ITAS: A Multi-Agent Architecture for LLM-Based Intelligent Tutoring
Pith reviewed 2026-05-07 17:31 UTC · model grok-4.3
The pith
ITAS supplies a three-layer multi-agent architecture that lets LLM-based tutors run end-to-end through a full university course.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
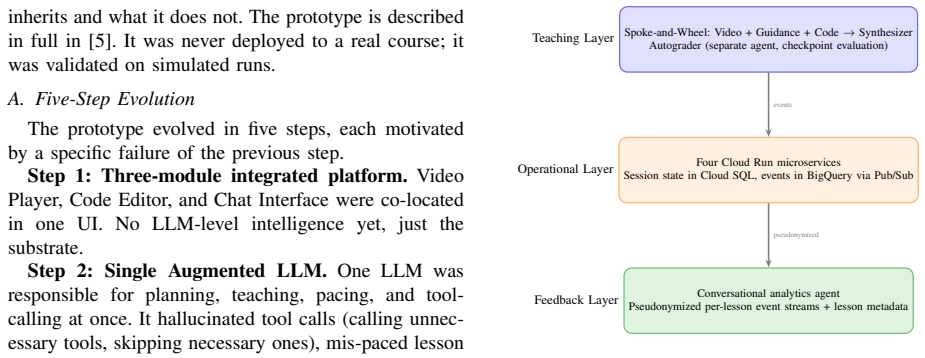
The central claim is that the described ITAS architecture, with its Spoke-and-Wheel teaching layer of three parallel specialist agents plus synthesizer and autograder, its Cloud Run operational microservices storing state in Cloud SQL and streaming events via Pub/Sub to BigQuery, and its narrow-scope conversational feedback agent over pseudonymized streams, constitutes one workable end-to-end design for an LLM-based intelligent tutoring system that can operate through an entire real course without the failures seen in an earlier prototype.
What carries the argument
The Spoke-and-Wheel teaching layer of three parallel specialist agents (Video, Code, Guidance) followed by a Synthesizer, paired with cloud microservices for state and logging and a dedicated feedback agent that summarizes per-lesson event streams.
If this is right
- Parallel specialist agents followed by a synthesizer keep chat responses inside intended task boundaries where a single consolidated agent would hallucinate.
- Streaming pseudonymized interaction events through a dedicated feedback agent lets instructors see actionable patterns without manually reviewing raw logs.
- Cloud microservices with persistent session state and event logging support continuous operation across multiple course modules without manual resets.
- An autograder that scores both correctness and approach gives students more diagnostic feedback than pass-fail checks alone.
- A narrow-scope feedback layer can surface mid-semester adjustments the instructor can act on before the course ends.
Where Pith is reading between the lines
- The same layered separation could be reused in other technical subjects where students alternate between conceptual video, code exercises, and conceptual guidance.
- Adding explicit learning-outcome metrics to the logged events would let future pilots measure whether the architecture improves student performance rather than only system uptime.
- Pseudonymized event streams might allow instructors to retain oversight while still satisfying stricter data-privacy rules that single-LLM tutors often violate.
- Scaling the operational layer to larger enrollments would test whether the microservice design continues to prevent the state and logging failures that smaller pilots never encounter.
Load-bearing premise
The fixes carried forward from the earlier prototype resolve the general deployment problems that LLM tutors encounter, and observations from a five-student pilot supply adequate evidence that the full system works end-to-end in real courses.
What would settle it
Deploying the same architecture in a later semester with more students and recording repeated task-boundary hallucinations or unlogged critical interactions would show the end-to-end claim does not hold.
