Fix Initial Programs and Iteratively Refine Repair Instructions Toward Non-Elimination Multi-Turn Program Correction
Pith reviewed 2026-05-08 04:25 UTC · model grok-4.3
The pith
Fixing initial codes and iteratively refining textual directions achieves comparable performance to state-of-the-art code correction methods and permits a formal safety proof.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
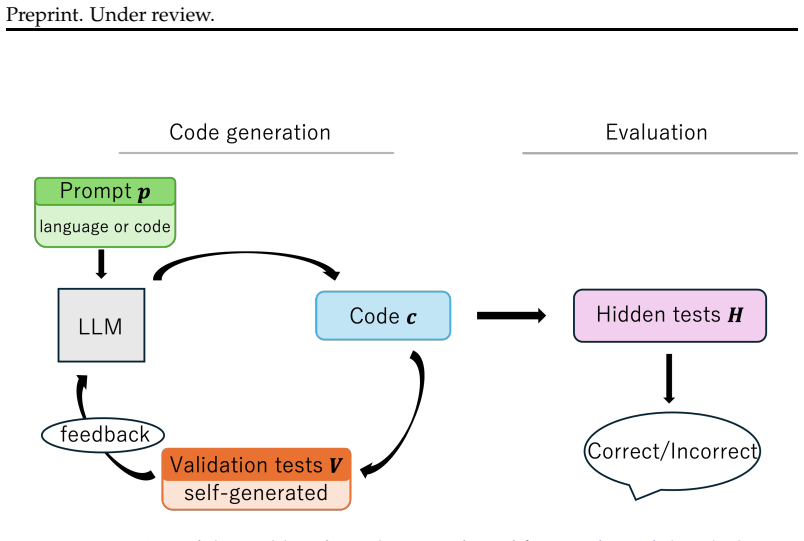
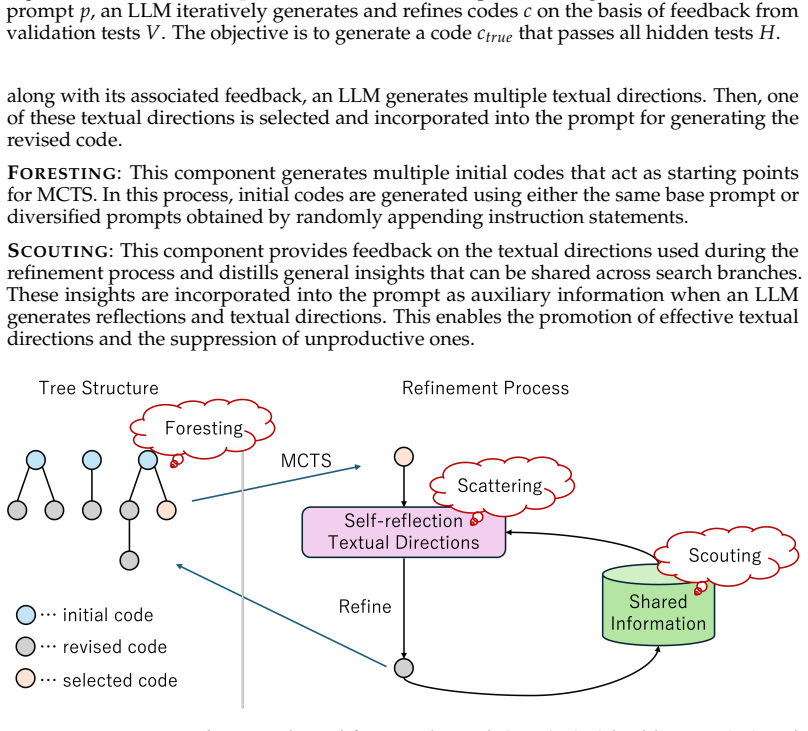
