The Role of Symmetry in Optimizing Overparameterized Networks
Pith reviewed 2026-05-11 00:55 UTC · model grok-4.3
The pith
Overparameterization introduces additional symmetries that precondition the Hessian and increase the reachability of global minima from typical initializations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We prove that these symmetries act as a form of diagonal preconditioning on the Hessian, enabling the existence of better-conditioned minima within each equivalence class of functionally identical solutions. Second, we show that overparameterization increases the probability mass of global minima near typical initializations. Empirically, wider networks exhibit lower top eigenvalues, smaller condition numbers, and faster convergence, consistent with the geometric analysis.
What carries the argument
weight-space symmetries introduced by overparameterization, which supply diagonal preconditioning on the Hessian and reshape the measure of favorable minima
If this is right
- Better-conditioned minima become available inside each equivalence class of solutions without changing the function computed.
- Global minima acquire higher probability mass near standard initializations, raising the chance that gradient descent finds them.
- Wider networks display lower dominant Hessian eigenvalues and smaller condition numbers.
- Convergence speed increases with width as a direct geometric consequence.
- Overparameterization and width growth can be viewed as a single geometric transformation of the loss landscape.
Where Pith is reading between the lines
- The same symmetry-based preconditioning might be engineered directly into narrower architectures to mimic the benefit of width.
- The account suggests a route from loss-landscape geometry to the observed simplicity bias in trained networks.
- If the mechanism is general, similar symmetry effects could appear in other overparameterized models such as transformers or graph networks.
Load-bearing premise
The additional symmetries created by increasing width are the primary driver of improved conditioning and reachability, rather than other consequences of having more parameters.
What would settle it
An experiment that increases width while holding the number of distinct symmetries fixed and finds no reduction in the top Hessian eigenvalue or condition number would falsify the claimed mechanism.
Figures
















read the original abstract
Overparameterization is central to the success of deep learning, yet the mechanisms by which it improves optimization remain incompletely understood. We analyze weight-space symmetries in neural networks and show that overparameterization introduces additional symmetries that benefit optimization in two distinct ways. First, we prove that these symmetries act as a form of diagonal preconditioning on the Hessian, enabling the existence of better-conditioned minima within each equivalence class of functionally identical solutions. Second, we show that overparameterization increases the probability mass of global minima near typical initializations, making these favourable solutions more reachable. These results offer a potential link between loss landscape geometry and simplicity bias. Empirically, we observe wider networks have lower top eigenvalues, smaller condition numbers and faster convergence, matching our analysis. Our analysis provides a unified framework for understanding overparameterization and width growth as a geometric transformation of the loss landscape.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript analyzes weight-space symmetries in neural networks and claims that overparameterization introduces additional symmetries benefiting optimization in two ways: (1) these symmetries act as diagonal preconditioning on the Hessian, enabling better-conditioned minima within each equivalence class of functionally identical solutions; (2) overparameterization increases the probability mass of global minima near typical initializations, making favorable solutions more reachable. The claims are supported by asserted proofs and empirical observations that wider networks exhibit lower top eigenvalues, smaller condition numbers, and faster convergence, offering a potential link between loss landscape geometry and simplicity bias.
Significance. If the results hold, this provides a geometric explanation connecting overparameterization to optimization success via symmetries and Hessian conditioning, potentially unifying theory with the observed benefits of width. The paper's attempt to derive both existence of better minima and increased reachability from symmetries, together with matching empirical trends on eigenvalues and convergence, is a positive feature.
major comments (2)
- [Abstract] Abstract: The claim that overparameterization increases the probability mass of global minima near typical initializations requires a precisely defined probability measure (or volume element) on weight space, together with an explicit demonstration that the measure of the set of parameters mapping to a given good function grows faster than the total space as width increases. If the analysis relies on unnormalized Lebesgue measure in higher dimensions or an initialization distribution whose density does not compensate for added dimensions, the mass increase does not automatically follow from the added symmetries; this is load-bearing for the reachability argument linking symmetries to optimization from random starts.
