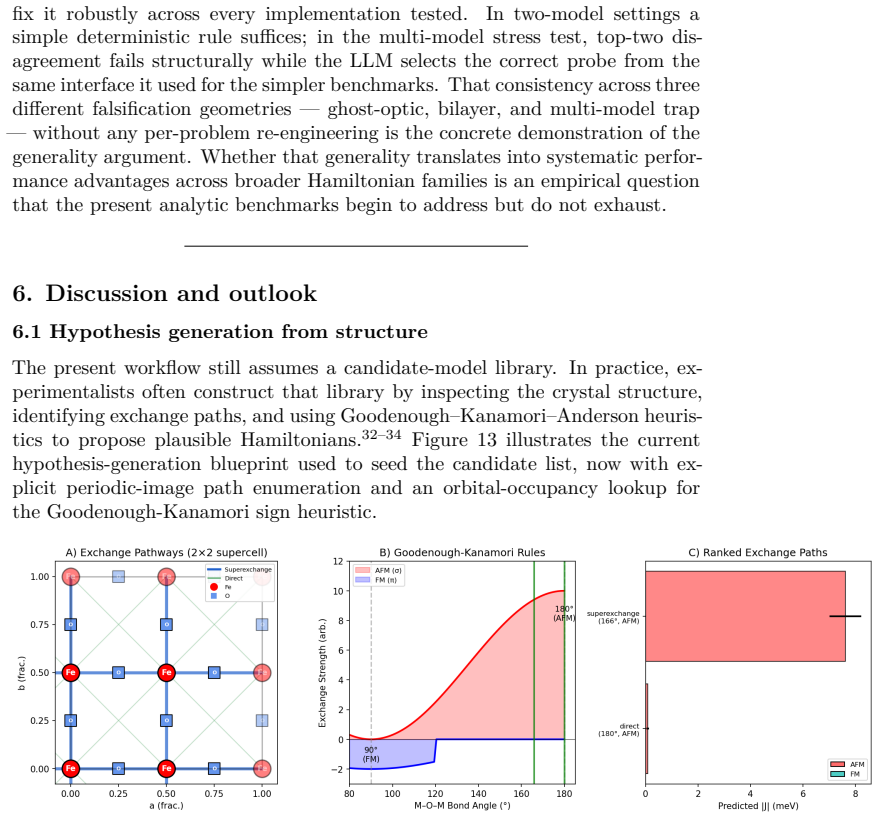
Accelerating Quantum Materials Characterization: Hybrid Active Learning for Autonomous Spin Wave Spectroscopy
Pith reviewed 2026-05-08 05:49 UTC · model grok-4.3
The pith
A hybrid framework that starts with model-agnostic sampling before physics-informed planning separates signal detection from Hamiltonian inference in autonomous neutron spectroscopy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
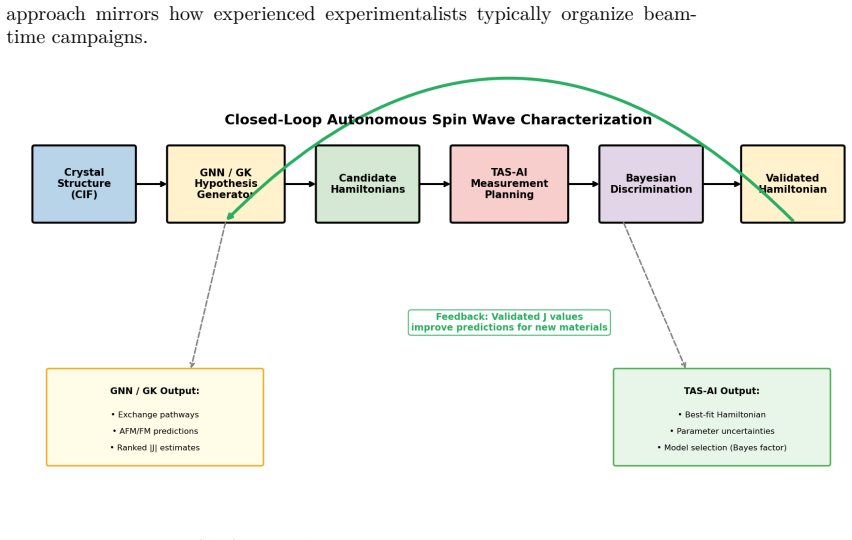
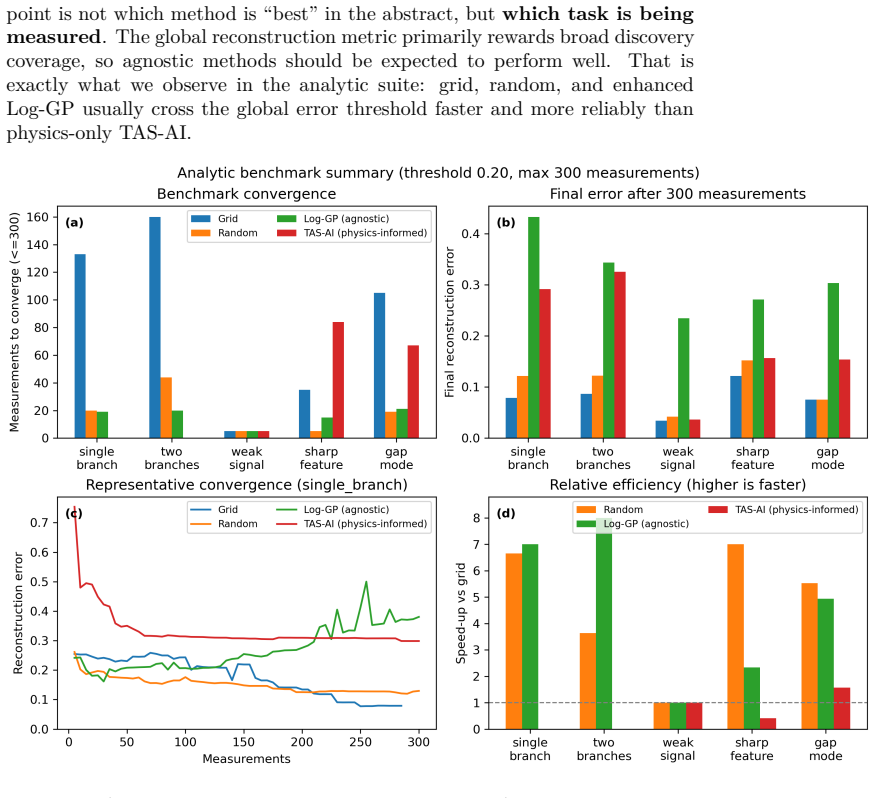
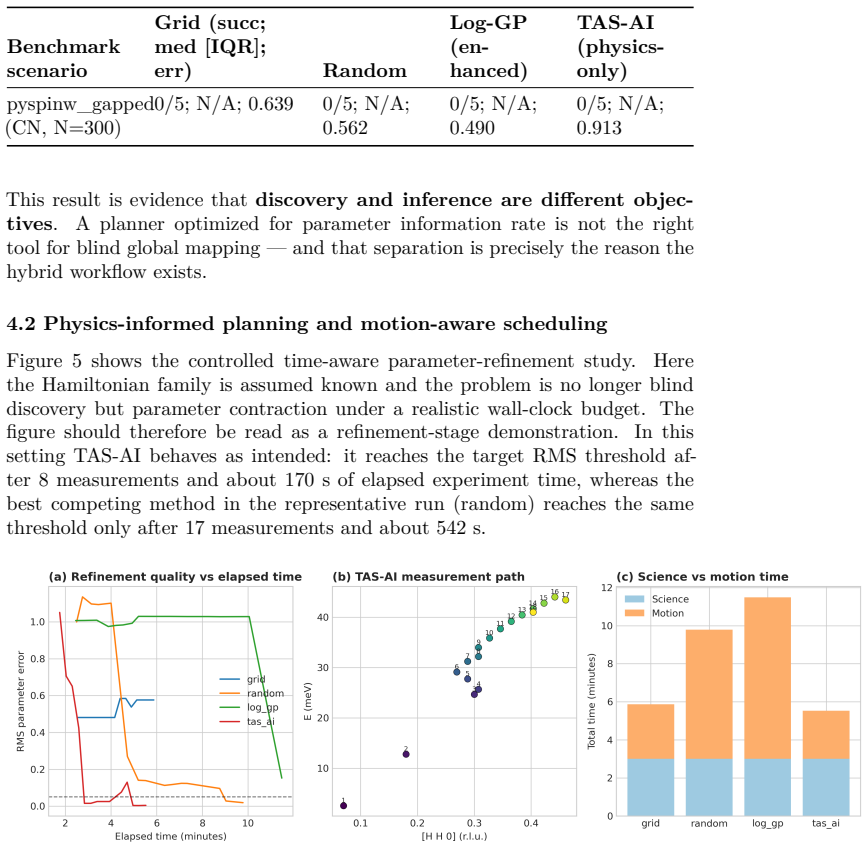
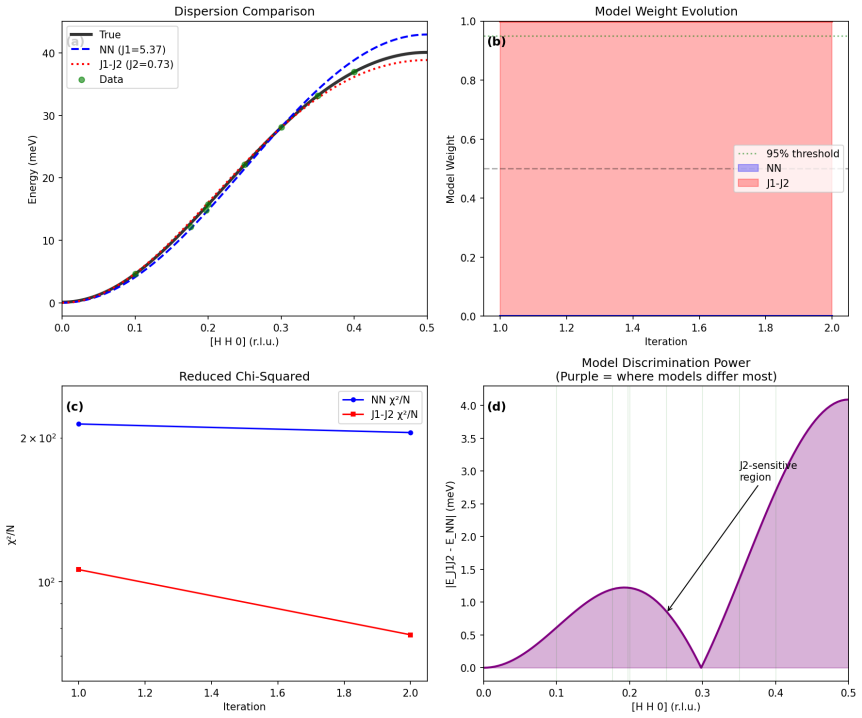
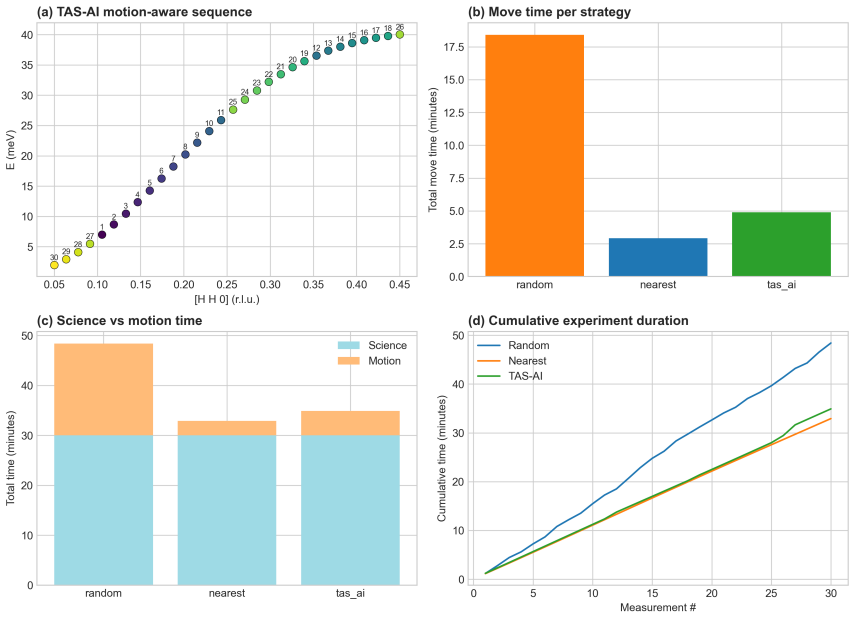
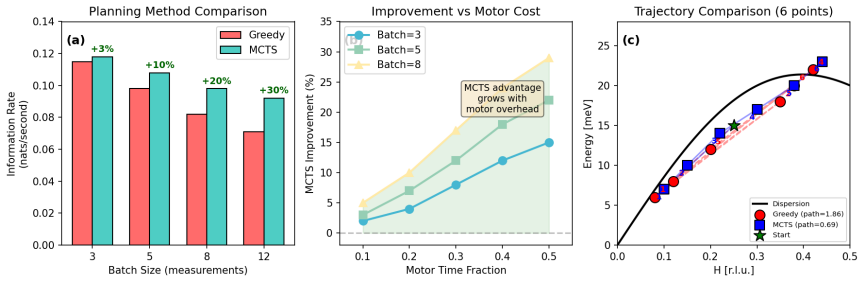
