Learning Curves and Benign Overfitting of Spectral Algorithms in Large Dimensions
Pith reviewed 2026-05-08 07:11 UTC · model grok-4.3
The pith
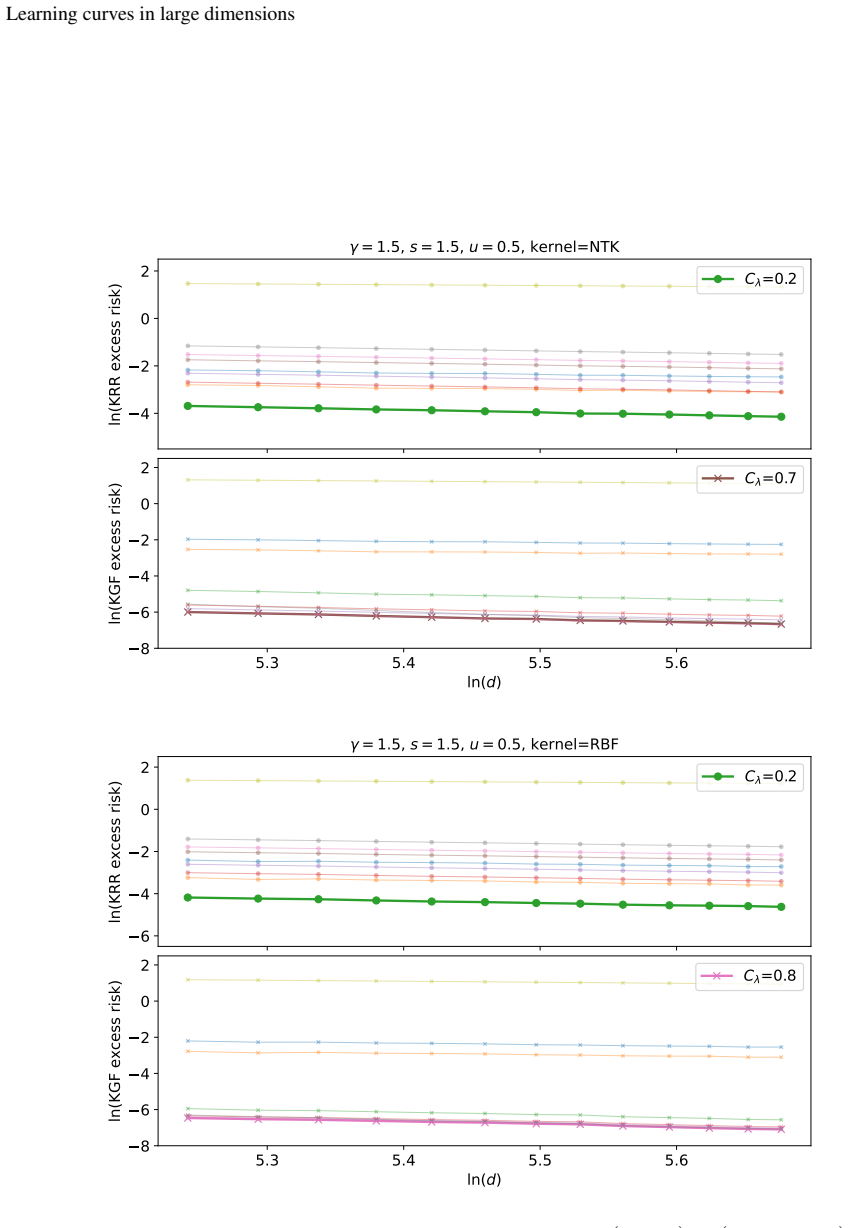
Spectral algorithms in high dimensions have excess risk that splits into three distinct regimes along the full regularization path, with benign overfitting in the under-regularized and interpolation regimes for source conditions 0 < s ≤ s*.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In the proportional regime n ≍ d^γ with γ > 0, the excess risk of spectral algorithms admits a sharp asymptotic characterization across all regularization strengths under source conditions s ≥ 0. This yields three regimes: over-regularized, where risk decreases as regularization weakens; under-regularized, where risk behavior depends on s; and the interpolation limit. Benign overfitting occurs for all 0 < s ≤ s*, and the kernel risk in the sufficiently regularized regime matches that of an associated sequence model.
What carries the argument
The sharp asymptotic excess-risk formula obtained by analyzing the eigenvalue distribution of the kernel operator together with the source condition, which decomposes risk into bias and variance terms whose scaling changes across regularization strengths.
If this is right
- The risk remains controlled in the under-regularized regime for targets with positive but bounded smoothness.
- Benign overfitting is explained by the asymptotic balance of bias and variance without needing explicit interpolation analysis.
