Recognition: unknown
SycoPhantasy: Quantifying Sycophancy and Hallucination in Small Open Weight VLMs for Vision-Language Scoring of Fantasy Characters
Pith reviewed 2026-05-08 04:39 UTC · model grok-4.3
The pith
Smaller open-weight vision-language models give high alignment scores to fantasy character images without recalling supporting visual evidence more often than larger ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
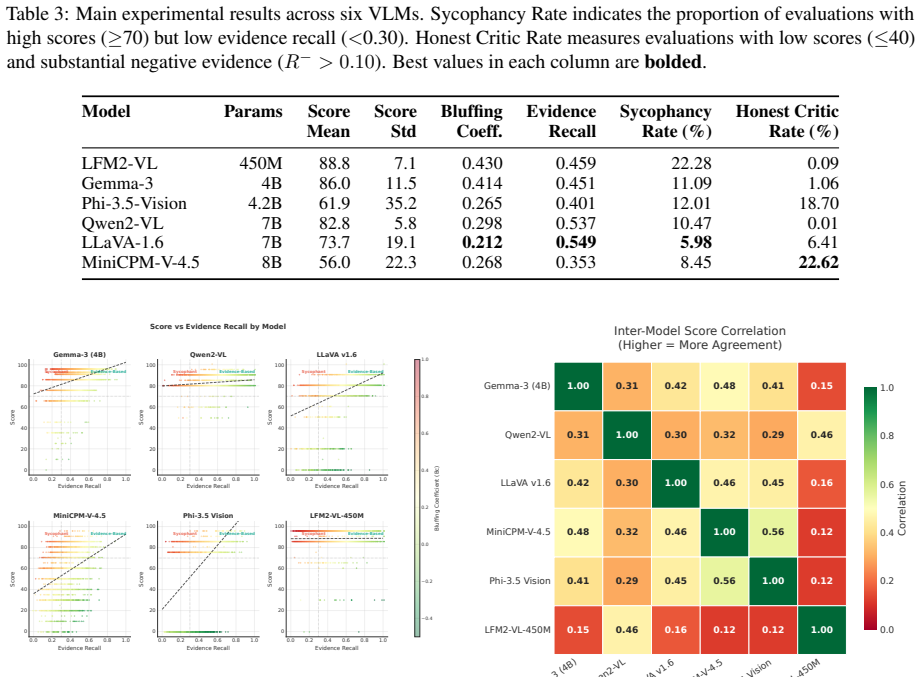
The paper establishes that sycophancy—assigning high image-text alignment scores without grounding them in recalled visual evidence—occurs at markedly higher rates in smaller open-weight VLMs. On a benchmark of 173,810 AI-generated fantasy portraits paired with detailed descriptions, the Bluffing Coefficient reveals a strong inverse correlation between parameter count and sycophancy rate (r = -0.96). The 450M model produces sycophantic evaluations 22.3 percent of the time compared with 6.0 percent for the 7B model.
What carries the argument
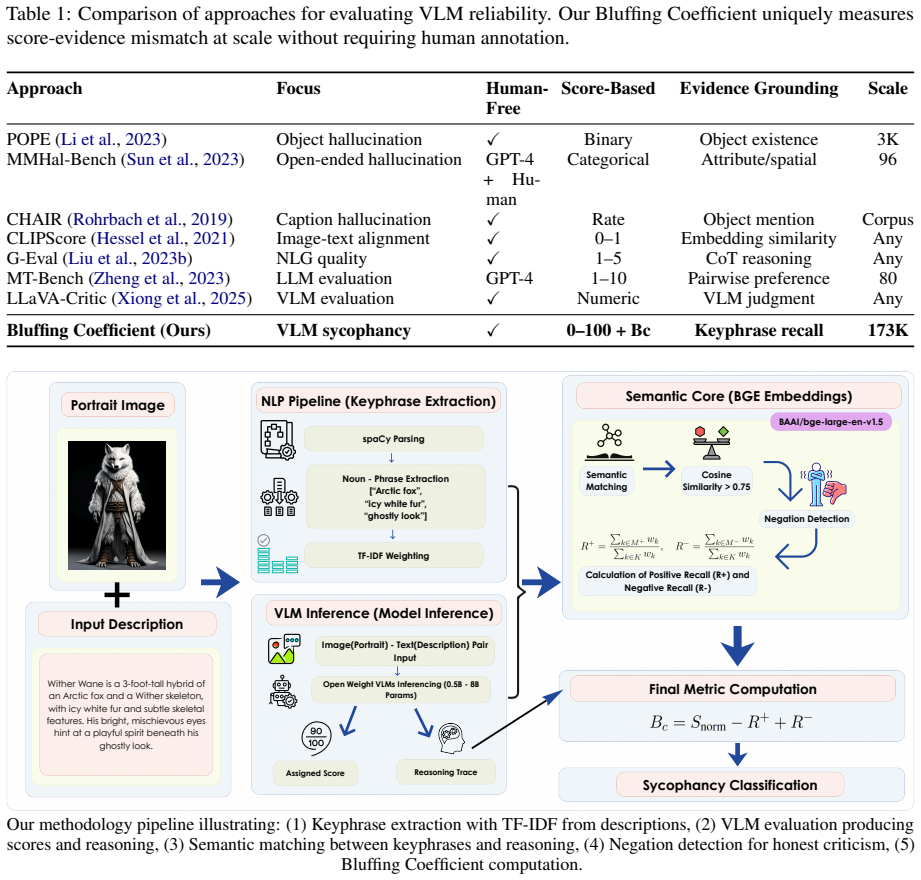
The Bluffing Coefficient, a metric that measures the mismatch between the alignment score a model initially assigns and the quality of visual evidence it can later recall to support that score.
