Recognition: unknown
Toward a Science of Intent: Closure Gaps and Delegation Envelopes for Open-World AI Agents
Pith reviewed 2026-05-08 03:19 UTC · model grok-4.3
The pith
Open-world AI agents require intent compilation to turn partial human purposes into inspectable artifacts that bind execution, rather than relying only on more inference-time search.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
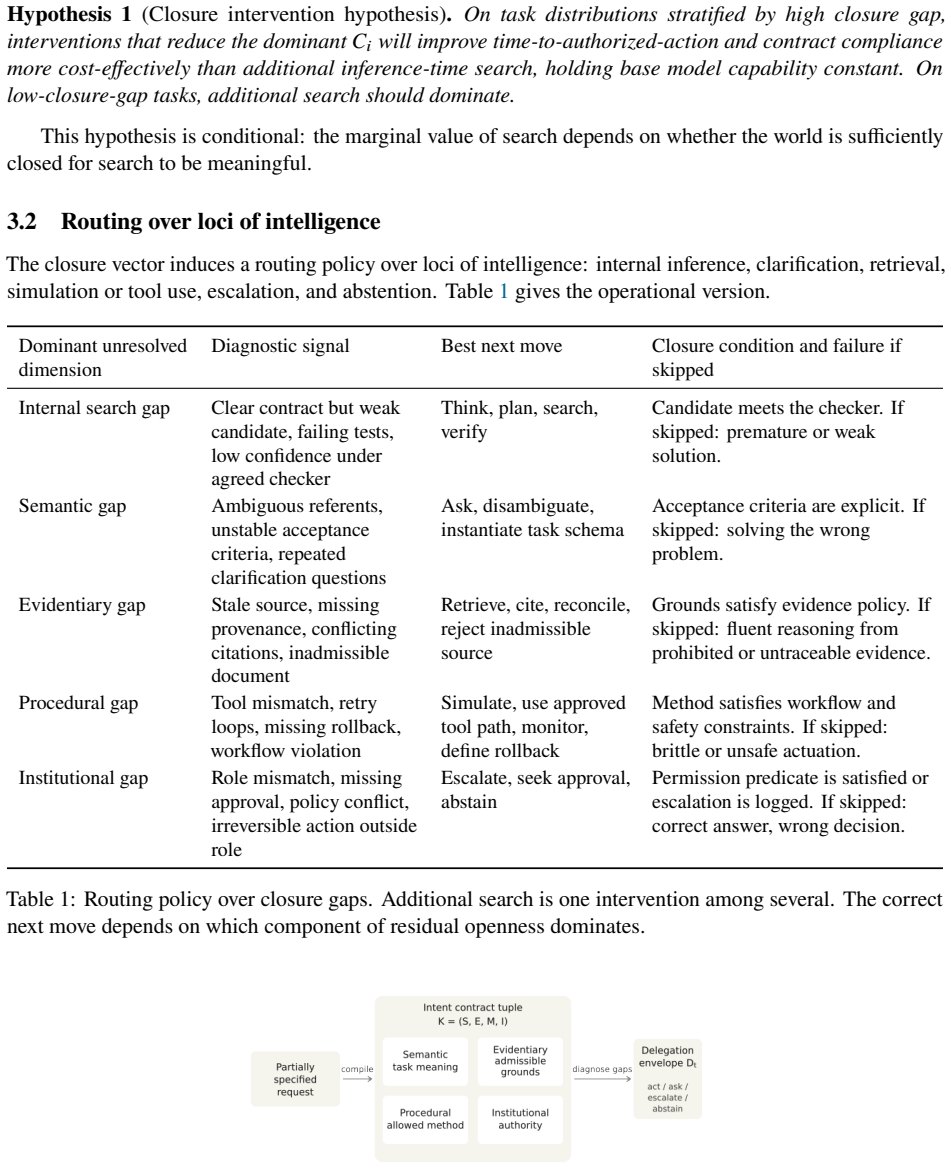
In closed worlds a checker is largely given; in open worlds verification is distributed, so the residual openness can be formalized as a closure-gap vector. Intent compilation converts partial human purpose into inspectable artifacts that bind execution, while delegation envelopes mark pre-authorized regions of action space. These mechanisms let us separate misclosure from undersearch and test whether targeted closure steps outperform additional inference-time search.