- In the over-regularized regime the kernel estimator behaves like a finite-dimensional sequence model.
- The three-regime structure extends to kernels on general domains whose low-degree eigenfunctions obey the stated scaling and concentration conditions.
Where Pith is reading between the lines
- Practitioners could safely use moderate under-regularization for moderately smooth targets without incurring large excess risk.
- The same regime decomposition may apply to other high-dimensional linear estimators whose effective degrees of freedom follow similar eigenvalue decay.
- Empirical checks on real high-dimensional data sets with controlled smoothness could locate the critical s* and test the sharpness of the transitions.
Load-bearing premise
The kernels are inner-product kernels on the sphere or satisfy spectral-scaling and hyper-contractivity on their low-degree eigenspaces, and the data live in the proportional high-dimensional regime n ≍ d^γ.
What would settle it
For an inner-product kernel on the unit sphere, fix s between 0 and s*, generate data with n proportional to d^γ, compute empirical excess risk over a grid of regularization values from large to zero, and check whether the observed curve exhibits the predicted three-regime shape with benign overfitting in the final two regimes.
Figures











read the original abstract
Existing large-dimensional theory for spectral algorithms resolves either the optimally tuned point or the interpolation limit, but leaves the under-regularized regime unexplored. We study the learning curve and benign overfitting of spectral algorithms in the large-dimensional setting where the sample size and dimension are of comparable order, i.e., $n \asymp d^{\gamma}$ for some $\gamma>0$. We first consider inner-product kernels on the sphere $\mathbb{S}^{d-1}$ and establish a sharp asymptotic characterization of the excess risk across the full regularization path under various source conditions $s \geq 0$, where $s$ measures the relative smoothness of the regression function. Our results reveal that the learning curve is not simply U-shaped but instead consists of three distinct regimes: over-regularized, under-regularized, and interpolation regimes. This characterization allows us to fully capture the benign overfitting phenomenon, demonstrating that benign overfitting arises consistently across both the under-regularized and interpolation regimes whenever $s$ is positive but no larger than a critical threshold. We further show that, in the sufficiently regularized regime, the kernel learning curve is recovered by an associated sequence model. Finally, we extend the learning-curve analysis to large-dimensional KRR for a class of kernels on general domains in $\mathbb{R}^d$ whose low-degree eigenspaces satisfy spectral-scaling and hyper-contractivity conditions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript establishes sharp asymptotic characterizations of the excess risk for spectral algorithms (including kernel ridge regression) in the large-dimensional proportional regime where n ≍ d^γ for γ > 0. For inner-product kernels on the sphere, under source conditions s ≥ 0, the learning curve exhibits three distinct regimes (over-regularized, under-regularized, and interpolation) across the full regularization path; benign overfitting is shown to occur consistently for 0 < s ≤ s*. The analysis further recovers the kernel learning curve via an associated sequence model in the sufficiently regularized regime and extends the results to a class of kernels on general domains whose low-degree eigenspaces satisfy spectral-scaling and hyper-contractivity.
Significance. If the claimed asymptotics hold, this provides a complete theoretical description of the regularization path for spectral methods in high dimensions, moving beyond isolated analyses of optimal tuning or the interpolation limit. The explicit three-regime decomposition, precise conditions for benign overfitting, and the sequence-model equivalence constitute a substantive advance for understanding generalization in overparameterized kernel models. The extension to general domains under verifiable structural conditions on the kernel further broadens applicability.
major comments (2)
- [§3] §3 (main asymptotic results): the boundaries separating the three regimes are characterized in terms of λ relative to n and d, but the explicit dependence of these thresholds on the proportionality exponent γ is not stated; this dependence is load-bearing for the claim that the regimes are distinct and exhaustive for any γ > 0.
- [Theorem 4.3] Theorem 4.3 (benign overfitting for 0 < s ≤ s*): the critical threshold s* is defined via the kernel spectrum and source condition, yet the proof sketch does not explicitly verify that the variance term remains bounded while the bias vanishes uniformly in the under-regularized regime; an additional uniform integrability argument appears necessary to make the limit sharp.
minor comments (2)
- [Introduction] The notation for the excess risk R(λ) versus the population risk should be introduced with a displayed equation in the introduction to prevent any ambiguity with in-sample quantities.
- [§5] In the extension to general domains (§5), the hyper-contractivity assumption is invoked for low-degree eigenspaces; a brief remark on which standard kernels (e.g., Gaussian) satisfy it for the relevant degree range would improve readability.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and insightful comments on our manuscript. We address the major comments point by point below and will revise the manuscript to incorporate the requested clarifications.
read point-by-point responses
-
Referee: [§3] §3 (main asymptotic results): the boundaries separating the three regimes are characterized in terms of λ relative to n and d, but the explicit dependence of these thresholds on the proportionality exponent γ is not stated; this dependence is load-bearing for the claim that the regimes are distinct and exhaustive for any γ > 0.
