MemeScouts@LT-EDI 2026: Asking the Right Questions -- Prompted Weak Supervision for Meme Hate Speech Detection
Pith reviewed 2026-05-08 03:34 UTC · model grok-4.3
The pith
Decomposing meme hate speech detection into targeted questions answered by a vision-language model outperforms direct end-to-end classification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
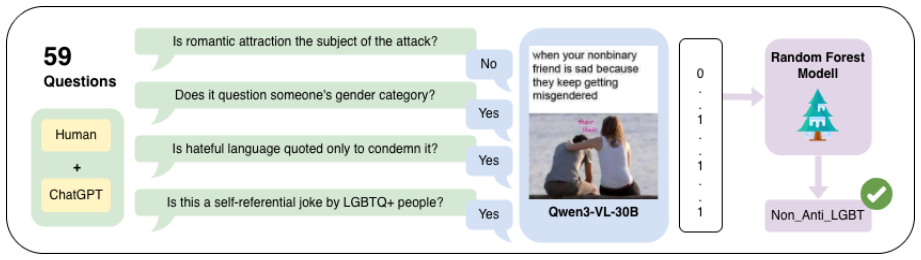
We propose a prompted weak supervision (PWS) approach that decomposes meme understanding into targeted, question-based labeling functions with constrained answer options for homophobia and transphobia detection. Using a quantized Qwen3-VLM to extract features by answering targeted questions, our method outperforms direct VLM classification, with substantial gains for Chinese and Hindi, ranking 1st in English, 2nd in Chinese, and 3rd in Hindi. Iterative refinement via error-driven LF expansion and feature pruning reduces redundancy and improves generalization.
What carries the argument
Prompted weak supervision using question-based labeling functions with constrained answers on a quantized vision-language model to extract features for classification.
If this is right
- Outperforms direct VLM classification in multilingual meme hate speech detection.
- Achieves first place in English, second in Chinese, and third in Hindi in the LT-EDI 2026 shared task.
- Substantial gains particularly for Chinese and Hindi languages.
- Iterative error-driven labeling function expansion and feature pruning improves generalization by reducing redundancy.
Where Pith is reading between the lines
- Such question decomposition might help in other tasks involving implicit meaning in images and text, like detecting irony or cultural references.
- Constrained answer options could limit the propagation of model biases in sensitive classification tasks.
- Testing the approach on additional languages or different VLM architectures would show how broadly the benefits apply.
Load-bearing premise
That decomposing meme understanding into targeted question-based labeling functions with constrained answer options can reliably capture subtle cues such as sarcasm, context, and implicitness without the VLM introducing systematic errors or biases.
What would settle it
A controlled experiment on memes relying heavily on sarcasm or cultural implicitness where the question-answering method produces more errors than direct classification would disprove the advantage.
Figures







read the original abstract
Detecting hate speech in memes is challenging due to their multimodal nature and subtle, culturally grounded cues such as sarcasm and context. While recent vision-language models (VLMs) enable joint reasoning over text and images, end-to-end prompting can be brittle, as a single prediction must resolve target, stance, implicitness, and irony. These challenges are amplified in multilingual settings. We propose a prompted weak supervision (PWS) approach that decomposes meme understanding into targeted, question-based labeling functions with constrained answer options for homophobia and transphobia detection in the LT-EDI 2026 shared task. Using a quantized Qwen3-VLM to extract features by answering targeted questions, our method outperforms direct VLM classification, with substantial gains for Chinese and Hindi, ranking 1st in English, 2nd in Chinese, and 3rd in Hindi. Iterative refinement via error-driven LF expansion and feature pruning reduces redundancy and improves generalization. Our results highlight the effectiveness of prompted weak supervision for multilingual multimodal hate speech detection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a prompted weak supervision (PWS) approach for detecting homophobia and transphobia in memes across English, Chinese, and Hindi for the LT-EDI 2026 shared task. It decomposes meme understanding into targeted question-based labeling functions with constrained answer options, uses a quantized Qwen3-VLM to extract features, applies iterative refinement via error-driven LF expansion and feature pruning, and claims to outperform direct VLM classification with rankings of 1st in English, 2nd in Chinese, and 3rd in Hindi.
Significance. If the empirical claims hold under detailed scrutiny, the work would be significant for showing that structured decomposition of multimodal reasoning into constrained question-answering labeling functions can yield gains over end-to-end VLM prompting, particularly for culturally nuanced hate speech detection in non-English languages. This could inform more robust VLM pipelines in low-resource multilingual settings.
major comments (3)
- Abstract: The central claim of outperformance over direct VLM classification, with 'substantial gains for Chinese and Hindi' and specific task rankings, is unsupported by any numerical results, baseline comparisons, error bars, or statistical tests. This is load-bearing because the paper's contribution is framed as an empirical improvement via the PWS framework rather than prompt engineering alone.
