Recognition: unknown
Why Does Reinforcement Learning Generalize? A Feature-Level Mechanistic Study of Post-Training in Large Language Models
Pith reviewed 2026-05-08 03:29 UTC · model grok-4.3
The pith
Reinforcement learning post-training improves LLM generalization by inducing a compact set of task-agnostic features that mediate performance on out-of-domain tasks, unlike the many specialized features introduced by supervised fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
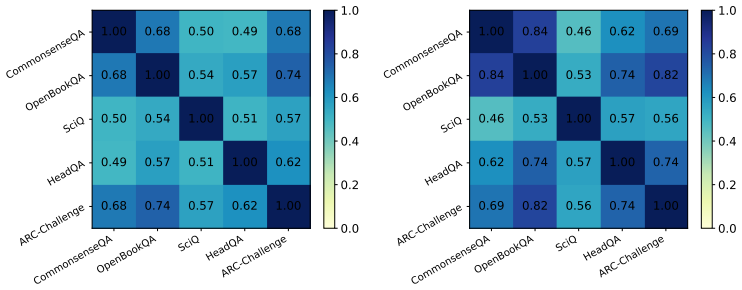
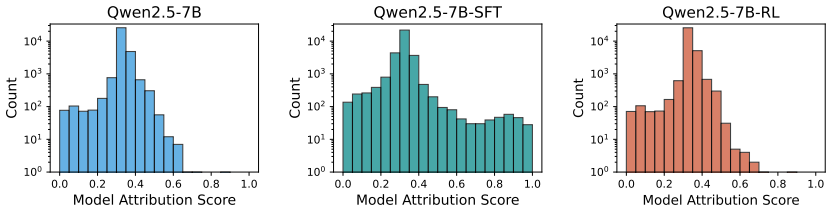
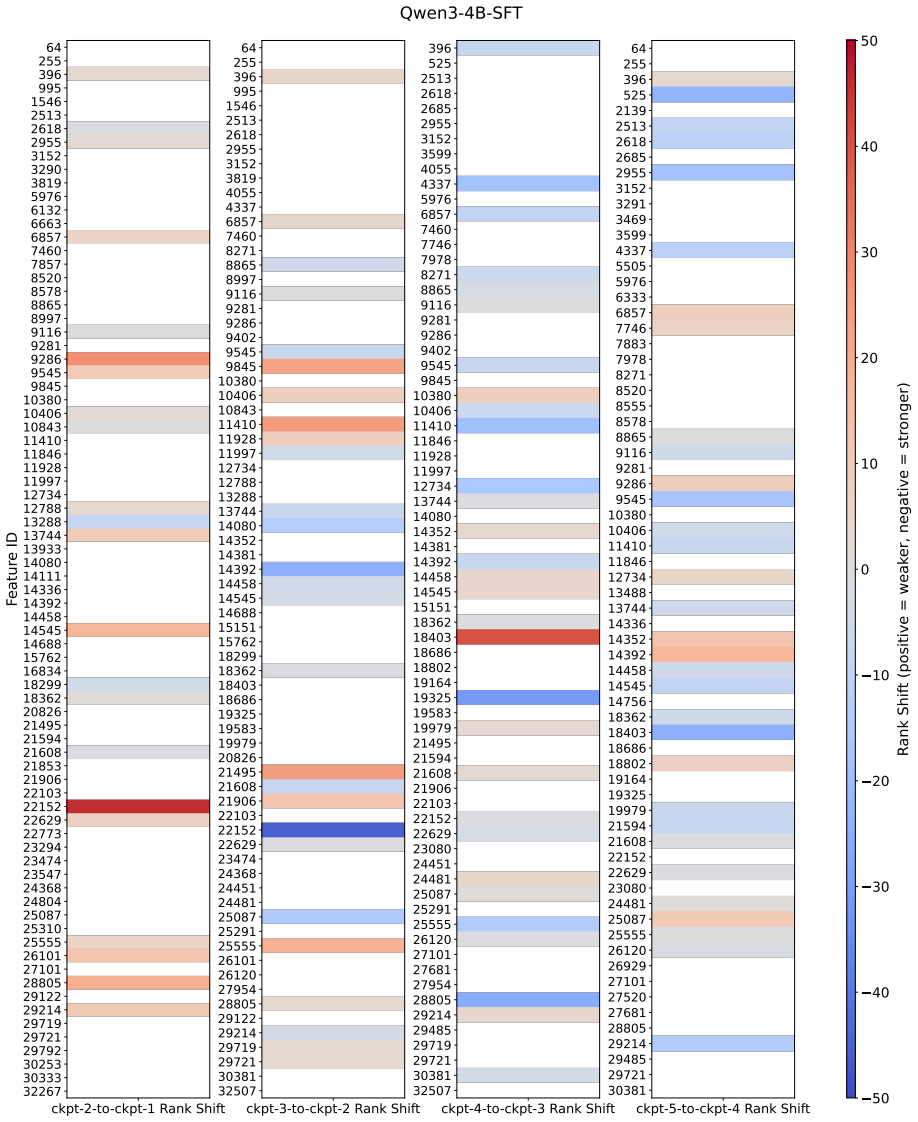
RL induces more restrained and continually evolving feature changes that largely preserve base models' representations, in contrast to SFT which rapidly introduces many highly specialized features that stabilize early in training. On samples where RL succeeds but the base model fails, a compact, task-agnostic set of features directly mediates generalization across diverse tasks, and feature-level interventions establish their causal role by showing that disabling them degrades RL performance while amplifying them improves base-model performance.
