Recognition: unknown
CUJBench: Benchmarking LLM-Agent on Cross-Modal Failure Diagnosis from Browser to Backend
Pith reviewed 2026-05-08 07:43 UTC · model grok-4.3
The pith
A new benchmark shows LLM agents diagnose cross-modal failures at 19.7 percent accuracy because they cannot correctly attribute evidence across browser and backend signals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CUJBench demonstrates that current LLM agents retrieve decisive browser and backend evidence but consistently fail to attribute it to the correct failure, producing 19.7 percent overall accuracy and a 52 percent ceiling across six models. Browser-only agents outperform full-toolset agents because additional observability induces unfocused exploration instead of better cross-modal reasoning. The limitation appears uniform regardless of model scale or tool richness.
What carries the argument
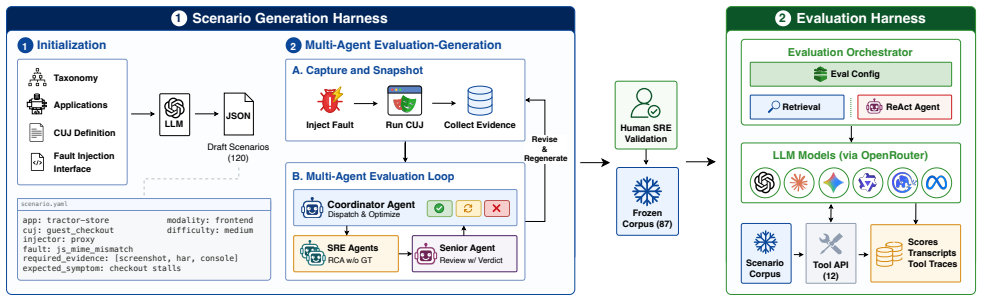
CUJBench, a collection of 87 deterministic multi-modal failure snapshots each paired with a fixed tool interface and three-layer labels, used to score agents on retrieval, browser-only, and full-toolset diagnosis tasks.
If this is right
- Expanded tool access can lower performance by encouraging unfocused exploration rather than focused synthesis.
- Cross-modal attribution remains the dominant error type even when agents locate the right evidence.
- The performance gap between browser-only and full-tool agents indicates that simply adding more signals does not improve diagnosis.
- No model scale tested overcomes the attribution bottleneck in these scenarios.
Where Pith is reading between the lines
- Future agent designs may need explicit mechanisms to track and match evidence across separate observation streams.
- The benchmark could serve as a testbed for training methods that reward correct evidence-to-cause mapping.
- Similar cross-modal gaps may appear in other domains that require linking user-visible symptoms to internal logs.
Load-bearing premise
The automated generation pipeline with multi-agent review produces failure scenarios that are realistic and free of artifacts that would change how agents perform.
What would settle it
Run the same six agents on a fresh set of 20 scenarios whose labels were created entirely by human experts instead of the pipeline and check whether accuracy rises above 30 percent.
Figures
read the original abstract
Automated failure diagnosis requires correlating browser-visible symptoms with backend observability signals, yet existing benchmarks do not evaluate this cross-modal reasoning task. Constructing one is non-trivial: multi-modal failure scenarios are costly to annotate, and live-environment capture introduces stochasticity that makes cross-run agent comparison unreliable. We present CUJBench, to our knowledge, the first benchmark to combine browser-visible failure evidence with backend observability in a diagnostic framing. CUJBench addresses annotation cost through an LLM-assisted generation pipeline with a multi-agent review loop and a three-layer annotation scheme, producing 87 labeled scenarios across five fault families, and ensures reproducibility by packaging each failure as a deterministic multi-modal snapshot with a fixed tool interface. Evaluating six frontier models under retrieval, browser-only, and full-toolset baselines, the benchmark yields an overall accuracy of 19.7% with a ceiling of 52%, well below saturation. Contrary to expectation, browser-only agents outperform full-toolset agents in aggregate, with expanded evidence access inducing unfocused exploration rather than improved synthesis. Trajectory analysis identifies cross-modal synthesis as the primary bottleneck: agents retrieve the decisive evidence but fail to attribute it correctly - a structural limitation uniform across all six models that model scale and richer tool access alone cannot resolve.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents CUJBench, the first benchmark for LLM-agent cross-modal failure diagnosis that correlates browser-visible symptoms with backend observability. It uses an LLM-assisted generation pipeline with multi-agent review and a three-layer annotation scheme to create 87 deterministic, reproducible scenarios across five fault families. Evaluation of six frontier models under retrieval, browser-only, and full-toolset settings reports 19.7% overall accuracy (ceiling 52%), finds browser-only agents outperform full-toolset agents, and concludes via trajectory analysis that cross-modal synthesis is the primary bottleneck uniform across models.