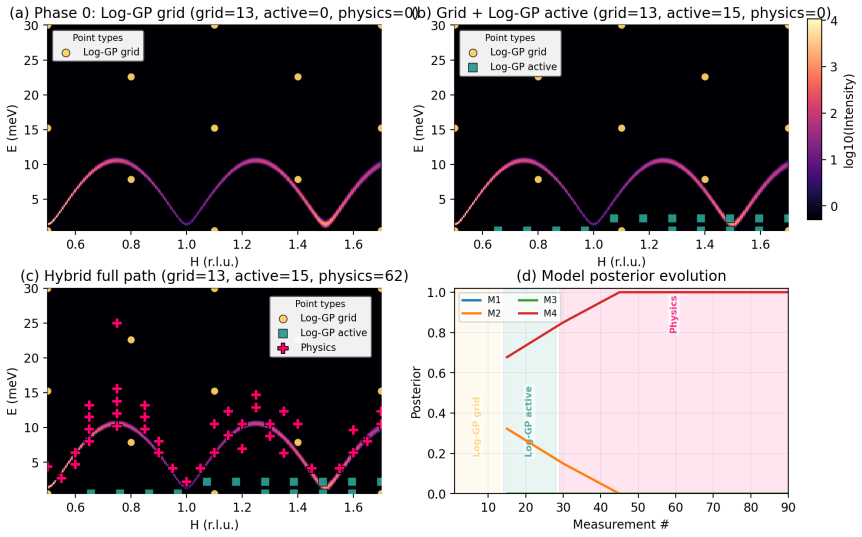
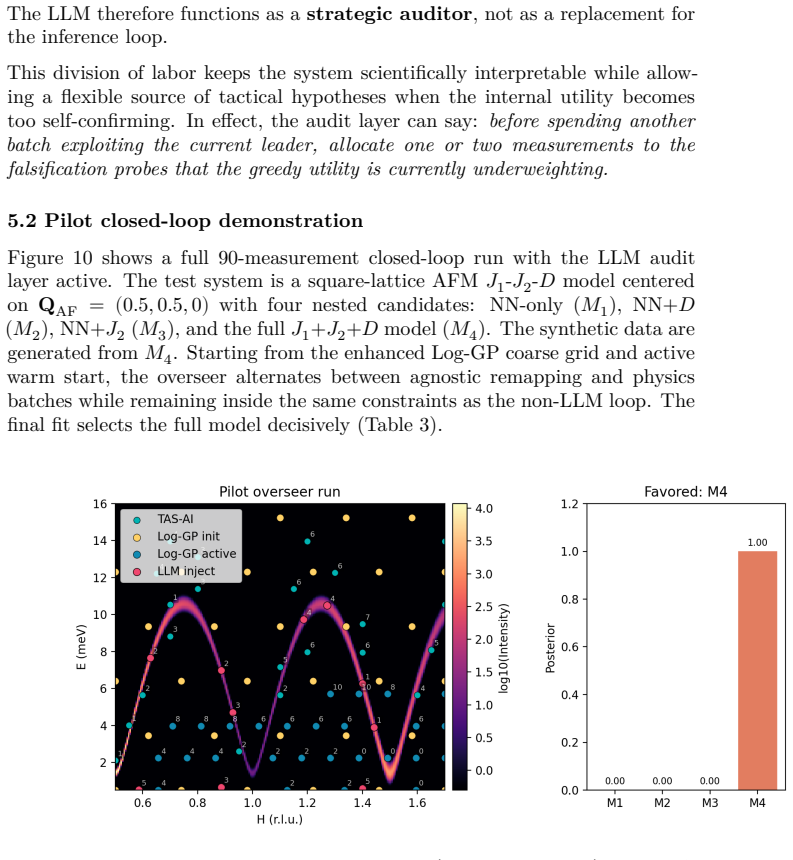
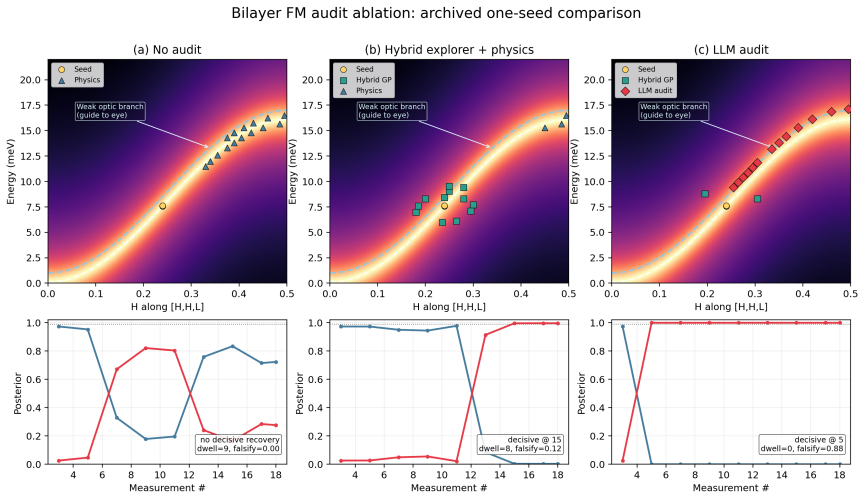
The authors claim that discovery and inference are distinct tasks requiring distinct controllers. In blind benchmarks, model-agnostic methods reach global error thresholds more reliably and with fewer measurements than physics-informed planning. Once the signal is localized, the physics-informed stage performs Hamiltonian discrimination via AIC evidence ratios and parameter refinement. A constrained falsification channel mitigates algorithmic myopia, in which posterior-weighted design over-refines the current leading model while under-sampling low-intensity probes that could falsify it. Motion-aware scheduling further reduces wall-clock time.
