Recognition: unknown
When Does Removing LayerNorm Help? Activation Bounding as a Regime-Dependent Implicit Regularizer
Pith reviewed 2026-05-08 08:25 UTC · model grok-4.3
The pith
Dynamic Tanh replaces LayerNorm with learned activation bounding that regularizes only in severely data-scarce regimes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
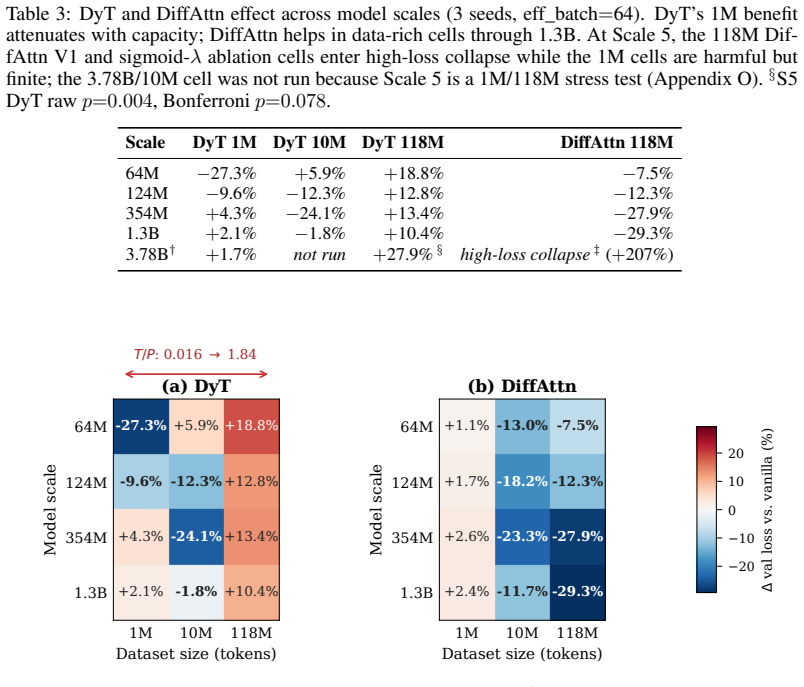
Dynamic Tanh removes LayerNorm by bounding activations with a learned tanh(alpha x). This bounding functions as a regime-dependent implicit regularizer: it improves validation loss by 27.3% at 64M parameters on 1M tokens but worsens loss by 18.8% at 64M on 118M tokens. The benefit disappears with added capacity while the penalty grows to +27.9%. Saturation reaches 49% of activations at 1M tokens versus 23% at 118M tokens. A 500-step saturation heuristic predicts the sign of DyT's effect with 75% raw accuracy on the calibration set. HardTanh reproduces the regime pattern, raising alpha at high data reduces the penalty, and vanilla training plus dropout matches DyT's data-rich loss.
What carries the argument
Learned tanh(alpha x) bounding in Dynamic Tanh, which induces activation saturation that supplies implicit regularization whose net effect flips with the data-to-compute ratio.
If this is right
- DyT is advantageous only when training remains compute-limited (T/P below roughly 1.84).
- Raising the learned alpha at high token counts monotonically reduces DyT's performance penalty.
- HardTanh clipping produces the same regime-dependent pattern as DyT.
- Saturation rates above approximately 40% correlate with positive DyT effects on validation loss.
- Llama-scale DyT collapse occurs specifically when SwiGLU gates saturate, separating convergence from failure across seeds.
Where Pith is reading between the lines
- The saturation heuristic could be used at the start of training to decide whether to keep or remove LayerNorm without running full ablations.
- Similar learned bounding might substitute for other normalization layers in low-data vision or language settings.
- Scaling curves that ignore regime-dependent regularization may mis-predict optimal model size when data is the bottleneck.
Load-bearing premise
Performance differences arise from the saturation-based regularization rather than other uncontrolled differences in the training runs.
What would settle it
A controlled comparison in which dropout or weight decay is tuned to match DyT's effective regularization strength without any bounding, yet the low-data benefit and high-data penalty both disappear.