Significance. If the generated scenarios prove representative of real failures, this benchmark fills a gap in evaluating agentic systems for practical software diagnosis tasks. The reproducible packaging of failures as fixed multi-modal snapshots is a clear strength that enables reliable cross-run comparisons. The counterintuitive result that expanded tool access can degrade performance, together with the uniform attribution failure finding, would usefully inform agent design if the benchmark construction is validated.
major comments (3)
- [§3] Scenario generation section (described in abstract and §3): The LLM-assisted pipeline with multi-agent review loop and three-layer annotation scheme operates entirely within the same model family. This raises the possibility that the scenarios systematically embed attribution artifacts, making the observed cross-modal synthesis bottleneck (agents retrieve evidence but fail to attribute) an artifact of the benchmark rather than a structural property of the agents. The manuscript should add an external validation step, such as comparison against a held-out set of human-annotated real-world failures or inter-rater agreement metrics with domain experts, to confirm the scenarios are free of such circularity.
- [§4] Evaluation section (§4): The headline claims of 19.7% accuracy, 52% ceiling, and browser-only outperforming full-toolset are load-bearing for the argument that richer tools do not resolve the bottleneck. However, the manuscript provides no definitions of the accuracy metric (e.g., exact criteria for correct diagnosis or partial credit), no statistical tests for the performance difference, and no per-model or per-scenario variance. These omissions prevent assessment of whether the results are robust or sensitive to implementation choices in the tool interfaces.
- [§5] Trajectory analysis (§5): The identification of cross-modal synthesis as the primary bottleneck rests on qualitative trajectory inspection showing retrieval without correct attribution. The paper should supply quantitative metrics for attribution failure (e.g., a defined attribution score or count of misattribution instances per scenario) and concrete examples to make this claim falsifiable and proportionate to the central conclusion.
minor comments (3)
- The abstract's claim of being 'to our knowledge, the first benchmark' should be supported by explicit comparisons in the related work section to prior failure diagnosis benchmarks in software engineering.
- Ensure all figures depicting agent trajectories or the benchmark architecture include clear legends and axis labels for readability.
- Expand the acronym CUJBench on first use in the main text.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback, which identifies key areas where the manuscript can be strengthened. We address each major comment point by point below, with clear indications of the revisions we will make.
read point-by-point responses
-
Referee: [§3] Scenario generation section (described in abstract and §3): The LLM-assisted pipeline with multi-agent review loop and three-layer annotation scheme operates entirely within the same model family. This raises the possibility that the scenarios systematically embed attribution artifacts, making the observed cross-modal synthesis bottleneck (agents retrieve evidence but fail to attribute) an artifact of the benchmark rather than a structural property of the agents. The manuscript should add an external validation step, such as comparison against a held-out set of human-annotated real-world failures or inter-rater agreement metrics with domain experts, to confirm the scenarios are free of such circularity.
Authors: We acknowledge the referee's concern regarding potential circularity in the LLM-assisted generation pipeline. While the multi-agent review loop and three-layer annotation scheme were intended to promote scenario quality and diversity, the use of models from the same family could introduce subtle biases. The observed bottleneck concerns attribution of already-retrieved evidence rather than retrieval itself, which we argue is less likely to be an artifact. To address this, we will add a limitations subsection to §3 discussing the generation process and its possible biases. We will also report a comparison of a random subset of 20 scenarios against real-world failure reports drawn from public GitHub repositories of web applications to assess representativeness. Full human re-annotation of the entire set is not feasible within this revision cycle. revision: partial
-
Referee: [§4] Evaluation section (§4): The headline claims of 19.7% accuracy, 52% ceiling, and browser-only outperforming full-toolset are load-bearing for the argument that richer tools do not resolve the bottleneck. However, the manuscript provides no definitions of the accuracy metric (e.g., exact criteria for correct diagnosis or partial credit), no statistical tests for the performance difference, and no per-model or per-scenario variance. These omissions prevent assessment of whether the results are robust or sensitive to implementation choices in the tool interfaces.