- Method (labeling function design): The assumption that constrained question-based labeling functions using the quantized Qwen3-VLM reliably capture subtle cues such as sarcasm, context, and implicitness without systematic errors or biases is not validated. This is especially critical for Chinese and Hindi, where the largest gains are claimed; if the VLM's multilingual understanding is weak, the decomposition may propagate rather than mitigate errors.
- Results (iterative refinement): The abstract states that iterative refinement via error-driven LF expansion and feature pruning 'reduces redundancy and improves generalization,' but provides no ablation studies, effect sizes, before/after metrics, or controls to quantify its impact. This is load-bearing for claims about the full pipeline's effectiveness.
minor comments (2)
- Abstract: The acronyms 'PWS' and 'LF' appear without initial expansion, reducing clarity for readers outside weak supervision literature.
- Abstract: The model reference 'quantized Qwen3-VLM' lacks the exact model variant, quantization level, or prompting details needed for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important areas for strengthening the empirical presentation and validation of our prompted weak supervision approach. We address each major comment below and commit to revisions that improve clarity without altering the core claims.
read point-by-point responses
-
Referee: Abstract: The central claim of outperformance over direct VLM classification, with 'substantial gains for Chinese and Hindi' and specific task rankings, is unsupported by any numerical results, baseline comparisons, error bars, or statistical tests. This is load-bearing because the paper's contribution is framed as an empirical improvement via the PWS framework rather than prompt engineering alone.
Authors: We agree that the abstract should be self-contained and include key quantitative support for the claims. The results section contains the full experimental details, including F1 scores for the PWS method versus direct VLM classification, language-specific gains, and the reported task rankings. We will revise the abstract to incorporate these specific metrics, baseline comparisons, and any available statistical details from the evaluation. This addresses the load-bearing nature of the empirical contribution. revision: yes
-
Referee: Method (labeling function design): The assumption that constrained question-based labeling functions using the quantized Qwen3-VLM reliably capture subtle cues such as sarcasm, context, and implicitness without systematic errors or biases is not validated. This is especially critical for Chinese and Hindi, where the largest gains are claimed; if the VLM's multilingual understanding is weak, the decomposition may propagate rather than mitigate errors.
Authors: The labeling functions were constructed from linguistic analysis of hate speech patterns in memes, with constrained options intended to reduce open-ended hallucination risks. Empirical support comes from the observed performance improvements over direct classification, particularly in the non-English tracks. We acknowledge that direct per-LF validation (e.g., accuracy on subtle cues) is not explicitly reported. We will add a dedicated error analysis subsection with examples of LF behavior on sarcasm and implicitness in Chinese and Hindi memes, plus any available checks against manual annotations. revision: partial
-
Referee: Results (iterative refinement): The abstract states that iterative refinement via error-driven LF expansion and feature pruning 'reduces redundancy and improves generalization,' but provides no ablation studies, effect sizes, before/after metrics, or controls to quantify its impact. This is load-bearing for claims about the full pipeline's effectiveness.
Authors: We agree that the contribution of the iterative refinement component requires explicit quantification to support the pipeline claims. The current manuscript describes the process but does not include ablations. We will add ablation experiments in the results section, reporting before/after F1 scores, redundancy metrics, and generalization indicators across languages to demonstrate the impact of error-driven LF expansion and feature pruning. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper describes an empirical prompted weak supervision framework that decomposes meme analysis into targeted VLM question-answering labeling functions, then reports performance gains over direct VLM classification on the LT-EDI 2026 multilingual meme hate speech task. No equations, parameter fits, or derivations are presented that reduce by construction to the inputs; the central claim rests on external experimental rankings (1st English, 2nd Chinese, 3rd Hindi) rather than self-referential definitions or self-citation chains. The method is self-contained against the provided baselines and does not invoke uniqueness theorems or ansatzes from prior author work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Leveraging large language models for struc- ture learning in prompted weak supervision. In2023 IEEE International Conference on Big Data (Big- Data), pages 875–884. Riza Velioglu and Jewgeni Rose. 2020. Detecting hate speech in memes using multimodal deep learning approaches: Prize-winning solution to hateful memes challenge.ArXiv, abs/2012.12975. An Yang...
-
[2]
InProceedings of the 16th ACM Web Science Conference, pages 241–249
Hate speech detection and reclaimed language: Mitigating false positives and compounded discrimi- nation. InProceedings of the 16th ACM Web Science Conference, pages 241–249. A LF Creation Prompt Figure 4 shows the initial prompt used for Chat- GPT assistance on the creation of the questions that composed the labeling functions. I have potentially homopho...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.