Figures





read the original abstract
Dynamic Tanh (DyT) removes LayerNorm by bounding activations with a learned tanh(alpha x). We show that this bounding is a regime-dependent implicit regularizer, not a uniformly beneficial replacement. Across GPT-2-family models spanning 64M to 3.78B parameters and 1M to 118M tokens, with Llama and ViT cross-checks, DyT improves validation loss by 27.3% at 64M/1M but worsens it by 18.8% at 64M/118M; the 1M benefit vanishes with capacity (+1.7% at 3.78B), while the 118M penalty reaches +27.9%. The mechanism is measurable: 49% of DyT activations saturate at 1M versus 23% at 118M, and a 500-step saturation heuristic classifies DyT's sign with 75% raw in-sample accuracy on the 12-cell GPT-2 calibration set (AUC 0.75; 64% when adding Scale 5 stress cells), correctly labels 3/3 Llama checks, but only reaches 50% raw leave-one-scale-out accuracy. Three interventions support the bounding explanation: HardTanh reproduces the regime pattern, increasing alpha at 118M monotonically reduces DyT's penalty, and vanilla+dropout(p=0.5) matches DyT's data-rich loss. We also localize Llama-DyT collapse to SwiGLU gating, where saturation separates collapse from convergence in a 3-seed component ablation (r=0.94). Scope: all experiments are compute-limited (T/P < 1.84), below Chinchilla-optimal training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Dynamic Tanh (DyT) as a LayerNorm replacement via learned tanh(αx) activation bounding. It claims this bounding functions as a regime-dependent implicit regularizer, improving validation loss by 27.3% at 64M/1M tokens but worsening it by 18.8% at 64M/118M (with the low-data benefit vanishing at 3.78B scale and the high-data penalty reaching 27.9%). The mechanism is supported by saturation rates (49% at 1M vs. 23% at 118M), a 500-step saturation heuristic (75% in-sample accuracy, AUC 0.75 on GPT-2 calibration; 50% leave-one-scale-out), and three interventions (HardTanh reproduction, α-increase at 118M, dropout(p=0.5) matching). Cross-checks on Llama/ViT and localization of Llama-DyT collapse to SwiGLU (r=0.94) are included. All experiments are compute-limited (T/P < 1.84, below Chinchilla optimality).
Significance. If the causal attribution to activation bounding holds, the work supplies a practical, measurable criterion for when LayerNorm removal is beneficial and a concrete proxy (saturation heuristic) for implicit regularization strength. The scale sweeps, cross-architecture checks, and explicit performance deltas constitute a useful empirical contribution in the low-compute regime, though the limited scope restricts immediate generalization.
major comments (3)
- [§4.3] §4.3 (intervention experiments): HardTanh reproduces the regime-dependent pattern but still removes LayerNorm, so observed differences cannot be attributed specifically to tanh bounding rather than ancillary changes in per-layer scaling, gradient flow, or optimization trajectory. This leaves the central causal claim under-isolated.
- [§5.1] §5.1 (saturation heuristic): The 500-step classifier reaches only 75% raw in-sample accuracy (AUC 0.75) on the 12-cell GPT-2 set and falls to 50% leave-one-scale-out; this modest performance weakens the assertion that saturation percentages (49% vs. 23%) measurably explain DyT sign and performance differences.
- [§4.4] §4.4 (α-tuning results): Monotonic reduction of the 118M DyT penalty with increasing α is consistent with tunable bounding, yet appears inconsistent with the lower saturation rate (23%) being the source of the penalty, since higher α should increase saturation if bounding drives the effect.