Authors: We agree that the evaluation section requires more precise definitions and statistical support to substantiate the headline results. In the revised manuscript we will explicitly define the accuracy metric in §4, stating that a diagnosis is scored correct only when both the fault family and the specific root cause match the ground-truth annotation (no partial credit is awarded). We will add tables reporting per-model and per-scenario accuracies together with standard deviations, and we will include statistical tests (McNemar's test for paired binary outcomes) to evaluate the significance of the browser-only versus full-toolset performance difference. These additions will allow readers to assess robustness directly. revision: yes
-
Referee: [§5] Trajectory analysis (§5): The identification of cross-modal synthesis as the primary bottleneck rests on qualitative trajectory inspection showing retrieval without correct attribution. The paper should supply quantitative metrics for attribution failure (e.g., a defined attribution score or count of misattribution instances per scenario) and concrete examples to make this claim falsifiable and proportionate to the central conclusion.
Authors: We concur that the trajectory analysis would be strengthened by quantitative metrics and concrete examples. We will introduce an 'attribution failure rate' metric in §5, defined as the percentage of scenarios in which the agent retrieves the decisive evidence (confirmed via tool-call logs) yet fails to correctly attribute it in the final diagnosis. This rate will be reported for each model and experimental setting. In addition, we will include an appendix containing three detailed trajectory examples that illustrate the retrieval-without-attribution pattern, making the central claim more falsifiable and proportionate to the evidence. revision: yes
Circularity Check
No significant circularity: purely empirical benchmark with direct measurements
full rationale
The paper constructs CUJBench via an LLM-assisted pipeline and evaluates six models on 87 scenarios, reporting accuracy, trajectory patterns, and comparative baselines. No equations, fitted parameters, predictions derived from subsets, or self-citation chains appear in the provided text. All reported results (19.7% accuracy, browser-only outperforming full-toolset, cross-modal attribution failures) are direct empirical observations on the generated test set rather than quantities forced by construction or renamed inputs. The generation process is presented as a practical solution to annotation cost, not as a derivation that loops back to validate itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM-assisted generation plus multi-agent review produces high-quality, unbiased failure scenarios that reflect genuine cross-modal diagnostic challenges
Reference graph
Works this paper leans on
-
[1]
AIOpsLab: A Holistic Framework to Evaluate AI Agents for Enabling Autonomous Clouds,
Y . Chen et al., “AIOpsLab: A Holistic Framework to Evaluate AI Agents for Enabling Autonomous Clouds,” inProc. MLSys, 2025
2025
-
[2]
ITBench: Evaluating AI Agents across Diverse Real-World IT Automation Tasks,
S. Jha et al., “ITBench: Evaluating AI Agents across Diverse Real-World IT Automation Tasks,” inProc. ICML, 2025
2025
-
[3]
Cloud-OpsBench: A Reproducible Benchmark for Agentic Root Cause Analysis in Cloud Systems,
Y . Wang et al., “Cloud-OpsBench: A Reproducible Benchmark for Agentic Root Cause Analysis in Cloud Systems,” arXiv:2603.00468, 2026
-
[4]
Why Do AI Agents Systematically Fail at Cloud Root Cause Analysis?,
T. Kim et al., “Why Do AI Agents Systematically Fail at Cloud Root Cause Analysis?,” arXiv:2602.09937, 2026
-
[5]
Stalled, Biased, and Confused: Uncovering Reasoning Failures in LLMs for Cloud-Based Root Cause Analysis,
