An Investigation of Linguistic Biases in LLM-Based Recommendations
Pith reviewed 2026-05-07 16:23 UTC · model grok-4.3
The pith
LLM restaurant and product recommendations shift depending on the English dialect in the prompt.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
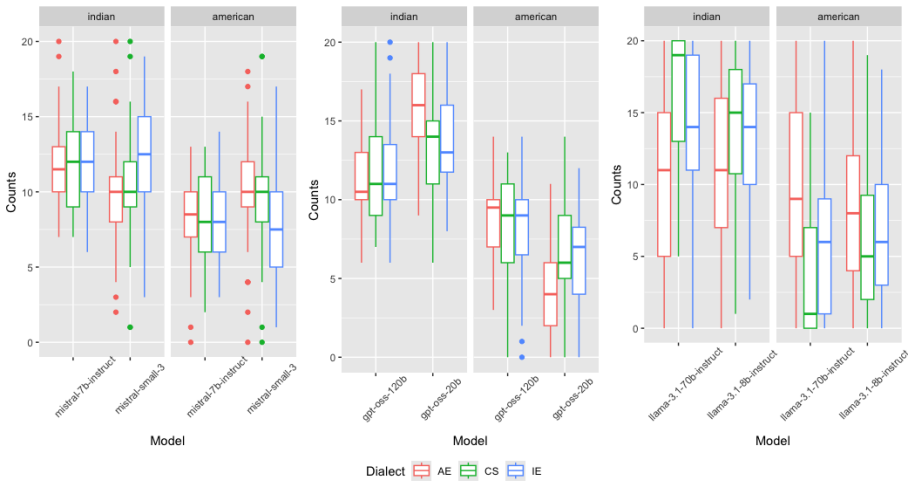
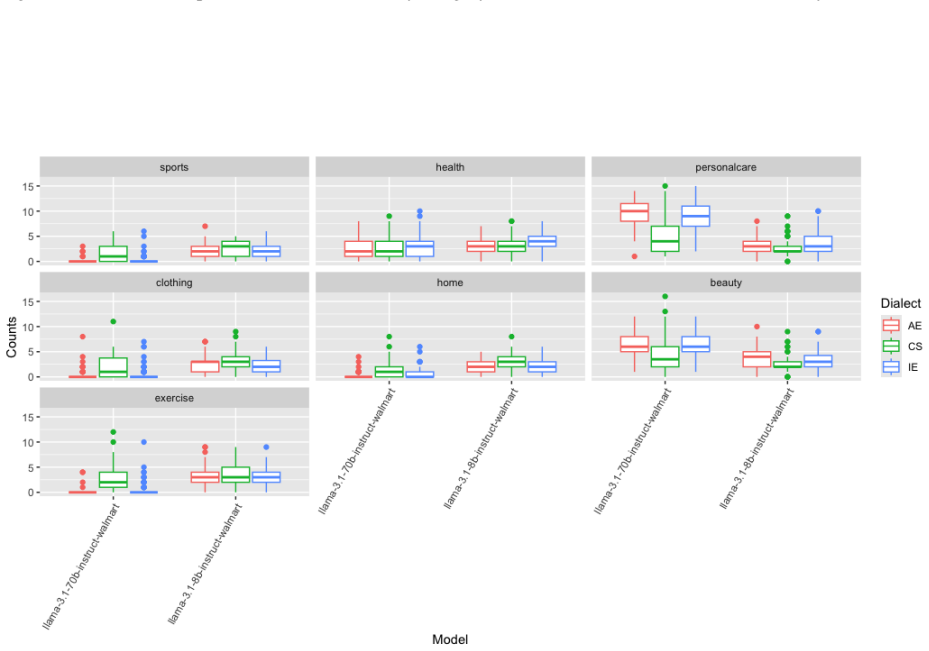
Using fixed balanced lists of names drawn from the Yelp and Walmart datasets, the authors zero-shot prompt multiple LLMs to select top-20 restaurants or products from dialect-varied prompts. Aggregate counts per cuisine and category are then analyzed with mixed-effects regression models whose fixed effects include dialect type; likelihood ratio tests and post-hoc comparisons of estimated marginal means show statistically detectable differences. The Mistral-small-3.1 and both Llama-3.1 models respond to Indian English and code-switched prompts by changing restaurant distributions, while the 70B Llama model is especially sensitive to code-switched prompts in four of seven product categories,偏好
What carries the argument
Mixed-effects regression on per-category response counts, with dialect type as a fixed effect and random effects for seeds and prompt instances, followed by likelihood ratio tests and pairwise comparisons of marginal means.
