A Layer Separation Optimization Framework for Cross-Entropy Training in Deep Learning
Pith reviewed 2026-05-08 08:29 UTC · model grok-4.3
The pith
Layer separation adds auxiliary variables to bound the cross-entropy loss and split deep network training into alternating subproblems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By introducing auxiliary variables associated with hidden-layer outputs, the layer separation models decompose the original cross-entropy optimization problem into a sequence of more manageable subproblems while guaranteeing that the new loss function provides an upper bound on the original cross-entropy loss; alternating minimization applied to these models exhibits decreasing properties of the loss function under appropriate conditions.
What carries the argument
Layer separation models formed by auxiliary variables for hidden layer outputs, which decompose the nested problem and supply an upper bound on cross-entropy loss for use in alternating minimization.
If this is right
- The layer separation loss can be minimized in place of the original loss without ever exceeding the true cross-entropy value.
- Alternating minimization steps are guaranteed to produce a monotonically decreasing loss sequence when the stated conditions hold.
- The same construction applies uniformly to both fully connected networks and convolutional networks.
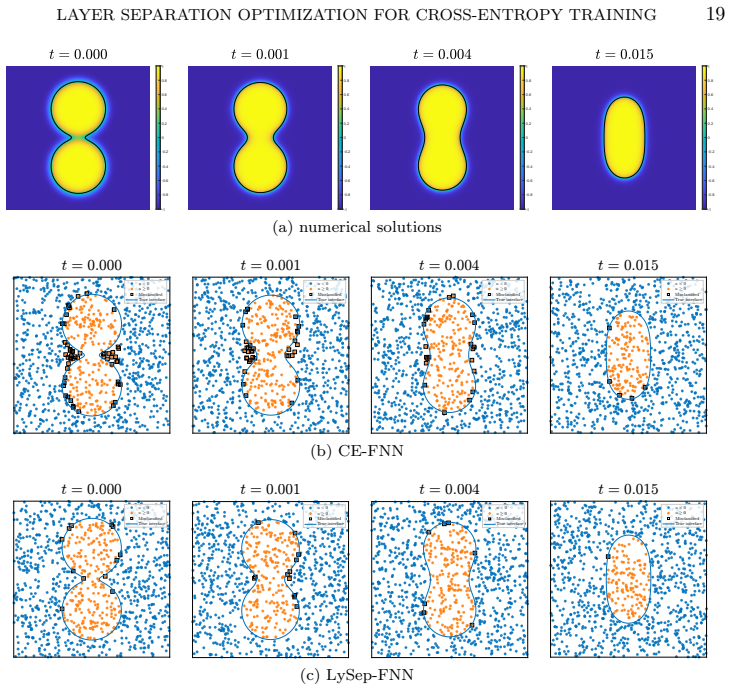
- Numerical tests show the approach yields improved optimization trajectories compared with direct cross-entropy training.
Where Pith is reading between the lines
- The decomposition may enable independent or parallel updates of individual layer subproblems in very deep architectures.
- Because the separated loss always dominates the original, any generalization bound proved for the separated model would automatically apply to the true cross-entropy objective.
- The auxiliary-variable technique could be tested on other composite losses such as focal loss or label-smoothed cross-entropy to check whether similar bounding and alternation properties hold.
Load-bearing premise
Adding auxiliary variables for hidden-layer outputs decomposes the non-convex problem without breaking the upper-bound link to the original cross-entropy loss or invalidating the convergence guarantees for alternating minimization.
What would settle it
A counter-example on a small fully connected network in which alternating minimization on the separated model increases the true cross-entropy loss on held-out data would falsify the bounding and monotonic-decrease claims.
Figures



read the original abstract
This paper investigates the deep learning optimization problem with softmax cross-entropy loss. We propose a layer separation strategy to alleviate the strong nonconvexity encountered during training deep networks. For cross-entropy models with fully connected and convolutional neural networks, we introduce auxiliary variables associated with hidden layer outputs and construct corresponding layer separation models, which decompose the original deeply nested optimization problem into a sequence of more manageable subproblems. We also conduct theoretical analyses, proving that the new layer separation loss provides an upper bound for the original cross-entropy loss. Moreover, we design alternating minimization algorithms and prove that, under appropriate conditions, these algorithms exhibit decreasing properties of the loss function. Numerical experiments validate the effectiveness of the proposed methods and indicate improved optimization behavior, especially for fully connected and convolutional neural networks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a layer separation optimization framework for training deep networks with softmax cross-entropy loss. It introduces auxiliary variables tied to hidden-layer outputs to decompose the nested non-convex problem into a sequence of subproblems for both fully-connected and convolutional architectures. The authors claim to prove that the resulting layer-separation loss is an upper bound on the original cross-entropy loss, design alternating-minimization algorithms, and prove that these algorithms produce monotonically decreasing loss sequences under suitable conditions. Numerical experiments are reported to show improved optimization behavior.
Significance. If the upper-bound and monotonicity claims are rigorously established, the framework would supply a concrete majorization-style surrogate for cross-entropy training that explicitly separates layers, potentially easing analysis of non-convexity and offering an alternative to standard back-propagation or other surrogate methods. The approach is a natural extension of auxiliary-variable techniques already used in optimization, but its practical impact hinges on whether the bound remains useful for modern-scale networks and whether the alternating scheme yields faster or more stable convergence than existing first-order methods.
major comments (3)
- [Abstract / Theoretical Analysis] Abstract and Theoretical Analysis section: the claim that the layer-separation loss furnishes an upper bound on the original cross-entropy loss is central, yet the manuscript provides no explicit inequality derivation or statement of the precise conditions (e.g., convexity of the auxiliary subproblems or Lipschitz constants) under which the bound holds. Without these steps it is impossible to verify whether the auxiliary variables preserve the original minimizers or merely relax the problem.