- [Abstract] Abstract: The manuscript asserts proofs that symmetries act as a form of diagonal preconditioning on the Hessian but provides no details on the derivations, assumptions on the loss or architecture, or the specific equations establishing the preconditioning effect. The full text must supply these steps to allow verification that the claimed better-conditioned minima exist within each equivalence class.
minor comments (2)
- [Introduction] The introduction should define the precise notion of equivalence classes and orbits under the symmetries before using them in the claims.
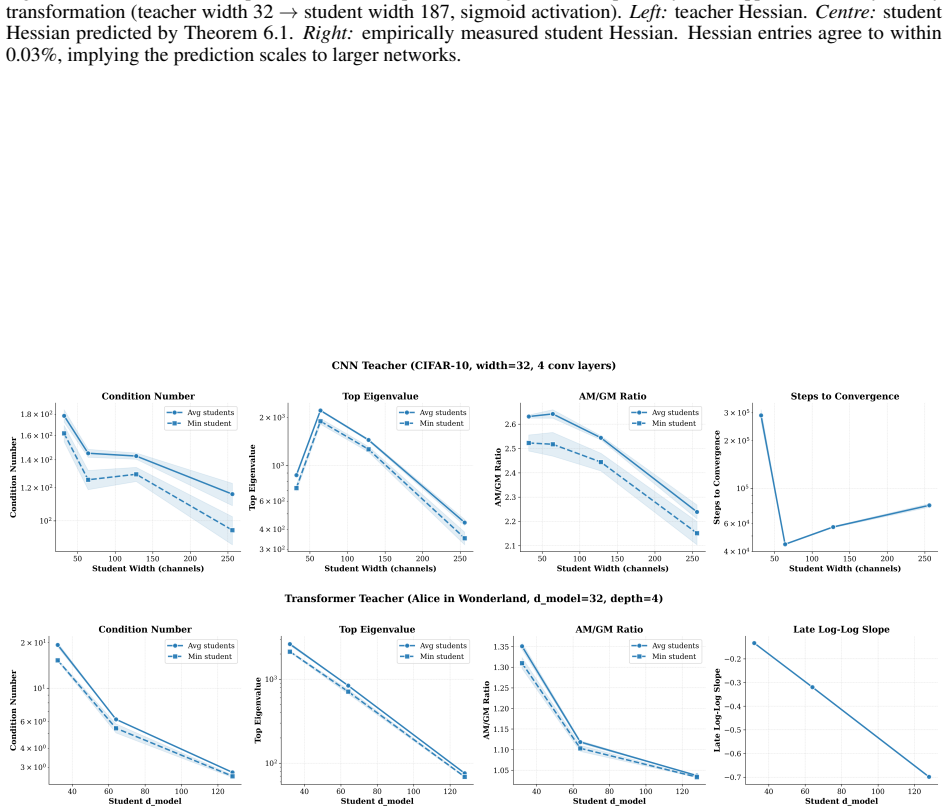
- [Experiments] Empirical figures comparing eigenvalues and condition numbers across widths would benefit from error bars or multiple random seeds to strengthen the reported trends.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The two major comments identify areas where additional rigor and explicit derivations are needed to support the claims. We will revise the manuscript to address both points fully, adding the requested definitions, demonstrations, and proof details without altering the core arguments.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that overparameterization increases the probability mass of global minima near typical initializations requires a precisely defined probability measure (or volume element) on weight space, together with an explicit demonstration that the measure of the set of parameters mapping to a given good function grows faster than the total space as width increases. If the analysis relies on unnormalized Lebesgue measure in higher dimensions or an initialization distribution whose density does not compensate for added dimensions, the mass increase does not automatically follow from the added symmetries; this is load-bearing for the reachability argument linking symmetries to optimization from random starts.
Authors: We agree that a precise definition of the measure is essential for the reachability claim. In the revised manuscript we will explicitly state that the probability measure is the one induced by the standard isotropic Gaussian initialization (with variance scaled as 1/width per layer, as is conventional). We will then provide a direct calculation showing that, for a fixed target function, the symmetry group generated by the additional hidden units enlarges the preimage set by a factor that grows polynomially with width, while the total measure of the ambient space grows only exponentially in the number of parameters; the net effect is an increase in the measure of the basin of attraction around typical initializations. This calculation will be placed in a new subsection of the main text together with the necessary volume estimates. revision: yes
-
Referee: [Abstract] Abstract: The manuscript asserts proofs that symmetries act as a form of diagonal preconditioning on the Hessian but provides no details on the derivations, assumptions on the loss or architecture, or the specific equations establishing the preconditioning effect. The full text must supply these steps to allow verification that the claimed better-conditioned minima exist within each equivalence class.
