A Taxonomy and Resolution Strategy for Client-Level Disagreements in Federated Learning
Pith reviewed 2026-05-08 07:06 UTC · model grok-4.3
The pith
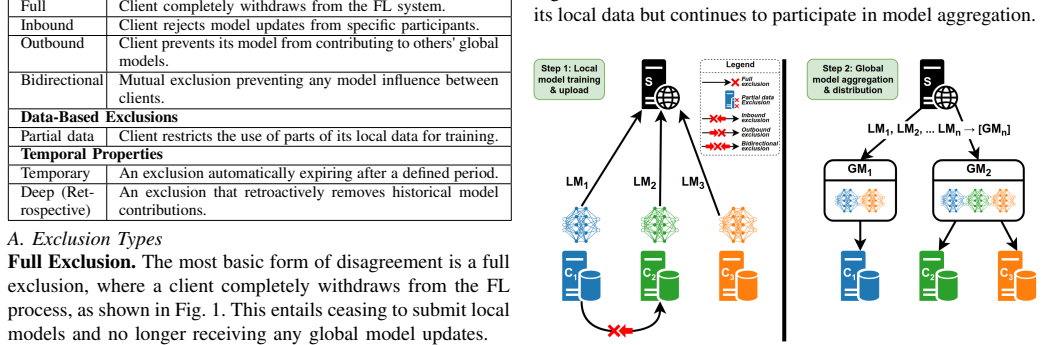
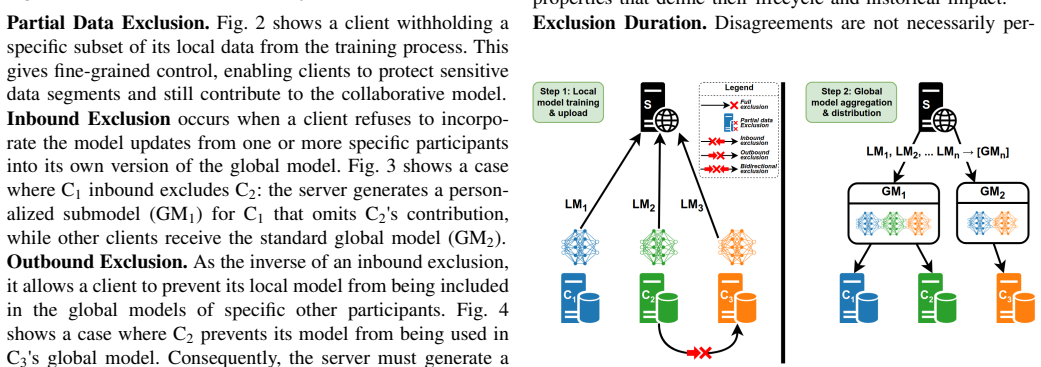
Client disagreements in federated learning are managed by running isolated model update tracks that keep excluded clients from mixing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce a taxonomy of client-level disagreements and a multi-track resolution strategy that guarantees strict client exclusion by creating and managing isolated model update paths, thereby preventing cross-contamination and unfairness issues present in naive strategies.
What carries the argument
The multi-track resolution strategy that creates isolated model update paths for groups of non-disagreeing clients and routes updates only within each track.
If this is right
- Federated learning becomes viable in competitive or regulated environments where unconditional collaboration is impossible.
- Naive averaging across all clients no longer produces unfair or contaminated models when exclusions exist.
- Server overhead stays under one millisecond per round regardless of the number of disagreement patterns.
- Client training cost rises with overlapping tracks but can be lowered through submodel reuse.
Where Pith is reading between the lines
- The same isolation idea might apply to other distributed training setups where participants have partial trust.
- Policy-driven exclusions could be detected automatically instead of requiring manual specification.
- Real deployments may need mechanisms to dynamically merge or split tracks as disagreements change over time.
Load-bearing premise
The custom simulation system accurately captures how client disagreements would unfold in real federated learning deployments and that clients can safely join multiple tracks without privacy or resource violations.
