On the Trainability of Masked Diffusion Language Models via Blockwise Locality
Pith reviewed 2026-05-08 04:16 UTC · model grok-4.3
The pith
Standard masked diffusion language models suffer training instabilities on ordered generation tasks that blockwise locality models can mitigate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
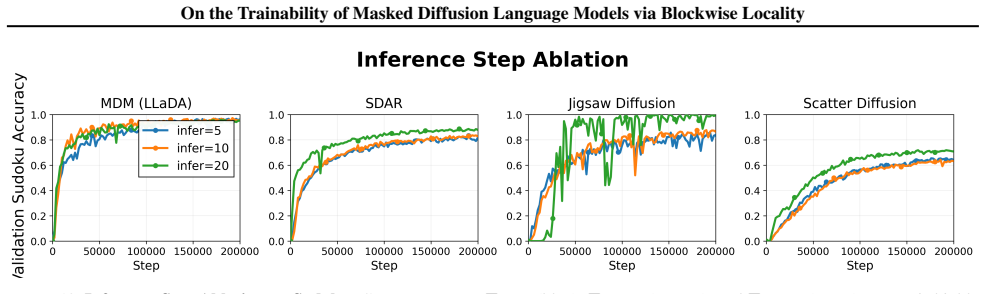
Standard random-masking MDMs fail to reliably learn linear regression, exhibit high variance training dynamics on graph path-finding, while outperforming AR-LLMs on Sudoku. The proposed locality-aware blockwise models Jigsaw and Scatter enforce autoregressive locality within blocks while preserving iterative refinement at the block level. Jigsaw matches AR-LLM stability on linear regression and remains strong on Sudoku, while Scatter retains diffusion's planning advantage on path-finding. This indicates that standard random-masking MDMs, even with blockwise variants, may be a suboptimal instantiation of diffusion LMs for ordered generation.
What carries the argument
Blockwise locality enforcement, which injects left-to-right autoregressive inductive bias inside blocks while allowing iterative refinement across blocks.
If this is right
- Jigsaw achieves training stability comparable to autoregressive LLMs on in-context linear regression.
- Scatter preserves the iterative planning benefit of diffusion models on graph path-finding.
- Task performance depends on the specific form of locality bias introduced.
- Random masking alone may not suffice for reliable ordered generation in diffusion language models.
- Modifications that respect sequence order can stabilize optimization without eliminating iterative refinement.
Where Pith is reading between the lines
- Hybrid designs that combine autoregressive order within blocks and diffusion refinement across blocks could generalize to full-scale language modeling.
- The observed task-specific trade-offs imply that different masking strategies may be optimal for different kinds of structured problems.
- If instabilities scale with model size, entirely new diffusion mechanisms beyond masking may become necessary.
- The same locality principle could be tested in other iterative generative models to check whether order bias improves convergence more broadly.
Load-bearing premise
The three controlled tasks capture the essential difficulties of structured generation that appear in broader language modeling.
What would settle it
A standard random-masking MDM achieving consistent low-error convergence across repeated runs on the in-context linear regression task would indicate that the reported training instabilities are not inherent to the approach.