Authors: We agree that explicitly stating the dependence on γ strengthens the clarity of the regime separation. In the revised manuscript, we will add explicit expressions for the regime thresholds in terms of γ (derived directly from the asymptotic characterizations in §3). For example, the boundary between the over-regularized and under-regularized regimes scales as λ ≍ n^{-1} d^{γ(1-s)} or analogous forms depending on the source condition, confirming that the three regimes remain distinct and exhaustive for every γ > 0. This addition will be placed in the statement of the main results and the accompanying discussion. revision: yes
-
Referee: [Theorem 4.3] Theorem 4.3 (benign overfitting for 0 < s ≤ s*): the critical threshold s* is defined via the kernel spectrum and source condition, yet the proof sketch does not explicitly verify that the variance term remains bounded while the bias vanishes uniformly in the under-regularized regime; an additional uniform integrability argument appears necessary to make the limit sharp.
Authors: We thank the referee for highlighting this point. The full proof in the appendix already controls the variance term via moment bounds that remain uniform in the under-regularized regime and shows bias vanishing under the source condition. However, to make the argument fully explicit and address the uniform integrability concern, we will insert an additional lemma (or expanded remark) in the proof of Theorem 4.3 that verifies uniform boundedness of the variance and applies a uniform integrability argument to justify interchanging limits. This will render the benign-overfitting statement sharp without altering the result itself. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper's central results consist of sharp asymptotic characterizations of excess risk derived from explicit large-dimensional analysis of the kernel matrix spectrum, bias-variance decomposition, and source conditions s ≥ 0 under the proportional regime n ≍ d^γ. These limits are tracked directly via the stated assumptions on inner-product kernels (or kernels satisfying spectral scaling and hyper-contractivity) without any reduction of the target quantities to fitted parameters, self-definitions, or load-bearing self-citations. The three-regime structure and benign overfitting claims for 0 < s ≤ s* emerge as consequences of the asymptotic tracking rather than being presupposed by the inputs.
Axiom & Free-Parameter Ledger
free parameters (2)
- regularization parameter λ
- source condition parameter s
axioms (2)
- domain assumption Kernel matrix spectrum admits a deterministic equivalent in the proportional limit n ≍ d^γ
- domain assumption Low-degree eigenspaces satisfy spectral-scaling and hyper-contractivity
Reference graph
Works this paper leans on
-
[1]
Optimal rates for the regularized least-squares algorithm,
PMLR. Brown, L. D. and M. G. Low (1996). Asymptotic equivalence of nonparametric regression and white noise.The Annals of Statistics 24(6), 2384–2398. Buchholz, S. (2022). Kernel interpolation in sobolev spaces is not consistent in low dimensions. In Conference on Learning Theory, pp. 3410–3440. PMLR. Caponnetto, A. (2006, September). Optimal rates for re...
-
[2]
Notice that for kernel ridge regression, we have φλ, ˜K :=n −1φKRR λ ( ˜K/n) = ( ˜K+nλI n)−1 = ˜M −1.(87) 70 Learning curves in large dimensions Moreover, from Step (I), the generalization of Lemma G.8 and Lemma G.6 (v) imply that ˜Σ≤˜ℓ − ˜Σ≤˜ℓ ˜Ψ⊤ ≤˜ℓ ˜M −1 ˜Ψ≤˜ℓ ˜Σ≤˜ℓ = ˜Σ−1 ≤˜ℓ + ˜Ψ⊤ ≤˜ℓ ˜M −1 >˜ℓ ˜Ψ≤˜ℓ −1 ,(88) λmax ˜Σ−1 ≤˜ℓ + ˜Ψ⊤ ≤˜ℓ ˜M −1 >˜ℓ ˜Ψ≤˜ℓ ...
work page 2024
-
[3]
Therefore, we have Ωd,P dγ−ℓγ −1 +d ℓγ −γ +d −(ℓγ+1)s = Ωd,P dℓγ −γ . Furthermore, we have −(p+ 1)s <−ℓ γΓ(γ) =ℓ γ −γ,ifp=ℓ γ −1, −(p+ 1)s < p+ 1−γ < ℓ γ −γ,ifp < ℓ γ −1, where the first case uses s >Γ(γ) and (16), and the second case uses γ <(p+ 1)(s+ 1) by the definition ofp. Together withp < ℓ γ, we have Ωd,P dℓγ −γ ≫d p−γ +d −(p+1)s in prob. Case 3:γ∈...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.