minor comments (3)
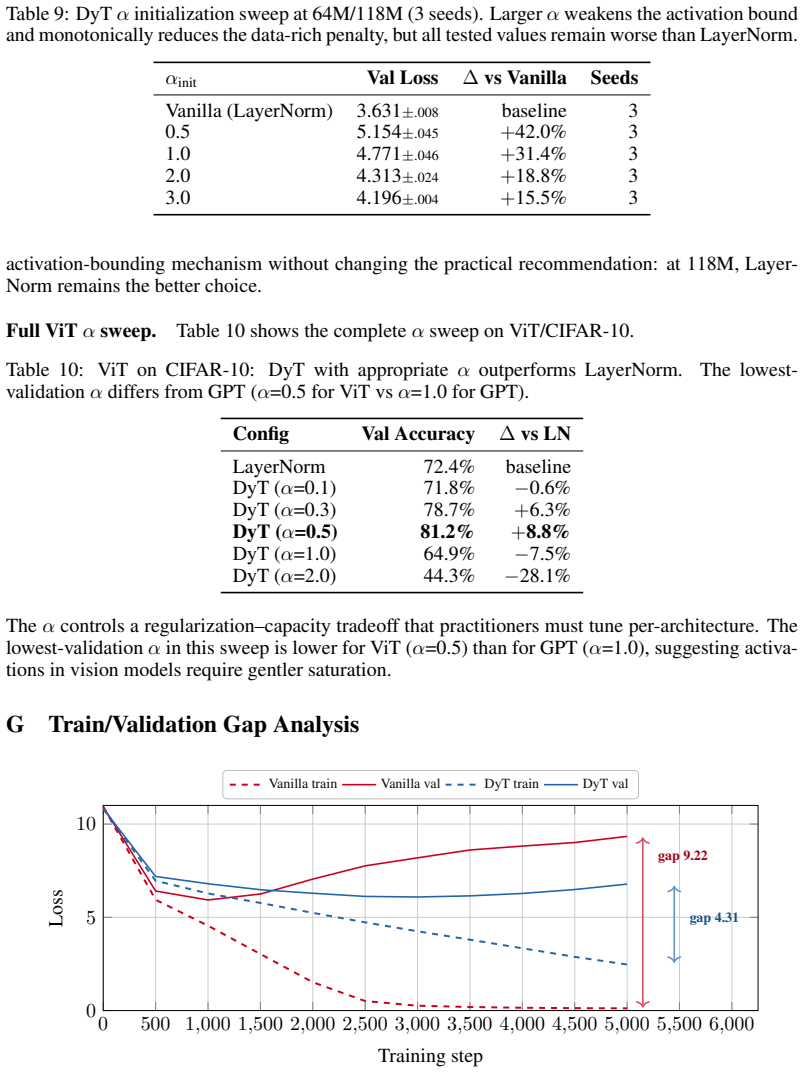
- [Methods] Methods section: key deltas (27.3%, 18.8%, etc.) are reported without error bars or seed statistics, complicating assessment of whether regime differences are statistically reliable.
- [Abstract and §3] Abstract and §3: baseline details for vanilla comparisons (hyperparameter re-tuning after LayerNorm removal, optimizer settings) are insufficiently specified.
- [Figures] Figure captions: activation-distribution plots would benefit from explicit saturation-threshold annotations and per-scale labeling.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive feedback on our manuscript. We have carefully considered each major comment and made revisions to the paper to address the concerns about causal attribution, the strength of the saturation heuristic, and the consistency of the α-tuning results. Our point-by-point responses are provided below.
read point-by-point responses
-
Referee: [§4.3] §4.3 (intervention experiments): HardTanh reproduces the regime-dependent pattern but still removes LayerNorm, so observed differences cannot be attributed specifically to tanh bounding rather than ancillary changes in per-layer scaling, gradient flow, or optimization trajectory. This leaves the central causal claim under-isolated.
Authors: We agree that using HardTanh as an intervention does not completely isolate the contribution of the tanh bounding function from other effects of removing LayerNorm, such as changes in scaling or optimization dynamics. The HardTanh experiment was intended to show that a fixed bounding activation can reproduce the regime-dependent behavior observed with DyT, supporting the role of activation bounding as the key mechanism. To better address this, we have revised the discussion in §4.3 to emphasize that the interventions collectively point to bounding rather than the specific functional form, and we acknowledge the need for more granular controls in future work. We have not added new experiments due to computational limitations. revision: partial
-
Referee: [§5.1] §5.1 (saturation heuristic): The 500-step classifier reaches only 75% raw in-sample accuracy (AUC 0.75) on the 12-cell GPT-2 set and falls to 50% leave-one-scale-out; this modest performance weakens the assertion that saturation percentages (49% vs. 23%) measurably explain DyT sign and performance differences.