- [Algorithm and Convergence Analysis] Alternating-minimization algorithm and convergence proof: the assertion that the algorithms exhibit decreasing loss properties under 'appropriate conditions' is load-bearing for the practical contribution, but the manuscript does not specify the exact conditions (e.g., strong convexity of each block, step-size restrictions, or closed-form solvability of the auxiliary-variable subproblems) nor supply a complete proof sketch. This gap directly affects whether the claimed monotonicity can be used to guarantee progress toward a stationary point of the original loss.
- [Experiments] Numerical experiments: the reported validation of 'improved optimization behavior' lacks quantitative comparison against standard baselines (SGD with momentum, Adam, or existing majorization-minimization schemes) and does not report training curves, final test accuracy, or wall-clock time on the same architectures and datasets. Without these controls it is difficult to isolate whether any observed benefit stems from the layer-separation construction itself.
minor comments (2)
- [Method] Notation for the auxiliary variables and the layer-separation loss function should be introduced with a clear table or diagram showing how each auxiliary variable maps to a hidden-layer output; current presentation leaves the mapping implicit.
- [Experiments] The abstract states that the framework applies to 'fully connected and convolutional neural networks,' yet the experimental section does not clarify whether the same auxiliary-variable construction is used verbatim for convolutions or whether additional modifications (e.g., for spatial dimensions) are required.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed report. The comments highlight important areas for improving clarity and rigor, and we appreciate the opportunity to strengthen the manuscript. Below we address each major comment point by point, indicating the revisions we will make.
read point-by-point responses
-
Referee: [Abstract / Theoretical Analysis] the claim that the layer-separation loss furnishes an upper bound on the original cross-entropy loss is central, yet the manuscript provides no explicit inequality derivation or statement of the precise conditions under which the bound holds.
Authors: The upper-bound property is derived in the Theoretical Analysis section by showing that the layer-separation loss equals the original cross-entropy loss when auxiliary variables coincide with the hidden-layer outputs and is strictly larger otherwise, using the non-negativity of the KL divergence between the softmax outputs. We agree that an explicit step-by-step derivation and the precise conditions (e.g., the auxiliary variables being free to match the network outputs) were not stated with sufficient prominence. In the revision we will add a dedicated lemma with the full inequality chain and the conditions under which the bound is tight, thereby confirming that the original minimizers are preserved. revision: yes
-
Referee: [Algorithm and Convergence Analysis] the assertion that the algorithms exhibit decreasing loss properties under 'appropriate conditions' is load-bearing, but the manuscript does not specify the exact conditions nor supply a complete proof sketch.
Authors: The alternating-minimization scheme is constructed so that each block subproblem (over weights or auxiliaries) is either solved in closed form or admits a sufficient decrease when the auxiliary subproblems are convex. We will expand the convergence section with an explicit statement of the required conditions (block-wise strong convexity or exact solvability for linear layers, and a uniform lower bound on the decrease per iteration) together with a concise proof sketch that directly links the monotonicity of the surrogate to progress on the original loss. revision: yes
-
Referee: [Experiments] the reported validation of 'improved optimization behavior' lacks quantitative comparison against standard baselines and does not report training curves, final test accuracy, or wall-clock time.
Authors: We acknowledge that the current experimental presentation is insufficient for isolating the contribution of the layer-separation construction. In the revised manuscript we will add direct comparisons against SGD with momentum, Adam, and a standard majorization-minimization baseline on the same fully-connected and convolutional architectures, including training-loss curves, final test accuracies, and wall-clock times on MNIST and CIFAR-10. revision: yes
Circularity Check
No significant circularity; new auxiliary-variable construction with independent proofs
full rationale
The paper introduces auxiliary variables tied to hidden-layer outputs to decompose the nested cross-entropy optimization into subproblems, then proves that the resulting layer-separation loss is an upper bound on the original loss and that the alternating-minimization scheme is monotonically decreasing under appropriate conditions. These claims rest on explicit construction of the surrogate and standard majorization-minimization analysis rather than on any fitted parameter renamed as a prediction, self-citation chain, or imported uniqueness theorem. No equation reduces by definition to its own inputs, and the framework is presented as a fresh decomposition whose validity is checked against the original loss without circular reduction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The original cross-entropy loss is a composition of nested functions through the network layers.
- domain assumption Alternating minimization on the separated subproblems yields monotonic decrease under appropriate conditions.
invented entities (1)
-
Auxiliary variables associated with hidden layer outputs
no independent evidence
Reference graph
Works this paper leans on
-
[1]
[9]J. Duchi, E. Hazan, and Y. Singer,Adaptive subgradient methods for online learning and stochastic optimization, J. Mach. Learn. Res., 12 (2011), pp. 2121–2159. [10]W. E, C. Ma, and L. Wu,A comparative analysis of optimization and generalization properties of two-layer neural network and random feature models under gradient descent dynamics, Sci. China ...
work page 2011
-
[2]
[14]Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner,Gradient-based learning applied to document recognition, Proc. IEEE, 86 (1998), pp. 2278–2324. [15]Y. Liu and Y. Gu,Layer separation deep learning model with auxiliary variables for partial differential equations, J. Comput. Phys., 543 (2025), p. 114414. [16]Y. Liu, Y. Gu, and M. K. Ng,Deep learning optim...
-
[3]
[17]S. Oymak and M. Soltanolkotabi,Toward moderate overparameterization: Global conver- gence guarantees for training shallow neural networks, IEEE J. Sel. Areas Inf. Theory, 1 (2020), pp. 84–105. [18]I. Sutskever, J. Martens, G. Dahl, and G. Hinton,On the importance of initialization and momentum in deep learning, in Proceedings of the 30th International...
work page 2020
- [4]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.