Authors: We acknowledge that the current version only sketches the preconditioning argument. In the revision we will expand the relevant section to include the complete derivation: starting from the chain-rule expression for the Hessian under a symmetry transformation that permutes or rescales redundant neurons, we show that the symmetry orbit induces a diagonal rescaling of the eigenvalues in the tangent space orthogonal to the equivalence class. The assumptions (twice-differentiable loss, local quadratic approximation near a minimum, and fully-connected layers with homogeneous activations) will be stated explicitly, and the key matrix identity establishing the diagonal preconditioner will be displayed as an equation. A short appendix will contain the intermediate algebraic steps. revision: yes
Circularity Check
No significant circularity; claims rest on independent proofs and separate empirical checks
full rationale
The paper's two central claims are presented as mathematical results: symmetries induce diagonal preconditioning on the Hessian (existence statement inside equivalence classes) and overparameterization enlarges the measure of favorable minima near initialization. These are derived from symmetry group actions and volume scaling arguments rather than from fitted parameters or self-referential definitions. Empirical observations of eigenvalue spectra and convergence rates are reported as corroboration, not as the source of the theoretical statements. No load-bearing step reduces to a self-citation chain, an ansatz smuggled via prior work, or a renaming of an input quantity. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ainsworth, Jonathan Hayase, and Siddhartha S
Samuel K. Ainsworth, Jonathan Hayase, and Siddhartha S. Srinivasa. Git re-basin: Merging models modulo permutation symmetries. In International Conference on Learning Representations, 2023
work page 2023
-
[2]
A convergence theory for deep learning via over-parameterization
Zeyuan Allen-Zhu, Yuanzhi Li, and Zhao Song. A convergence theory for deep learning via over-parameterization. In Proceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pages 242--252. PMLR, 2019
work page 2019
-
[3]
On the optimization of deep networks: Implicit acceleration by overparameterization
Sanjeev Arora, Nadav Cohen, and Elad Hazan. On the optimization of deep networks: Implicit acceleration by overparameterization. In Proceedings of the 35th International Conference on Machine Learning, volume 80 of Proceedings of Machine Learning Research, pages 244--253. PMLR, 2018
work page 2018
-
[4]
Johanni Brea, Berfin Simsek, Bernd Illing, and Wulfram Gerstner. Weight-space symmetry in deep networks gives rise to permutation saddles, connected by equal-loss valleys across the loss landscape, 2019
work page 2019
-
[5]
On lazy training in differentiable programming
L\' e na\" i c Chizat, Edouard Oyallon, and Francis Bach. On lazy training in differentiable programming. In Advances in Neural Information Processing Systems, volume 32, 2019
work page 2019
-
[6]
Ronan Collobert. Large Scale Machine Learning. PhD thesis, Universit\' e de Paris VI, 2004
work page 2004
-
[7]
Global minima of overparameterized neural networks
Yaim Cooper. Global minima of overparameterized neural networks. SIAM Journal on Mathematics of Data Science, 3 0 (2): 0 676--691, 2021
work page 2021
-
[8]
Sharp minima can generalize for deep nets, 2017
Laurent Dinh, Razvan Pascanu, Samy Bengio, and Yoshua Bengio. Sharp minima can generalize for deep nets, 2017
work page 2017
-
[9]
Numerical computations and the ømega -condition number
X Doan and Henry Wolkowicz. Numerical computations and the ømega -condition number. 01 2011
work page 2011
-
[10]