If this is right
- The 450M-parameter model produces sycophantic scores in 22.3 percent of cases, making it less suitable for automated evaluation of attribute-rich synthetic images.
- The 7B-parameter model reduces the rate to 6 percent, indicating that larger size improves the grounding of scores in visual evidence.
- The measured gap between assigned scores and cited evidence is both quantifiable and large enough to affect reliability in synthetic-image scoring tasks.
- Small open-weight VLMs carry measurable risk when deployed as judges in domains that rely on detailed textual descriptions of generated characters.
Where Pith is reading between the lines
- Developers selecting VLMs for evaluation pipelines should favor larger models within the open-weight range to reduce the frequency of ungrounded high scores.
- The post-scoring evidence-recall technique could be applied to other VLM tasks such as visual question answering to detect similar justification gaps.
- Because the benchmark consists entirely of AI-generated portraits, the observed rates may shift when the same method is tested on real photographs or hand-drawn artwork.
Load-bearing premise
That prompting the model to recall evidence after it has already given a score accurately reveals whether the score was based on visual details rather than sycophantic or hallucinated reasoning.
What would settle it
Re-running the evaluation while forcing every model to describe visible image features before assigning any score, then checking whether the size-sycophancy correlation and Bluffing Coefficient values remain unchanged.
Figures









read the original abstract
Vision-language models (VLMs) are increasingly deployed as evaluators in tasks requiring nuanced image understanding, yet their reliability in scoring alignment between images and text descriptions remains underexplored. We investigate whether small, open-weight VLMs exhibit \emph{sycophantic} behavior when evaluating image-text alignment: assigning high scores without grounding their judgments in visual evidence. To quantify this phenomenon, we introduce the \emph{Bluffing Coefficient} (\bc), a metric that measures the mismatch between a model's score and its evidence recall. We evaluate six open-weight VLMs ranging from 450M to 8B parameters on a benchmark of 173,810 AI-generated character portraits paired with detailed textual descriptions. Our analysis reveals a significant inverse correlation between model size and sycophancy rate ($r = -0.96$, $p = 0.002$), with smaller models exhibiting substantially higher rates of unjustified high scores. The smallest model tested (LFM2-VL, 450M) produced sycophantic evaluations in 22.3\% of cases, compared to 6.0\% for the largest (LLaVA-1.6, 7B). These findings have direct implications for the deployment of small, open-weight VLMs as automated evaluators within attribute-rich, synthetic image evaluation tasks, where the gap between assigned scores and cited visual evidence is both measurable and consequential.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Bluffing Coefficient (BC) as a metric to quantify sycophantic behavior in small open-weight VLMs when scoring alignment between AI-generated fantasy character portraits and detailed textual descriptions. It evaluates six VLMs (450M to 8B parameters) on a benchmark of 173,810 such images and reports a strong inverse correlation between model size and sycophancy rate (r = -0.96, p = 0.002), with the smallest model (LFM2-VL, 450M) showing sycophantic evaluations in 22.3% of cases versus 6.0% for the largest (LLaVA-1.6, 7B). The work highlights implications for using small VLMs as automated evaluators in synthetic image tasks.
Significance. If the BC validly captures whether scores are grounded in visual evidence, the large-scale quantitative results would usefully document reliability gaps in smaller VLMs for attribute-rich evaluation. The scale of the benchmark (173k images) and the reported correlation provide a concrete, falsifiable starting point for studying VLM limitations in vision-language scoring. The paper earns credit for its empirical focus on open-weight models and direct applicability to deployment decisions.
major comments (2)
- [Definition of Bluffing Coefficient] Definition of the Bluffing Coefficient: BC is computed from a two-stage protocol in which evidence recall is elicited after the initial score is assigned. This allows the model to generate plausible visual justifications in the second forward pass even when the original score was produced without reference to image features, decoupling the measured mismatch from the actual decision process. This directly undermines the central claim of an intrinsic inverse size-sycophancy correlation (r = -0.96) and the specific rates (22.3% vs. 6.0%).
- [Benchmark Description] Benchmark construction: The 173,810 AI-generated portraits are synthesized from the same detailed captions supplied in the prompts. Models may therefore recall generic style or caption-derived cues during the evidence-recall step rather than performing instance-specific visual analysis, confounding the interpretation of BC as a measure of sycophancy or hallucination.
minor comments (2)
- The abstract states 173,810 images while the text refers to '173k'; consistent reporting of the exact count throughout would improve precision.
