Interfaces En- able Automated Software Engineering.Advances in Neural Information Processing Systems37 (2024), 50528–50652
2024
-
[33]
Feng Yao, Liyuan Liu, Dinghuai Zhang, Chengyu Dong, Jingbo Shang, and Jian- feng Gao. 2025. Your Efficient RL Framework Secretly Brings You Off-Policy RL Training. https://fengyao.notion.site/off-policy-rl
2025
-
[34]
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al . 2025. DAPO: An Open-Source LLM Reinforcement Learning System at Scale. InAdvances in Neural Information Processing Systems
2025
-
[35]
Aohan Zeng, Xin Lv, Zhenyu Hou, Zhengxiao Du, Qinkai Zheng, Bin Chen, Da Yin, Chendi Ge, Chengxing Xie, Cunxiang Wang, et al. 2026. GLM-5: from Vibe Coding to Agentic Engineering.arXiv preprint arXiv:2602.15763(2026)
work page internal anchor Pith review arXiv 2026
-
[36]
Aohan Zeng, Xin Lv, Qinkai Zheng, Zhenyu Hou, Bin Chen, Chengxing Xie, Cunxiang Wang, Da Yin, Hao Zeng, Jiajie Zhang, et al. 2025. GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models.arXiv preprint arXiv:2508.06471 (2025)
work page internal anchor Pith review arXiv 2025
-
[37]
Xin Zhao, Yongkang Liu, Kuan Xu, Jia Guo, Zihao Wang, Yan Sun, Xinyu Kong, Qianggang Cao, Liang Jiang, Zujie Wen, Zhiqiang Zhang, and Jun Zhou. 2025. Small Leak Can Sink a Great Ship–Boost RL Training on MoE with IcePop! https://ringtech.notion.site/icepop
2025
-
[38]
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, et al. 2025. Group Sequence Policy Optimization.arXiv preprint arXiv:2507.18071(2025)
work page internal anchor Pith review arXiv 2025
-
[39]
Hao Zheng, Xinyan Guan, Hao Kong, Wenkai Zhang, Jia Zheng, Weixiang Zhou, Hongyu Lin, Yaojie Lu, Xianpei Han, and Le Sun. 2025. PPTAgent: Generating and Evaluating Presentations Beyond Text-to-Slides. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 14413–14429
2025
-
[40]
Hao Zheng, Guozhao Mo, Xinru Yan, Qianhao Yuan, Wenkai Zhang, Xuanang Chen, Yaojie Lu, Hongyu Lin, Xianpei Han, and Le Sun. 2026. DeepPresenter: Environment-Grounded Reflection for Agentic Presentation Generation.arXiv preprint arXiv:2602.22839(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[41]
Dwelling in the Fuchun Mountains
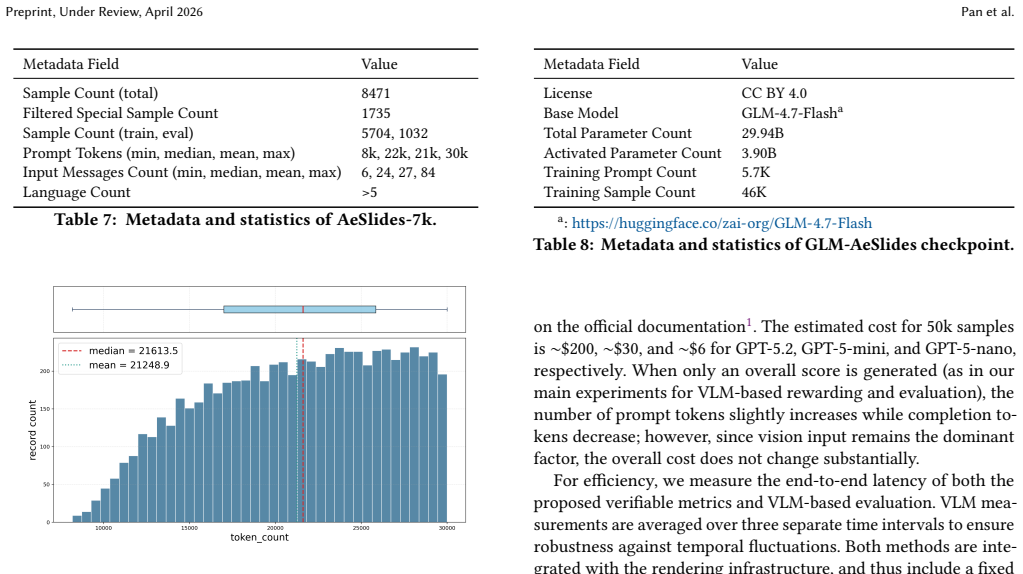
Zilin Zhu, Chengxing Xie, Xin Lv, and slime Contributors. 2025. slime: An LLM post-training framework for RL Scaling. https://github.com/THUDM/slime. GitHub repository. Corresponding author: Xin Lv. A Metadata and Statistics of Datasets and Model Checkpoints A.1 AeSlides-Reward-Bench A.1.1 Annotation Protocol.AeSlides-Reward-Bench is introduced to provide...
2025
-
[42]
Treat width/height ratios within +/-5% of 16:9 (roughly 1.69 to 1.87) as acceptable
distorted_aspect_ratio: The slide should follow a 16:9 ratio (1280x720). Treat width/height ratios within +/-5% of 16:9 (roughly 1.69 to 1.87) as acceptable. Deviations or visual distortion should be considered a flaw
-
[43]
Note: Background fills (gradients, textures) do NOT count as content
excessive_whitespace: Identify empty regions without semantic content. Note: Background fills (gradients, textures) do NOT count as content
-
[44]
element_collision: Check for overlap, occlusion, overflow, clipping, or boundary violations between elements
-
[45]
Evaluation Criteria: Judge the slide holistically as a visual composition
visual_imbalance: Evaluate whether the layout is visually balanced or biased toward one side. Evaluation Criteria: Judge the slide holistically as a visual composition. Consider layout balance, alignment, spacing, hierarchy, readability, proportional sizing, whitespace distribution, and visual grouping. Strongly penalize: - Incorrect or visually distorted...
2026
-
[46]
Treat width/height ratios within +/-5% of 16:9 (roughly 1.69 to 1.87) as acceptable
has_distorted_aspect_ratio: The standard slide aspect ratio is 16:9 (1280x720). Treat width/height ratios within +/-5% of 16:9 (roughly 1.69 to 1.87) as acceptable. Outside that tolerance, or when the slide visibly appears stretched, squashed, or improperly scaled, it should be treated as a significant aspect-ratio defect
-
[47]
Note: Background fills (gradients, textures, color blocks) DO NOT count as content
has_excessive_whitespace: There are abnormally large regions without semantic content. Note: Background fills (gradients, textures, color blocks) DO NOT count as content
-
[48]
Do NOT flag minor or visually harmless overlays (e.g., subtle badges, light decorations)
has_element_collision: Elements visibly overlap, occlude each other, overflow containers, or extend beyond boundaries. Do NOT flag minor or visually harmless overlays (e.g., subtle badges, light decorations)
-
[49]
has_distorted_aspect_ratio
has_visual_imbalance: The visual center of gravity is clearly biased to one side (left/right/top/bottom), making the layout feel unstable or uncomfortable. Judging Rules: - Only flag obvious and visually significant issues - Do NOT flag minor imperfections - Do NOT penalize intentional clean layouts unless clearly problematic Output the final answer betwe...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.