Recognition: unknown
Symmetric Equilibrium Propagation for Thermodynamic Diffusion Training
Pith reviewed 2026-05-08 06:16 UTC · model grok-4.3
The pith
Symmetric Equilibrium Propagation on bilinear analog substrates yields an unbiased estimator of the denoising score-matching gradient for diffusion training in the zero-nudge limit.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
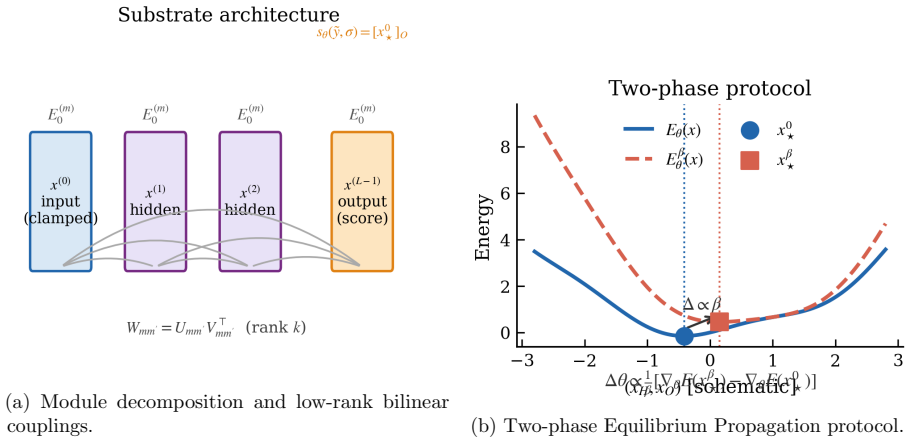
Equilibrium Propagation applied directly to the bilinear energy yields an unbiased estimator of the denoising score-matching gradient in the zero-nudge limit. For finite nudging a sharp bias bound is derived that depends only on substrate stiffness, local curvature, and the norm of the loss-gradient signal, with the bilinear structure causing one dominant bias term to vanish identically for coupling-parameter updates. Symmetric nudging upgrades the leading bias scaling from O(β) to O(β²) at negligible extra cost, which is essential under realistic finite-relaxation budgets because one-sided nudging produces anti-correlated gradients while symmetric nudging yields well-aligned updates.
What carries the argument
Symmetric Equilibrium Propagation applied to the bilinearly-coupled energy function that realizes overdamped Langevin dynamics via low-rank inter-module couplings instead of dense skip connections.
If this is right
- The zero-nudge limit supplies an unbiased estimator of the denoising score-matching gradient.
- Bias for finite nudges is bounded solely by substrate stiffness, local curvature, and loss-gradient norm.
- Bilinear structure makes one dominant bias term vanish identically for coupling-parameter updates.
- Symmetric nudging reduces leading bias order from O(β) to O(β²) while preserving alignment under finite relaxation.
- End-to-end physical-unit accounting projects a 10^3 to 10^4 times energy advantage per training step over a matched GPU baseline.
Where Pith is reading between the lines
- The local, readout-only nature of the updates could allow fully decentralized training across distributed analog arrays without requiring global synchronization or back-propagation wiring.
- The same bilinear substrate and symmetric EqProp rule might extend to other score-based generative tasks if their dynamics can be cast into comparable time-dependent energy landscapes.
- Hardware verification would need to test whether the projected energy savings survive realistic noise, mismatch, and finite-precision effects in physical substrates.
- Connections to existing analog or neuromorphic platforms that already support low-rank couplings could be tested by mapping the bilinear energy directly onto their native dynamics.
Load-bearing premise
The bilinearly-coupled analog substrate can physically realize the required time-dependent Langevin dynamics with sufficient fidelity under finite relaxation budgets, keeping stiffness and curvature parameters controllable independently of the training updates.
What would settle it
A measurement on a physical or simulated bilinear substrate that directly compares the gradient estimates produced by symmetric EqProp against digital score-matching gradients and confirms the derived bias bounds hold for finite nudge values and relaxation times.
