Understanding the Limits of Automated Evaluation for Code Review Bots in Practice
Pith reviewed 2026-05-08 02:58 UTC · model grok-4.3
The pith
Automated evaluation of code review bot comments reaches only moderate agreement with actual developer labels in industrial settings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
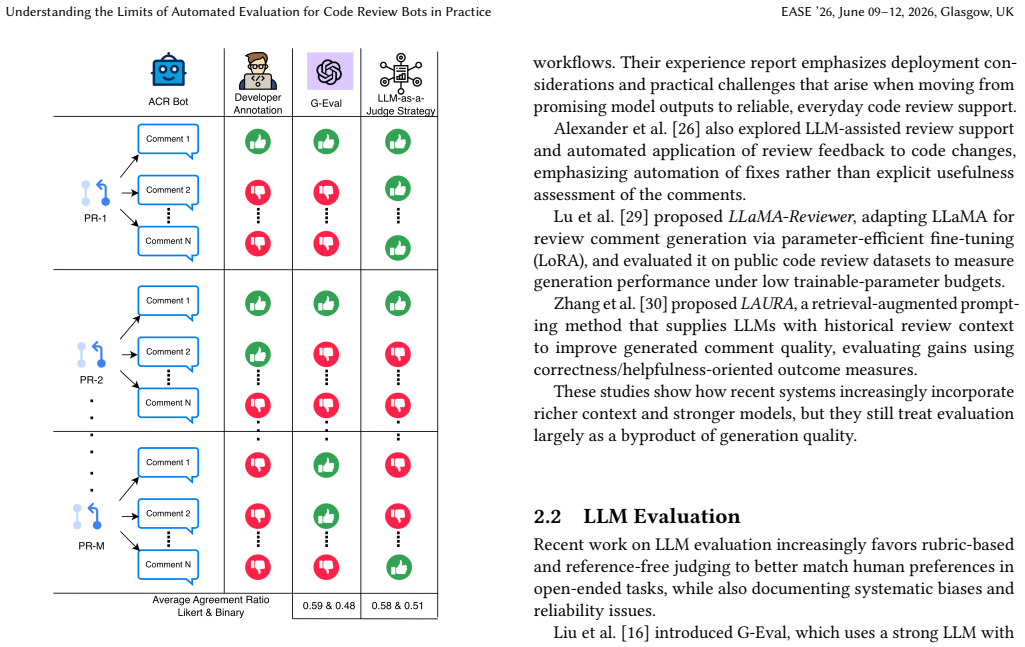
On an industrial dataset of 2,604 bot-generated pull-request comments labeled by engineers as fixed or wontFix, both G-Eval and an LLM-as-Judge pipeline produce agreement ratios of roughly 0.44 to 0.62 with the human labels. The same range appears whether the automated judge outputs a binary decision or a 0-4 Likert score, and the level of agreement varies with the underlying model. A director interview confirms that labeling behavior is shaped by workflow pressures and organizational constraints rather than comment quality alone.
What carries the argument
Direct comparison of G-Eval and LLM-as-Judge outputs against developer fixed/wontFix labels on real industrial pull-request comments.
If this is right
- Developer actions on bot comments cannot be treated as objective ground truth for evaluation.
- Automated evaluation performance remains sensitive to model choice and to binary versus scale-based scoring.
- Static comment text alone omits the contextual factors that drive real developer decisions.
- Industrial adoption of automated code review bots will require evaluation approaches that account for workflow dynamics.
Where Pith is reading between the lines
- Evaluation systems for code review bots may need to ingest live project metadata such as deadline pressure or reviewer workload to improve alignment.
- Similar limits could appear when automating assessment of other developer-assistance tools that produce suggestions in context-dependent settings.
- Hybrid human-AI loops might remain necessary for reliable quality signals until richer context can be fed to evaluators.
Load-bearing premise
That moderate agreement between the chosen automated evaluators and developer labels on this dataset indicates a general limit of automation rather than a fixable issue of prompt design or missing context.
What would settle it
A new industrial dataset on which the same or improved automated evaluators reach agreement above 0.8 with developer labels after adding workflow metadata or richer prompts would falsify the claim of fundamental limits.