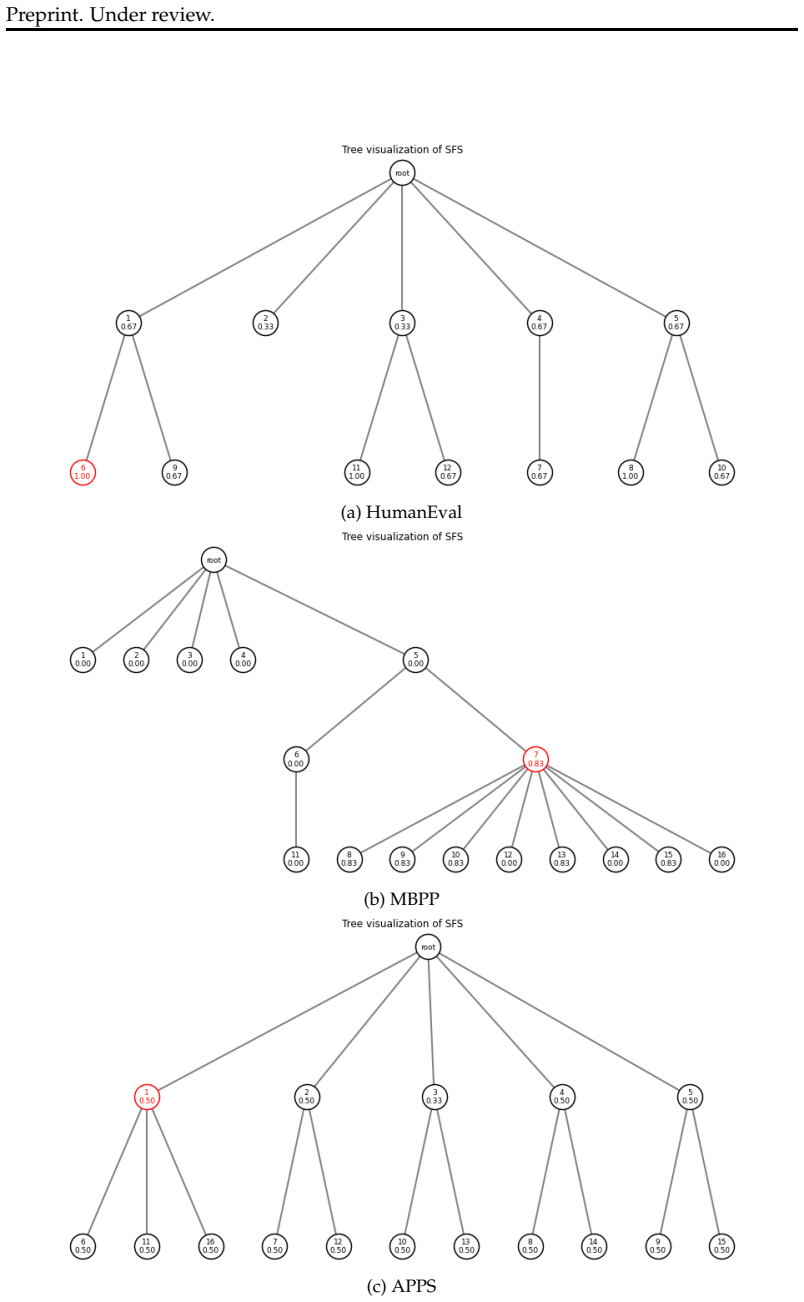
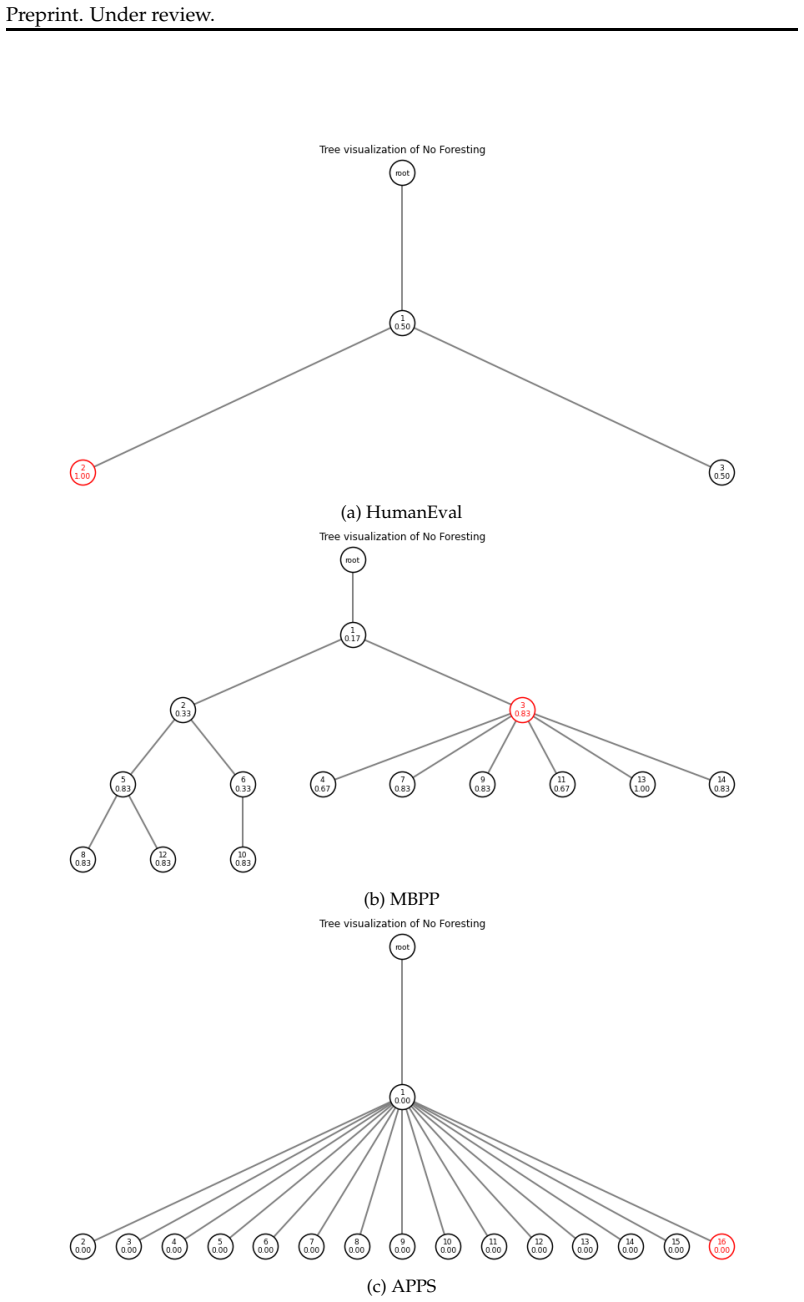
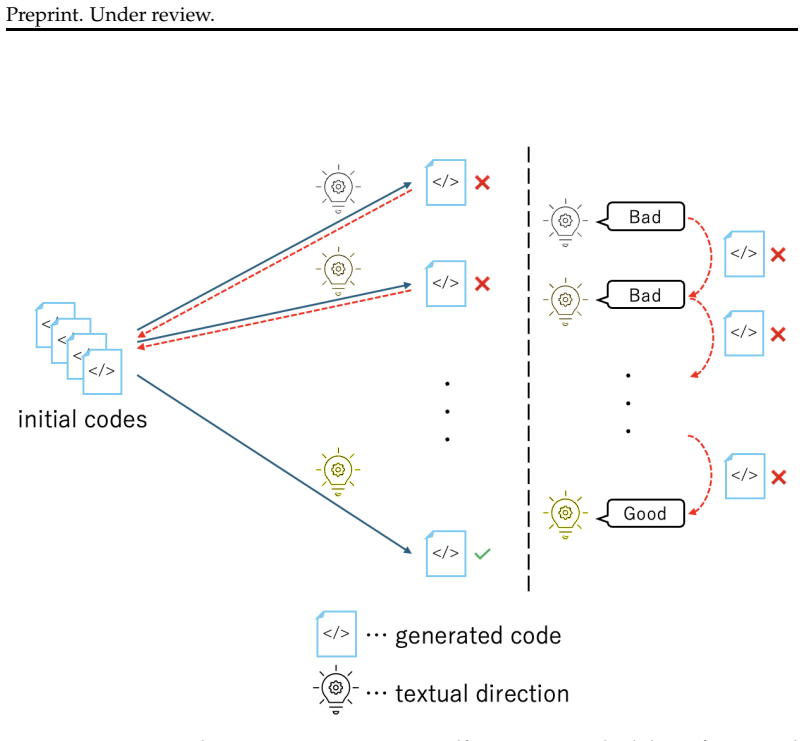
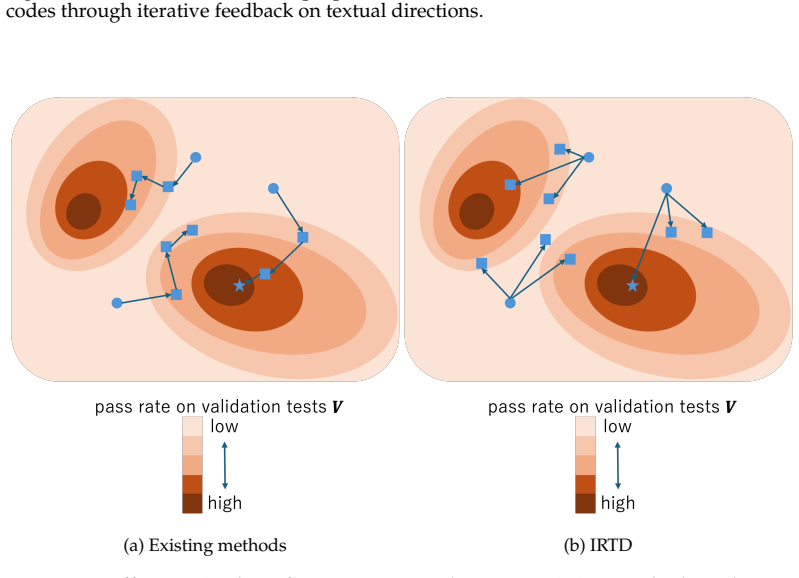
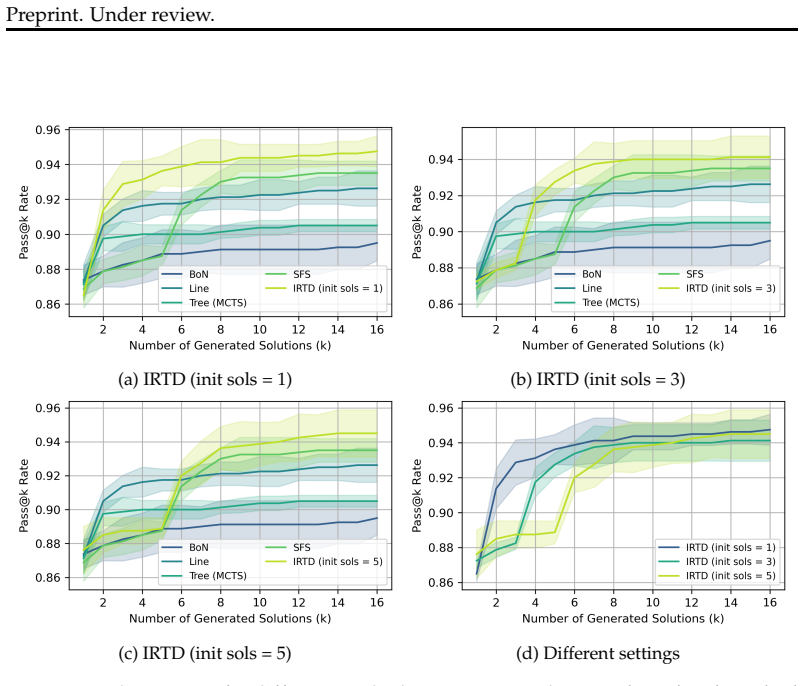