Figures





read the original abstract
The reverse process in score-based diffusion models is formally equivalent to overdamped Langevin dynamics in a time-dependent energy landscape. In our prior work we showed that a bilinearly-coupled analog substrate can physically realize this dynamics at a projected three-to-four orders of magnitude energy advantage over digital inference by replacing dense skip connections with low-rank inter-module couplings. Whether the \emph{training} loop can be closed on the same substrate -- without routing gradients through an external digital accelerator -- has remained open. We resolve this affirmatively: Equilibrium Propagation applied directly to the bilinear energy yields an unbiased estimator of the denoising score-matching gradient in the zero-nudge limit. For finite nudging we derive a sharp bias bound controlled solely by substrate stiffness, local curvature, and the norm of the loss-gradient signal, with a bilinear-specific corollary showing that one dominant bias term vanishes identically for coupling-parameter updates. Symmetric nudging further upgrades the leading bias from $ \mathcal{O}(\beta) $ to $ \mathcal{O}(\beta^2) $ at negligible extra cost. Under realistic finite-relaxation budgets this upgrade is essential, as one-sided EqProp produces anti-correlated gradients while symmetric EqProp yields well-aligned updates. Bias-variance analysis determines the optimal operating point, and end-to-end physical-unit accounting projects a $ 10^3$-$10^4\times $ energy advantage per training step over a matched GPU baseline. Symmetric bilinear EqProp is the first local, readout-only training rule that preserves the low-rank coupling enabling scalable thermodynamic diffusion models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that Equilibrium Propagation applied directly to the bilinear energy of a thermodynamic diffusion model produces an unbiased estimator of the denoising score-matching gradient in the zero-nudge limit. For finite nudging it derives an explicit bias bound controlled solely by substrate stiffness, local curvature, and loss-gradient norm, with a bilinear corollary that one dominant bias term vanishes for coupling-parameter updates. Symmetric nudging is shown to upgrade the leading bias from O(β) to O(β²), and the work includes bias-variance analysis plus end-to-end energy accounting projecting 10³–10⁴× advantage over GPU baselines.
Significance. If the derivations hold, the result enables the first local, readout-only training rule that preserves the low-rank inter-module couplings of the analog substrate, thereby closing the training loop for thermodynamic diffusion models without routing gradients through an external digital accelerator. The explicit bias bounds, the bilinear vanishing-term corollary, and the symmetric-nudging O(β²) improvement are technically substantive contributions that directly address the open question left by the authors’ prior substrate work.
major comments (1)
- [Bias derivation and symmetric-nudging corollary (abstract and § on finite-nudge analysis)] The central bias expansion and the O(β²) upgrade under symmetric nudging rest on the equilibrium free-energy derivatives and the time-dependent Langevin equivalence stated in the manuscript. These steps should be cross-referenced explicitly to the relevant equations in the prior substrate paper so that the bias bound’s dependence on stiffness and curvature can be verified independently without circular appeal to the substrate construction.
minor comments (2)
- The abstract and energy-accounting section refer to “end-to-end physical-unit accounting” yielding 10³–10⁴× savings; a compact table listing the concrete assumptions (relaxation time, coupling rank, per-step energy per module, etc.) would make the projection reproducible and allow readers to assess sensitivity to those parameters.
- Notation for the nudge parameter β, substrate stiffness, and local curvature should be introduced with a single consolidated table or paragraph early in the manuscript, as these quantities appear in both the bias bound and the physical-fidelity discussion.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of our manuscript and the recommendation for minor revision. We address the single major comment below.
read point-by-point responses
-
Referee: [Bias derivation and symmetric-nudging corollary (abstract and § on finite-nudge analysis)] The central bias expansion and the O(β²) upgrade under symmetric nudging rest on the equilibrium free-energy derivatives and the time-dependent Langevin equivalence stated in the manuscript. These steps should be cross-referenced explicitly to the relevant equations in the prior substrate paper so that the bias bound’s dependence on stiffness and curvature can be verified independently without circular appeal to the substrate construction.
Authors: We agree that explicit cross-references will strengthen the presentation and enable independent verification. In the revised manuscript we will add direct citations to the specific equations in our prior substrate paper that establish the equilibrium free-energy derivatives (with respect to the bilinear couplings) and the equivalence between the time-dependent Langevin dynamics and the reverse diffusion process. These references will make the dependence of the bias bound on substrate stiffness, local curvature, and loss-gradient norm fully traceable without requiring the reader to reconstruct the substrate construction from the current text. revision: yes
Circularity Check
Minor self-citation to prior substrate realization; central derivation of unbiased EqProp estimator and bias bounds remains independent
full rationale
The paper's core mathematical claim—that Equilibrium Propagation on the bilinear energy produces an unbiased estimator of the denoising score-matching gradient at zero nudge, with an explicit bias bound controlled by stiffness, curvature, and loss-gradient norm—is presented as a fresh derivation supported by equilibrium free-energy derivatives and bias expansion. The only self-citation is to prior work establishing that the bilinear substrate can realize the time-dependent Langevin dynamics; this is used as a physical precondition rather than as a load-bearing step that defines or forces the training-rule result itself. No equations reduce by construction to fitted inputs, no ansatz is smuggled via self-citation, and no uniqueness theorem from the same authors is invoked to forbid alternatives. The derivation is therefore self-contained against external benchmarks once the substrate equivalence is granted, warranting only a minor self-citation flag.