What carries the argument
Intent compilation, the transformation of partially specified human purpose into inspectable artifacts that bind execution, supported by the closure-gap vector that quantifies residual openness and delegation envelopes that pre-authorize regions of action space.
If this is right
- Verification in open-world settings must address multiple distributed dimensions rather than assuming a fixed checker.
- Delegation envelopes can limit agent behavior to pre-authorized regions before execution begins.
- Benchmark metrics can reveal when closing specific gaps outperforms further search.
- Misclosure and undersearch are distinct failure modes that require different remedies.
- Learned runtimes and test-time search alone do not resolve the deployment difficulties of open institutions.
Where Pith is reading between the lines
- The framework suggests new evaluation protocols that track closure gaps separately from raw capability.
- It could be tested by applying delegation envelopes to existing agent benchmarks and measuring changes in verifiable outcomes.
- Extensions might examine how closure interventions interact with model scale in specific institutional settings such as planning or legal review.
Load-bearing premise
That verification in open worlds decomposes usefully into semantic, evidentiary, procedural, and institutional dimensions and that closure interventions can be benchmarked against additional search without first specifying how the vector components are quantified or combined.
What would settle it
A controlled experiment on an open-world task where every measured closure intervention produces strictly smaller error reduction than simply allocating the same compute budget to extra inference-time search.
Figures
read the original abstract
Recent work has framed intelligence in verifiable tasks as reducing time-to-solution through learned structure and test-time search, while systems work has explored learned runtimes in which computation, memory and I/O migrate into model state. These perspectives do not explain why capable models remain difficult to deploy in open institutions. We propose intent compilation: the transformation of partially specified human purpose into inspectable artifacts that bind execution. The relevant deployment distinction is closed-world solver versus open-world agent. In closed worlds, a checker is largely given; in open worlds, verification is distributed across semantic, evidentiary, procedural and institutional dimensions. Weformalize this residual openness as a closure-gap vector, define delegation envelopes as pre-authorized regions of action space, distinguish misclosure from undersearch, and outline benchmark metrics for testing when closure interventions outperform additional inference-time search.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes intent compilation as the transformation of partially specified human purposes into inspectable artifacts that bind AI agent execution. It distinguishes closed-world solvers (where a checker is largely given) from open-world agents (where verification is distributed across semantic, evidentiary, procedural, and institutional dimensions), formalizes residual openness as a closure-gap vector, defines delegation envelopes as pre-authorized regions of action space, distinguishes misclosure from undersearch, and outlines benchmark metrics for determining when closure interventions outperform additional inference-time search.
Significance. If the closure-gap vector and associated benchmarks could be made operational with explicit quantification and aggregation rules, the framework might offer a structured approach to managing verification gaps in open-world AI deployments, potentially informing safer delegation practices. The conceptual distinction between misclosure and undersearch is a potentially useful starting point, but without concrete mappings or testable content the contribution remains at the level of definitional proposals.
major comments (1)
- [Abstract] Abstract: The closure-gap vector is defined with four dimensions (semantic, evidentiary, procedural, institutional) and the text promises benchmark metrics for comparing closure interventions to inference-time search, yet no mapping from world states to vector component values is supplied, nor is any aggregation or decision rule given for combining components into a threshold or loss. This renders the central claim that such interventions can outperform additional search non-operational and untestable.
minor comments (1)
- [Abstract] Abstract: Typo in 'Weformalize' (should be 'We formalize').
Simulated Author's Rebuttal
We thank the referee for their careful reading and for identifying the need for greater operational detail in our framework. We address the single major comment below and have prepared revisions that add concrete illustrations without overstating the current scope of the work.
read point-by-point responses
-
Referee: [Abstract] Abstract: The closure-gap vector is defined with four dimensions (semantic, evidentiary, procedural, institutional) and the text promises benchmark metrics for comparing closure interventions to inference-time search, yet no mapping from world states to vector component values is supplied, nor is any aggregation or decision rule given for combining components into a threshold or loss. This renders the central claim that such interventions can outperform additional search non-operational and untestable.