Figures


read the original abstract
Large language model tutors are easy to build in a notebook and hard to run in a real course. We describe ITAS (Intelligent Teaching Assistant System), a multi-agent tutoring system that a graduate quantum computing course used for a semester at Old Dominion University. The system has three layers. The teaching layer is a Spoke-and-Wheel of three parallel specialist agents (Video, Code, Guidance) followed by a Synthesizer, plus a separate autograder that evaluates both the correctness and the approach of checkpoint submissions. The operational layer is four Cloud Run microservices with session state in Cloud SQL and interaction events streamed through Pub/Sub to BigQuery. The feedback layer is a narrow-scope conversational agent that answers instructor questions over per-lesson pseudonymized event streams, addressing what we call the Blind Instructor Problem: LLM tutors accumulate more data about students than the instructor can reach through routine channels. The architecture is a direct response to specific failures of an earlier prototype, and we describe which of those fixes carried forward and which were dropped for this iteration. We report on a pilot deployment (five students, one course, one semester) interpreted as system-behavior evidence rather than learning-outcome evidence: the teaching layer handled 334 chat turns without the task-boundary hallucinations that domain consolidation would have risked, the operational layer captured 10,628 events across five modules, and the feedback layer surfaced two findings the instructor acted on mid-semester. We do not claim the pilot generalizes. We do claim that the system as described is one workable answer to the question of what an LLM-based ITS needs to look like end-to-end to run in a real course.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents ITAS, a three-layer multi-agent architecture for LLM-based intelligent tutoring: a teaching layer with parallel specialist agents (Video, Code, Guidance) plus Synthesizer and autograder; an operational layer of Cloud Run microservices using Cloud SQL for state and Pub/Sub to BigQuery for events; and a feedback layer consisting of a narrow conversational agent that lets instructors query pseudonymized per-lesson event streams to address the Blind Instructor Problem. The system was deployed for a full semester in a graduate quantum computing course at Old Dominion University. The authors report pilot results from five students (334 chat turns with no task-boundary hallucinations, 10,628 logged events across five modules, and two mid-semester findings that the instructor acted on) and explicitly frame the contribution as one workable end-to-end design for real-course use rather than a generalizable or efficacy claim.
Significance. If the reported behaviors are accurate, the work supplies a concrete, deployed blueprint for LLM tutoring systems that directly targets specific failure modes (task-boundary hallucinations, instructor data blindness) observed in an earlier prototype. The operational details, event-streaming infrastructure, and modest scoping to system viability rather than learning outcomes constitute a practical contribution for the AIED and multi-agent systems communities. Explicit metrics and the decision to drop certain prior fixes are strengths that aid reproducibility and iteration.
minor comments (3)
- [Introduction / Architecture Description] The abstract and introduction refer to 'which of those fixes carried forward and which were dropped' from the prior prototype; a concise table or enumerated list in the architecture section would make this comparison explicit and easier to follow.
- [Operational Layer] The operational layer description would benefit from a short table enumerating the main event types that contribute to the 10,628 total; this would clarify what data the feedback agent actually sees without requiring the reader to infer from the narrative.
- [Figures] Figure captions and axis labels should be checked for consistency with the text (e.g., any diagrams of the spoke-and-wheel teaching layer or event pipeline); current presentation leaves some visual elements under-explained.
Simulated Author's Rebuttal
We thank the referee for the accurate summary of the ITAS architecture, its deployment context, and the explicit scoping of our claims to system viability rather than efficacy. The positive assessment of the operational details, event-streaming infrastructure, and decision to report concrete metrics is appreciated. We note the recommendation for minor revision and will prepare a revised manuscript accordingly.
Circularity Check
No significant circularity
full rationale
The paper is a descriptive account of an implemented three-layer multi-agent architecture (teaching agents, operational microservices, feedback agent) together with observed behaviors from a five-student pilot deployment. No equations, fitted parameters, or predictive derivations appear; claims are scoped to 'one workable answer' supported by direct reporting of 334 chat turns without hallucinations and 10,628 captured events. Self-reference to an earlier prototype is present but functions only as design motivation, not as a load-bearing justification that reduces the central claim to its own inputs. The work is self-contained as system-description evidence and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