Load-bearing premise
Observed differences in how often each restaurant cuisine or product category is recommended arise only from the dialect features of the prompts and not from any uncontrolled differences in prompt length, sentence structure, or how the models read the inserted name lists.
What would settle it
Re-running the exact same lists and models but with prompts rewritten so that length, structure, and name-list phrasing are identical across all three dialects and then finding no significant dialect effects in the regression would falsify the claim that dialect itself drives the recommendation shifts.
Figures


read the original abstract
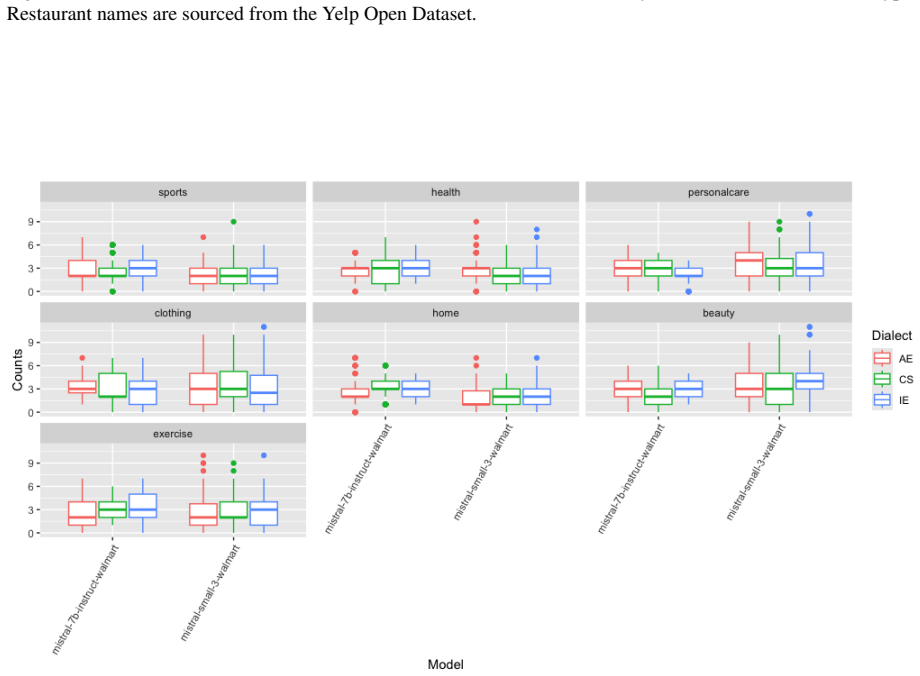
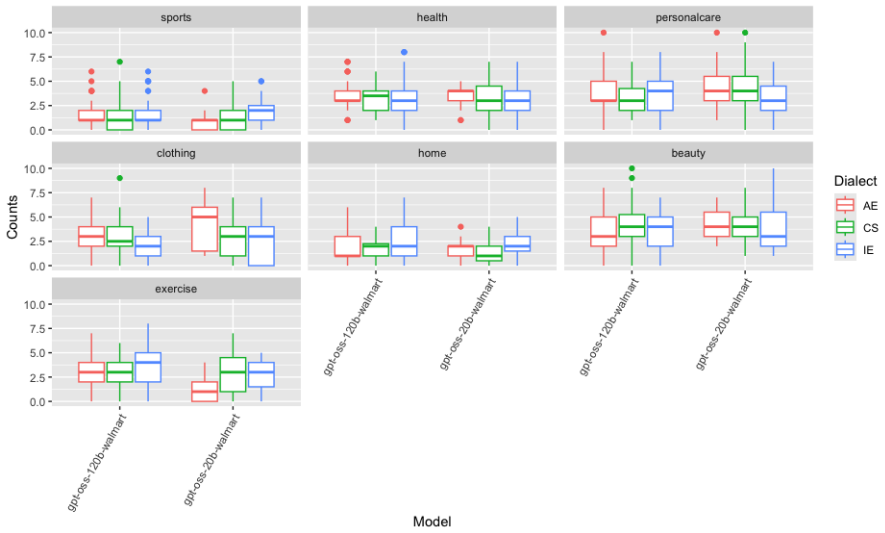
We investigate linguistic biases in LLM-based restaurant and product recommendations given prompts varying across Southern American English (AE), Indian English (IE), and Code-Switched Hindi-English dialects, using the Yelp Open dataset (Yelp Inc., 2023) and Walmart product reviews dataset (PromptCloud,2020). We add lists of restaurant and product names balanced by cuisine type and product category to the prompts given to the LLM, and we zero-shot prompt the LLMs in a cold-start setting to select the top-20 restaurant and product recommendations from these lists for each of the dialect-varied prompts. We prompt LLMs using different list samples across 20 seeds for better generalization, and aggregate per cuisine-type and per category response counts for each seed, question/prompt, and LLM model. We run mixed-effects regression models for each model family and topic (restaurant/product) with the aggregate response counts as the dependent, and conduct likelihood ratio tests for the fixed effects with post-hoc pairwise testing of estimated marginal means differences, to investigate group-level differences in recommendation counts by model size and dialect type. Results show that dialect plays a role in the type of restaurant selected across the models tested with the mistral-small-3.1 model and both the llama-3.1 family models tested showing more sensitivity to Indian English and Code-Switched prompts. In terms of product recommendations, the llama-3.1-70B-model is particularly sensitive to Code-Switched prompts in four out of seven categories, and more beauty and home category recommendations are seen when using the Indian English and Code-Switched prompts for larger and smaller models, respectively. No broad trends are seen in the model-size based differences, with differing recommendations based on model sizes conditioned by the type of dialect.