Figures

read the original abstract
Automated code review (ACR) bots are increasingly used in industrial software development to assist developers during pull request (PR) review. As adoption grows, a key challenge is how to evaluate the usefulness of bot-generated comments reliably and at scale. In practice, such evaluation often relies on developer actions and annotations that are shaped by contextual and organizational factors, complicating their use as objective ground truth. We examine the feasibility and limitations of automating the evaluation of LLM-powered ACR bots in an industrial setting. We analyze an industrial dataset from Beko comprising 2,604 bot-generated PR comments, each labeled by software engineers as fixed/wontFix. Two automated evaluation approaches, G-Eval and an LLM-as-a-Judge pipeline, are applied using both binary decisions and a 0-4 Likert-scale formulation, enabling a controlled comparison against developer-provided labels. Across Gemini-2.5-pro, GPT-4.1-mini, and GPT-5.2, both evaluation strategies achieve only moderate alignment with human labels. Agreement ratios range from approximately 0.44 to 0.62, with noticeable variation across models and between binary and Likert-scale formulations, indicating sensitivity to both model choice and evaluation design. Our findings highlight practical limitations in fully automating the evaluation of ACR bot comments in industrial contexts. Developer actions such as resolving or ignoring comments reflect not only comment quality, but also contextual constraints, prioritization decisions, and workflow dynamics that are difficult to capture through static artifacts. Insights from a follow-up interview with a software engineering director further corroborate that developer labeling behavior is strongly influenced by workflow pressures and organizational constraints, reinforcing the challenges of treating such signals as objective ground truth.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports an empirical analysis of 2,604 bot-generated pull request comments from an industrial dataset at Beko, each labeled by developers as fixed or wontFix. It applies two automated evaluation approaches—G-Eval and an LLM-as-Judge pipeline—using both binary decisions and 0-4 Likert-scale formulations across models including Gemini-2.5-pro, GPT-4.1-mini, and GPT-5.2. The study finds only moderate agreement (approximately 0.44 to 0.62) with the developer labels and concludes that this reflects practical limitations of automated evaluation in industrial contexts, since developer actions embed contextual constraints, prioritization, and workflow dynamics not capturable from static artifacts; a follow-up director interview is cited in support.
Significance. If the central empirical findings hold after addressing methodological gaps, the work usefully demonstrates that developer resolution labels cannot be treated as clean ground truth for assessing code review bot quality. This has direct implications for industrial tool evaluation practices and for research on LLM-based judges in software engineering, underscoring the need to incorporate richer context or organizational factors rather than relying on static comment analysis alone.
major comments (2)
- [Evaluation Methodology and Results] The claim that moderate agreement indicates inherent limits of automated evaluation (rather than limits of the specific G-Eval and LLM-as-Judge implementations) is load-bearing for the paper's conclusions, yet the manuscript provides no details on prompt construction, no ablation on prompt variants, and no experiments incorporating richer context such as full PR diffs or metadata. Without such tests it remains unclear whether agreement could be substantially raised, weakening the generalization from observed numbers to 'practical limitations in fully automating' evaluation.
- [Dataset and Human Labeling] The human labels (fixed/wontFix) are treated as the reference standard, but the paper reports neither inter-annotator agreement among the labeling engineers nor any statistical tests (e.g., confidence intervals or significance of differences across models and binary/Likert formulations). These omissions make it difficult to assess the reliability of the 0.44–0.62 range and the strength of the claim that developer actions are irreducibly contextual.
minor comments (2)
- [Results] Exact per-model and per-formulation agreement values, together with any confusion matrices or breakdown tables, should be presented explicitly rather than summarized as a range in the abstract and text.
- [Evaluation Approaches] The distinction between binary and Likert formulations is mentioned but the precise mapping of Likert scores to binary decisions (or vice versa) for comparison purposes is not stated clearly.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and describe the revisions we will incorporate to improve the manuscript.
read point-by-point responses
-
Referee: [Evaluation Methodology and Results] The claim that moderate agreement indicates inherent limits of automated evaluation (rather than limits of the specific G-Eval and LLM-as-Judge implementations) is load-bearing for the paper's conclusions, yet the manuscript provides no details on prompt construction, no ablation on prompt variants, and no experiments incorporating richer context such as full PR diffs or metadata. Without such tests it remains unclear whether agreement could be substantially raised, weakening the generalization from observed numbers to 'practical limitations in fully automating' evaluation.