ChatGPT for good? On opportunities and challenges of large language models for education,
E. Kasneciet al., “ChatGPT for good? On opportunities and challenges of large language models for education,”Learning and Individual Differences, vol. 103, p. 102274, 2023
work page 2023
-
[2]
LLM agents for education: Advances and applications,
Z. Chu, S. Wang, J. Xie, T. Zhu, Y . Yan, J. Ye, A. Zhong, X. Hu, J. Liang, P. S. Yu, and Q. Wen, “LLM agents for education: Advances and applications,” 2025
work page 2025
-
[3]
From prototype to class- room: An intelligent tutoring system for quantum education,
I. Elhaimeur and N. Chrisochoides, “From prototype to class- room: An intelligent tutoring system for quantum education,” 2026
work page 2026
-
[4]
Latency and cost of multi-agent intelligent tutoring at scale,
——, “Latency and cost of multi-agent intelligent tutoring at scale,” 2026
work page 2026
-
[5]
Toward personalizing quantum computing education: An evolutionary LLM-powered approach,
——, “Toward personalizing quantum computing education: An evolutionary LLM-powered approach,” inProceedings of the IEEE International Conference on Quantum Computing and Engineering (QCE), 2025
work page 2025
-
[6]
B. S. Bloom, “The 2 sigma problem: The search for methods of group instruction as effective as one-to-one tutoring,”Educa- tional Researcher, vol. 13, no. 6, pp. 4–16, 1984
work page 1984
-
[7]
K. VanLehn, “The relative effectiveness of human tutoring, intel- ligent tutoring systems, and other tutoring systems,”Educational Psychologist, vol. 46, no. 4, pp. 197–221, 2011
work page 2011
-
[8]
Cognitive tutors: Lessons learned,
J. R. Anderson, A. T. Corbett, K. R. Koedinger, and R. Pelletier, “Cognitive tutors: Lessons learned,”Journal of the Learning Sciences, vol. 4, no. 2, pp. 167–207, 1995
work page 1995
-
[9]
AutoTutor: A tutor with dialogue in natural language,
A. C. Graesser, S. Lu, G. T. Jackson, H. H. Mitchell, M. Ven- tura, A. Olney, and M. M. Louwerse, “AutoTutor: A tutor with dialogue in natural language,”Behavior Research Methods, Instruments, & Computers, vol. 36, no. 2, pp. 180–193, 2004
work page 2004
-
[10]
Effectiveness of intelligent tutoring systems: A meta-analytic review,
J. A. Kulik and J. D. Fletcher, “Effectiveness of intelligent tutoring systems: A meta-analytic review,”Review of Educational Research, vol. 86, no. 1, pp. 42–78, 2016
work page 2016
-
[11]
A. Tack and C. Piech, “The AI teacher test: Measuring the peda- gogical ability of Blender and GPT-3 in educational dialogues,” in Proceedings of the 15th International Conference on Educational Data Mining (EDM 2022), 2022, pp. 522–529
work page 2022
-
[12]
The BEA 2023 shared task on generating AI teacher responses in educational dialogues,
A. Tack, E. Kochmar, Z. Yuan, S. Bibauw, and C. Piech, “The BEA 2023 shared task on generating AI teacher responses in educational dialogues,” inProceedings of the 18th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2023). Association for Computational Linguistics, 2023, pp. 785–795
work page 2023
-
[13]
GPT-4 as a homework tutor can improve student engagement and learning outcomes,
A. Vanzo, S. Pal Chowdhury, and M. Sachan, “GPT-4 as a homework tutor can improve student engagement and learning outcomes,” 2024, randomized controlled trial in four high-school classes; reports significant gains in grammar learning outcomes and student engagement from GPT-4 interactive homework ses- sions versus traditional homework
work page 2024
-
[14]
Towards responsible development of generative AI for education: An evaluation-driven approach,
I. Jurenkaet al., “Towards responsible development of generative AI for education: An evaluation-driven approach,” 2024, learnLM tech report; demonstrates that pedagogically fine-tuned Gemini (LearnLM-Tutor) is consistently preferred over prompted Gemini baselines by educators and learners on multiple pedagogical dimensions
work page 2024
-
[15]
Practical and ethical challenges of large language models in education: A systematic scoping review,
L. Yan, L. Sha, L. Zhao, Y . Li, R. Martinez-Maldonado, G. Chen, X. Li, Y . Jin, and D. Ga ˇsevi´c, “Practical and ethical challenges of large language models in education: A systematic scoping review,”British Journal of Educational Technology, vol. 55, no. 1, pp. 90–112, 2024
work page 2024
-
[16]
ReAct: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao, “ReAct: Synergizing reasoning and acting in language models,” inProceedings of the Eleventh International Conference on Learning Representations (ICLR 2023), 2023
work page 2023
-
[17]
AutoGen: Enabling next-gen LLM applications via multi-agent conversation,