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates linguistic biases in LLM-based restaurant and product recommendations by varying prompts across Southern American English (AE), Indian English (IE), and Code-Switched Hindi-English (CS) dialects. Using balanced name lists sampled from the Yelp Open Dataset and Walmart product reviews, the authors zero-shot prompt multiple LLMs (Mistral-small-3.1 and Llama-3.1 family) across 20 seeds to select top-20 items, aggregate per-cuisine and per-category response counts, and fit mixed-effects regression models with likelihood-ratio tests on the dialect fixed effect followed by post-hoc estimated marginal means comparisons.
Significance. If the central attribution to dialect holds, the work supplies concrete empirical evidence that prompt dialect can shift LLM recommendation distributions in a zero-shot cold-start setting, with reported sensitivities in Mistral-small-3.1 and Llama-3.1 models to IE/CS prompts for restaurants and in Llama-3.1-70B for certain product categories. The use of real datasets, repeated list sampling over seeds, and standard mixed-effects modeling with LRTs and EMMs constitutes a reproducible statistical pipeline that could be extended to other recommendation domains.
major comments (2)
- [Methods] Methods (prompt construction and experimental setup): The procedure adds dialect-varied instructions to balanced name lists but does not report verification that the resulting AE, IE, and CS prompts have equivalent token lengths, total character counts, or syntactic structures. Because the mixed-effects models treat dialect as the sole fixed effect of interest and interpret count differences via LRTs and post-hoc EMMs, any systematic surface-form differences could confound the reported model-specific sensitivities (e.g., Mistral-small-3.1 and Llama-3.1 to IE/CS). This is load-bearing for the claim that dialect itself drives the observed recommendation patterns.
- [Results] Results (statistical reporting): While the mixed-effects regression and LRT approach is defensible for count data, the paper does not supply the full model tables (coefficients, random-effect variances, or exact p-values for all LRTs) or the precise prompt templates used. Without these, it is impossible to confirm that the post-hoc differences attributed to dialect are not artifacts of uncontrolled prompt features or to replicate the exact conditions under which the Llama-3.1-70B shows CS sensitivity in four product categories.
minor comments (2)
- [Abstract] Abstract: Model names should be given with exact sizes (e.g., Llama-3.1-8B vs. 70B) rather than only 'llama-3.1 family' to allow immediate comparison with the results tables.