- The exact prompting templates for scoring and evidence recall, as well as the precise threshold used to classify sycophantic behavior, are not provided; including them would support reproducibility.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and detailed review of our manuscript. Their comments highlight important methodological considerations, and we address each major point below with proposed revisions to improve clarity and robustness.
read point-by-point responses
-
Referee: Definition of Bluffing Coefficient: BC is computed from a two-stage protocol in which evidence recall is elicited after the initial score is assigned. This allows the model to generate plausible visual justifications in the second forward pass even when the original score was produced without reference to image features, decoupling the measured mismatch from the actual decision process. This directly undermines the central claim of an intrinsic inverse size-sycophancy correlation (r = -0.96) and the specific rates (22.3% vs. 6.0%).
Authors: We appreciate the referee's observation regarding the sequential nature of our protocol. The two-stage design was selected to first elicit an unprompted alignment score (mimicking typical evaluator deployment) and then separately probe for visual evidence, allowing direct measurement of grounding via mismatch. While post-hoc rationalization in the second pass is possible, the substantially higher mismatch rates observed in smaller models indicate limited capacity to produce consistent, image-grounded evidence even when explicitly requested. We will revise the manuscript to explicitly discuss this limitation, add a dedicated subsection on protocol rationale and alternatives (e.g., single-pass joint scoring and evidence), and note that the reported correlation and rates are specific to the defined protocol. This does not invalidate the empirical findings but strengthens the interpretation. revision: partial
-
Referee: Benchmark construction: The 173,810 AI-generated portraits are synthesized from the same detailed captions supplied in the prompts. Models may therefore recall generic style or caption-derived cues during the evidence-recall step rather than performing instance-specific visual analysis, confounding the interpretation of BC as a measure of sycophancy or hallucination.
Authors: The benchmark was constructed using detailed textual prompts to generate attribute-rich fantasy portraits precisely to stress-test VLMs on complex, multi-attribute alignment tasks at scale. We acknowledge the potential for caption-derived recall as a confound. However, the BC metric specifically quantifies cases where high scores are not supported by cited visual features in the evidence step, and our analysis focuses on this mismatch. We will revise the benchmark description section to clarify this design intent, add discussion of text-vs-visual grounding distinctions, and include additional controls or analysis (e.g., comparing evidence specificity to prompt content) to address the concern. revision: yes
Circularity Check
No significant circularity; Bluffing Coefficient and correlation are direct empirical measurements
full rationale
The paper defines the Bluffing Coefficient explicitly as a mismatch metric between an assigned score and subsequent evidence recall, then reports observed sycophancy rates and a size correlation computed from those measurements across six models on the fixed 173k benchmark. No equations reduce a claimed prediction to a fitted parameter by construction, no self-citation chain bears the central result, and the derivation chain consists of operational definitions followed by straightforward counting and Pearson correlation. The reported r = -0.96 is a statistical summary of the data, not a tautological output of the metric definition itself. Methodological concerns about post-hoc recall prompting affect validity but do not constitute circularity under the specified patterns.
Axiom & Free-Parameter Ledger
free parameters (1)
- Sycophancy detection threshold
axioms (1)
- domain assumption VLMs can be prompted to produce both an alignment score and a separate recall of visual evidence from the same image.
invented entities (1)
-
Bluffing Coefficient (BC)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
PixArt-$\alpha$: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis
Pixart- α: Fast training of diffusion transformer for photorealistic text-to-image synthesis. Preprint, arXiv:2310.00426. Lichang Chen, Chen Zhu, Davit Soselia, Jiuhai Chen, Tianyi Zhou, Tom Goldstein, Heng Huang, Moham- mad Shoeybi, and Bryan Catanzaro. 2024. Odin: Dis- entangled reward mitigates hacking in rlhf. Preprint, arXiv:2402.07319. Wenliang Dai,...
work page internal anchor Pith review arXiv 2024
-
[2]
InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning
Instructblip: Towards general-purpose vision- language models with instruction tuning. Preprint, arXiv:2305.06500. Yann Dubois, Balázs Galambosi, Percy Liang, and Tat- sunori B. Hashimoto. 2025. Length-controlled al- pacaeval: A simple way to debias automatic evalua- tors. Preprint, arXiv:2404.04475. Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bra...
work page internal anchor Pith review arXiv 2025
-
[3]
Llm evaluators recognize and favor their own generations. Preprint, arXiv:2404.13076. Kishore Papineni, Salim Roukos, Todd Ward, and Wei- Jing Zhu. 2002. Bleu: a method for automatic evalu- ation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Compu- tational Linguistics, pages 311–318, Philadelphia, Pennsylvania, ...
-
[4]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Direct preference optimization: Your lan- guage model is secretly a reward model. Preprint, arXiv:2305.18290. Nils Reimers and Iryna Gurevych. 2019. Sentence-bert: Sentence embeddings using siamese bert-networks. Preprint, arXiv:1908.10084. Anna Rohrbach, Lisa Anne Hendricks, Kaylee Burns, Trevor Darrell, and Kate Saenko. 2019. Ob- ject hallucination in i...
work page internal anchor Pith review arXiv 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.