Figures
















read the original abstract
Masked diffusion language models (MDMs) have recently emerged as a promising alternative to standard autoregressive large language models (AR-LLMs), yet their optimization can be substantially less stable. We study blockwise MDMs and compare them with AR-LLMs on three controlled tasks that stress different aspects of structured generation: in-context linear regression, graph path-finding, and Sudoku solving. We find that standard random-masking MDMs fail to reliably learn linear regression, exhibit high variance training dynamics on graph path-finding, while outperforming AR-LLMs on Sudoku. To mitigate these instabilities, we propose two locality aware blockwise models, namely Jigsaw and Scatter, that inject left-to-right inductive bias by enforcing autoregressive locality within blocks while preserving iterative refinement at the block level. Empirically, Jigsaw matches AR-LLM stability on linear regression and remains strong on Sudoku, while Scatter retains diffusion's planning advantage on path-finding. Our results indicate that standard random-masking MDMs, even with blockwise variants, may be a suboptimal instantiation of diffusion LMs for ordered generation, motivating models beyond random masking.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript examines the trainability and optimization stability of masked diffusion language models (MDMs) relative to autoregressive LLMs (AR-LLMs) using three controlled synthetic tasks that probe structured generation: in-context linear regression, graph path-finding, and Sudoku solving. It reports that standard random-masking MDMs fail to reliably learn linear regression, show high-variance training dynamics on path-finding, and outperform AR-LLMs on Sudoku. To address instabilities, the authors introduce two blockwise locality-aware variants (Jigsaw and Scatter) that enforce autoregressive left-to-right bias within blocks while preserving iterative block-level refinement. Jigsaw is shown to match AR-LLM stability on regression and perform strongly on Sudoku, while Scatter retains diffusion advantages on path-finding. The work concludes that random-masking MDMs (even blockwise) may be suboptimal for ordered generation, motivating diffusion LMs beyond random masking.
Significance. If the empirical results prove robust, the paper makes a useful contribution by isolating specific failure modes of random masking in diffusion LMs on ordered tasks and by proposing concrete blockwise locality mechanisms (Jigsaw, Scatter) that inject useful inductive bias without fully abandoning iterative refinement. The controlled tasks enable clear head-to-head comparisons that highlight trade-offs between stability and planning capacity. This could inform the design of future non-autoregressive generative models, especially where partial observability or global constraints matter. The absence of machine-checked proofs or parameter-free derivations is offset by the direct empirical motivation for architectural variants.
major comments (2)
- [Abstract and empirical evaluation section] Abstract and empirical evaluation section: the abstract states specific outcomes (failure to learn linear regression, high-variance path-finding dynamics, outperformance on Sudoku) yet supplies no details on experimental setup, statistical tests, baselines, variance measures, or number of runs. This is load-bearing for the central claim of suboptimality, because without these the reported instabilities cannot be verified as reliable rather than artifacts of training protocol or random seeds.
- [Empirical evaluation and discussion] Empirical evaluation and discussion: the motivation to move beyond random masking rests on the three tasks being representative of ordered-generation challenges. These tasks are narrow, fully deterministic, low-dimensional, and impose rigid global constraints (exact linear fit, shortest-path planning on small graphs, unique Sudoku solutions). The manuscript does not test or discuss whether the same instabilities appear on less rigid ordered problems such as long-form code generation or multi-step reasoning with partial observability; if they do not, the claimed general limitation of random-masking MDMs is weakened.
minor comments (2)
- [Model description] Clarify the precise definitions and implementation details of the Jigsaw and Scatter blockwise mechanisms, including how locality is enforced within blocks and how this differs from standard blockwise masking.
- [Figures] Ensure all figures reporting training curves include error bands or multiple runs to support claims of 'high variance' versus 'stable' behavior.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address the two major comments below by committing to concrete revisions that strengthen verifiability while preserving the paper's focus on controlled, isolating tasks.
read point-by-point responses
-
Referee: [Abstract and empirical evaluation section] Abstract and empirical evaluation section: the abstract states specific outcomes (failure to learn linear regression, high-variance path-finding dynamics, outperformance on Sudoku) yet supplies no details on experimental setup, statistical tests, baselines, variance measures, or number of runs. This is load-bearing for the central claim of suboptimality, because without these the reported instabilities cannot be verified as reliable rather than artifacts of training protocol or random seeds.
