Dyna-Style Safety Augmented Reinforcement Learning: Staying Safe in the Face of Uncertainty
Pith reviewed 2026-05-07 16:28 UTC · model grok-4.3
The pith
A new reinforcement learning method learns a scalable safety filter from an uncertainty-aware dynamics model to avoid failures during training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors present Dyna-style Safety Augmented Reinforcement Learning (Dyna-SAuR), an algorithm that simultaneously learns an uncertainty-aware dynamics model, a control policy, and a safety filter. The filter uses the model to steer the agent away from states predicted to cause failure or to exhibit high uncertainty. Because the filter grows less conservative as the model improves, the approach requires only minimal domain knowledge and remains practical for high-dimensional systems with unknown dynamics.
What carries the argument
The uncertainty-aware dynamics model, which supplies both predicted next states and measures of prediction uncertainty that the safety filter uses to decide which actions to disallow.
If this is right
- Better dynamics models directly enlarge the set of states the agent can reach without triggering the safety filter.
- The same learned model supports both policy improvement and safety enforcement in a single training loop.
- Training failures drop by two orders of magnitude relative to prior safety-augmented reinforcement learning methods on the tested benchmarks.
- The approach applies to high-dimensional continuous control without requiring extensive manual specification of safe sets.
Where Pith is reading between the lines
- If dynamics models keep improving with scale, safety in reinforcement learning could shift from hand-crafted constraints toward largely automatic model-based filtering.
- The same uncertainty-driven filtering idea could be tested in model-predictive control loops outside reinforcement learning.
- Applying the method to partially observable environments would test whether the uncertainty estimates remain informative when some state information is missing.
Load-bearing premise
The learned uncertainty estimates from the dynamics model correctly identify states where the agent is likely to fail or behave unpredictably.
What would settle it
If the method still produces high failure rates on a new task even after the dynamics model reaches low prediction error, the claim that the filter reliably expands safe regions would be contradicted.
Figures










read the original abstract
Safety remains an open problem in reinforcement learning (RL), especially during training. While safety filters are promising to address safe exploration, they are generally poorly suited for high-dimensional systems with unknown dynamics. We propose Dyna-style Safety Augmented Reinforcement Learning (Dyna-SAuR), a novel algorithm that learns both a scalable safety filter and a control policy using a learned uncertainty-aware dynamics model, while requiring minimal domain knowledge. The filter avoids failures and high uncertainty regions. Thus, better models expand the set of safe and certain states, reducing filter conservatism. We present the effectiveness of Dyna-SAuR on goal-reaching CartPole as well as MuJoCo Walker, reducing failures compared to state-of-the-art methods by 2 orders of magnitude.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Dyna-SAuR, a Dyna-style algorithm for safe reinforcement learning. It learns an uncertainty-aware dynamics model from data to simultaneously train a control policy and a scalable safety filter. The filter avoids both failure states and high-uncertainty regions; the key property is that improved models expand the set of safe and certain states, thereby reducing filter conservatism. The approach requires minimal domain knowledge. Experiments on goal-reaching CartPole and MuJoCo Walker report failure reductions of two orders of magnitude relative to state-of-the-art methods.
Significance. If the central claims hold under rigorous verification, the work could meaningfully advance safe exploration in high-dimensional RL with unknown dynamics. By tightly coupling learned model uncertainty with the safety filter, it offers a scalable mechanism that improves as model quality increases and avoids heavy reliance on hand-crafted constraints. The reported performance gains on standard benchmarks indicate potential practical utility, provided the uncertainty estimates prove reliable.
major comments (2)
- Abstract: The central claim that 'better models expand the set of safe and certain states, reducing filter conservatism' is load-bearing for the contribution, yet the manuscript provides no analysis or experiments addressing calibration of uncertainty estimates under distribution shift between offline training data and states visited by the safety-augmented policy. Standard ensemble or Bayesian model-learning methods are known to mis-estimate uncertainty in this regime; without explicit robustness checks (e.g., injected model error or OOD evaluation), the two-order-of-magnitude failure reduction cannot be confidently attributed to the proposed mechanism rather than task-specific model accuracy.