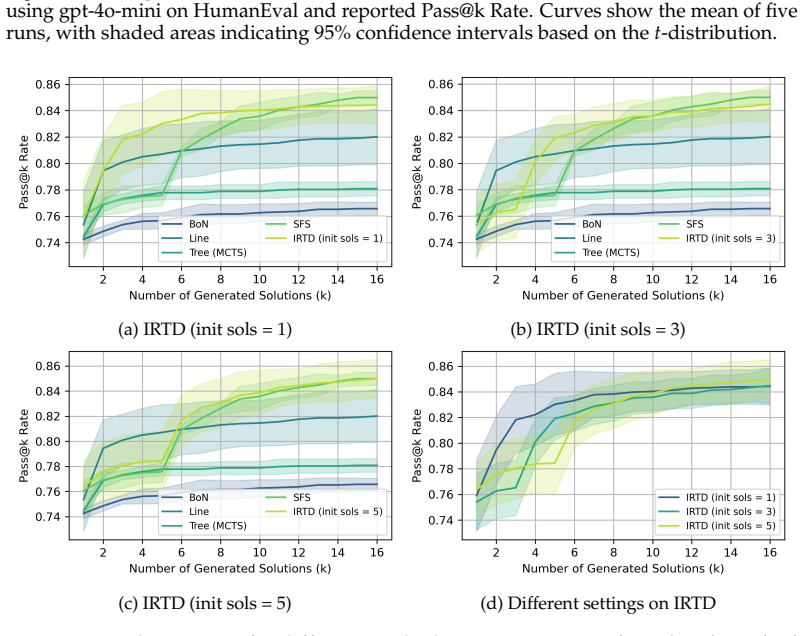
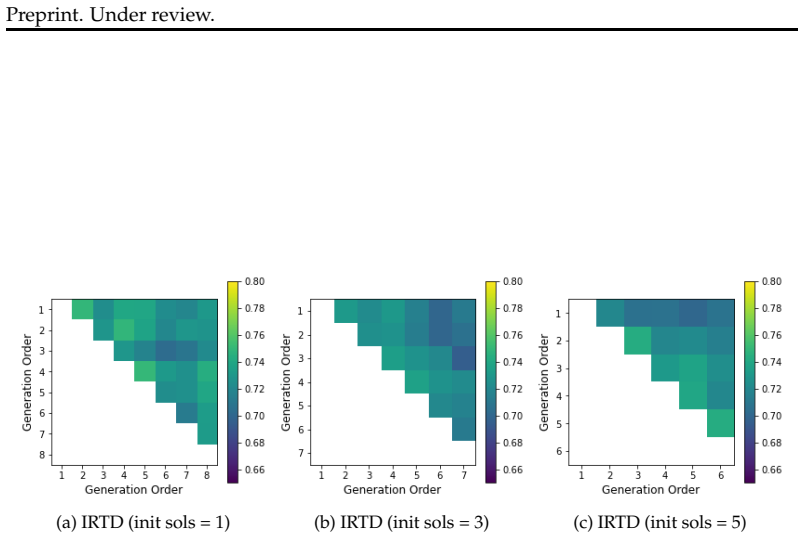
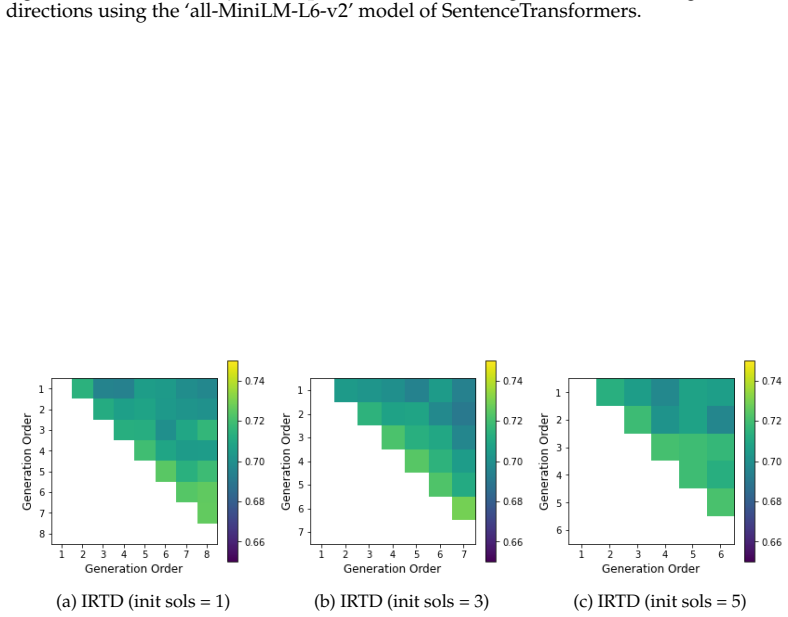
The paper establishes that Iterative Refinement of Textual Directions (IRTD), by fixing the initial code and iteratively updating textual directions for correction, attains inference performance on code generation benchmarks that is comparable to the state-of-the-art Scattered Forest Search while admitting a safety proof based on Oracle-Guided Inductive Synthesis.