What carries the argument
The TAS-AI hybrid framework, which explicitly switches from model-agnostic controllers for signal detection to physics-informed controllers for model discrimination and refinement, together with a constrained falsification channel that forces sampling of low-intensity probes.
If this is right
- Model-agnostic methods reach global error thresholds more reliably and with fewer measurements than physics-informed planning in blind reconstruction benchmarks.
- Physics-informed planning reaches decisive AIC-derived evidence ratios greater than 100 in fewer than 10 measurements for selecting between competing Hamiltonians.
- Motion-aware scheduling reduces wall-clock time by 32 percent at a fixed measurement budget.
- The constrained falsification channel reduces time spent committed to an incorrect model without altering the Bayesian inference engine.
- Both deterministic top-two max-disagreement rules and LLM-based audit committees achieve the same reduction in time to correct model selection under identical constraints.
Where Pith is reading between the lines
- The same separation of detection from inference may apply to other autonomous characterization techniques such as X-ray or electron scattering.
- The open-source Python implementation makes it possible to test whether the simulated gains hold on actual laboratory instruments.
- Algorithmic myopia may appear in other Bayesian experimental design settings that involve multiple candidate models.
- Extending the framework to discriminate among more than two Hamiltonians would test how well the falsification channel scales.
Load-bearing premise
The high-fidelity digital twin accurately reproduces the noise, resolution, and motion constraints of a real triple-axis spectrometer, and the task separation seen in simulation generalizes to physical data.
What would settle it
Running the full TAS-AI workflow on a physical triple-axis spectrometer and checking whether it reaches the same global error threshold or AIC evidence ratio in the same number of measurements as the digital twin predicts.