What carries the argument
Alignment of internal activations from RL and SFT models into a shared feature space, followed by identification of a compact task-agnostic feature set and targeted interventions that disable or amplify those features to test effects on generalization.
If this is right
- RL post-training succeeds by making limited, ongoing adjustments rather than overwriting base representations with specialized ones.
- A small number of features can be edited to control whether a model generalizes on reasoning tasks it previously failed.
- The same features appear to operate across multiple distinct tasks, suggesting a shared mechanism for RL-driven generalization.
- SFT's early stabilization of many narrow features explains why it often reduces capabilities outside the fine-tuning distribution.
Where Pith is reading between the lines
- Training procedures could be designed to target induction of this small feature set directly instead of relying on full RL.
- The contrast between RL and SFT may extend to other post-training methods such as preference optimization or continued pre-training.
- If these features can be located early in training, models might be monitored or steered toward generalization without full RL runs.
Load-bearing premise
Aligning activations from different models in one feature space captures the true mechanistic differences without artifacts from the alignment procedure or the choice of how features are extracted.
What would settle it
An experiment in which the identified features are disabled inside a trained RL model yet its generalization accuracy on held-out tasks stays essentially unchanged, or in which amplifying the same features inside a base model produces no measurable gain.
Figures









read the original abstract
Reinforcement learning (RL)-based post-training often improves the reasoning performance of large language models (LLMs) beyond the training domain, while supervised fine-tuning (SFT) frequently leads to general capabilities forgetting. However, the mechanisms underlying this contrast remain unclear. To bridge this gap, we present a feature-level mechanistic analysis methodology to probe RL generalization using a controlled experimental setup, where RL- and SFT-tuned models are trained from the same base model on identical data. Leveraging our interpretability framework, we align internal activations across models within a shared feature space and analyze how features evolve during post-training. We find that SFT rapidly introduces many highly specialized features that stabilize early in training, whereas RL induces more restrained and continually evolving feature changes that largely preserve base models' representations. Focusing on samples where RL succeeds but the base model fails, we identify a compact, task-agnostic set of features that directly mediate generalization across diverse tasks. Feature-level interventions confirm their causal role: disabling these features significantly degrades RL models' generalization performance, while amplifying them improves base models' performance. The code is available at https://github.com/danshi777/RL-generalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that RL post-training improves LLM generalization over SFT by inducing more restrained, continually evolving feature changes that largely preserve base-model representations, while SFT introduces many specialized features early. Using a controlled setup with RL- and SFT-tuned models trained from the same base on identical data, the authors align internal activations in a shared feature space, identify a compact task-agnostic set of features that mediate generalization on RL-success/base-failure samples, and validate causality via interventions: disabling the features degrades RL generalization while amplifying them improves base-model performance.
Significance. If the central claims hold, the work supplies a mechanistic account of why RL generalizes where SFT does not, grounded in a controlled experimental design, direct feature-level interventions, and open code. These elements could guide more effective post-training techniques and advance interpretability research on LLM capabilities.
major comments (1)
- [interpretability framework / activation alignment] The shared feature space alignment procedure (described in the interpretability framework section) is load-bearing for the identification of the compact task-agnostic feature set and all subsequent causal claims. The manuscript does not report sensitivity analyses to the alignment objective, regularization, choice of backbone, or alternative maps (linear vs. nonlinear). If the selected features or intervention effects vary under different alignment choices, the reported mediation and causality results could be artifacts rather than intrinsic differences.
minor comments (2)
- Expand the methods section with full details on feature extraction, error analysis, and explicit checks for confounds in feature selection to make the evidence more conclusive.