E. Riddell et al., “Stalled, Biased, and Confused: Uncovering Reasoning Failures in LLMs for Cloud-Based Root Cause Analysis,” inProc. FORGE, 2026
2026
-
[6]
Survey on Evaluation of LLM-based Agents
A. Yehudai et al., “Survey on Evaluation of LLM-based Agents,” arXiv:2503.16416, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Evaluation and Benchmarking of LLM Agents: A Survey,
M. Mohammadi et al., “Evaluation and Benchmarking of LLM Agents: A Survey,” inProc. KDD, 2025, pp. 6129–6139
2025
-
[8]
How to Fight Production Incidents? An Empirical Study on a Large-Scale Cloud Service,
S. Ghosh et al., “How to Fight Production Incidents? An Empirical Study on a Large-Scale Cloud Service,” inProc. SoCC, 2022, pp. 126–141
2022
-
[9]
Beyer, N
B. Beyer, N. R. Murphy, D. K. Rensin, K. Kawahara, and S. Thorne,The Site Reliability Workbook: Practical Ways to Implement SRE. O’Reilly Media, 2018, ISBN 978-1-492-02950-2
2018
-
[10]
Critical User Journey Test Cov- erage,
C. Arguelles and T. Sampson, “Critical User Journey Test Cov- erage,”Technical Disclosure Commons, 2020. [Online]. Available: https://www.tdcommons.org/dpubs series/3744/
2020
-
[11]
OpenRCA: Can Large Language Models Locate the Root Cause of Software Failures?,
J. Xu et al., “OpenRCA: Can Large Language Models Locate the Root Cause of Software Failures?,” inProc. ICLR, 2025
2025
-
[12]
RCAEval: A Benchmark for Root Cause Analysis of Microservice Systems with Telemetry Data,
L. Pham et al., “RCAEval: A Benchmark for Root Cause Analysis of Microservice Systems with Telemetry Data,” inProc. WWW, 2025
2025
-
[13]
arXiv:2601.22881 [cs.SE] https://arxiv.org/abs/2601.22881
K. Ping et al., “AnoMod: A Dataset for Anomaly Detection and Root Cause Analysis in Microservice Systems,” inProc. MSR, 2026. arXiv:2601.22881
-
[14]
WebArena: A Realistic Web Environment for Building Autonomous Agents,
S. Zhou et al., “WebArena: A Realistic Web Environment for Building Autonomous Agents,” inProc. ICLR, 2024
2024
-
[15]
VisualWebArena: Evaluating Multimodal Agents on Realistic Visual Web Tasks,
J. Y . Koh et al., “VisualWebArena: Evaluating Multimodal Agents on Realistic Visual Web Tasks,” inProc. ACL, 2024
2024
-
[16]
OSWorld: Benchmarking Multimodal Agents for Open- Ended Tasks in Real Computer Environments,
T. Xie et al., “OSWorld: Benchmarking Multimodal Agents for Open- Ended Tasks in Real Computer Environments,” inProc. NeurIPS, 2024
2024
-
[17]
TheAgentCompany: Benchmarking LLM Agents on Consequential Real World Tasks
F. Xu et al., “TheAgentCompany: Benchmarking LLM Agents on Consequential Real World Tasks,” arXiv:2412.14161, 2024
work page internal anchor Pith review arXiv 2024
-
[18]
Odysseybench: Evaluating llm agents on long-horizon complex office application workflows
W. Wang et al., “OdysseyBench: Evaluating LLM Agents on Long- Horizon Complex Office Application Workflows,” arXiv:2508.09124, 2025
-
[19]
The Tool Decathlon: Benchmarking Language Agents for Diverse, Realistic, and Long-Horizon Task Execution,
J. Li et al., “The Tool Decathlon: Benchmarking Language Agents for Diverse, Realistic, and Long-Horizon Task Execution,” inProc. ICLR, 2026
2026
-
[20]
Claude Sonnet 4.6,
Anthropic, “Claude Sonnet 4.6,” 2026. [Online]. Available: https://www.anthropic.com/claude/sonnet
2026
-
[21]
Gemini 3.1 Pro Model Card,
Google DeepMind, “Gemini 3.1 Pro Model Card,” 2026. [Online]. Available: https://deepmind.google/models/model-cards/gemini-3-1-pro/
2026
-
[22]
LabelEase: A Semi-Automatic Tool for Efficient and Accurate Trace Labeling in Microservices,
S. Zhang et al., “LabelEase: A Semi-Automatic Tool for Efficient and Accurate Trace Labeling in Microservices,” inProc. ISSRE, 2024
2024
-
[23]