Authors: The referee correctly notes the limitations in the predictive power of the saturation heuristic. With 75% in-sample accuracy and only 50% in leave-one-scale-out validation, the heuristic provides a suggestive but not definitive link between saturation rates and performance differences. We have updated §5.1 to describe the heuristic more cautiously as a preliminary indicator of implicit regularization strength rather than a reliable classifier, and we highlight the cross-validation results to temper the claims. This revision better reflects the empirical support while retaining the observation that saturation rates differ substantially across regimes. revision: yes
-
Referee: [§4.4] §4.4 (α-tuning results): Monotonic reduction of the 118M DyT penalty with increasing α is consistent with tunable bounding, yet appears inconsistent with the lower saturation rate (23%) being the source of the penalty, since higher α should increase saturation if bounding drives the effect.
Authors: This is a perceptive point regarding potential inconsistency in our mechanistic interpretation. If the high-data penalty were primarily due to insufficient bounding (low saturation), increasing α should exacerbate the penalty by increasing saturation, yet we observe the opposite. We interpret this as suggesting that the effect of bounding may depend on factors beyond the raw saturation percentage, such as the timing or distribution of saturated activations during training. We have added a paragraph in §4.4 discussing this observation and its implications for the regime-dependent regularizer hypothesis, noting it as an area for further investigation. No changes to the experimental results were needed. revision: yes
Circularity Check
No circularity; empirical measurements and ablations stand independently
full rationale
The paper advances no derivation chain, first-principles equations, or predictions that reduce to fitted quantities defined within the work itself. All load-bearing claims rest on direct experimental outcomes: validation-loss deltas across scales, measured saturation fractions (49% vs 23%), an explicitly in-sample saturation heuristic whose accuracy is reported as such, and three ablation interventions (HardTanh, alpha scaling, dropout matching). No self-citation is invoked to justify uniqueness or to carry the central mechanism; the scope statement and cross-checks (Llama, ViT) are external to any internal fit. The analysis is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Does your optimizer care how you normalize? Normalization-Optimizer coupling in LLM training
Abdelrahman Abouzeid. Does your optimizer care how you normalize? Normalization-Optimizer coupling in LLM training. ArXiv preprint, abs/2604.01563, 2026. URL https://arxiv.org/abs/2604.01563
-
[2]
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebr \'o n, and Sumit Sanghai. GQA : Training generalized multi-query transformer models from multi-head checkpoints. ArXiv preprint, abs/2305.13245, 2023. URL https://arxiv.org/abs/2305.13245
work page internal anchor Pith review arXiv 2023
-
[3]
Subcritical Signal Propagation at Initialization in Normalization-Free Transformers
Sergey Alekseev. Subcritical signal propagation at initialization in normalization-free transformers. ArXiv preprint, abs/2604.11890, 2026. URL https://arxiv.org/abs/2604.11890
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Hoyoon Byun, Youngjun Choi, Taero Kim, Sungrae Park, and Kyungwoo Song. Bounded hyperbolic tangent: A stable and efficient alternative to pre-layer normalization in large language models. ArXiv preprint, abs/2601.09719, 2026. URL https://arxiv.org/abs/2601.09719
-
[5]
WeightWatcher : Diagnostics for deep neural networks