What would settle it
A production federated learning run in which excluded clients' data still influences the shared model or in which clients cannot sustain the extra training load from multiple tracks.
Figures









read the original abstract
Federated Learning (FL) typically assumes unconditional collaboration, a premise that overlooks the complexities of real-world, multi-stakeholder environments in which clients may need to exclude one another for strategic, regulatory, or competitive reasons. This paper addresses this gap, which we term 'client-level disagreements,' by first introducing a taxonomy of such scenarios. We then propose a robust, multi-track resolution strategy that guarantees strict client exclusion by creating and managing isolated model update paths ('tracks'), thereby preventing the cross-contamination and unfairness issues present in naive strategies. Through an empirical evaluation of our custom simulation system across 34 scenarios using the MNIST and N-CMAPSS datasets, we validate that our approach correctly handles permanent, temporal, and overlapping disagreement patterns. Our scalability analysis reveals the server-side resolution algorithm's overhead is negligible (<1 ms per round) even under heavy load. The primary scalability constraint is the client-side training load from participating in multiple tracks, a cost that we show can be effectively mitigated by a submodel reuse strategy. This work presents a scalable and architecturally sound method for managing client-level disagreements, and enhances the practical applicability of FL in settings where policy compliance and strategic control are non-negotiable.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a taxonomy of client-level disagreements in federated learning arising from strategic, regulatory, or competitive reasons, and proposes a multi-track resolution strategy that creates isolated model-update paths ('tracks') to enforce strict client exclusion and prevent cross-contamination. It reports results from a custom simulation system evaluated across 34 scenarios on the MNIST and N-CMAPSS datasets, claiming correct handling of permanent, temporal, and overlapping disagreement patterns, negligible server-side overhead (<1 ms per round), and effective mitigation of client-side costs via submodel reuse.
Significance. If the claims hold, the work would meaningfully extend federated learning to multi-stakeholder settings where unconditional collaboration is unrealistic, by providing an architecturally explicit mechanism for policy-compliant exclusion. The breadth of 34 simulated scenarios across two datasets and the identification of submodel reuse as a practical mitigation are strengths that could improve deployability.
major comments (2)
- [§5] §5 (Empirical Evaluation): The validation of the central claim that the multi-track strategy 'correctly handles permanent, temporal, and overlapping disagreement patterns' rests solely on results from an unvalidated custom simulator; no details are given on how disagreement patterns were generated, no baselines or quantitative metrics (e.g., accuracy deltas, exclusion violation rates) are reported, and no comparison to real-world FL disagreement traces is provided. This directly undermines the strength of the correctness guarantee.
- [§4] §4 (Resolution Strategy): The assertion that isolated tracks 'guarantee strict client exclusion' and prevent cross-contamination in overlapping cases is presented without a formal invariant, proof, or even a pseudocode-level argument showing that submodel reuse preserves the exclusion property; the guarantee therefore reduces to simulation outcomes whose fidelity is not established.
minor comments (2)
- [Abstract] Abstract and §2: 'N-CMAPSS' is used without expansion on first occurrence; a brief parenthetical description of the dataset would improve accessibility.
- [§3] §3 (Taxonomy): The taxonomy categories are introduced narratively but lack a compact tabular summary or decision tree that would make the distinctions between permanent/temporal/overlapping cases immediately usable by readers.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and describe the revisions that will be incorporated to strengthen the manuscript.
read point-by-point responses
-
Referee: [§5] §5 (Empirical Evaluation): The validation of the central claim that the multi-track strategy 'correctly handles permanent, temporal, and overlapping disagreement patterns' rests solely on results from an unvalidated custom simulator; no details are given on how disagreement patterns were generated, no baselines or quantitative metrics (e.g., accuracy deltas, exclusion violation rates) are reported, and no comparison to real-world FL disagreement traces is provided. This directly undermines the strength of the correctness guarantee.