AIOpsArena: Scenario-Oriented Evaluation and Leader- board for AIOps Algorithms in Microservices,
Y . Sun et al., “AIOpsArena: Scenario-Oriented Evaluation and Leader- board for AIOps Algorithms in Microservices,” inProc. SANER, 2025
2025
-
[24]
OpenTelemetry Demo: Astronomy Shop,
OpenTelemetry Authors, “OpenTelemetry Demo: Astronomy Shop,” GitHub repository, 2024. [Online]. Available: https://github.com/open- telemetry/opentelemetry-demo
2024
-
[25]
The Tractor Store - Preact,
neuland, “The Tractor Store - Preact,” GitHub repository, ver. 1.0.0, commit 187de47, 2025. [Online]. Available: https://github.com/neuland/tractor-store-preact
2025
-
[26]
Eadro: An End-to-End Troubleshooting Framework for Microservices on Multi-Source Data,
C. Lee et al., “Eadro: An End-to-End Troubleshooting Framework for Microservices on Multi-Source Data,” inProc. ICSE, 2023
2023
-
[27]
Nezha: Interpretable Fine-Grained Root Causes Anal- ysis for Microservices on Multi-modal Observability Data,
G. Yu et al., “Nezha: Interpretable Fine-Grained Root Causes Anal- ysis for Microservices on Multi-modal Observability Data,” inProc. ESEC/FSE, 2023
2023
-
[28]
Exploring LLM-Based Agents for Root Cause Analysis,
D. Roy et al., “Exploring LLM-Based Agents for Root Cause Analysis,” inProc. FSE Companion, 2024
2024
-
[29]
Introducing GPT-5.4,
OpenAI, “Introducing GPT-5.4,” 2026. [Online]. Available: https://openai.com/index/introducing-gpt-5-4/
2026
-
[30]
ReAct: Synergizing Reasoning and Acting in Language Models,
S. Yao et al., “ReAct: Synergizing Reasoning and Acting in Language Models,” inProc. ICLR, 2023
2023
-
[31]
TAMO: Fine-Grained Root Cause Analysis via Tool-Assisted LLM Agent With Multi-Modality Observation Data in Cloud-Native Systems,
X. Zhang et al., “TAMO: Fine-Grained Root Cause Analysis via Tool-Assisted LLM Agent With Multi-Modality Observation Data in Cloud-Native Systems,”IEEE Trans. Services Comput., vol. 18, no. 6, pp. 4221–4233, 2025
2025
-
[32]
G. Park, “Bridging Temporal and Textual Modalities: A Multimodal Framework for Automated Cloud Failure Root Cause Analysis,” arXiv:2601.04709, 2026
-
[33]
Too Many Cooks: Assessing the Need for Multi-Source Data in Microservice Failure Diagnosis,
S. Zhang et al., “Too Many Cooks: Assessing the Need for Multi-Source Data in Microservice Failure Diagnosis,” inProc. ISSRE, 2025
2025
-
[34]
Recommending Root-Cause and Mitigation Steps for Cloud Incidents using Large Language Models,
T. Ahmed et al., “Recommending Root-Cause and Mitigation Steps for Cloud Incidents using Large Language Models,” inProc. ICSE, 2023, pp. 1737–1749
2023
-
[35]
Automatic Root Cause Analysis via Large Language Models for Cloud Incidents,
Y . Chen et al., “Automatic Root Cause Analysis via Large Language Models for Cloud Incidents,” inProc. EuroSys, 2024, pp. 674–688
2024
-
[36]
Gui-robust: A comprehensive dataset for test- ing gui agent robustness in real-world anomalies,
J. Yang et al., “GUI-Robust: A Comprehensive Dataset for Testing GUI Agent Robustness in Real-World Anomalies,” arXiv:2506.14477, 2025
-
[37]
VideoWebArena: Evaluating Long Context Multimodal Agents with Video Understanding Web Tasks,
L. Jang et al., “VideoWebArena: Evaluating Long Context Multimodal Agents with Video Understanding Web Tasks,” inProc. ICLR, 2025
2025
-
[38]
TRAIL: Trace reasoning and agentic issue localization.arXiv preprint arXiv:2505.08638, 2025
D. Deshpande et al., “TRAIL: Trace Reasoning and Agentic Issue Localization,” arXiv:2505.08638, 2025
-
[39]
RCAgent: Cloud Root Cause Analysis by Autonomous Agents with Tool-Augmented Large Language Models,
Z. Wang et al., “RCAgent: Cloud Root Cause Analysis by Autonomous Agents with Tool-Augmented Large Language Models,” inProc. CIKM, 2024, pp. 4966–4974
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.