Authors: We appreciate the referee highlighting the need for greater methodological transparency to support our interpretation. The core empirical result is the moderate agreement (0.44-0.62) observed when applying established G-Eval and LLM-as-Judge pipelines to real industrial data; the director interview is cited to show that developer actions incorporate workflow and organizational factors absent from static comment text. To strengthen the paper, we will add the exact prompt templates for both binary and Likert-scale variants to an appendix. We will also include a limited ablation on prompt phrasing (e.g., variations in instruction specificity and scale anchoring). Experiments that incorporate full PR diffs and metadata were outside the scope of the current study due to data-access and computational constraints. We will revise the discussion and conclusion sections to frame the findings as evidence of practical limitations with current automated approaches on this dataset, rather than an absolute claim that no future implementation could improve agreement. revision: partial
-
Referee: [Dataset and Human Labeling] The human labels (fixed/wontFix) are treated as the reference standard, but the paper reports neither inter-annotator agreement among the labeling engineers nor any statistical tests (e.g., confidence intervals or significance of differences across models and binary/Likert formulations). These omissions make it difficult to assess the reliability of the 0.44–0.62 range and the strength of the claim that developer actions are irreducibly contextual.
Authors: We agree that additional statistical reporting will improve rigor. In the revised manuscript we will add bootstrap-derived confidence intervals for all reported agreement metrics and perform statistical significance tests (e.g., McNemar’s test for paired binary decisions and appropriate tests for Likert-scale differences) across models and evaluation formulations. Regarding inter-annotator agreement, the labels were assigned by individual developers as part of their standard PR workflow at Beko; the released dataset contains only these single annotations and does not include redundant ratings. Consequently, inter-annotator agreement cannot be computed. We will explicitly discuss this as a limitation of using authentic workflow labels and note that controlled multi-rater annotation studies could be pursued in future work. revision: partial
- Inter-annotator agreement for the developer labels, which cannot be computed because the dataset contains only single annotations per comment from the industrial workflow.
Circularity Check
No significant circularity: purely empirical comparison on fixed external labels
full rationale
The paper conducts a direct empirical evaluation by applying G-Eval and LLM-as-Judge pipelines (with specified models, binary/Likert formulations, and prompts) to a fixed dataset of 2,604 developer-labeled comments and measuring agreement (0.44-0.62). No equations, fitted parameters, or derivations exist; the central claim follows from observed moderate alignment plus a separate director interview. No self-citations are load-bearing for any result, and the human labels serve as an independent external benchmark rather than being derived from the automated methods. This is a standard non-circular empirical study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Developer actions on bot comments provide a usable reference signal for evaluating comment quality despite known contextual influences
Reference graph
Works this paper leans on
-
[1]
Understanding automated code review process and developer experience in industry
Hyungjin Kim, Yonghwi Kwon, Sangwoo Joh, Hyukin Kwon, Yeonhee Ryou, and Taeksu Kim. Understanding automated code review process and developer experience in industry. InProceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ESEC/FSE 2022, page 1398–1407, New York, NY, USA, 2022. ...