Authors: We acknowledge that the current presentation of the empirical evaluation in §5 lacks sufficient detail on the simulation methodology. In the revised manuscript we will expand this section to explicitly describe the generation of the 34 disagreement patterns, including the precise rules and parameter settings used to instantiate permanent (fixed exclusion sets across rounds), temporal (time-varying exclusions), and overlapping (partial client-group intersections) cases. We will report quantitative metrics including test accuracy, accuracy deltas relative to non-exclusion baselines, and exclusion-violation rates (which remain zero across all scenarios). Standard baselines (FedAvg without exclusion and a naive per-client exclusion approach) will be added for direct comparison. Regarding real-world traces, no public datasets of client-level disagreements exist because such information is proprietary and privacy-sensitive in multi-stakeholder deployments; our simulations were constructed to exhaustively instantiate the taxonomy. We will add an explicit limitations paragraph discussing this point and the coverage provided by the synthetic scenarios. revision: yes
-
Referee: [§4] §4 (Resolution Strategy): The assertion that isolated tracks 'guarantee strict client exclusion' and prevent cross-contamination in overlapping cases is presented without a formal invariant, proof, or even a pseudocode-level argument showing that submodel reuse preserves the exclusion property; the guarantee therefore reduces to simulation outcomes whose fidelity is not established.
Authors: We agree that §4 would benefit from an explicit argument for the exclusion property. The multi-track design maintains separate parameter sets for each track; clients are assigned only to tracks consistent with their agreement sets, and aggregation occurs independently per track. In overlapping scenarios, a client may participate in multiple tracks, but updates never cross track boundaries. Submodel reuse copies parameters from a prior track only when the client sets of the source and target tracks satisfy the same exclusion constraints, thereby preserving isolation. We will add pseudocode to §4 that details track creation, client-to-track assignment, per-track aggregation, and the reuse predicate. This supplies the requested pseudocode-level argument. While a machine-checked formal invariant is outside the scope of the present applied work, the construction ensures exclusion by design; the expanded simulation metrics will provide supporting evidence. revision: yes
Circularity Check
No circularity: new algorithmic construction validated by independent simulation
full rationale
The paper defines a taxonomy of client-level disagreements and introduces a multi-track resolution strategy as an original algorithmic design. Its central claims (correct handling of disagreement patterns and negligible server overhead) are established through empirical runs on a custom simulator across 34 scenarios; these runs test the algorithm's behavior rather than deriving a fitted quantity or renaming an input. No equations, self-definitional loops, or load-bearing self-citations appear in the provided text. The simulation is treated as an external validation mechanism, not as a tautological restatement of the strategy itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Clients can participate in multiple isolated tracks without violating data privacy or regulatory constraints
invented entities (2)
-
tracks
no independent evidence
-
client-level disagreements
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Adaptive personalized federated learning,
[Online]. Available: http://arxiv.org/abs/2003.13461 [5]W. Li et al., “Enhancing collaborative intrusion detection via disagreement-based semi-supervised learning in IoT en- vironments,”Journal of Network and Computer Applications, vol. 161, Jul
-
[2]
Fine-tuning Global Model via Data-Free Knowledge Distillation for Non-IID Federated Learning,
[9]L. Zhang et al., “Fine-tuning Global Model via Data-Free Knowledge Distillation for Non-IID Federated Learning,” en, in 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA: IEEE, Jun
2022
-
[3]
arXiv: 2006.08848[cs.LG]. [Online]. Avail- able: https://arxiv.org/abs/2006.08848 [22]A. Fallah et al.,Personalized federated learning: A meta- learning approach,
-
[4]
Personalized federated learning: A meta-learning approach,
arXiv: 2002.07948[cs.LG]. [On- line]. Available: https://arxiv.org/abs/2002.07948 [23]X. Gao et al., “Verifi: Towards verifiable federated unlearning,” Transactions on Dependable and Secure Computing,
-
[5]
A comprehensive review on granularity perspective of the access control models in cloud computing,
[29]A. K. Routh et al., “A comprehensive review on granularity perspective of the access control models in cloud computing,” in IEEE International Conference on Interdisciplinary Approaches in Technology and Management for Social Innovation, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.