Safe Reinforcement Learning using Action Projection: Safeguard the Policy or the Environment?
Pith reviewed 2026-05-18 15:53 UTC · model grok-4.3
The pith
In safe RL, applying action projection inside the policy network produces worse gradient estimates than applying it as part of the environment due to action aliasing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that action aliasing in projection-based safety filters leads to information loss in policy gradients, with this effect being implicitly handled by the critic in safe environment RL but appearing explicitly as rank-deficient Jacobians in safe policy RL during backpropagation through the safeguard.
What carries the argument
Action aliasing caused by the projection operator mapping multiple unsafe actions to one safe action, and how it impacts the Jacobian of the policy gradient in actor-critic algorithms.
If this is right
- SP-RL experiences more direct harm from action aliasing than SE-RL.
- A novel penalty-based mitigation for SP-RL aligns it with practices in SE-RL and improves performance.
- With suitable improvements, SP-RL can match or outperform SE-RL in various environments.
- Empirical results confirm that action aliasing hurts SP-RL more severely.
Where Pith is reading between the lines
- Practitioners facing frequent unsafe actions during training may prefer the environment-based approach unless they apply the penalty fix to the policy version.
- Testing the methods in domains with very high-dimensional action spaces could reveal whether the rank deficiency becomes even more limiting.
- Extending the analysis to other safety filter types beyond projections might show similar gradient issues in policy-embedded versions.
Load-bearing premise
The safety filter must be expressible as a differentiable projection operator that can be placed inside the policy network without breaking the usual actor-critic gradient flow.
What would settle it
Measuring the rank of the Jacobian matrices when backpropagating through the safeguard in SP-RL and checking whether they are lower rank than in the SE-RL case, or observing larger performance gaps in tasks where projections occur often.
Figures





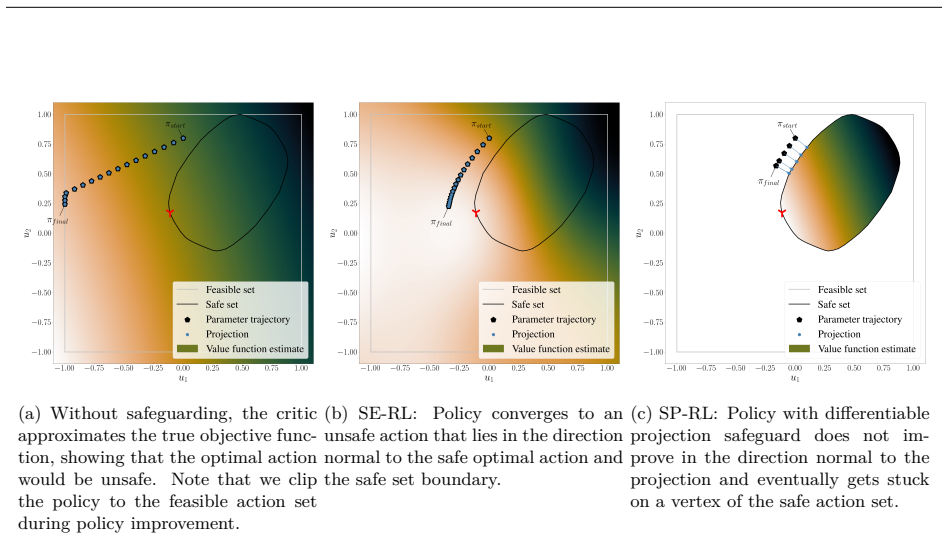

read the original abstract
Projection-based safety filters, which modify unsafe actions by mapping them to the closest safe alternative, are widely used to enforce safety constraints in reinforcement learning (RL). Two integration strategies are commonly considered: Safe environment RL (SE-RL), where the safeguard is treated as part of the environment, and safe policy RL (SP-RL), where it is embedded within the policy through differentiable optimization layers. Despite their practical relevance in safety-critical settings, a formal understanding of their differences is lacking. In this work, we present a theoretical comparison of SE-RL and SP-RL. We identify a key distinction in how each approach is affected by action aliasing, a phenomenon in which multiple unsafe actions are projected to the same safe action, causing information loss in the policy gradients. In SE-RL, this effect is implicitly approximated by the critic, while in SP-RL, it manifests directly as rank-deficient Jacobians during backpropagation through the safeguard. Our contributions are threefold: (i) a unified formalization of SE-RL and SP-RL in the context of actor-critic algorithms, (ii) a theoretical analysis of their respective policy gradient estimates, highlighting the role of action aliasing, and (iii) a comparative study of mitigation strategies, including a novel penalty-based improvement for SP-RL that aligns with established SE-RL practices. Empirical results support our theoretical predictions, showing that action aliasing is more detrimental for SP-RL than for SE-RL. However, with appropriate improvement strategies, SP-RL can match or outperform improved SE-RL across a range of environments. These findings provide actionable insights for choosing and refining projection-based safe RL methods based on task characteristics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper compares two strategies for incorporating projection-based safety filters into RL: SE-RL (treating the safeguard as part of the environment) and SP-RL (embedding a differentiable projection inside the policy network). It unifies both within actor-critic methods, analyzes how action aliasing produces information loss in policy gradients (implicitly approximated by the critic in SE-RL versus explicit rank-deficient Jacobians in SP-RL), introduces a penalty-based mitigation for SP-RL, and reports empirical results indicating that improved SP-RL can match or outperform improved SE-RL.