CalculatedContent . WeightWatcher : Diagnostics for deep neural networks. https://github.com/CalculatedContent/WeightWatcher, 2023
2023
-
[6]
Yueyang Cang, Yuhang Liu, Xiaoteng Zhang, Erlu Zhao, and Li Shi. DINT transformer. ArXiv preprint, abs/2501.17486, 2025. URL https://arxiv.org/abs/2501.17486
-
[7]
Stronger normalization-free transformers
Mingzhi Chen, Taiming Lu, Jiachen Zhu, Mingjie Sun, and Zhuang Liu. Stronger normalization-free transformers. ArXiv preprint, abs/2512.10938, 2025. URL https://arxiv.org/abs/2512.10938
-
[8]
Why do we need weight decay in modern deep learning? ArXiv, abs/2310.04415, 2023
Francesco D'Angelo, Maksym Andriushchenko, Aditya Varre, and Nicolas Flammarion. Why do we need weight decay in modern deep learning? ArXiv preprint, abs/2310.04415, 2023. URL https://arxiv.org/abs/2310.04415
-
[9]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. ArXiv preprint, abs/2010.11929, 2020. URL https://arxiv.org/abs/2010.11929
work page internal anchor Pith review arXiv 2010
-
[10]
Training Compute-Optimal Large Language Models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models. ArXiv preprint, abs/2203.15556, 2022. URL https://arxiv.org/abs/2203.15556
work page internal anchor Pith review arXiv 2022
-
[11]
Gated removal of normalization in transformers enables stable training and efficient inference
Andrei Kanavalau, Carmen Amo Alonso, and Sanjay Lall. Gated removal of normalization in transformers enables stable training and efficient inference. ArXiv preprint, abs/2602.10408, 2026. URL https://arxiv.org/abs/2602.10408
-
[12]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. ArXiv preprint, abs/2001.08361, 2020. URL https://arxiv.org/abs/2001.08361
work page internal anchor Pith review arXiv 2001
-
[13]
Nikita Karagodin, Shu Ge, Yury Polyanskiy, and Philippe Rigollet. Normalization in attention dynamics. ArXiv preprint, abs/2510.22026, 2025. URL https://arxiv.org/abs/2510.22026
-
[14]
nanogpt, 2023
Andrej Karpathy. nanogpt, 2023. URL https://github.com/karpathy/nanoGPT
2023
-
[15]
Peri- LN : Revisiting normalization layer in the transformer architecture
Jeonghoon Kim, Byeongchan Lee, Cheonbok Park, Yeontaek Oh, Beomjun Kim, Taehwan Yoo, Seongjin Shin, Dongyoon Han, Jinwoo Shin, and Kang Min Yoo. Peri- LN : Revisiting normalization layer in the transformer architecture. ArXiv preprint, abs/2502.02732, 2025. URL https://arxiv.org/abs/2502.02732
-
[16]
Grouped differential attention
Junghwan Lim, Sungmin Lee, Dongseok Kim, Wai Ting Cheung, Beomgyu Kim, Taehwan Kim, Haesol Lee, Junhyeok Lee, Dongpin Oh, and Eunhwan Park. Grouped differential attention. ArXiv preprint, abs/2510.06949, 2025. URL https://arxiv.org/abs/2510.06949
-
[17]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6--9, 2019 . OpenReview.net, 2019. URL https://openreview.net/forum?id=Bkg6RiCqY7
2019
-
[18]
Ilya Loshchilov, Cheng-Ping Hsieh, Simeng Sun, and Boris Ginsburg. ngpt: Normalized transformer with representation learning on the hypersphere. ArXiv preprint, abs/2410.01131, 2024. URL https://arxiv.org/abs/2410.01131
-
[19]
Martin, Tian Peng, and Michael W
Charles H Martin, Tongsu Serena Peng, and Michael W Mahoney. Predicting trends in the quality of state-of-the-art neural networks without access to training or testing data. Nature Communications, 12: 0 4122, 2021. doi:10.1038/s41467-021-24025-8
-
[20]
Sharan Narang, Hyung Won Chung, Yi Tay, William Fedus, Thibault Fevry, Michael Matena, Karishma Malkan, Noah Fiedel, Noam Shazeer, Zhenzhong Lan, Yanqi Zhou, Wei Li, Nan Ding, Jake Marcus, Adam Roberts, and Colin Raffel. Do transformer modifications transfer across implementations and applications? ArXiv preprint, abs/2102.11972, 2021. URL https://arxiv.o...