Figures
read the original abstract
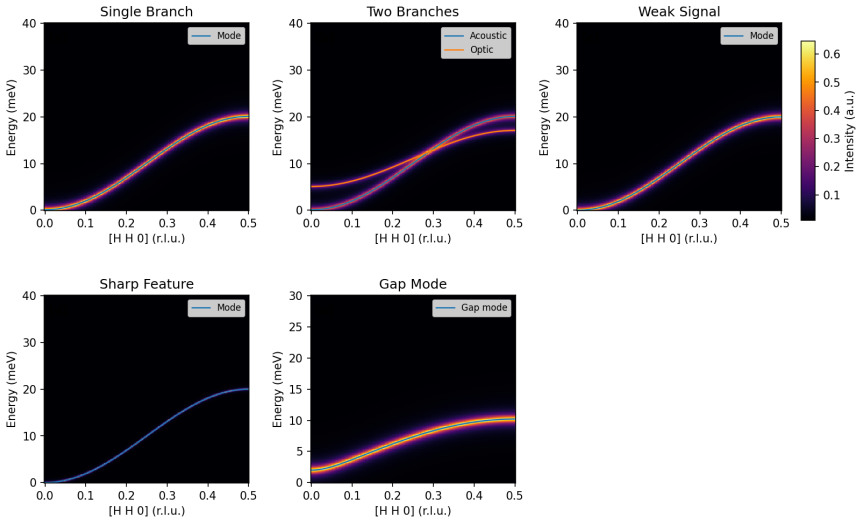
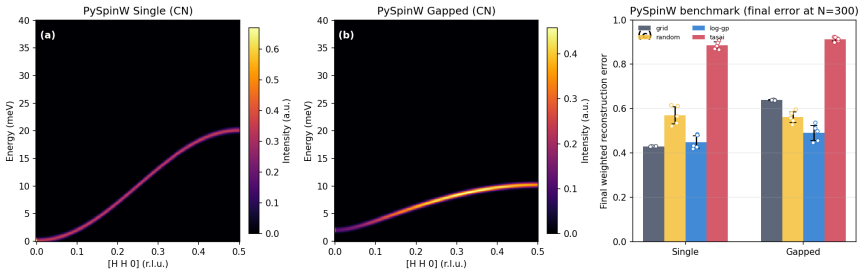
Autonomous neutron spectroscopy must solve three distinct tasks: detection (where is the signal?), inference (which Hamiltonian governs it?), and refinement (what are the parameters?). No single controller solves all three equally well. We present TAS-AI, a hybrid agnostic-to-physics-informed framework for autonomous triple-axis spin-wave spectroscopy that separates these tasks explicitly. In blind reconstruction benchmarks, model-agnostic methods such as random sampling, coarse grids, and Gaussian-process mappers reach a global error threshold more reliably and with fewer measurements than physics-informed planning, supporting the claim that discovery and inference are distinct tasks requiring distinct controllers. Once signal structure is localized, the physics-informed stage performs in-loop Hamiltonian discrimination and parameter refinement: in a controlled square-lattice test between nearest-neighbor-only and J1-J2 Hamiltonians, TAS-AI reaches a decisive AIC-derived evidence ratio (>100) in fewer than 10 measurements, while motion-aware scheduling cuts wall-clock time by 32% at a fixed measurement budget. We also identify a failure mode of posterior-weighted design, algorithmic myopia, in which the planner over-refines the current leading model while under-sampling low-intensity falsification probes. A constrained falsification channel sharply reduces time spent committed to the wrong model and accelerates correct model selection without modifying the Bayesian inference engine. In controlled two-model ablations, both a deterministic top-two max-disagreement rule and an LLM-based audit committee achieve this gain under identical constraints. We demonstrate the full workflow in silico using a high-fidelity digital twin and provide an open-source Python implementation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents TAS-AI, a hybrid active-learning framework for autonomous triple-axis spin-wave spectroscopy that explicitly separates signal detection (via model-agnostic controllers such as random sampling, coarse grids, and Gaussian-process mappers) from subsequent physics-informed tasks of Hamiltonian model selection and parameter refinement. In blind in-silico reconstruction benchmarks using a high-fidelity digital twin, agnostic methods are shown to reach a global error threshold more reliably and with fewer measurements than physics-informed planning. The framework further demonstrates rapid AIC-based model discrimination (evidence ratio >100 in <10 measurements) between nearest-neighbor and J1-J2 Hamiltonians on a square lattice, a 32% reduction in wall-clock time via motion-aware scheduling, and a constrained falsification channel that mitigates algorithmic myopia in posterior-weighted design. Controlled two-model ablations and an open-source Python implementation are provided.
