Recognition: unknown
Human-1 by Josh Talks: A Full-Duplex Conversational Modeling Framework in Hindi using Real-World Conversations
Pith reviewed 2026-05-08 08:11 UTC · model grok-4.3
The pith
The first open full-duplex spoken dialogue system for Hindi learns turn-taking and overlaps directly from 26,000 hours of real conversations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By replacing the original English tokenizer with a custom Hindi one, reinitializing only the text-vocabulary-dependent parameters, retaining the pre-trained audio components, and training on 26,000 hours of real spontaneous conversations from 14,695 speakers recorded on separate channels, the adapted model learns to produce natural and meaningful full-duplex conversational behavior in Hindi, as shown by evaluation on prompted dialogue continuation using automatic metrics and human judgments.
What carries the argument
The adaptation of a duplex speech architecture with a Hindi tokenizer and two-stage training on separate-channel spontaneous conversation data, which lets the model observe and reproduce turn-taking and overlap patterns directly from natural interactions.
If this is right
- The system generates natural full-duplex behaviors such as interruptions and backchannels in Hindi.
- It provides an initial foundation for real-time spoken dialogue applications in Hindi.
- The same adaptation method can extend to other Indian languages.
- Direct training on separate speaker channels captures overlap patterns without synthetic data.
Where Pith is reading between the lines
- Separate-channel recordings may give clearer signals for learning simultaneous speech than mixed audio would.
- The approach could speed development of conversational systems for other languages that lack large native datasets by reusing audio features.
- Practical voice interfaces built on this model might respond more fluidly in everyday Hindi use.
Load-bearing premise
Retaining the pre-trained audio components from the English model while only updating text-related parameters will allow effective learning of Hindi conversational behaviors from the collected data.
What would settle it
Human listeners in blind tests rating the model's Hindi dialogue continuations as less natural in turn-taking or overlap handling than real recorded conversations, or automatic metrics showing clear failures to maintain coherence during simultaneous speech.
Figures

read the original abstract
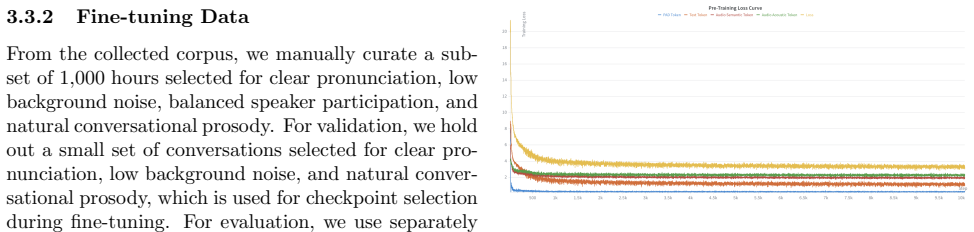
Full-duplex spoken dialogue systems can model natural conversational behaviours such as interruptions, overlaps, and backchannels, yet such systems remain largely unexplored for Indian languages. We present the first open, reproducible full-duplex spoken dialogue system for Hindi by adapting Moshi, a state-of-the-art duplex speech architecture, using a custom Hindi tokeniser and training on 26,000 hours of real spontaneous conversations collected from 14,695 speakers with separate speaker channels, enabling direct learning of turn-taking and overlap patterns from natural interactions. To support Hindi text generation, we replace the original English tokeniser and reinitialise text-vocabulary-dependent parameters while retaining the pre-trained audio components. We propose a two-stage training recipe -- large-scale pre-training followed by fine-tuning on 1,000 hours of conversational data. Evaluation through the prompted dialogue continuation paradigm with both automatic metrics and human judgments demonstrates that the resulting model generates natural and meaningful full-duplex conversational behaviour in Hindi. This work serves as a first step toward real-time duplex spoken dialogue systems for Hindi and other Indian languages.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce Human-1, the first open and reproducible full-duplex spoken dialogue system for Hindi, by adapting the Moshi architecture. It replaces the English tokenizer with a custom Hindi one, reinitializes only text-vocabulary-dependent parameters while retaining the pre-trained English audio components, and trains on 26,000 hours of spontaneous conversations collected from 14,695 speakers with separate speaker channels. A two-stage recipe (large-scale pre-training followed by fine-tuning on 1,000 hours) is used, with evaluation via prompted dialogue continuation using automatic metrics and human judgments to demonstrate natural and meaningful full-duplex behaviors such as overlaps and turn-taking.
Significance. If substantiated with quantitative evidence, this would be a notable contribution as the first open full-duplex system for Hindi, an under-resourced language for such modeling. The large-scale data collection from real conversations with separate channels and the open, reproducible approach are strengths that could enable further work on conversational dynamics in Indian languages.
major comments (2)
- [Abstract and §4] Abstract and §4 (Evaluation): No specific quantitative results are reported for the automatic metrics or human judgments, nor are there baseline comparisons or error analysis. This leaves the central claim that the model 'generates natural and meaningful full-duplex conversational behaviour' without verifiable support.