Felix Draxler, Kambis Veschgini, Manfred Salmhofer, and Fred A. Hamprecht. Essentially no barriers in neural network energy landscape. In Proceedings of the 35th International Conference on Machine Learning, volume 80 of Proceedings of Machine Learning Research, pages 1309--1318. PMLR, 2018
work page 2018
-
[11]
Simon S. Du, Jason D. Lee, Haochuan Li, Liwei Wang, and Xiyu Zhai. Gradient descent finds global minima of deep neural networks. In Proceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pages 1675--1685. PMLR, 2019
work page 2019
-
[12]
The role of permutation invariance in linear mode connectivity of neural networks
Rahim Entezari, Hanie Sedghi, Olga Saukh, and Behnam Neyshabur. The role of permutation invariance in linear mode connectivity of neural networks. In International Conference on Learning Representations, 2022
work page 2022
-
[13]
G. E. Forsythe and E. G. Straus. On best conditioned matrices. Proceedings of the American Mathematical Society, 6 0 (3): 0 340--345, 1955
work page 1955
-
[14]
Loss surfaces, mode connectivity, and fast ensembling of DNN s
Timur Garipov, Pavel Izmailov, Dmitrii Podoprikhin, Dmitry Vetrov, and Andrew Gordon Wilson. Loss surfaces, mode connectivity, and fast ensembling of DNN s. In Advances in Neural Information Processing Systems, volume 31, 2018
work page 2018
-
[15]
Saeed Ghadimi, Woosuk L. Jung, Arnesh Sujanani, David Torregrosa-Belén, and Henry Wolkowicz. New insights and algorithms for optimal diagonal preconditioning, 2025. URL https://arxiv.org/abs/2509.23439
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
An investigation into neural net optimization via hessian eigenvalue density, 2019
Behrooz Ghorbani, Shankar Krishnan, and Ying Xiao. An investigation into neural net optimization via hessian eigenvalue density, 2019
work page 2019
-
[17]
Learning dynamics of deep linear networks beyond the edge of stability, 2025
Avrajit Ghosh, Soo Min Kwon, Rongrong Wang, Saiprasad Ravishankar, and Qing Qu. Learning dynamics of deep linear networks beyond the edge of stability, 2025
work page 2025
-
[18]
Elisenda Grigsby, Kathryn Lindsey, and David Rolnick
J. Elisenda Grigsby, Kathryn Lindsey, and David Rolnick. Hidden symmetries of relu networks. In International Conference on Machine Learning, pages 11734--11760. PMLR, 2023
work page 2023
-
[19]
No wrong turns: The simple geometry of neural networks optimization paths, 2023
Charles Guille-Escuret, Hiroki Naganuma, Kilian Fatras, and Ioannis Mitliagkas. No wrong turns: The simple geometry of neural networks optimization paths, 2023
work page 2023
-
[20]
Sepp Hochreiter and J\"urgen Schmidhuber. Flat minima. Neural Computation, 9 0 (1): 0 1--42, 1997. doi:10.1162/neco.1997.9.1.1
-
[21]
Projection based weight normalization for deep neural networks, 2017
Lei Huang, Xianglong Liu, Bo Lang, and Bo Li. Projection based weight normalization for deep neural networks, 2017
work page 2017
-
[22]
Neural tangent kernel: Convergence and generalization in neural networks
Arthur Jacot, Franck Gabriel, and Cl\' e ment Hongler. Neural tangent kernel: Convergence and generalization in neural networks. In Advances in Neural Information Processing Systems, volume 31, 2018
work page 2018
-
[23]
Barriers for learning in an evolving world: Mathematical understanding of loss of plasticity, 2025
Amir Joudaki, Giulia Lanzillotta, Mohammad Samragh Razlighi, Iman Mirzadeh, Keivan Alizadeh, Thomas Hofmann, Mehrdad Farajtabar, and Fartash Faghri. Barriers for learning in an evolving world: Mathematical understanding of loss of plasticity, 2025. URL https://arxiv.org/abs/2510.00304
work page internal anchor Pith review arXiv 2025
-
[24]
Jung, David Torregrosa-Belén, and Henry Wolkowicz
Woosuk L. Jung, David Torregrosa-Belén, and Henry Wolkowicz. The -condition number: Applications to optimal preconditioning and low rank generalized jacobian updating, 2024. URL https://arxiv.org/abs/2308.13195
-
[25]