work page 2022
-
[2]
Modern code reviews - preliminary results of a systematic mapping study
Deepika Badampudi, Ricardo Britto, and Michael Unterkalmsteiner. Modern code reviews - preliminary results of a systematic mapping study. InProceedings of the Evaluation and Assessment on Software Engineering, EASE ’19, page 340–345. ACM, April 2019
work page 2019
-
[3]
Zezhou Yang, Cuiyun Gao, Zhaoqiang Guo, Zhenhao Li, Kui Liu, Xin Xia, and Yuming Zhou. A survey on modern code review: Progresses, challenges and opportunities.arXiv preprint arXiv:2405.18216, 2024
-
[4]
Automated code review in practice: An industrial case study
Umut Cihan, Vahid Haratian, Arda Icoz, Mert Kaan Gul, Omercan Devran, Emir- can Furkan Bayendur, Baykal Mehmet Uçar, and Eray Tüzün. Automated code review in practice: An industrial case study. InProceedings of the 46th Inter- national Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP), pages 1–12. ACM, 2024
work page 2024
-
[5]
SonarQube for IDE: Real-Time AI Code Verification
SonarSource. SonarQube for IDE: Real-Time AI Code Verification. https://www. sonarsource.com/products/sonarqube/ide/. Accessed: 2026-03-03
work page 2026
-
[6]
Bitsai-cr: Automated code review via llm in practice
Tao Sun, Jian Xu, Yuanpeng Li, Zhao Yan, Ge Zhang, Lintao Xie, Lu Geng, Zheng Wang, Yueyan Chen, Qin Lin, et al. Bitsai-cr: Automated code review via llm in practice. InProceedings of the 33rd ACM International Conference on the Foundations of Software Engineering, pages 274–285, 2025
work page 2025
-
[7]
Mairieli Wessel, Alexander Serebrenik, Igor Wiese, Igor Steinmacher, and Marco A. Gerosa. Effects of adopting code review bots on pull requests to oss projects. In2020 IEEE International Conference on Software Maintenance and Evolution (ICSME), pages 1–11, 2020
work page 2020
-
[8]
A survey of code review benchmarks and evaluation practices in pre-llm and llm era, 2026
Taufiqul Islam Khan, Shaowei Wang, Haoxiang Zhang, and Tse-Hsun Chen. A survey of code review benchmarks and evaluation practices in pre-llm and llm era, 2026
work page 2026
-
[9]
Evaluation of LLM- based software engineering tools: Practices, challenges, and future directions
Utku Boran Torun, Veli Karakaya, Ali Babar, and Eray Tüzün. Evaluation of LLM- based software engineering tools: Practices, challenges, and future directions. InProceedings of the 30th International Conference on Evaluation and Assessment in Software Engineering, EASE ’26, New York, NY, USA, 2026. Association for Computing Machinery
work page 2026
-
[10]
https://www.coderabbit.ai/, 2026
CodeRabbit: Ai-powered code review platform. https://www.coderabbit.ai/, 2026
work page 2026
-
[11]
Qodo: Ai code review and code quality platform. https://www.qodo.ai/, 2026
work page 2026
-
[12]
Snyk Code: Static application security testing (sast) documentation. https://docs. snyk.io/scan-with-snyk/snyk-code, 2026
work page 2026
-
[13]
Ai-assisted assessment of coding practices in modern code review
Manushree Vijayvergiya, Małgorzata Salawa, Ivan Budiselić, Dan Zheng, Pascal Lamblin, Marko Ivanković, Juanjo Carin, Mateusz Lewko, Jovan Andonov, Goran Petrović, Daniel Tarlow, Petros Maniatis, and René Just. Ai-assisted assessment of coding practices in modern code review. InProceedings of the 1st ACM Inter- national Conference on AI-Powered Software, A...
work page 2024
-
[14]
Exploring the potential of chatgpt in automated code refinement: An empirical study
Qi Guo, Junming Cao, Xiaofei Xie, Shangqing Liu, Xiaohong Li, Bihuan Chen, and Xin Peng. Exploring the potential of chatgpt in automated code refinement: An empirical study. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering, ICSE ’24, New York, NY, USA, 2024. Association for Computing Machinery
work page 2024
-
[15]
Fine-tuning and prompt engineering for large language models-based code review automation.Inf
Chanathip Pornprasit and Chakkrit Tantithamthavorn. Fine-tuning and prompt engineering for large language models-based code review automation.Inf. Softw. Technol., 175(C), November 2024
work page 2024
-
[16]
G-eval: NLG evaluation using gpt-4 with better human alignment
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. G-eval: NLG evaluation using gpt-4 with better human alignment. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 2511–2522, Singapore, December 2023. Association for Computational ...
work page 2023
- [17]
-
[18]
Humans or LLMs as the judge? a study on judgement bias
Guiming Hardy Chen, Shunian Chen, Ziche Liu, Feng Jiang, and Benyou Wang. Humans or LLMs as the judge? a study on judgement bias. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 8301–8327, Miami, Florida, USA, November 2024. Association for Computat...