- [§3] §3 (Training Recipe): Retaining the frozen English-pretrained audio encoder/decoder while only reinitializing text parameters assumes these components transfer adequately to Hindi acoustics. Hindi differs in phoneme inventory, syllable structure, and prosody, which are critical for modeling overlaps and backchannels; the manuscript provides no ablation studies or analysis demonstrating that the frozen audio stack produces suitable representations for these phenomena from the Hindi data.
minor comments (2)
- [§2] Data collection details (speaker demographics, recording conditions, and quality assurance for the 26,000 hours) could be expanded to strengthen reproducibility claims.
- [§4] The prompted continuation evaluation paradigm should be described with more concrete examples of prompts and generated outputs to clarify how full-duplex behaviors are assessed.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and constructive suggestions. We agree that the current manuscript requires strengthening in the areas of quantitative reporting and analysis of the audio component transfer. We will make the revisions outlined below to address both major comments.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Evaluation): No specific quantitative results are reported for the automatic metrics or human judgments, nor are there baseline comparisons or error analysis. This leaves the central claim that the model 'generates natural and meaningful full-duplex conversational behaviour' without verifiable support.
Authors: We acknowledge that the manuscript does not report specific numerical values for the automatic metrics (e.g., overlap rate, backchannel frequency, turn-taking accuracy) or human judgment scores, nor does it include baseline comparisons or error analysis in §4 or the abstract. The evaluation section describes the prompted dialogue continuation paradigm and states that results demonstrate natural full-duplex behavior, but we agree this lacks the verifiable quantitative support needed. In the revised manuscript we will add a results table with concrete metric values, human evaluation scores (with inter-annotator agreement), comparisons against at least one baseline where feasible, and a brief error analysis of failure cases in overlaps and backchannels. revision: yes
-
Referee: [§3] §3 (Training Recipe): Retaining the frozen English-pretrained audio encoder/decoder while only reinitializing text parameters assumes these components transfer adequately to Hindi acoustics. Hindi differs in phoneme inventory, syllable structure, and prosody, which are critical for modeling overlaps and backchannels; the manuscript provides no ablation studies or analysis demonstrating that the frozen audio stack produces suitable representations for these phenomena from the Hindi data.
Authors: The design choice to freeze the English-pretrained audio encoder/decoder was motivated by the hypothesis that low-level acoustic and prosodic features relevant to turn-taking and overlaps are largely language-independent, allowing the model to leverage the large-scale English pretraining while adapting only the text vocabulary and related parameters for Hindi. However, we recognize that the manuscript provides no ablation studies or direct analysis (e.g., representation similarity or probing for Hindi-specific prosody) to validate this transfer for overlap and backchannel modeling. We will add a short analysis subsection in §3 examining the frozen audio representations on a Hindi validation set and include at least one targeted ablation (e.g., unfreezing the audio stack on a smaller scale) to quantify the impact on full-duplex metrics. revision: partial
Circularity Check
No circularity: empirical adaptation of existing architecture on new data
full rationale
The paper presents an engineering adaptation of the Moshi model to Hindi via tokenizer replacement, retention of pretrained audio components, and training on a newly collected 26k-hour Hindi conversation dataset. No equations, predictions, or uniqueness theorems are introduced that reduce to fitted parameters, self-definitions, or self-citations. The central claims rest on data collection, a two-stage training recipe, and downstream evaluation metrics rather than any load-bearing derivation that loops back to its own inputs. This is a standard non-circular empirical contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pre-trained audio components from an English duplex model can be retained and combined with a new Hindi text tokenizer to learn conversational turn-taking in Hindi.