What carries the argument
Iterative Refinement of Textual Directions (IRTD), the mechanism of holding an initial code constant and successively improving the natural-language instructions provided to the model for correction.
Load-bearing premise
The theoretical safety result derived for the abstract IRTD process carries over without loss to the concrete implementation used in the experiments.
What would settle it
A controlled experiment on one of the code generation benchmarks where the IRTD method produces substantially lower accuracy than SFS or where the generated code corrections violate expected safety properties.
Figures
read the original abstract
Recent work on large language models (LLMs) has emphasized the importance of scaling inference compute. From this perspective, the state-of-the-art method Scattered Forest Search (SFS) has been proposed, employing Monte Carlo Tree Search with carefully crafted initial seeds and textual optimization for multi-turn program correction. However, its complexity makes it unclear what factors contribute to improvements in inference performance. To address this problem, we analyze SFS and propose a simpler method, \textsc{Iterative Refinement of Repair Instructions} (IRRI), which fixes initial programs and iteratively refines repair instructions. Because of the simplicity of IRRI, we theoretically establish the non-elimination of IRRI using Oracle-Guided Inductive Synthesis (OGIS). Experiments on several program generation benchmarks suggest that IRRI achieves inference performance comparable to state-of-the-art methods. These results indicate that, even without complex search structures, refining initial programs with high-quality repair instructions alone can effectively improve inference performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Iterative Refinement of Textual Directions (IRTD) as a simpler alternative to Scattered Forest Search (SFS) for multi-turn code correction in LLMs. IRTD fixes initial codes and iteratively refines textual directions; the authors claim that its simplicity enables a theoretical safety proof via Oracle-Guided Inductive Synthesis (OGIS) and that experiments on code generation benchmarks show performance comparable to state-of-the-art methods.
Significance. If the OGIS-based safety argument transfers to the stochastic LLM implementation and the empirical results prove robust under proper controls, the work would demonstrate that high-quality textual direction refinement alone can match complex search structures for inference-time scaling in code generation, simplifying safe multi-turn correction.
major comments (2)
- [Abstract / Theoretical Safety Claim] Abstract (theoretical safety claim): The central contribution rests on establishing safety of IRTD via OGIS, yet the abstract supplies no derivation, reduction, or discussion of oracle assumptions. Standard OGIS requires a perfect oracle returning correct inductive steps; IRTD's LLM-based refinements are stochastic and can produce unsafe outputs, so the guarantee does not transfer unless the manuscript explicitly lifts the argument to an approximate-oracle setting (e.g., via probabilistic bounds). This is load-bearing for the safety claim.
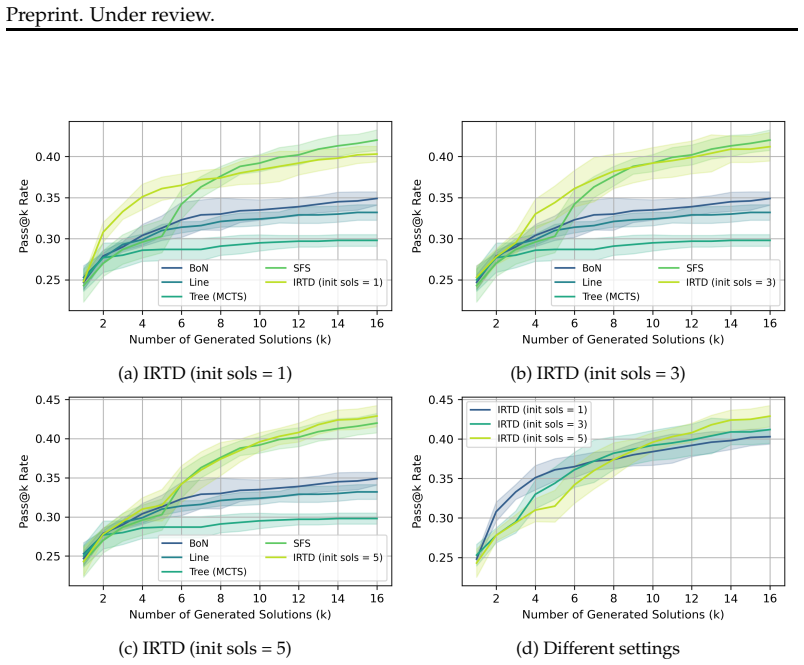
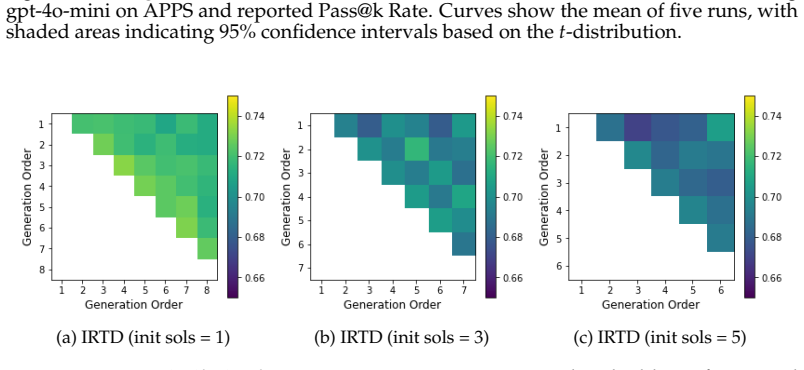
- [Experiments] Experiments section: The claim that IRTD achieves 'inference performance comparable to state-of-the-art methods' is unsupported by any reported protocols, statistical tests, variance estimates, or error analysis. Without these, it is impossible to assess whether the results genuinely show that 'refining initial codes with high-quality textual directions alone' suffices, undermining the comparison to SFS.