Authors: The referee is correct that the submitted manuscript supplies only a high-level definition of the four-dimensional closure-gap vector and an outline of benchmark metrics rather than explicit state-to-component mappings or an aggregation function. The paper's primary contribution is the conceptual separation of misclosure from undersearch and the introduction of delegation envelopes; the metrics are presented as a direction for future empirical tests rather than a fully specified procedure. To respond, the revised version will add a dedicated subsection containing illustrative mappings (for example, semantic gap measured by the number of unresolved goal predicates, evidentiary gap by the fraction of required evidence that remains unverified) together with a simple aggregation rule (the Euclidean norm of the normalized vector) and a threshold-based decision criterion for when a closure intervention is preferred to extra search. These additions will make the comparison testable in principle while preserving the paper's focus on definitional foundations. revision: partial
Circularity Check
No circularity: concepts introduced by explicit definition without self-referential reductions or fitted predictions
full rationale
The paper proposes new terminology including intent compilation, the closure-gap vector (with semantic/evidentiary/procedural/institutional components), delegation envelopes, and the distinction between misclosure and undersearch. These are presented as formalizations and definitions rather than derivations from prior equations, fitted parameters, or self-citations. No load-bearing step claims a prediction or result that reduces by construction to its own inputs, and the benchmark metrics are outlined as proposals without quantitative instantiation or circular equivalence. The derivation chain remains self-contained as a conceptual framework.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Intelligence in verifiable tasks reduces time-to-solution through learned structure and test-time search.
- domain assumption Systems work has explored learned runtimes in which computation, memory and I/O migrate into model state.
invented entities (3)
-
intent compilation
no independent evidence
-
closure-gap vector
no independent evidence
-
delegation envelopes
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Herbert A. Simon. A behavioral model of rational choice.Quarterly Journal of Economics, 69(1): 99–118, 1955
1955
-
[2]
Using anytime algorithms in intelligent systems.AI Magazine, 17(3):73–83, 1996
Shlomo Zilberstein. Using anytime algorithms in intelligent systems.AI Magazine, 17(3):73–83, 1996. 12
1996
-
[3]
Lewis, Andrew Howes, and Satinder Singh
Richard L. Lewis, Andrew Howes, and Satinder Singh. Computational rationality: Linking mechanism and behavior through bounded utility maximization.Topics in Cognitive Science, 6(2):279–311, 2014
2014
-
[4]
AI Agents as Universal Task Solvers: It’s All About Time,
Alessandro Achille and Stefano Soatto. Ai agents as universal task solvers: It’s all about time.arXiv preprint arXiv:2510.12066, 2025. doi: 10.48550/arXiv.2510.12066
-
[5]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute optimally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314, 2024
work page internal anchor Pith review arXiv 2024
-
[6]
David Ha and J¨ urgen Schmidhuber. World models.arXiv preprint arXiv:1803.10122, 2018
work page internal anchor Pith review arXiv 2018
-
[7]
Mingchen Zhuge, Changsheng Zhao, Haozhe Liu, Zijian Zhou, Shuming Liu, Wenyi Wang, Ernie Chang, Gael Le Lan, Junjie Fei, Wenxuan Zhang, Yasheng Sun, Zhipeng Cai, Zechun Liu, Yunyang Xiong, Yining Yang, Yuandong Tian, Yangyang Shi, Vikas Chandra, and J¨ urgen Schmidhuber. Neural computers.arXiv preprint arXiv:2604.06425, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse control tasks through world models.Nature, 640:647–653, 2025. doi: 10.1038/s41586-025-08744-2
-
[9]
Wiley, 2009