Q. Wu, G. Bansal, J. Zhang, Y . Wu, B. Li, E. Zhu, L. Jiang, X. Zhang, S. Zhang, J. Liu, A. H. Awadallah, R. W. White, D. Burger, and C. Wang, “AutoGen: Enabling next-gen LLM applications via multi-agent conversation,” inProceedings of the Third Conference on Language Modeling (COLM 2024), 2024
work page 2024
-
[18]
MetaGPT: Meta program- ming for a multi-agent collaborative framework,
S. Hong, M. Zhuge, J. Chen, X. Zheng, Y . Cheng, J. Wang, C. Zhang, Z. Wang, S. K. S. Yau, Z. Lin, L. Zhou, C. Ran, L. Xiao, C. Wu, and J. Schmidhuber, “MetaGPT: Meta program- ming for a multi-agent collaborative framework,” inProceedings of the Twelfth International Conference on Learning Represen- tations (ICLR 2024), 2024
work page 2024
-
[19]
CAMEL: Communicative agents for “mind
G. Li, H. A. A. K. Hammoud, H. Itani, D. Khizbullin, and B. Ghanem, “CAMEL: Communicative agents for “mind” explo- ration of large language model society,” inAdvances in Neural Information Processing Systems, vol. 36, 2023
work page 2023
-
[20]
Cognitive architectures for language agents,
T. R. Sumers, S. Yao, K. Narasimhan, and T. L. Griffiths, “Cognitive architectures for language agents,”Transactions on Machine Learning Research, 2024
work page 2024
-
[21]
Large language model based multi- agents: A survey of progress and challenges,
T. Guo, X. Chen, Y . Wang, R. Chang, S. Pei, N. V . Chawla, O. Wiest, and X. Zhang, “Large language model based multi- agents: A survey of progress and challenges,” inProceedings of the Thirty-Third International Joint Conference on Artificial Intelligence (IJCAI-24), 2024, pp. 8048–8057
work page 2024
-
[22]
LLM-powered multi-agent framework for goal- oriented learning in intelligent tutoring system,
T. Wang, Y . Zhan, J. Lian, Z. Hu, N. J. Yuan, Q. Zhang, X. Xie, and H. Xiong, “LLM-powered multi-agent framework for goal- oriented learning in intelligent tutoring system,” inProceedings of The Web Conference 2025 (Industry Track), 2025
work page 2025
-
[23]
Simulating classroom education with LLM- empowered agents,
Z. Zhang, D. Zhang-Li, J. Yu, L. Gong, J. Zhou, Z. Liu, L. Hou, and J. Li, “Simulating classroom education with LLM- empowered agents,” inProceedings of the 2025 Annual Confer- ence of the Nations of the Americas Chapter of the ACL (NAACL 2025), 2025
work page 2025
-
[24]
Towards a science of scaling agent systems,
Y . Kim, K. Gu, C. Park, C. Park, S. Schmidgall, A. A. Heydari, Y . Yan, Z. Zhang, Y . Zhuang, M. Malhotra, P. P. Liang, H. W. Park, Y . Yang, X. Xu, Y . Du, S. Patel, T. Althoff, D. McDuff, and X. Liu, “Towards a science of scaling agent systems,” 2025, first quantitative scaling principles for LLM-based agent systems. Evaluates five canonical topologies...
work page 2025
-
[25]
How video production affects student engagement: An empirical study of MOOC videos,
P. J. Guo, J. Kim, and R. Rubin, “How video production affects student engagement: An empirical study of MOOC videos,” in Proceedings of the First ACM Conference on Learning @ Scale (L@S ’14), 2014, pp. 41–50
work page 2014
-
[26]
P. Blikstein, M. Worsley, C. Piech, M. Sahami, S. Cooper, and D. Koller, “Programming pluralism: Using learning analytics to detect patterns in the learning of computer programming,” Journal of the Learning Sciences, vol. 23, no. 4, pp. 561–599, 2014
work page 2014
-
[27]
P. Blikstein and M. Worsley, “Multimodal learning analytics and education data mining: Using computational technologies to measure complex learning tasks,”Journal of Learning Analytics, vol. 3, no. 2, pp. 220–238, 2016
work page 2016
-
[28]
Deconstructing disengagement: Analyzing learner subpopulations in massive open online courses,
R. F. Kizilcec, C. Piech, and E. Schneider, “Deconstructing disengagement: Analyzing learner subpopulations in massive open online courses,” inProceedings of the Third International Conference on Learning Analytics and Knowledge (LAK ’13), 2013, pp. 170–179
work page 2013
-
[29]
Family educational rights and privacy act (FERPA),
U.S. Congress, “Family educational rights and privacy act (FERPA),” 20 U.S.C. § 1232g; 34 CFR Part 99, 1974
work page 1974
-
[30]
Google, “Agent development kit (ADK),” https://google.github. io/adk-docs/, 2025, open-source framework for building, evalu- ating, and deploying multi-agent LLM applications. Used in ITAS for the Spoke-and-Wheel teaching pipeline
work page 2025
-
[31]
M. Q. Patton,Qualitative Research and Evaluation Methods, 3rd ed. Thousand Oaks, CA: Sage Publications, 2002, foun- dational text on qualitative methodology; argues that validity and meaningfulness in qualitative inquiry depend on information- richness of cases and analytical capabilities of the researcher, not sample size
work page 2002
-
[32]
L. Huang, W. Yu, W. Ma, W. Zhong, Z. Feng, H. Wang, Q. Chen, W. Peng, X. Feng, B. Qin, and T. Liu, “A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions,”ACM Transactions on Information Systems, 2024
work page 2024
-
[33]
MonarchSphere: AI incubator powered by Google Cloud,
Old Dominion University, “MonarchSphere: AI incubator powered by Google Cloud,” https://www.odu.edu/ forward-focused-transformation/monarchsphere, 2025
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.