Authors: We agree that the current abstract and empirical section lack sufficient detail for independent verification. In the revised manuscript we will (i) expand the abstract to briefly note the number of runs and variance reporting, (ii) add a dedicated experimental-setup subsection that specifies training protocol, optimizer settings, number of random seeds (five), and how variance is measured (mean ± std), (iii) include explicit baseline descriptions and any statistical comparisons used. These additions will make the reported instabilities reproducible and will not alter the central claims. revision: yes
-
Referee: [Empirical evaluation and discussion] Empirical evaluation and discussion: the motivation to move beyond random masking rests on the three tasks being representative of ordered-generation challenges. These tasks are narrow, fully deterministic, low-dimensional, and impose rigid global constraints (exact linear fit, shortest-path planning on small graphs, unique Sudoku solutions). The manuscript does not test or discuss whether the same instabilities appear on less rigid ordered problems such as long-form code generation or multi-step reasoning with partial observability; if they do not, the claimed general limitation of random-masking MDMs is weakened.
Authors: We chose the three tasks precisely because their rigid constraints allow us to isolate trainability failures without confounding factors from large-scale data or ambiguous objectives. The linear-regression task tests exact in-context fitting, path-finding tests planning under global constraints, and Sudoku tests satisfaction of unique global solutions; together they expose distinct instability modes that random masking exhibits. We acknowledge that broader domains such as code generation or multi-step reasoning would be valuable extensions. In the revision we will add an explicit limitations paragraph that (a) states the tasks are synthetic and controlled, (b) explains why these particular constraints are diagnostic for ordered generation, and (c) notes that generalization to less rigid settings remains future work. No new large-scale experiments are added, as they fall outside the paper's scope of controlled comparison. revision: partial
Circularity Check
No circularity: purely empirical comparisons with no derivations or self-referential reductions
full rationale
The paper is an empirical study that trains and evaluates standard random-masking MDMs, blockwise variants, Jigsaw, Scatter, and AR-LLMs on three controlled synthetic tasks (in-context linear regression, graph path-finding, Sudoku). Central claims rest on observed training stability, variance, and task performance differences rather than any derivation chain, fitted parameters renamed as predictions, or load-bearing self-citations. No equations, ansatzes, uniqueness theorems, or prior-author results are invoked to force the conclusions; the motivation for models beyond random masking follows directly from the reported experimental outcomes.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Gemini: A Family of Highly Capable Multimodal Models
URL https://openreview.net/forum ?id=sMyXP8Tanm. Radford, A., Narasimhan, K., Salimans, T., Sutskever, I., et al. Improving language understanding by generative pre-training.OpenAI blog, 2018. Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., Sutskever, I., et al. Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019. Raffel, C...
work page internal anchor Pith review arXiv 2018
-
[2]
D iffusion BERT : Improving generative masked language models with diffusion models
Association for Computational Linguistics, 2023. doi: 10.18653/v1/2023.acl-long.248. URL https: //aclanthology.org/2023.acl-long.248. 11 On the Trainability of Masked Diffusion Language Models via Blockwise Locality A. Model Architecture and Training Configurations To ensure a rigorous comparison, we standardize the underlying neural network parameters (e...
-
[3]
Profiling Strategy.We measure the train step flops using the fvcore library [or specify your tool] at Step 10. This accounts for the specific architectural implementation (e.g., attention mechanisms and linear layers). We ensure that sequence lengths and batch sizes are identical across all compared paradigms for a specific task
-
[4]
The Forward-Backward Decomposition.Total training compute is modeled based on the standard Forward-Backward relationship. Assuming the backward pass consumes approximately twice the compute of the forward pass, we derive the 23 On the Trainability of Masked Diffusion Language Models via Blockwise Locality foundational unit forward compute (F) from the tot...
-
[5]
(Assuming KV-caching is enabled)
Inference Complexity (Relative Analysis).While A(t) in Figure 1 focuses on training efficiency, we provide the following model for inference to highlight the total deployment cost: • AR Models:C inf, AR ≈ F ×n respond. (Assuming KV-caching is enabled). • Diffusion Models:C inf, Diff =F ×sampling steps. D.3. Target performance thresholds (τ) The thresholds...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.