- Clarify how the task-agnostic property of the identified features is quantified across the diverse tasks.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. The concern about the robustness of the activation alignment procedure is substantive, and we address it directly below while committing to revisions that will strengthen the evidence.
read point-by-point responses
-
Referee: [interpretability framework / activation alignment] The shared feature space alignment procedure (described in the interpretability framework section) is load-bearing for the identification of the compact task-agnostic feature set and all subsequent causal claims. The manuscript does not report sensitivity analyses to the alignment objective, regularization, choice of backbone, or alternative maps (linear vs. nonlinear). If the selected features or intervention effects vary under different alignment choices, the reported mediation and causality results could be artifacts rather than intrinsic differences.
Authors: We agree that the alignment procedure is central to identifying the task-agnostic features and to the subsequent causal interventions, and that the lack of reported sensitivity analyses is a genuine limitation of the current manuscript. The linear alignment was selected for its interpretability and empirical stability in preserving cross-model correspondences on our controlled setup, but this choice requires explicit validation. In the revised version we will add a dedicated sensitivity subsection that systematically varies the alignment objective (including cosine-based and contrastive losses), regularization strength, backbone model, and alignment map (linear versus nonlinear MLPs or kernel methods). For each variant we will quantify overlap in the recovered feature set, consistency of mediation on RL-success/base-failure samples, and stability of the intervention effects. These results will be reported alongside the original findings so that readers can evaluate robustness directly. revision: yes
Circularity Check
No significant circularity in empirical mechanistic chain
full rationale
The paper's derivation proceeds via controlled training of RL/SFT models from the same base on identical data, activation alignment into a shared space, selection of features differing on RL-success/base-failure samples, and direct causal interventions (disabling/amplifying features). None of these steps reduce by the paper's own descriptions or equations to self-defined quantities, fitted inputs renamed as predictions, or load-bearing self-citations; the interventions supply independent falsifiable evidence outside the identification procedure itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Internal activations of different models can be aligned in a shared feature space that preserves mechanistic meaning.
Reference graph
Works this paper leans on
-
[1]
Boyi Deng, Yu Wan, Baosong Yang, Yidan Zhang, and Fuli Feng
Association for Computational Linguistics. Boyi Deng, Yu Wan, Baosong Yang, Yidan Zhang, and Fuli Feng. 2025. Unveiling language-specific fea- tures in large language models via sparse autoen- coders. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Vol- ume 1: Long Papers), pages 4563–4608. Andrey Galichin, Alexe...
-
[2]
Measuring massive multitask language under- standing. InInternational Conference on Learning Representations. Maggie Huan, Yuetai Li, Tuney Zheng, Xiaoyu Xu, Seungone Kim, Minxin Du, Radha Poovendran, Gra- ham Neubig, and Xiang Yue. 2025. Does math rea- soning improve general LLM capabilities? under- standing transferability of LLM reasoning.arXiv preprin...
-
[3]
Notion Blog
DeepScaleR: Surpassing o1-preview with a 1.5b model by scaling RL. Notion Blog. Samuel Marks, Can Rager, Eric J Michaud, Yonatan Be- linkov, David Bau, and Aaron Mueller. 2025. Sparse feature circuits: Discovering and editing interpretable causal graphs in language models. InThe Thirteenth International Conference on Learning Representa- tions. Todor Miha...
2025
-
[4]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Automatic evals for LLMs. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, and 1 others. 2024. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300. Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Ya...
work page internal anchor Pith review arXiv 2024
-
[5]
Kimi k1.5: Scaling Reinforcement Learning with LLMs
Kimi k1. 5: Scaling reinforcement learning with LLMs.arXiv preprint arXiv:2501.12599. David Vilares and Carlos Gómez-Rodríguez. 2019. HEAD-QA: A healthcare dataset for complex reason- ing. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 960–966, Florence, Italy. Association for Computa- tional Linguistics. ...
work page internal anchor Pith review arXiv 2019
-
[6]
Safe-SAIL: Towards a fine-grained safety landscape of large language models via sparse au- toencoder interpretation framework.arXiv preprint arXiv:2509.18127. Xinwei Wu, Junzhuo Li, Minghui Xu, Weilong Dong, Shuangzhi Wu, Chao Bian, and Deyi Xiong. 2023. DEPN: Detecting and editing privacy neurons in pre- trained language models. InProceedings of the 2023...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxin Yang, Jingren Zhou, Junyang Lin, and 25 oth- ers. 2024. Qwen2.5 technical report.arXiv preprin...
work page internal anchor Pith review arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.