Axiom & Free-Parameter Ledger
free parameters (1)
- nudge parameter β
axioms (1)
- domain assumption The reverse process in score-based diffusion models is formally equivalent to overdamped Langevin dynamics in a time-dependent energy landscape.
invented entities (1)
-
bilinearly-coupled analog substrate
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A connection between score matching and denoising autoencoders.Neural Computation, 23(7):1661–1674, 2011
Vincent, P. A connection between score matching and denoising autoencoders.Neural Computation, 23(7):1661–1674, 2011
2011
-
[2]
Thermodynamic linear algebra.npj Unconventional Computing, 1:13, 2024
Aifer, M., Donatella, K., Gordon, M., Duffield, S., Ahle, T., Simpson, D., Crooks, G., and Coles, P. Thermodynamic linear algebra.npj Unconventional Computing, 1:13, 2024
2024
-
[3]
Bennett, C. H. Logical reversibility of computation.IBM Journal of Research and Develop- ment, 17(6):525–532, 1973
1973
-
[4]
Y., Sutton, B
Camsari, K. Y., Sutton, B. M., and Datta, S. p-bits for probabilistic spin logic.Applied Physics Reviews, 6(1):011305, 2019
2019
-
[5]
and Guillin, A
Cattiaux, P. and Guillin, A. Trend to equilibrium for diffusions: a Poincar´ e-type inequality and a Lyapunov functional.Journal of Functional Analysis, 256(9):2815–2845, 2009
2009
-
[6]
arXiv preprint arXiv:2305.13542 , year=
Coles, P., Aifer, M., Donatella, K., Gordon, M., Duffield, S., Ahle, T., Simpson, D., and Crooks, G. Thermodynamic computing. Preprint, arXiv:2305.13542, 2023
-
[7]
Thermodynamic Diffusion Inference with Minimal Digital Conditioning
De, A. Thermodynamic Diffusion Inference with Minimal Digital Conditioning. arXiv:2604.14332 [cs.LG], 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
Denoising diffusion probabilistic models
Ho, J., Jain, A., and Abbeel, P. Denoising diffusion probabilistic models. InAdvances in Neural Information Processing Systems (NeurIPS), volume 33, pp. 6840–6851, 2020
2020
-
[9]
Elucidating the design space of diffusion- based generative models
Karras, T., Aittala, M., Aila, T., and Laine, S. Elucidating the design space of diffusion- based generative models. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[10]
An efficient probabilistic hardware architecture for diffusion-like models
Jelinˇ ciˇ c, A., Lockwood, O., Garlapati, A., Schillinger, P., Chuang, I., Verdon, G., and McCourt, T. An efficient probabilistic hardware architecture for diffusion-like models. arXiv:2510.23972v2, 2025
-
[11]
and Scellier, B
Laborieux, A. and Scellier, B. Convergence of equilibrium propagation with constant learning rates.Journal of Machine Learning Research, 23:1–38, 2022
2022
-
[12]
Irreversibility and heat generation in the computing process.IBM Journal of Research and Development, 5(3):183–191, 1961
Landauer, R. Irreversibility and heat generation in the computing process.IBM Journal of Research and Development, 5(3):183–191, 1961
1961
-
[13]
Normal computing: thermodynamic architectures for generative modeling
Melanson, et al. Normal computing: thermodynamic architectures for generative modeling. Preprint, 2025
2025
-
[14]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., M¨ uller, J., Rombach, R., and Ommer, B. SDXL: Improving latent diffusion models for high-resolution image synthesis. arXiv:2307.01952, 2023. 8
work page internal anchor Pith review arXiv 2023
-
[15]
High-resolution image synthesis with latent diffusion models
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., and Ommer, B. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 10684–10695, 2022
2022
-
[16]
U-Net: Convolutional networks for biomedical image segmentation
Ronneberger, O., Fischer, P., and Brox, T. U-Net: Convolutional networks for biomedical image segmentation. InMedical Image Computing and Computer-Assisted Intervention (MICCAI), volume 9351, pp. 234–241. Springer, 2015
2015
-
[17]
and Bengio, Y
Scellier, B. and Bengio, Y. Equilibrium propagation: Bridging the gap between energy-based models and backpropagation.Frontiers in Computational Neuroscience, 11:24, 2017
2017
-
[18]
arXiv preprint arXiv:1805.04623 , year=
Scellier, B. A deep learning theory for the equilibrium propagation algorithm. arXiv:1805.04623, 2018
-
[19]
Deep unsupervised learning using nonequilibrium thermodynamics
Sohl-Dickstein, J., Weiss, E., Maheswaranathan, N., and Ganguli, S. Deep unsupervised learning using nonequilibrium thermodynamics. InInternational Conference on Machine Learning (ICML), pp. 2256–2265, 2015
2015
-
[20]
and Ermon, S
Song, Y. and Ermon, S. Generative modeling by estimating gradients of the data distribution. InAdvances in Neural Information Processing Systems (NeurIPS), 2019
2019
-
[21]
P., Kumar, A., Ermon, S., and Poole, B
Song, Y., Sohl-Dickstein, J., Kingma, D. P., Kumar, A., Ermon, S., and Poole, B. Score-based generative modeling through stochastic differential equations. InInternational Conference on Learning Representations (ICLR), 2021
2021
-
[22]
and Du, S
Wang, Y. and Du, S. S. Equilibrium matching: A unified framework for energy-based models. Preprint, 2025
2025
-
[23]
Generative thermodynamic computing
Whitelam, S. Generative thermodynamic computing. arXiv:2506.15121, 2025
-
[24]
and Casert, C
Whitelam, S. and Casert, C. Equilibrium-based generative models on physical substrates. Preprint, 2026. 9
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.