Significance. If the digital-twin results generalize, the work offers a practical route to more efficient use of limited neutron beam time for quantum-materials characterization, with the explicit task-separation insight providing a conceptual advance over monolithic active-learning approaches. The open code, controlled ablations, and identification of the myopia failure mode are concrete strengths that support reproducibility and extension. The central performance claims, however, rest entirely on in-silico benchmarks whose fidelity to real TAS noise statistics, resolution functions, and motion constraints remains unquantified.
major comments (3)
- [§4] §4 (blind reconstruction benchmarks): the claim that model-agnostic controllers reach the global error threshold 'more reliably and with fewer measurements' is presented without reported success rates across independent trials, standard deviations, or statistical tests; the absence of these quantities leaves the quantitative superiority statement only partially supported.
- [§3.2] §3.2 (digital twin): all reported performance gaps between agnostic and physics-informed planners, as well as the AIC evidence ratios and two-model ablations, depend on the twin faithfully reproducing real TAS correlated background, sample mosaicity, and instrumental artifacts; no quantitative validation against experimental data is provided, so the observed task separation may not survive real measurements.
- [§5.1] §5.1 (falsification channel): the deterministic top-two max-disagreement rule and LLM-based audit committee are shown to reduce time spent on the wrong model, yet the paper does not specify the exact disagreement metric, the prior widths used in the Bayesian update, or the precise AIC formula, preventing direct replication of the >100 evidence-ratio result.
minor comments (2)
- The term 'algorithmic myopia' is introduced without a concise formal definition; a one-sentence mathematical characterization would improve clarity.
- Figure captions for the benchmark plots should explicitly state the number of Monte-Carlo realizations and the precise definition of the global error threshold used.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed report. The comments highlight important opportunities to strengthen statistical reporting, clarify the scope of the in-silico study, and improve reproducibility. We address each major comment below and will incorporate revisions as indicated.
read point-by-point responses
-
Referee: [§4] §4 (blind reconstruction benchmarks): the claim that model-agnostic controllers reach the global error threshold 'more reliably and with fewer measurements' is presented without reported success rates across independent trials, standard deviations, or statistical tests; the absence of these quantities leaves the quantitative superiority statement only partially supported.
Authors: We agree that the quantitative superiority claims require additional statistical support to be fully convincing. In the revised manuscript we will report success rates (fraction of independent trials reaching the global error threshold), standard deviations across runs, and results of appropriate non-parametric tests (e.g., Wilcoxon rank-sum) comparing agnostic versus physics-informed planners. These quantities will be added to the text of §4 and to the corresponding benchmark figures. revision: yes
-
Referee: [§3.2] §3.2 (digital twin): all reported performance gaps between agnostic and physics-informed planners, as well as the AIC evidence ratios and two-model ablations, depend on the twin faithfully reproducing real TAS correlated background, sample mosaicity, and instrumental artifacts; no quantitative validation against experimental data is provided, so the observed task separation may not survive real measurements.
Authors: The study is explicitly an in-silico benchmark that isolates the effect of task separation under controlled, reproducible conditions. The digital twin incorporates standard TAS resolution functions, correlated background models, and motion constraints drawn from the literature, but we have not performed a quantitative side-by-side comparison with a specific experimental dataset. We will expand the discussion in §3.2 and the conclusions to state the assumptions of the twin and to identify real-beam validation as an important future direction. The core methodological insight—that detection and inference benefit from distinct controllers—remains valid within the simulated environment used. revision: partial
-
Referee: [§5.1] §5.1 (falsification channel): the deterministic top-two max-disagreement rule and LLM-based audit committee are shown to reduce time spent on the wrong model, yet the paper does not specify the exact disagreement metric, the prior widths used in the Bayesian update, or the precise AIC formula, preventing direct replication of the >100 evidence-ratio result.