Axel van Lamsweerde.Requirements Engineering: From System Goals to UML Models to Software Specifications. Wiley, 2009
2009
-
[10]
Addison-Wesley, 2001
Michael Jackson.Problem Frames: Analysing and Structuring Software Development Problems. Addison-Wesley, 2001
2001
-
[11]
Retrieval-augmented generation for knowledge-intensive nlp tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K¨ uttler, Mike Lewis, Wen-tau Yih, Tim Rockt¨aschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive nlp tasks. InAdvances in Neural Information Processing Systems, 2020
2020
-
[12]
The rationale of prov.Journal of Web Semantics, 35:235–257, 2015
Luc Moreau, Paul Groth, James Cheney, Timothy Lebo, and Simon Miles. The rationale of prov.Journal of Web Semantics, 35:235–257, 2015
2015
-
[13]
Sigstore: Software signing for everybody
Zachary Newman, John Speed Meyers, and Santiago Torres-Arias. Sigstore: Software signing for everybody. InACM Conference on Computer and Communications Security, 2022
2022
-
[14]
Petri nets: Properties, analysis and applications.Proceedings of the IEEE, 77(4):541–580, 1989
Tadao Murata. Petri nets: Properties, analysis and applications.Proceedings of the IEEE, 77(4):541–580, 1989
1989
-
[15]
Wil M. P. van der Aalst and Arthur H. M. ter Hofstede. Yawl: Yet another workflow language. Information Systems, 30(4):245–275, 2005
2005
-
[16]
A brief account of runtime verification.Journal of Logic and Algebraic Programming, 78(5):293–303, 2009
Martin Leucker and Christian Schallhart. A brief account of runtime verification.Journal of Logic and Algebraic Programming, 78(5):293–303, 2009
2009
-
[17]
Introduction to runtime verification
Ezio Bartocci, Yli`es Falcone, Adrian Francalanza, and Giles Reger. Introduction to runtime verification. InLectures on Runtime Verification, pages 1–33. Springer, 2018
2018
-
[18]
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. Swe-agent: Agent-computer interfaces enable automated software engineering.arXiv preprint arXiv:2405.15793, 2024. 13
work page internal anchor Pith review arXiv 2024
-
[19]
OpenHands: An Open Platform for AI Software Developers as Generalist Agents
Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, et al. Openhands: An open platform for ai software developers as generalist agents.arXiv preprint arXiv:2407.16741, 2024
work page internal anchor Pith review arXiv 2024
-
[20]
Sandhu, Edward J
Ravi S. Sandhu, Edward J. Coyne, Hal L. Feinstein, and Charles E. Youman. Role-based access control models.IEEE Computer, 29(2):38–47, 1996
1996
-
[21]
Dennis and Earl C
Jack B. Dennis and Earl C. Van Horn. Programming semantics for multiprogrammed computations. Communications of the ACM, 9(3):143–155, 1966
1966
-
[22]
Miller.Robust Composition: Towards a Unified Approach to Access Control and Concurrency Control
Mark S. Miller.Robust Composition: Towards a Unified Approach to Access Control and Concurrency Control. PhD thesis, Johns Hopkins University, 2006
2006
-
[23]
extensible access control markup language (xacml) version 3.0
OASIS. extensible access control markup language (xacml) version 3.0. Technical report, OASIS Standard, 2013
2013
-
[24]
Hinrichs
Tim Sandall and Timothy L. Hinrichs. Open policy agent: Policy-based control for cloud native environments. Technical report, Cloud Native Computing Foundation, 2021
2021
-
[25]
Cedar: A new policy language
Amazon Web Services. Cedar: A new policy language. Technical report, Amazon Web Services, 2023
2023
-
[26]
Kroll, Joanna Huey, Solon Barocas, Edward W
Joshua A. Kroll, Joanna Huey, Solon Barocas, Edward W. Felten, Joel R. Reidenberg, David G. Robinson, and Harlan Yu. Accountable algorithms.University of Pennsylvania Law Review, 165:633–705, 2017
2017
-
[27]
Hadfield.Rules for a Flat World: Why Humans Invented Law and How to Reinvent It for a Complex Global Economy
Gillian K. Hadfield.Rules for a Flat World: Why Humans Invented Law and How to Reinvent It for a Complex Global Economy. Oxford University Press, 2017
2017
-