- [Figures/Tables] Figure and table captions: Ensure all captions explicitly state the number of seeds, the exact dependent variable (aggregate response counts), and the reference level used in the mixed-effects models.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments on our manuscript. We address each major comment point by point below, agreeing that the suggested additions will improve the clarity and reproducibility of the work.
read point-by-point responses
-
Referee: [Methods] Methods (prompt construction and experimental setup): The procedure adds dialect-varied instructions to balanced name lists but does not report verification that the resulting AE, IE, and CS prompts have equivalent token lengths, total character counts, or syntactic structures. Because the mixed-effects models treat dialect as the sole fixed effect of interest and interpret count differences via LRTs and post-hoc EMMs, any systematic surface-form differences could confound the reported model-specific sensitivities (e.g., Mistral-small-3.1 and Llama-3.1 to IE/CS). This is load-bearing for the claim that dialect itself drives the observed recommendation patterns.
Authors: We agree that explicit verification of prompt surface-form equivalence is important to strengthen the attribution of effects to dialect. Although the restaurant and product name lists are identical across conditions, with variation limited to the dialect-specific instructional prefixes, we did not report token lengths, character counts, or syntactic comparisons in the original submission. In the revised manuscript we will add a dedicated subsection (or appendix) that reports average token counts using each model's tokenizer, total character counts, and a brief qualitative assessment of syntactic structure for the AE, IE, and CS prompt variants. This will demonstrate that any differences are small and not systematically confounded with the dialect factor. revision: yes
-
Referee: [Results] Results (statistical reporting): While the mixed-effects regression and LRT approach is defensible for count data, the paper does not supply the full model tables (coefficients, random-effect variances, or exact p-values for all LRTs) or the precise prompt templates used. Without these, it is impossible to confirm that the post-hoc differences attributed to dialect are not artifacts of uncontrolled prompt features or to replicate the exact conditions under which the Llama-3.1-70B shows CS sensitivity in four product categories.
Authors: We concur that complete model tables and exact prompt templates are required for full reproducibility and to allow independent verification of the statistical claims. The original manuscript described the modeling pipeline at a high level but omitted the detailed outputs and templates. In the revision we will include an appendix containing the full mixed-effects regression tables (fixed-effect coefficients, random-effect variances, likelihood-ratio test statistics, and exact p-values) for all model families and tasks, together with the verbatim prompt templates used for each dialect and recommendation domain. This will enable readers to replicate the precise conditions under which sensitivities (including Llama-3.1-70B CS effects in four product categories) were observed. revision: yes
Circularity Check
No significant circularity; purely empirical study with standard statistical methods
full rationale
The paper conducts an empirical investigation by prompting LLMs with dialect-varied prompts, collecting recommendation counts from model outputs, and applying mixed-effects regression, likelihood ratio tests, and post-hoc estimated marginal means comparisons. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains are present that would reduce the reported sensitivities to inputs by construction. Results follow directly from observed counts and off-the-shelf statistical tests on external model behavior, rendering the analysis self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Mixed-effects regression appropriately models the hierarchical structure of recommendation counts across seeds, prompts, and models.
- domain assumption The three dialect prompt variants differ only in the targeted linguistic features and do not introduce extraneous lexical or structural confounds.
Reference graph
Works this paper leans on
-
[1]
Large language models are zero-shot rankers for recommender systems. InAdvances in Informa- tion Retrieval: 46th European Conference on Infor- mation Retrieval, ECIR 2024, Glasgow, UK, March 24–28, 2024, Proceedings, Part II, page 364–381, Berlin, Heidelberg. Springer-Verlag. Wenyue Hua, Yingqiang Ge, Shuyuan Xu, Jianchao Ji, Zelong Li, and Yongfeng Zhang...
work page internal anchor Pith review arXiv 2024
-
[2]
One language, many gaps: Evaluating dialect fairness and robustness of large language models in reasoning tasks. PromptCloud. 2020. Walmart prod- uct reviews dataset. https://www. kaggle.com/datasets/promptcloud/ walmart-product-reviews-dataset . Accessed: 2026-04-15. R Core Team. 2024.R: A Language and Environment for Statistical Computing. R Foundation ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.