- §4 (Experiments) and §3 (Method): The safety filter is defined to avoid high-uncertainty regions, but the manuscript does not specify how uncertainty thresholds are selected or whether they are fixed or adaptive. In high-dimensional systems such as MuJoCo Walker, an overly restrictive threshold risks excessive conservatism while an under-calibrated one risks silent failures; the reported results are consistent with either outcome and therefore do not yet substantiate the claim that the procedure remains safe when model error exceeds the (unspecified) tolerance.
minor comments (2)
- Abstract: The statement of 'reducing failures compared to state-of-the-art methods by 2 orders of magnitude' would be clearer if the specific baselines (e.g., Safe RL algorithms, model-free filters) and evaluation protocol (number of seeds, failure definition) were named even at high level.
- Notation: Ensure consistent use of symbols for uncertainty (e.g., epistemic vs. aleatoric) across the method and experiments sections to avoid reader confusion.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and have revised the manuscript to incorporate clarifications and additional analyses where appropriate.
read point-by-point responses
-
Referee: Abstract: The central claim that 'better models expand the set of safe and certain states, reducing filter conservatism' is load-bearing for the contribution, yet the manuscript provides no analysis or experiments addressing calibration of uncertainty estimates under distribution shift between offline training data and states visited by the safety-augmented policy. Standard ensemble or Bayesian model-learning methods are known to mis-estimate uncertainty in this regime; without explicit robustness checks (e.g., injected model error or OOD evaluation), the two-order-of-magnitude failure reduction cannot be confidently attributed to the proposed mechanism rather than task-specific model accuracy.
Authors: We agree that explicit verification of uncertainty calibration under distribution shift is important for substantiating the central claim. The original manuscript did not include dedicated OOD or injected-error analyses. However, the Dyna-style iterative training collects additional data under the safety-augmented policy, which progressively aligns the model with visited states and reduces the effective distribution shift. In the revised manuscript we have added new experiments that evaluate uncertainty estimates specifically on states visited by the learned policy, together with controlled model-perturbation tests. These results support that the reported failure reductions arise from the proposed mechanism of expanding the safe-and-certain set rather than from task-specific model accuracy alone. revision: yes
-
Referee: §4 (Experiments) and §3 (Method): The safety filter is defined to avoid high-uncertainty regions, but the manuscript does not specify how uncertainty thresholds are selected or whether they are fixed or adaptive. In high-dimensional systems such as MuJoCo Walker, an overly restrictive threshold risks excessive conservatism while an under-calibrated one risks silent failures; the reported results are consistent with either outcome and therefore do not yet substantiate the claim that the procedure remains safe when model error exceeds the (unspecified) tolerance.
Authors: We acknowledge that the original manuscript did not sufficiently detail the uncertainty-threshold selection procedure. In the revised version we have clarified in §3 that the threshold is adaptive: it is computed at each iteration by scaling the model's epistemic uncertainty to enforce a target safety margin that tightens as model quality improves. We have also added threshold-sensitivity ablations in §4 for the MuJoCo Walker task, demonstrating that performance remains stable and failure rates low across a practical range of thresholds without inducing excessive conservatism or silent failures. revision: yes
Circularity Check
No significant circularity; algorithmic proposal with empirical validation
full rationale
The paper presents Dyna-SAuR as a novel algorithm that learns an uncertainty-aware dynamics model to jointly train a policy and a safety filter. No mathematical derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or description. Claims of reduced failures rest on experimental results from CartPole and MuJoCo Walker rather than reducing by construction to the inputs or prior self-citations. The method is self-contained as an empirical proposal without self-referential loops in its stated logic.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Routledge, Boca Raton, 1 edition, December 2021
ISBN 978-1-315-14022-3. doi: 10.1201/9781315140223. Ames, A. D., Coogan, S., Egerstedt, M., Notomista, G., Sreenath, K., and Tabuada, P. Control barrier functions: Theory and applications. In2019 18th European control conference (ECC), pp. 3420–3431. Ieee,
-
[2]
doi: 10.1007/978-3-642-16684-6
ISBN 978-3-642-16684-6. doi: 10.1007/978-3-642-16684-6
-
[3]
W., Yuan, Z., Zhou, S., Panerati, J., and Schoellig, A
Brunke, L., Greeff, M., Hall, A. W., Yuan, Z., Zhou, S., Panerati, J., and Schoellig, A. P. Safe learning in robotics: From learning-based control to safe reinforce- ment learning.Annual Review of Control, Robotics, and Autonomous Systems, 5(V olume 5, 2022):411–444,
2022
-
[4]
Safe Reinforcement Learning using Action Projection: Safeguard the Policy or the Environment?