[28]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues? InInternational Conference on Learning Representations, 2024
2024
-
[29]
$\tau$-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. 𝜏-bench: A benchmark for tool-agent-user interaction in real-world domains.arXiv preprint arXiv:2406.12045, 2024
work page internal anchor Pith review arXiv 2024
-
[30]
GAIA: a benchmark for General AI Assistants
Gr´egoire Mialon, Cl´ementine Fourrier, Craig Swift, Thomas Wolf, Yann LeCun, and Thomas Scialom. Gaia: A benchmark for general ai assistants.arXiv preprint arXiv:2311.12983, 2023
work page internal anchor Pith review arXiv 2023
-
[31]
AgentBench: Evaluating LLMs as Agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, et al. Agentbench: Evaluating llms as agents.arXiv preprint arXiv:2308.03688, 2023
work page internal anchor Pith review arXiv 2023
-
[32]
Holistic evaluation of language models
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, et al. Holistic evaluation of language models. Transactions on Machine Learning Research, 2023
2023
-
[33]
Zoom in: An introduction to circuits.Distill, 2020
Chris Olah, Nick Cammarata, Ludwig Schubert, Gabriel Goh, Michael Petrov, and Shan Carter. Zoom in: An introduction to circuits.Distill, 2020
2020
-
[34]
Toy models of superposition
Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds, Robert Lasenby, Dawn Drain, Carol Chen, et al. Toy models of superposition. Transformer Circuits Thread, 2022
2022
-
[35]
George C. Necula. Proof-carrying code. InACM SIGPLAN Symposium on Principles of Programming Languages, pages 106–119, 1997. 14
1997
-
[36]
Miles Brundage, Shahar Avin, Jack Wang, Haydn Belfield, Gretchen Krueger, Gillian Hadfield, et al. Toward trustworthy ai development: Mechanisms for supporting verifiable claims.arXiv preprint arXiv:2004.07213, 2020
-
[37]
Github copilot workspace: Ai-native developer environment
GitHub. Github copilot workspace: Ai-native developer environment. Product announcement, 2024
2024
-
[38]
Aider: Ai pair programming in your terminal
Paul Gauthier. Aider: Ai pair programming in your terminal. Software documentation, 2024
2024
-
[39]
Introducing devin, the first ai software engineer
Cognition AI. Introducing devin, the first ai software engineer. Product announcement, 2024
2024
-
[40]
Metagpt: Meta programming for a multi-agent collaborative framework
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, et al. Metagpt: Meta programming for a multi-agent collaborative framework. InInternational Conference on Learning Representations, 2024
2024
-
[41]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations, 2023
2023
-
[42]
Reflexion: Language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning. InAdvances in Neural Information Processing Systems, 2023
2023
-
[43]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, et al. Autogen: Enabling next-gen llm applications via multi-agent conversation.arXiv preprint arXiv:2308.08155, 2023
work page internal anchor Pith review arXiv 2023
-
[44]
Langchain: Building applications with llms through composability
Harrison Chase. Langchain: Building applications with llms through composability. Software documentation, 2022
2022
-
[45]
Maximiliano Armesto and Christophe Kolb. Orchestrating human-ai software delivery: A retrospective longitudinal field study of three software modernization programs.arXiv preprint arXiv:2603.20028, 2026
-
[46]
Maximiliano Armesto and Christophe Kolb. Coupled control, structured memory, and verifiable action in agentic ai (scrat – stochastic control with retrieval and auditable trajectories): A comparative perspective from squirrel locomotion and scatter-hoarding.arXiv preprint arXiv:2604.03201, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[47]
Jonathan Rademacher. Standing algebra Σ𝑅: A closure-theoretic operator for constraining domination and preserving autonomy. Zenodo working paper, Version 6.5, April 2026. URL https://doi.org/ 10.5281/zenodo.19656146. 15
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.