Daniel Kunin, Javier Sagastuy-Bre\ n a, Surya Ganguli, Daniel L.K. Yamins, and Hidenori Tanaka. Neural mechanics: Symmetry and broken conservation laws in deep learning dynamics. In International Conference on Learning Representations, 2021
work page 2021
-
[26]
Aaron Mishkin, Alberto Bietti, and Robert M. Gower. Level set teleportation: An optimization perspective, 2025
work page 2025
-
[27]
Path- SGD : Path-normalized optimization in deep neural networks, 2015
Behnam Neyshabur, Ruslan Salakhutdinov, and Nathan Srebro. Path- SGD : Path-normalized optimization in deep neural networks, 2015
work page 2015
-
[28]
On connected sublevel sets in deep learning
Quynh Nguyen. On connected sublevel sets in deep learning. In Proceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pages 4790--4799. PMLR, 2019
work page 2019
-
[29]
Homogenization of sgd in high-dimensions: Exact dynamics and generalization properties, 2022
Courtney Paquette, Elliot Paquette, Ben Adlam, and Jeffrey Pennington. Homogenization of sgd in high-dimensions: Exact dynamics and generalization properties, 2022. URL https://arxiv.org/abs/2205.07069
-
[30]
Ugur Guney, Yann Dauphin, and Leon Bottou
Levent Sagun, Utku Evci, V. Ugur Guney, Yann Dauphin, and Leon Bottou. Empirical analysis of the hessian of over-parametrized neural networks, 2017
work page 2017
-
[31]
Tim Salimans and Diederik P. Kingma. Weight normalization: A simple reparameterization to accelerate training of deep neural networks, 2016
work page 2016
-
[32]
Andrew M. Saxe, James L. McClelland, and Surya Ganguli. Exact solutions to the nonlinear dynamics of learning in deep linear neural networks, 2014
work page 2014
-
[33]
Berfin Simsek, Fran c ois Ged, Arthur Jacot, Francesco Spadaro, Cl\' e ment Hongler, Wulfram Gerstner, and Johanni Brea. Geometry of the loss landscape in overparameterized neural networks: Symmetries and invariances, 2021
work page 2021
-
[34]
A. van der Sluis. Condition numbers and equilibration of matrices. Numerische Mathematik, 14: 0 14--23, 1970. URL http://eudml.org/doc/131939
work page 1970
-
[35]
Uniqueness of the weights for minimal feedforward nets with a given input-output map
H \'e ctor J Sussmann. Uniqueness of the weights for minimal feedforward nets with a given input-output map. Neural Networks, 5 0 (4): 0 589--593, 1992
work page 1992
-
[36]
Greg Yang, Edward J. Hu, Igor Babuschkin, Szymon Sidor, Xiaodong Liu, David Farhi, Nick Ryder, Jakub Pachocki, Weizhu Chen, and Jianfeng Gao. Tensor programs V : Tuning large neural networks via zero-shot hyperparameter transfer, 2022
work page 2022
-
[37]
Beyond the permutation symmetry of transformers: The role of rotation for model fusion, 2025 a
Binchi Zhang, Zaiyi Zheng, Zhengzhang Chen, and Jundong Li. Beyond the permutation symmetry of transformers: The role of rotation for model fusion, 2025 a
work page 2025
-
[38]
Tianyue H. Zhang, Lucas Maes, Alan Milligan, Alexia Jolicoeur-Martineau, Ioannis Mitliagkas, Damien Scieur, Simon Lacoste-Julien, and Charles Guille-Escuret. Understanding Adam requires better rotation dependent assumptions, 2025 b
work page 2025
-
[39]
arXiv preprint arXiv:2402.03804 , year=
Zhengyan Zhang, Yixin Song, Guanghui Yu, Xu Han, Yankai Lin, Chaojun Xiao, Chenyang Song, Zhiyuan Liu, Zeyu Mi, and Maosong Sun. Relu ^2 wins: Discovering efficient activation functions for sparse llms, 2024. URL https://arxiv.org/abs/2402.03804
-
[40]
Symmetry induces structure and constraint of learning, 2023
Liu Ziyin. Symmetry induces structure and constraint of learning, 2023. URL https://arxiv.org/abs/2309.16932
-
[41]
Stochastic gradient descent optimizes over-parameterized deep ReLU networks, 2019
Difan Zou, Yuan Cao, Dongruo Zhou, and Quanquan Gu. Stochastic gradient descent optimizes over-parameterized deep ReLU networks, 2019
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.