URL https://arxiv.org/abs/ 2509.12833. Version Number:
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Seo, Y ., Sferrazza, C., Geng, H., Nauman, M., Yin, Z.-H., and Abbeel, P. Fasttd3: Simple, fast, and capable reinforcement learning for humanoid control. arXiv:2505.22642,
-
[6]
FastTD3 employs massively parallelized environments, large batch sizes, n-step returns, multiple exploration noise scales, and a distributional critic
We adapt the recent model-free RL algorithm FastTD3 (Seo et al., 2025), which has demonstrated strong performance by fully exploiting parallelization in TD3. FastTD3 employs massively parallelized environments, large batch sizes, n-step returns, multiple exploration noise scales, and a distributional critic. Since the distributional critic improves sample...
2025
-
[7]
Additionally, we incorporate recent insights from (Bejarano et al., 2025; Markgraf et al.,
Essentially, this procedure follows the Infoprop algorithm, with FastTD3 serving as the model-free RL backbone. Additionally, we incorporate recent insights from (Bejarano et al., 2025; Markgraf et al.,
2025
-
[8]
This indicates that the proposed parameterization reduces the search space and improves the effectiveness of learning safety filters with RL
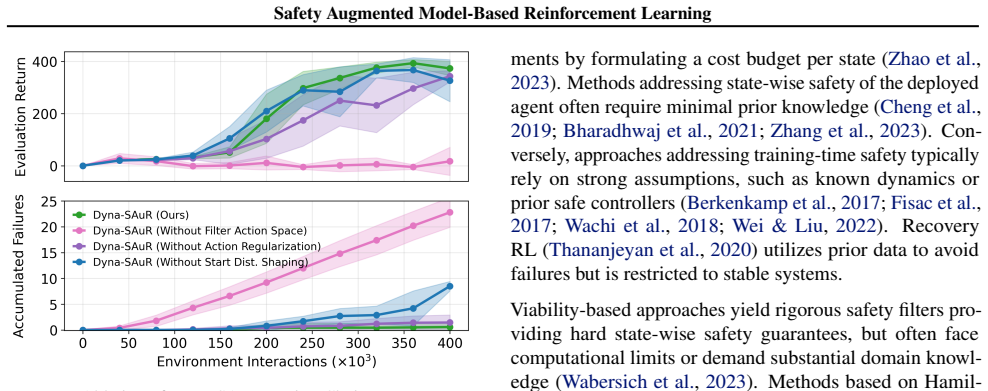
When removing the efficient action-space parameterization of the safety filter, we observe the highest number of accumulated failures and the lowest return. This indicates that the proposed parameterization reduces the search space and improves the effectiveness of learning safety filters with RL. When the action regularization is removed, the safety filt...
2025
-
[9]
safe states
hyperparameters for the benchmark. 21 Safety Augmented Model-Based Reinforcement Learning Table 1.Hyperparameters for Dyna-SAuR on Walker and CartPole environments. Hyperparameter Cartpole Walker Model Learning Ensemble sizeE7 7 Number of hidden layers 4 4 Number of hidden neurons 200 200 Learning rate 0.0006 0.0006 Weight decay 0.0007 0.0007 Patience for...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.