-
[21]
The LAMBADA dataset: Word prediction requiring a broad discourse context
Denis Paperno, Germ \'a n Kruszewski, Angeliki Lazaridou, Ngoc Quan Pham, Raffaella Bernardi, Sandro Pezzelle, Marco Baroni, Gemma Boleda, and Raquel Fern \'a ndez. The LAMBADA dataset: Word prediction requiring a broad discourse context. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pa...
-
[22]
Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free
Zihan Qiu et al. Gated attention for large language models: Non-linearity, sparsity, and attention-sink-free. ArXiv preprint, abs/2505.06708, 2025. URL https://arxiv.org/abs/2505.06708
work page internal anchor Pith review arXiv 2025
-
[23]
GLU Variants Improve Transformer
Noam Shazeer. GLU variants improve transformer. ArXiv preprint, abs/2002.05202, 2020. URL https://arxiv.org/abs/2002.05202
work page internal anchor Pith review arXiv 2002
-
[24]
Impact of layer norm on memorization and generalization in transformers
Rishi Singhal and Jung-Eun Kim. Impact of layer norm on memorization and generalization in transformers. ArXiv preprint, abs/2511.10566, 2025. URL https://arxiv.org/abs/2511.10566
-
[25]
The implicit bias of gradient descent on separable data
Daniel Soudry, Elad Hoffer, Mor Shpigel Nacson, Suriya Gunasekar, and Nathan Srebro. The implicit bias of gradient descent on separable data. Journal of Machine Learning Research, 19 0 (70): 0 1--57, 2018. URL https://jmlr.org/papers/v19/18-188.html
2018
-
[26]
RoFormer: Enhanced Transformer with Rotary Position Embedding
Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. RoFormer : Enhanced transformer with rotary position embedding. ArXiv preprint, abs/2104.09864, 2021. URL https://arxiv.org/abs/2104.09864
work page internal anchor Pith review arXiv 2021
-
[27]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth \'e e Lacroix, Baptiste Rozi \`e re, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. LLaMA : Open and efficient foundation language models. ArXiv preprint, abs/2302.13971, 2023. URL https://arxiv.org/ab...
work page internal anchor Pith review arXiv 2023
-
[28]
Alex Warstadt, Alicia Parrish, Haokun Liu, Anhad Mohananey, Wei Peng, Sheng-Fu Wang, and Samuel R. Bowman. BL i MP : The benchmark of linguistic minimal pairs for E nglish. Transactions of the Association for Computational Linguistics, 8: 0 377--392, 2020. doi:10.1162/tacl_a_00321. URL https://aclanthology.org/2020.tacl-1.25
- [29]
-
[30]
Differential transformer, 2025
Tianzhu Ye, Li Dong, Yuqing Xia, Yutao Sun, Yi Zhu, Gao Huang, and Furu Wei. Differential transformer. ArXiv preprint, abs/2410.05258, 2024. URL https://arxiv.org/abs/2410.05258
-
[31]
Differential transformer v2
Tianzhu Ye, Li Dong, Yutao Sun, and Furu Wei. Differential transformer v2. Microsoft Research Hugging Face blog, 2026. URL https://huggingface.co/blog/microsoft/diff-attn-v2
2026
-
[32]
Root mean square layer normalization
Biao Zhang and Rico Sennrich. Root mean square layer normalization. In Advances in Neural Information Processing Systems 32, pages 12360--12371, 2019. URL https://proceedings.neurips.cc/paper/2019/hash/1e8a19426224ca89e83cef47f1e7f53b-Abstract.html
2019
-
[33]
Transformers without normalization
Jiachen Zhu, Xinlei Chen, Kaiming He, Yann LeCun, and Zhuang Liu. Transformers without normalization. ArXiv preprint, abs/2503.10622, 2025. URL https://arxiv.org/abs/2503.10622
- [34]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.