work page 2024
-
[19]
Mingqi Gao, Xinyu Hu, Xunjian Yin, Jie Ruan, Xiao Pu, and Xiaojun Wan. LLM- based NLG evaluation: Current status and challenges.Computational Linguistics, 51:661–687, June 2025
work page 2025
-
[20]
RAGAs: Automated evaluation of retrieval augmented generation
Shahul Es, Jithin James, Luis Espinosa Anke, and Steven Schockaert. RAGAs: Automated evaluation of retrieval augmented generation. In Nikolaos Aletras and Orphee De Clercq, editors,Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations, pages 150–158, St. Julians, Malta, March 202...
work page 2024
-
[21]
GPT-4 Turbo Model | OpenAI API Documentation
OpenAI. GPT-4 Turbo Model | OpenAI API Documentation. https://developers. openai.com/api/docs/models/gpt-4-turbo. Accessed: 2026-03-03
work page 2026
-
[22]
Towards automating code review activities
Michele Tufano, Denys Poshyvanyk, Gabriele Bavota, and Massimiliano Di Penta. Towards automating code review activities. InProceedings of the 43rd International Conference on Software Engineering (ICSE), page 163–174, 2021
work page 2021
-
[23]
Zhiyu Li, Shuai Lu, Daya Guo, Nan Duan, Shailesh Jannu, Grant Jenks, Deep Ma- jumder, Jared Green, Alexey Svyatkovskiy, Shengyu Fu, et al. Codereviewer: Pre- training for automating code review activities.arXiv preprint arXiv:2203.09095, 2022
-
[24]
Auger: Auto- matically generating review comments with pre-trained models
Yucheng Li, Xin Xia, David Lo, Weiqin Wang, and Zhiqiang Chen. Auger: Auto- matically generating review comments with pre-trained models. InProceedings of the ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE), pages 1087–1099, 2022
work page 2022
-
[25]
Commentfinder: A simpler, faster, more accurate code review comment recommendation
Changrong Hong, Zhiqiang Chen, Xin Xia, and David Lo. Commentfinder: A simpler, faster, more accurate code review comment recommendation. In Proceedings of the ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE), pages 890– 902, 2022
work page 2022
-
[26]
Resolving code review comments with machine learning
Alexander Froemmgen, Jacob Austin, Peter Choy, Nimesh Ghelani, Lera Kharatyan, Gabriela Surita, Elena Khrapko, Pascal Lamblin, Pierre-Antoine Man- zagol, Marcus Revaj, Maxim Tabachnyk, Daniel Tarlow, Kevin Villela, Daniel Zheng, Satish Chandra, and Petros Maniatis. Resolving code review comments with machine learning. InProceedings of the 46th Internation...
work page 2024
-
[27]
Evaluating large language models for code review.arXiv preprint arXiv:2505.20206, 2025
Umut Cihan, Arda İçöz, Vahid Haratian, and Eray Tüzün. Evaluating large language models for code review.arXiv preprint arXiv:2505.20206, 2025
-
[28]
Automated code review using large language models at ericsson: An experience report, 2025
Shweta Ramesh, Joy Bose, Hamender Singh, A K Raghavan, Sujoy Roychowdhury, Giriprasad Sridhara, Nishrith Saini, and Ricardo Britto. Automated code review using large language models at ericsson: An experience report, 2025
work page 2025
-
[29]
Junyi Lu, Lei Yu, Xiaojia Li, Li Yang, and Chun Zuo. Llama-reviewer: Advancing code review automation with large language models through parameter-efficient fine-tuning. In2023 IEEE 34th International Symposium on Software Reliability Engineering (ISSRE), pages 647–658. IEEE, 2023
work page 2023
-
[30]
Laura: Enhancing code review generation with context-enriched retrieval-augmented llm
Yuxin Zhang, Yuxia Zhang, Zeyu Sun, Yanjie Jiang, and Hui Liu. Laura: Enhancing code review generation with context-enriched retrieval-augmented llm. In2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE), pages 2983–2995. IEEE, 2025
work page 2025
-
[31]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems, 36:46595–46623, 2023
work page 2023
-
[32]