Significance. If the gradient analysis is sound, the work supplies a useful theoretical distinction for a common practical choice in safe RL and a mitigation strategy that aligns SP-RL with existing SE-RL techniques. The cross-environment empirical support and explicit focus on action aliasing add value for practitioners selecting or refining projection-based safeguards.
major comments (2)
- [§3] §3 (Policy Gradient Analysis): The central distinction—that SP-RL produces rank-deficient Jacobians under action aliasing while SE-RL lets the critic absorb the effect—rests on the projection operator being realized as a differentiable optimization layer that preserves the standard actor-critic gradient structure. For Euclidean projection onto a convex set, the map is only subdifferentiable at boundary points where aliasing is most pronounced; without an explicit statement of the gradient (e.g., Clarke subdifferential, smoothing parameter, or solver-specific approximation) used in the back-propagation, the claimed rank deficiency does not necessarily follow from the same formalization applied to SE-RL.
- [§4] §4 (Mitigation Strategies): The novel penalty-based improvement for SP-RL is presented as aligning with SE-RL practice, yet the derivation does not show how the added penalty term interacts with the (potentially rank-deficient) Jacobian of the projection layer. If the penalty is applied after the projection, the gradient flow may still be affected by the same aliasing-induced deficiency unless an additional correction is derived.
minor comments (2)
- [Experimental Setup] The experimental section would benefit from an explicit statement of the projection solver (e.g., CVXPY layer, custom QP solver) and any gradient approximation or smoothing used, so that the reported performance differences can be reproduced and the rank-deficiency effect verified.
- [Preliminaries] Notation for the projected action and its Jacobian is introduced without a consolidated table; a short notation summary would improve readability when comparing the two RL variants.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help us strengthen the technical presentation of the gradient analysis and mitigation strategy. We address each major comment below, indicating planned revisions to the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Policy Gradient Analysis): The central distinction—that SP-RL produces rank-deficient Jacobians under action aliasing while SE-RL lets the critic absorb the effect—rests on the projection operator being realized as a differentiable optimization layer that preserves the standard actor-critic gradient structure. For Euclidean projection onto a convex set, the map is only subdifferentiable at boundary points where aliasing is most pronounced; without an explicit statement of the gradient (e.g., Clarke subdifferential, smoothing parameter, or solver-specific approximation) used in the back-propagation, the claimed rank deficiency does not necessarily follow from the same formalization applied to SE-RL.
Authors: We agree that an explicit statement of the gradient computation is necessary for rigor. In the current manuscript, the SP-RL projection is realized via a differentiable optimization layer (Section 3) that back-propagates through the KKT conditions of the Euclidean projection problem, using the standard solver approximation implemented in the optimization layer library. At boundary points the Jacobian is indeed rank-deficient by construction when aliasing occurs, which is the source of the information loss we analyze. To address the referee's concern, we will revise §3 to explicitly document the gradient method (including any smoothing parameter or Clarke subdifferential handling) and to show that the rank deficiency holds under this formalization, thereby preserving the distinction with SE-RL where the critic implicitly averages over the aliased actions. revision: yes
-
Referee: [§4] §4 (Mitigation Strategies): The novel penalty-based improvement for SP-RL is presented as aligning with SE-RL practice, yet the derivation does not show how the added penalty term interacts with the (potentially rank-deficient) Jacobian of the projection layer. If the penalty is applied after the projection, the gradient flow may still be affected by the same aliasing-induced deficiency unless an additional correction is derived.
Authors: The referee correctly notes that the interaction between the penalty and the projection Jacobian merits further derivation. In our formulation the penalty is added to the policy objective before the projection step, which reduces the probability mass on actions that would trigger aliasing and thereby lowers the frequency of rank-deficient Jacobians during back-propagation. We will expand the derivation in §4 to include the chain-rule expansion through the (sub)differentiable projection layer, demonstrating that the penalty term directly attenuates the contribution of aliased directions without requiring an extra correction. This aligns the improved SP-RL more closely with the SE-RL penalty practice while preserving the theoretical distinction we established. revision: partial
Circularity Check
Standard actor-critic formalization with independent empirical support; no load-bearing reductions
full rationale
The paper supplies a unified formalization of SE-RL and SP-RL inside actor-critic methods, derives the effect of action aliasing on policy gradients from the respective placements of the projection operator, and validates the distinction with experiments across environments. No equation or central claim reduces the reported gradient behavior or performance gap to a quantity that was fitted or defined inside the same study. The analysis rests on standard differentiable optimization layers and established RL theory rather than self-referential definitions or self-citation chains.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The environment is a Markov decision process and both SE-RL and SP-RL are implemented inside an actor-critic framework.