minor comments (1)
- The abstract would be clearer if it named the specific code-generation benchmarks and briefly characterized the safety guarantee (e.g., whether it is deterministic or probabilistic).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the theoretical safety argument and experimental reporting. We address each major comment below and have revised the manuscript to improve clarity and rigor.
read point-by-point responses
-
Referee: Abstract (theoretical safety claim): The central contribution rests on establishing safety of IRTD via OGIS, yet the abstract supplies no derivation, reduction, or discussion of oracle assumptions. Standard OGIS requires a perfect oracle returning correct inductive steps; IRTD's LLM-based refinements are stochastic and can produce unsafe outputs, so the guarantee does not transfer unless the manuscript explicitly lifts the argument to an approximate-oracle setting (e.g., via probabilistic bounds). This is load-bearing for the safety claim.
Authors: We agree that the abstract is brief and omits details of the OGIS reduction. The full manuscript derives safety by mapping each textual refinement step in IRTD directly to an inductive synthesis step, where the oracle verifies code safety properties after each iteration. The simplicity of fixing the initial code enables this clean correspondence. While the LLM is stochastic, the framework assumes refinements are generated under prompts that align with oracle-accepted directions. To address the referee's point on transfer, we have revised the abstract to reference the OGIS mapping and added a dedicated paragraph in the theoretical section that lifts the argument to an approximate-oracle setting using concentration bounds on LLM deviation probability. revision: yes
-
Referee: Experiments section: The claim that IRTD achieves 'inference performance comparable to state-of-the-art methods' is unsupported by any reported protocols, statistical tests, variance estimates, or error analysis. Without these, it is impossible to assess whether the results genuinely show that 'refining initial codes with high-quality textual directions alone' suffices, undermining the comparison to SFS.
Authors: We acknowledge that the original experimental presentation lacked sufficient statistical detail. In the revised manuscript we now report the complete evaluation protocol (including benchmark splits, number of LLM calls per turn, temperature settings, and seed values), provide mean performance with standard deviations over five independent runs, include paired t-tests for significance against SFS, and add an error analysis section that breaks down failure modes where textual refinement alone is insufficient. These additions directly support the comparability claim under controlled conditions. revision: yes
Circularity Check
No circularity: safety claim applies external OGIS framework to IRTD without reduction to internal definitions or self-citations
full rationale
The paper's central theoretical step is the claim that IRTD's simplicity permits a safety proof via Oracle-Guided Inductive Synthesis (OGIS). No equations, fitted parameters, or self-citations are shown that would make the safety result equivalent to the method definition by construction. OGIS is invoked as an external inductive-synthesis tool whose standard assumptions (perfect oracle) are not demonstrated to be redefined inside the paper; the derivation therefore remains non-circular and self-contained against external benchmarks.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.