Ruiqi Wang, Jiyu Guo, Cuiyun Gao, Guodong Fan, Chun Yong Chong, and Xin Xia. Can llms replace human evaluators? an empirical study of llm-as-a-judge in software engineering.Proceedings of the ACM on Software Engineering, 2(IS- STA):1955–1977, June 2025
work page 1955
-
[33]
Llm-as-a-judge for software engineering: Literature review, vision, and the road ahead.ACM Trans
Junda He, Jieke Shi, Terry Yue Zhuo, Christoph Treude, Jiamou Sun, Zhenchang Xing, Xiaoning Du, and David Lo. Llm-as-a-judge for software engineering: Literature review, vision, and the road ahead.ACM Trans. Softw. Eng. Methodol., February 2026. Just Accepted
work page 2026
-
[34]
Crscore: Ground- ing automated evaluation of code review comments in code claims and smells
Atharva Naik, Marcus Alenius, Daniel Fried, and Carolyn Rose. Crscore: Ground- ing automated evaluation of code review comments in code claims and smells. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 9049–9076, 2025
work page 2025
-
[35]
Gemini 2.5 Pro | Generative AI on Vertex AI
Google Cloud. Gemini 2.5 Pro | Generative AI on Vertex AI. https://docs.cloud. google.com/vertex-ai/generative-ai/docs/models/gemini/2-5-pro. Accessed: 2026-03-03
work page 2026
-
[36]
Introducing GPT-4.1 in the API
OpenAI. Introducing GPT-4.1 in the API. https://openai.com/index/gpt-4-1/. Accessed: 2026-03-03
work page 2026
-
[37]
OpenAI. Introducing GPT-5.2. https://openai.com/index/introducing-gpt-5-2/. Accessed: 2026-03-03
work page 2026
-
[38]
Boran Torun, Baykal Mehmet Uçar, and Eray Tüzün
Veli Karakaya, U. Boran Torun, Baykal Mehmet Uçar, and Eray Tüzün. Under- standing the Limits of Automated Evaluation for Code Review Bots in Practice. 3 2026. https://doi.org/10.6084/m9.figshare.31462948
-
[39]
Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Linyi Yang, Kaijie Zhu, Hao Chen, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, Wei Ye, Yue Zhang, Yi Chang, Philip S. Yu, Qiang Yang, and Xing Xie. A survey on evaluation of large language models, 2023
work page 2023
-
[40]
Kla Tantithamthavorn, Hong Yi Lin, Patanamon Thongtanunam, Wachiraphan Charoenwet, Minwoo Jeong, and Ming Wu. Hallujudge: A reference-free hallu- cination detection for context misalignment in code review automation.arXiv preprint arXiv:2601.19072, 2026
-
[41]
George Kour, Itay Nakash, Michal Shmueli-Scheuer, and Ateret Anaby Tavor. Think again! the effect of test-time compute on preferences, opinions, and beliefs of large language models. InProceedings of the 63rd Annual Meeting of the EASE ’26, June 09–12, 2026, Glasgow, UK Veli Karakaya, Utku Boran Torun, Baykal Mehmet Uçar, and Eray Tüzün Association for Co...
work page 2026
-
[42]
Davide Chicco and Giuseppe Jurman. The advantages of the matthews correlation coefficient (mcc) over f1 score and accuracy in binary classification evaluation. BMC genomics, 21(1):6, 2020
work page 2020
-
[43]
Grounded theory in software engineering research: a critical review and guidelines
Klaas-Jan Stol, Paul Ralph, and Brian Fitzgerald. Grounded theory in software engineering research: a critical review and guidelines. InProceedings of the 38th International Conference on Software Engineering, ICSE ’16, page 120–131, New York, NY, USA, 2016. Association for Computing Machinery
work page 2016
-
[44]
Eray Tüzün, Hakan Erdogmus, Maria Teresa Baldassarre, Michael Felderer, Robert Feldt, and Burak Turhan. Ground-truth deficiencies in software engineering: When codifying the past can be counterproductive.IEEE Software, 39(3):85–95, 2022
work page 2022
-
[45]
Martin Obaidi, Marc Herrmann, Kurt Schneider, and Jil Klünder. Towards trust- worthy sentiment analysis in software engineering: Dataset characteristics and tool selection. In2025 IEEE 33rd International Requirements Engineering Confer- ence Workshops (REW), pages 538–547. IEEE, 2025
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.