Authors: We agree that these details are required for replication. The revised manuscript will explicitly define: (i) the disagreement metric as the maximum absolute difference between the predictive means of the two leading models at each candidate point, (ii) the prior widths as uniform distributions over physically motivated intervals for the exchange couplings (e.g., J1, J2 ∈ [−10, 10] meV), and (iii) the AIC formula as AIC = 2k − 2 ln(ℒ) where ℒ is the Gaussian-process marginal likelihood. These specifications will be added to §5.1 and the methods section. revision: yes
Circularity Check
No significant circularity in empirical benchmarks or task separation claim
full rationale
The paper advances an empirical hybrid framework (TAS-AI) whose central claims rest on controlled in-silico benchmarks, blind reconstruction tests, two-model ablations, and AIC evidence ratios rather than any mathematical derivation chain. No equations are shown that reduce by construction to fitted inputs, self-definitions, or prior self-citations. Task separation (discovery vs. inference) is demonstrated via comparative performance metrics on a digital twin, not assumed or renamed into existence. The high-fidelity twin is an explicit modeling choice whose fidelity is an external assumption, not a circular reduction. Open code further supports independent verification. This is a standard non-circular empirical result.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Linear-intensity variance weighting. Rather than ranking candidates by raw log-space variance alone, the acquisition is weighted by a linear- space variance proxy so that dim background regions are not treated as equally valuable as bright signal regions. When the surrogate exposes log-space mean and variance (𝜇, 𝜎2)directly, this can be written as Var(𝐼)...
-
[2]
A 1D cosine taper in energy . We apply a soft window in 𝐸 that smoothly downweights the outer 10% of the energy domain while leaving the interior nearly unchanged. A stronger 2D taper in both 𝐸 and 𝐻 further suppresses edge selection, but in this model it can over-penalize low- |𝐻| regions where the dispersion is strongest. We therefore retain the energy-...
-
[3]
The current mode is held for at least two mea- surements before any switch is considered
Minimum run length. The current mode is held for at least two mea- surements before any switch is considered
-
[4]
F orced periodic exploration. A loggp_active batch is forced when- ever six measurements have elapsed since the previous Log-GP batch
-
[5]
Ambiguity triggers. Outside the forced-exploration condition, the router selects loggp_active whenever any of the following hold: posterior entropy exceeds 0.20, falsification-region coverage remains below 0.10, or the posterior margin (difference between the top two model weights) falls below 0.35
-
[6]
If none of the above triggers fire, the router selects physics refinement
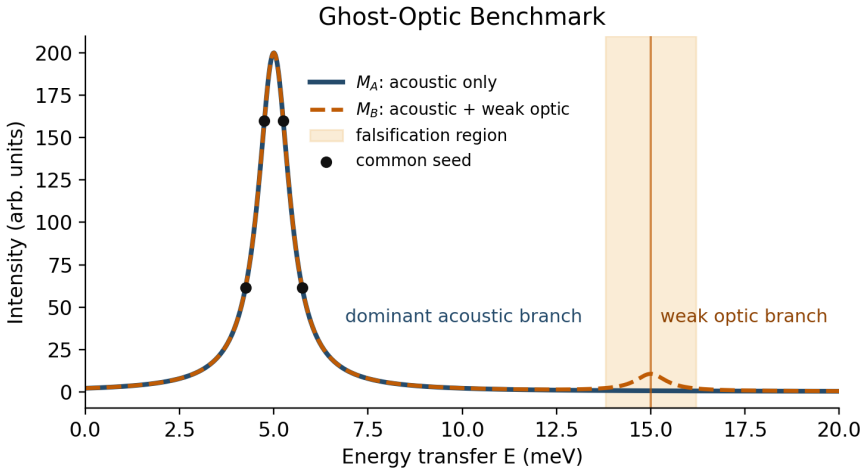
Default. If none of the above triggers fire, the router selects physics refinement. These thresholds were set before examining the LLM comparison and were not tuned to favor or disadvantage any policy. S5.2 Five-seed robustness check for the Section 5 ablations To test whether the one-seed ablation pattern was robust or merely anecdotal, we reran the ghos...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.