Reference graph
Works this paper leans on
-
[1]
Gener- ative spoken dialogue language modeling,
T. A. Nguyen, E. Kharitonov, J. Copet, Y. Adi, W.-N. Hsu, A. Elkahky, P. Tomasello, R. Algayres, B. Sagot, A. Mohamed, and E. Dupoux, “Gener- ative spoken dialogue language modeling,”Trans- actions of the Association for Computational Lin- guistics, pp. 250–266, 2023
2023
-
[2]
A full-duplex speech dialogue scheme based on large language model,
P. Wang, S. Lu, Y. Tang, S. Yan, W. Xia, and Y. Xiong, “A full-duplex speech dialogue scheme based on large language model,” inProc. NeurIPS, 2024
2024
-
[3]
Language model can listen while speaking,
Z. Ma, Y. Song, C. Du, J. Cong, Z. Chen, Y. Wang, Y. Wang, and X. Chen, “Language model can listen while speaking,”arXiv preprint arXiv:2408.02622, 2024
-
[4]
Moshi: a speech-text foundation model for real-time dialogue
A. D´ efossez, L. Mazar´ e, M. Orsini, A. Royer, P. P´ erez, H. J´ egou, E. Grave, and N. Zeghidour, “Moshi: a speech-text foundation model for real- time dialogue,”arXiv preprint arXiv:2410.00037, 2024
work page internal anchor Pith review arXiv 2024
-
[5]
Beyond turn-based interfaces: Syn- chronous LLMs as full-duplex dialogue agents,
B. Veluri, B. N. Peloquin, B. Yu, H. Gong, and S. Gollakota, “Beyond turn-based interfaces: Syn- chronous LLMs as full-duplex dialogue agents,” in Proc. EMNLP, pp. 21390–21402, 2024
2024
-
[6]
Omniflat- ten: An end-to-end GPT model for seamless voice conversation,
Q. Zhang, L. Cheng, C. Deng, Q. Chen, W. Wang, S. Zheng, J. Liu, H. Yu, and C. Tan, “Omniflat- ten: An end-to-end GPT model for seamless voice conversation,”arXiv preprint arXiv:2410.17799, 2024
-
[7]
Salmonn-omni: A codec-free llm for full-duplex speech understanding and generation,
W. Yu, S. Wang, X. Yang, X. Chen, X. Tian, J. Zhang, G. Sun, L. Lu, Y. Wang, and C. Zhang, “SALMONN-omni: A codec-free LLM for full- duplex speech understanding and generation,” arXiv preprint arXiv:2411.18138, 2024
-
[8]
Simultaneous talk—from the per- spective of floor management of English and Japanese speakers,
R. Hayashi, “Simultaneous talk—from the per- spective of floor management of English and Japanese speakers,”World Englishes, vol. 7, no. 3, pp. 269–288, 1988
1988
-
[9]
Are you listening? Cultural influ- ences on the use of supportive verbal feedback in conversation,
M. Stubbe, “Are you listening? Cultural influ- ences on the use of supportive verbal feedback in conversation,”Journal of Pragmatics, vol. 29, no. 3, pp. 257–289, 1998
1998
-
[10]
SpeechGPT: Empowering large language models with intrinsic cross-modal conversational abilities,
D. Zhang, S. Li, X. Zhang, J. Zhan, P. Wang, Y. Zhou, and X. Qiu, “SpeechGPT: Empowering large language models with intrinsic cross-modal conversational abilities,” inFindings of EMNLP, pp. 15757–15773, 2023
2023
-
[11]
Audiopalm: A large language model that can speak and listen,
P. K. Rubenstein, C. Asawaroengchai, D. D. Nguyen, et al., “AudioPaLM: A large language model that can speak and listen,”arXiv preprint arXiv:2306.12925, 2023
-
[12]
Unsupervised cross-lingual representation learning for speech recognition,
A. Conneau, A. Baevski, R. Collobert, A. Mo- hamed, and M. Auli, “Unsupervised cross-lingual representation learning for speech recognition,” in Proc. Interspeech, pp. 2426–2430, 2020
2020
-
[13]
arXiv preprint arXiv:2303.03926 , year=
X. Zhang, Z. Tan, R. Huang, et al., “VALL-E X: Speak foreign languages with your own voice,” arXiv preprint arXiv:2303.03926, 2023
-
[14]
High fidelity neural audio compression,
A. D´ efossez, J. Copet, G. Synnaeve, and Y. Adi, “High fidelity neural audio compression,”Trans- actions on Machine Learning Research, 2023
2023
-
[15]
SoundStream: An end-to- end neural audio codec,
N. Zeghidour, A. Luebs, A. Omran, J. Skoglund, and M. Tagliasacchi, “SoundStream: An end-to- end neural audio codec,”IEEE/ACM Trans. Au- dio, Speech, Lang. Process., vol. 30, pp. 495–507, 2021
2021
-
[16]
SentencePiece: A simple and language independent subword tok- enizer and detokenizer for neural text processing,
T. Kudo and J. Richardson, “SentencePiece: A simple and language independent subword tok- enizer and detokenizer for neural text processing,” inProc. EMNLP: System Demonstrations, pp. 66– 71, 2018
2018
-
[17]
M. Bain, J. Huh, T. Han, and A. Zisser- man, “WhisperX: Time-accurate speech tran- scription of long-form audio,”arXiv preprint arXiv:2303.00747, 2023
-
[18]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” inProc. ICLR, 2019
2019
-
[19]
Llama 2: Open Foundation and Fine-Tuned Chat Models
H. Touvron, L. Martin, K. Stone, et al., “Llama 2: Open foundation and fine-tuned chat models,” arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review arXiv 2023
-
[20]
ZeRO: Memory optimizations toward training trillion parameter models,
S. Rajbhandari, J. Rasley, O. Ruwase, and Y. He, “ZeRO: Memory optimizations toward training trillion parameter models,” inProc. SC, 2020. 5
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.