Forward citations
Cited by 1 Pith paper
-
Dyna-Style Safety Augmented Reinforcement Learning: Staying Safe in the Face of Uncertainty
Dyna-SAuR learns scalable safety filters and policies from an uncertainty-aware model, cutting failures by two orders of magnitude on CartPole and MuJoCo Walker tasks.
Reference graph
Works this paper leans on
-
[1]
Safe Exploration in Continuous Action Spaces
Gal Dalal, Krishnamurthy Dvijotham, Matej Vecerik, Todd Hester, Cosmin Paduraru, and Yuval Tassa. Safe exploration in continuous action spaces.arXiv preprint arXiv:1801.08757,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Differentiable nonlinear model predictive control.arXiv preprint arXiv:2505.01353,
Jonathan Frey, Katrin Baumgärtner, Gianluca Frison, Dirk Reinhardt, Jasper Hoffmann, Leonard Fichtner, Sebastien Gros, and Moritz Diehl. Differentiable nonlinear model predictive control.arXiv preprint arXiv:2505.01353,
-
[3]
Continuous control with deep reinforcement learning
16 Timothy P Lillicrap, Jonathan J Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver, and Daan Wierstra. Continuous control with deep reinforcement learning.arXiv preprint arXiv:1509.02971,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Asynchronous methods for deep reinforcement learning
Volodymyr Mnih, Adria Puigdomenech Badia, Mehdi Mirza, Alex Graves, Timothy Lillicrap, Tim Harley, David Silver, and Koray Kavukcuoglu. Asynchronous methods for deep reinforcement learning. InInter- national conference on machine learning, pp. 1928–1937,
work page 1928
-
[5]
Hoang T Nguyen and Priya L Donti. Fsnet: Feasibility-seeking neural network for constrained optimization with guarantees.arXiv preprint arXiv:2506.00362,
-
[6]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
John Schulman, Philipp Moritz, Sergey Levine, Michael Jordan, and Pieter Abbeel. High-dimensional continuous control using generalized advantage estimation.arXiv preprint arXiv:1506.02438,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimiza- tion algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Leveraging Analytic Gradients in Provably Safe Reinforcement Learning
Tim Walter, Hannah Markgraf, Jonathan Külz, and Matthias Althoff. Provably safe reinforcement learning from analytic gradients.arXiv preprint arXiv:2506.01665,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
A Appendix A.1 Action Projection Using Zonotopes One option for defining safe action sets is to consider control invariant sets as safe state setsXφ, where xt∈Xφensures that there exists an admissible actionut∈Usuch that equation 10 can satisfied for all times. Then, the constraints in equation 12b can be defined usingC(xt,ut,wt)⊆Xφ, whereCis the set of a...
work page 2020
-
[10]
Buν=˜u−cu (33) ∥ν∥∞≤1.(34) A.2 Differentiating the Safeguard Using the Implicit Function Theorem If the projection safeguardΦis integrated into the policy as shown in figure 1b, we require the sensitivity of its output (the safe action) with respect to its input (the unsafe action) for the backward pass of the policy optimization. To obtain the sensitivit...
work page 2002
-
[11]
19 Proof.In SE-RL, for a certain policyπ, the state value function (equation 15b) is given as vSE π(x) =E ut∼π,xt∼pSEx [ gt ⏐⏐⏐⏐x0 =x ] (40) =E ut∼π,xt∼pSEx [ ∞∑ k=0 γkrt+k+1 ⏐⏐⏐⏐x0 =x ] (41) = ∞∑ k=0 γk ∫ ˜X ... ∫ ˜X ∫ U ... ∫ U ∫ R rp SE r (r|xk,uk)π(uk|xk) [k−1∏ i=0 pSE x (xi+1|xi,ui)π(ui|xi) ] drdu 0...dukdx1...dxk (42) = ∞∑ k=0 γk ∫ ˜X ... ∫ ˜X ∫ U ....
work page 2021
-
[12]
A.8 Benchmark Problems A.8.1 Pendulum Stabilization Task Our pendulum environment is closely related to theOpenAI Gym Pendulum-V02 environment with the difference that we limit the one-dimensional control input to|u|≤8rads−1. The environment has the state x= [ ϑ,˙ϑ ]T and the dynamics ˙x= ( ˙ϑ g ℓsin(ϑ) +1 mℓ2u ) ,(53) wheregis gravity andm,ℓare the mass ...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.